VMware: Fejlfindingsvejledning til vSAN fysisk disk
Summary: Dette er en generel fejlfindingsvejledning, der kan hjælpe dig med at finde ud af, om der er et problem med en fysisk disk i vSAN-klynger.
Instructions
Søger efter status for fysisk vSAN-disk fra webbrugergrænsefladen:
Opret forbindelse til vCenter Server-webklienten, og kontrollér diskstatus fra:
Lager > Vært og klynger > vSAN-klynge > Konfigurer > vSAN-diskhåndtering >
Billede 1: Visning
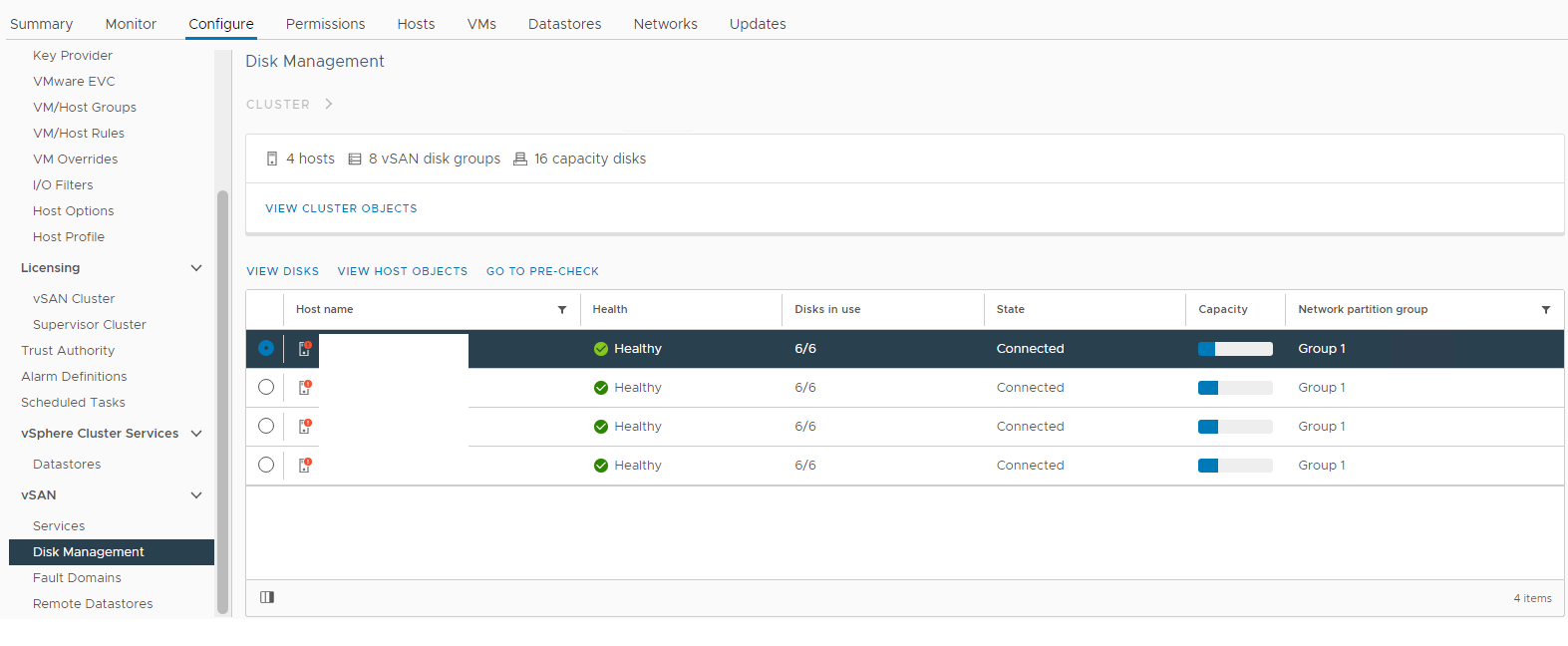
af vSAN-diskhåndtering Vælg den berørte vært, og udvid derefter afsnittet Vis disk:
Billede 2: Gruppevisning
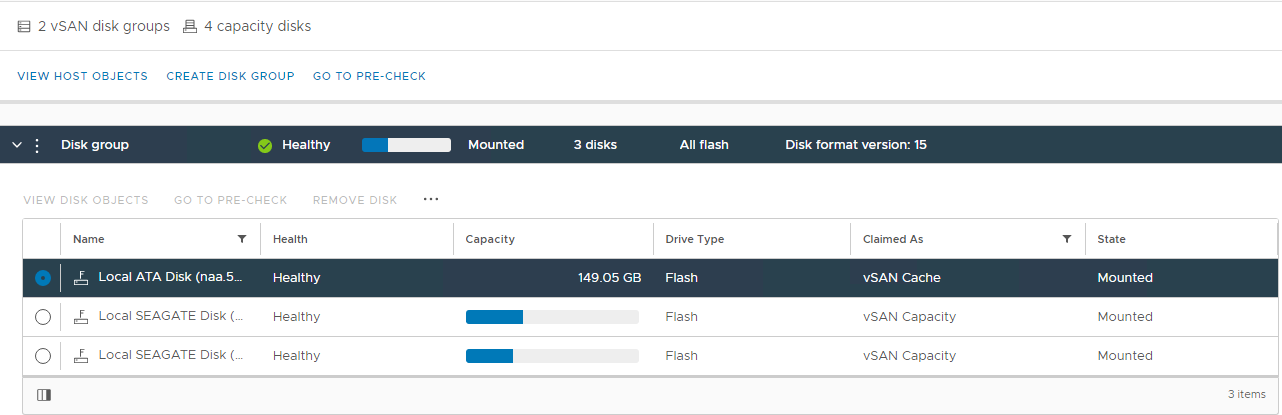
af vSAN-disk Her kan du kontrollere, om en disk registreres som:
Usund
Afmonteret
0 Kapacitet
Permanent diskfejl
Disk Down
Disk Absent
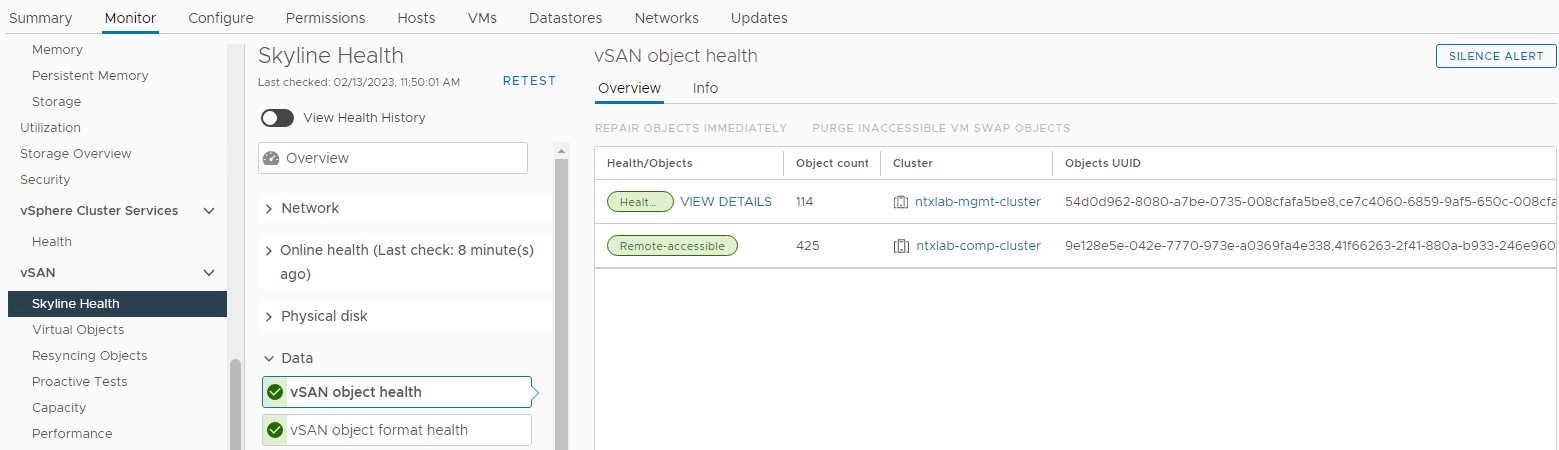
Kontroller også, om der er diskrelaterede alarmer, der udløses fra afsnittet vSAN Skyline Health:
Lager > Vært og klynger vSAN-klyngeovervågning >> vSAN > Skyline Health > Fysisk disk Billede 3:>
Visning
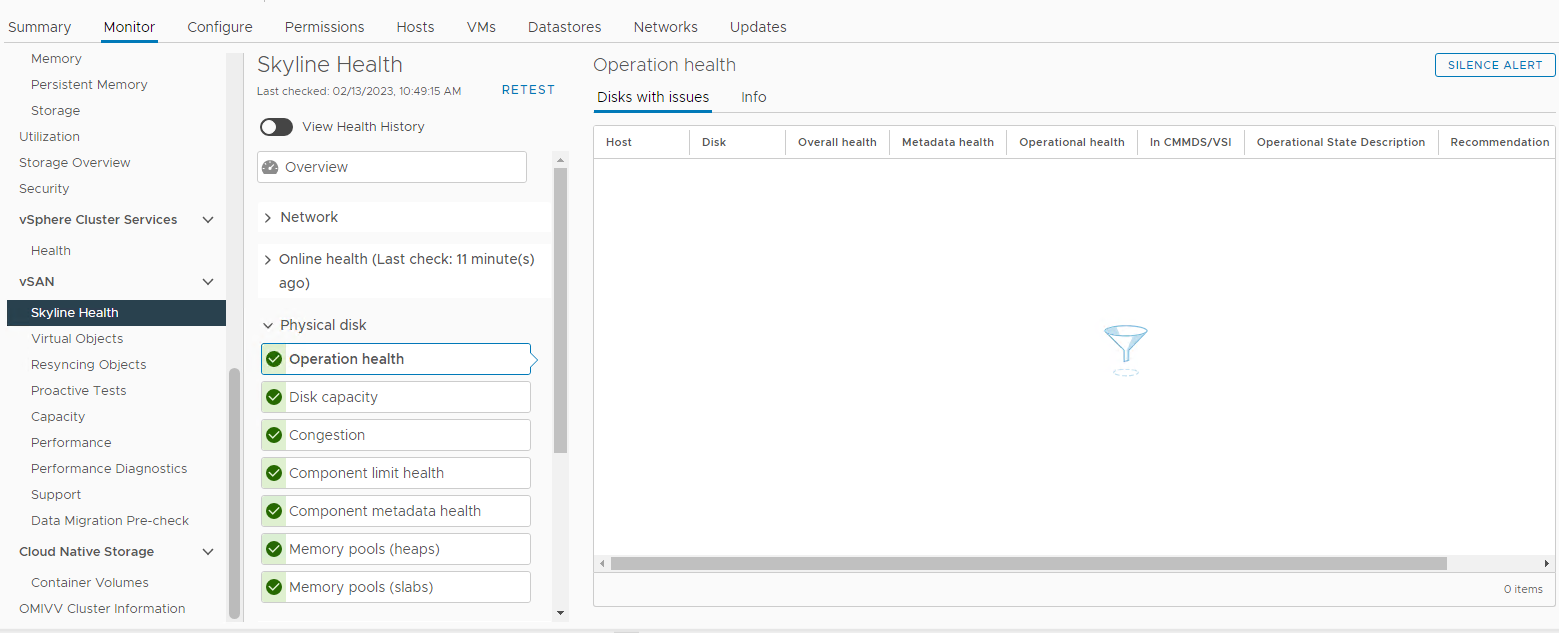
af Skyline Health Her kan du kontrollere, om en af følgende alarmer udløses:
Impending permanent disk failure, data is being evacuated (Health state - Yellow).
Impending permanent disk failure, data evacuation failed due to insufficient resources (Health state - Red).
Impending permanent disk failure, data evacuation failed due to inaccessible objects (Health state - Red).
Impending permanent disk failure, data evacuation completed (Health state - Yellow)
Du kan også kontrollere diskstatus fra den berørte værts liste over lagerenheder:
Lager > Vært og klynger > vSAN-klyngepåvirket > vSAN ESXi-vært > Konfigurer > lagerlagerenheder >
Billede 4: Visning af
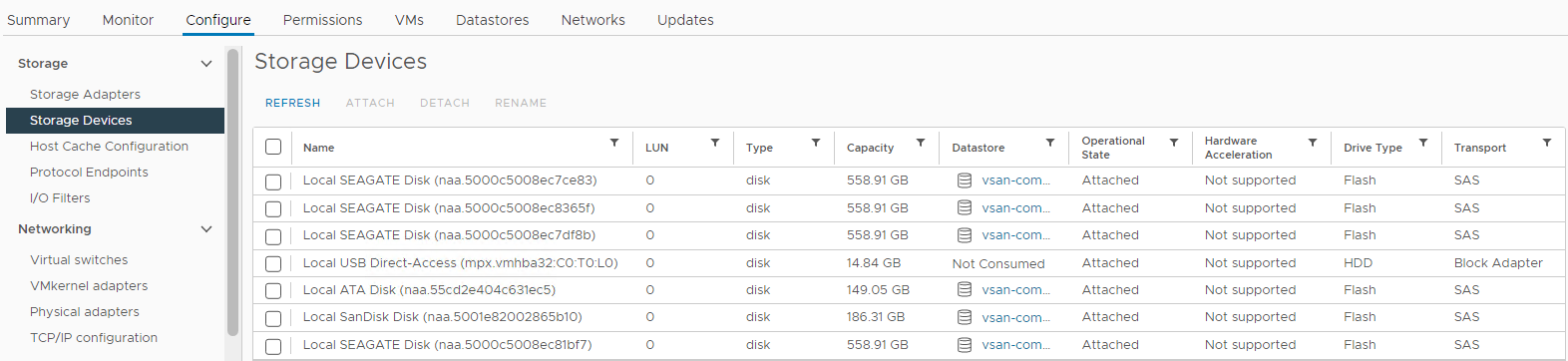
værtsstorageenheder Her kan du kontrollere, om en diskstatus er:
0 kapacitet
disk fraværende disk ikke-monteret
Kontroller, om der sker en gensynkronisering:
Lager > Vært og klynger > vSAN-klyngeovervågning >> vSAN > gensynkronisering af objekter:
Billede 5: Visning af gensynkronisering af objekter
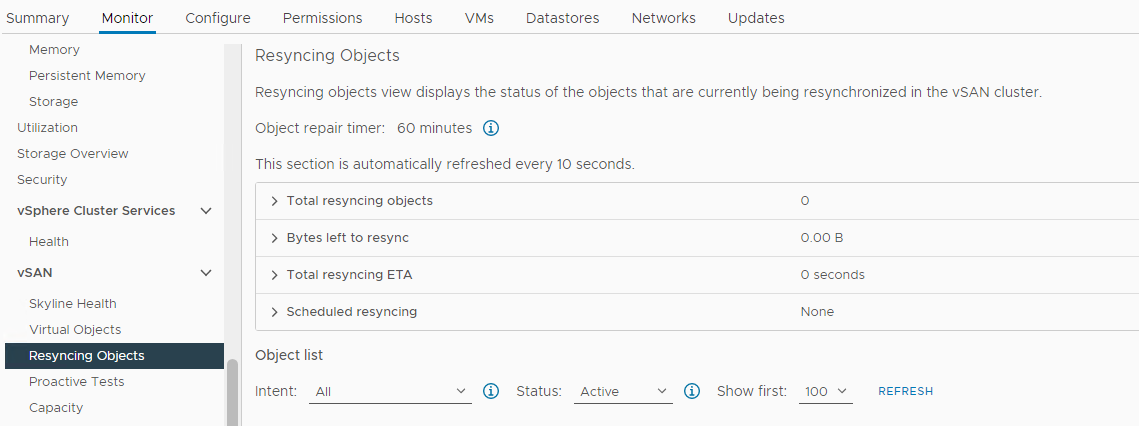
Kontrollér status for vSAN-objekter:
Lager > Værter og klynger vSAN-klyngeovervågning >> vSAN > Skyline-tilstandsdata >> vSAN-objekttilstand Billede 6: vSAN-objekttilstandsvisning >
Det næste trin er at indsamle flere oplysninger om problemet med CLI og kontrollere logfilerne:
Kontrol af status for vSAN fysisk disk fra CLI:
Opret forbindelse via SSH til den berørte vært, og kør følgende kommandoer:
vdq -qH
Tjek på "IsPDL" (permanent enhedstab) parameter. Hvis det er lig med 1, går disken tabt.
Eksempel:
DiskResults:
DiskResult[0]:
Name: naa.600508b1001c4b820b4d80f9f8acfa95
VSANUUID: 5294bbd8-67c4-c545-3952-7711e365f7fa
State: In-use for VSAN
ChecksumSupport: 0
Reason: Non-local disk
IsSSD?: 0
IsCapacityFlash?: 0
IsPDL?: 0
<<truncated>>
DiskResult[18]:
Name:
VSANUUID: 5227c17e-ec64-de76-c10e-c272102beba7
State: In-use for VSAN
ChecksumSupport: 0
Reason: None
IsSSD?: 0
IsCapacityFlash?: 0
IsPDL?: 1
vdq -iH
Kontroller, om der mangler en disk fra diskgruppen.
Eksempel:
Mappings: DiskMapping[0]: SSD: naa.58ce38ee2016ffe5 MD: naa.5002538a4819e3e0 DiskMapping[2]: SSD: naa.58ce38ee2016fe55 MD: naa.5002538a48199ca0 MD: naa.5002538a48199e20 MD: naa.5002538a48199e00
esxcli vsan storage list
Tjek på "In CMMDS" parameter. Hvis falsk, går kommunikationen tabt til disken.
Eksempel:
Device: Unknown
Display Name: Unknown
Is SSD: false
VSAN UUID: 529cadbc-acd1-b588-8643-68336d5512d6
VSAN Disk Group UUID:
VSAN Disk Group Name:
Used by this host: false
In CMMDS: false
On-disk format version: <Unknown>
Deduplication: false
Compression: false
Checksum:
Checksum OK: false
Is Capacity Tier: false
for i in `esxcli storage core device list | grep ^naa` ; do echo $i; esxcli storage core device smart get -d $i; done.
Kontrollér for læse-/skrivefejl med smart get-kommandoen.
Eksempel:
naa.55cd2e404c1f35a1 Parameter Value Threshold Worst Raw -------------------------- ----- --------- ----- --- Health Status OK N/A N/A N/A Media Wearout Indicator 100 0 100 86 Read Error Count 130 39 130 133 Power-on Hours 100 0 100 110 Power Cycle Count 100 0 100 106 Drive Temperature 100 0 100 26 Uncorrectable Sector Count 100 0 100 0
naa.55cd2e404c1f35a5 Parameter Value Threshold Worst Raw -------------------------- ----- --------- ----- --- Health Status OK N/A N/A N/A Media Wearout Indicator 100 0 100 10 Read Error Count 130 39 130 53 Power-on Hours 100 0 100 110 Power Cycle Count 100 0 100 106 Drive Temperature 100 0 100 27 Uncorrectable Sector Count 100 0 100 0
esxcli vsan storage list | grep "VSAN Disk Group UUID:" | sort | uniq -c
Kontroller, om der findes diskgrupper.
Eksempel:
2 VSAN Disk Group UUID: 5203424c-ee56-497d-75d1-fcf73ae997cb 2 VSAN Disk Group UUID: 52af8e5c-77d1-b552-3310-ec5fef09edf4
while true;do echo " ****************************************** "; echo "" > /tmp/resyncStats.txt ;cmmds-tool find -t DOM_OBJECT -f json |grep uuid |awk -F \" '{print $4}' |while read i;do pendingResync=$(cmmds-tool find -t DOM_OBJECT -f json -u $i|grep -o "\"bytesToSync\": [0-9]*,"|awk -F " |," '{sum+=$2} END{print sum / 1024 / 1024 / 1024;}');if [ ${#pendingResync} -ne 1 ]; then echo "$i: $pendingResync GiB";fi;done |tee -a /tmp/resyncStats.txt;total=$(cat /tmp/resyncStats.txt |awk '{sum+=$2} END{print sum}');echo "Total: $total GiB" |tee -aa /tmp/resyncStats.txt;total=$(cat /tmp/resyncStats.txt |grep Total);totalObj=$(cat /tmp/resyncStats.txt|grep -vE " 0 GiB|Total"|wc -l);echo "`date +%Y-%m-%dT%H:%M:%SZ` $total ($totalObj objects)" >> /tmp/totalHistory.txt; echo `date `; sleep 60; done
Kontroller, om der er igangværende eller fastlåste gensynkroniseringshandlinger.
Eksempel:
Total: 0 GiB Mon Feb 13 17:32:06 UTC 2023
Tryk på Ctrl+C for at stoppe kommandoen.
cmmds-tool find -f python | grep CONFIG_STATUS -B 4 -A 6 | grep 'uuid\|content' | grep -o 'state\\\":\ [0-9]*' | sort | uniq -c
Kontroller komponenternes tilstand.
Healthy -- state 7
Inaccessible -- state 13
Absent or Degraded -- state 15
Eksempel:
425 state\": 7
Sådan identificerer du, hvor den defekte SSD eller HARDDISK er placeret over CLI:
Vis alle tilgængelige enheder:
esxcli storage core device list | grep "naa" | awk '{print $1}' | grep "naa"
Eksempel:
naa.5000c500852df8d3 naa.55cd2e404c1f35a1 naa.55cd2e404c1f35a5 naa.5000c500852dd5e7
Kontroller placeringen ved hjælp af hver disk naa fra listen:
esxcli storage core device physical get -d
Eksempel:
esxcli storage core device physical get -d naa.5000c500852df8d3 esxcli storage core device physical get -d naa.55cd2e404c1f35a1 esxcli storage core device physical get -d naa.55cd2e404c1f35a5 esxcli storage core device physical get -d naa.5000c500852dd5e7 Physical Location: enclosure 65535 slot 0 Physical Location: enclosure 65535 slot 1 Physical Location: enclosure 65535 slot 2 Physical Location: enclosure 65535 slot 3
Sådan identificeres den defekte harddisk eller SSD, hvis enhedsnavnet mangler:
Det er muligt, at den fejlbehæftede disk ikke registreres og ikke kan identificeres ved hjælp af den tilsvarende naa. I dette scenarie er det nødvendigt at finde alle diske, og den, der ikke er fysisk placeret, ville være den, der mislykkedes.
Her er et script, der kan bruges til at udføre opgaven lidt hurtigere:
echo "=============Physical disks placement=============="
echo ""
esxcli storage core device list | grep "naa" | awk '{print $1}' | grep "naa" | while read in; do
echo "$in"
esxcli storage core device physical get -d "$in"
sleep 1
echo "===================================================="
done
vSAN-relevante logfiler til lagringsrelaterede problemer:
/var/log/vmkernel.log
Problemer med læsning og skrivning til vSAN-diske, vSAN-værtshjerteslag, PDL'er, SCSI-registreringskoder og I/O-anmodninger (læsninger/skrivninger) samt oplysninger om klyngemedlemskab.
Eksempel:
2021-06-22T12:02:08.408Z cpu30:1001397101)ScsiDeviceIO: PsaScsiDeviceTimeoutHandlerFn:12834: TaskMgmt op to cancel IO succeeded for device naa.55cd2e404b7736d0 and the IO did not complete. WorldId 0, Cmd 0x28, CmdSN = 0x428.Cancelling of IO will be 2021-06-22T12:02:08.408Z cpu30:1001397101)retried.
/var/log/vobd.log
Rapporter om disktilstand, permanente PDL'er (Device Lost Disks), diskforsinkelse og rapporter om, hvornår en vært går i og forlader vedligeholdelsestilstand.
Eksempel:
2022-05-31T11:42:46.065Z: [vSANCorrelator] 10605891965954us: [vob.vsan.lsom.devicerepair] vSAN device 521a74ce-c980-c16c-ff3d-38a036233daf is being repaired due to I/O failures, and will be out of service until the repair is complete. If the device is part of a dedup disk group, the entire disk group will be out of service until the repair is complete. 2022-05-31T11:42:46.065Z: [vSANCorrelator] 10606062774178us: [esx.problem.vob.vsan.lsom.devicerepair] Device 521a74ce-c980-c16c-ff3d-38a036233daf is in offline state and is getting repaired
/var/log/vsandevicemonitord.log
Den hjælper dig med at finde ud af, om disken blev markeret som usund på grund af overdreven overbelastning af loggen eller I/O-ventetider.
Eksempel:
INFO vsandevicemonitord WARNING - WRITE Average Latency on VSAN device naa.50000xxxxxxxx has exceeded threshold value 2000000 us 2 times. INFO vsandevicemonitord Tier 2 (naa.50000xxxxxxxx) as unhealthy
Additional Information
Se denne video:
VMware: Fejlfindingsvejledning til vSAN fysisk disk
Varighed: 00:10:19 (hh:mm:ss)
Når sprogindstillingerne for undertekster er tilgængelige, kan du vælge sprogindstillinger for undertekster ved hjælp af CC-ikonet på denne videoafspiller.
Du kan også se denne video på YouTube.