VMware: Probleemoplossingsgids voor vSAN fysieke schijven
Summary: Dit is een algemene probleemoplossingsgids om te helpen identificeren of er een probleem is met een fysieke schijf in vSAN-clusters.
Instructions
Controleren op de status van de fysieke vSAN-schijf vanuit de webinterface:
Maak verbinding met de vCenter Server Web Client en controleer de schijfstatus vanaf:
Inventaris > Host en clusters > vSAN-cluster vSAN-schijfbeheer >>>
configureren Afbeelding 1: weergave
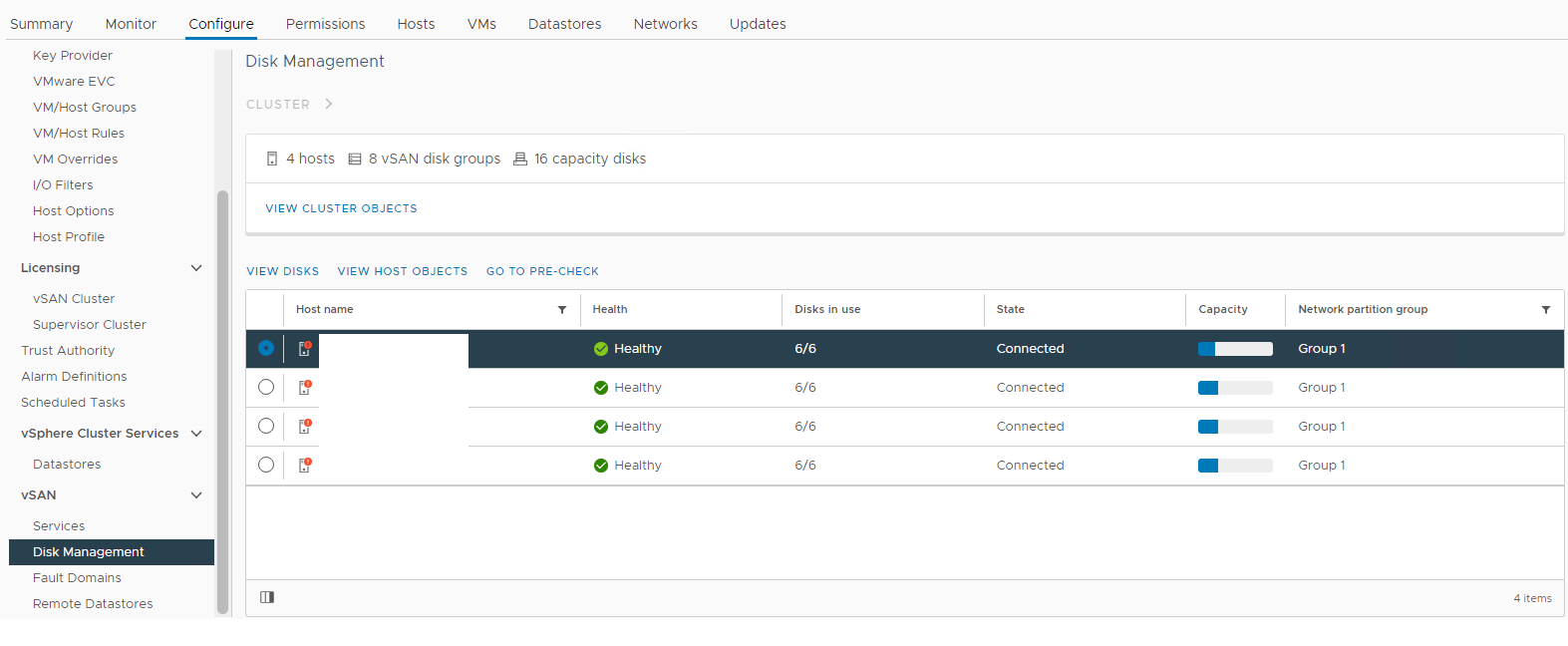 vSAN-schijfbeheer Selecteer de betreffende host en vouw vervolgens de sectie Schijf weergeven uit:
vSAN-schijfbeheer Selecteer de betreffende host en vouw vervolgens de sectie Schijf weergeven uit:
Afbeelding 2: weergave
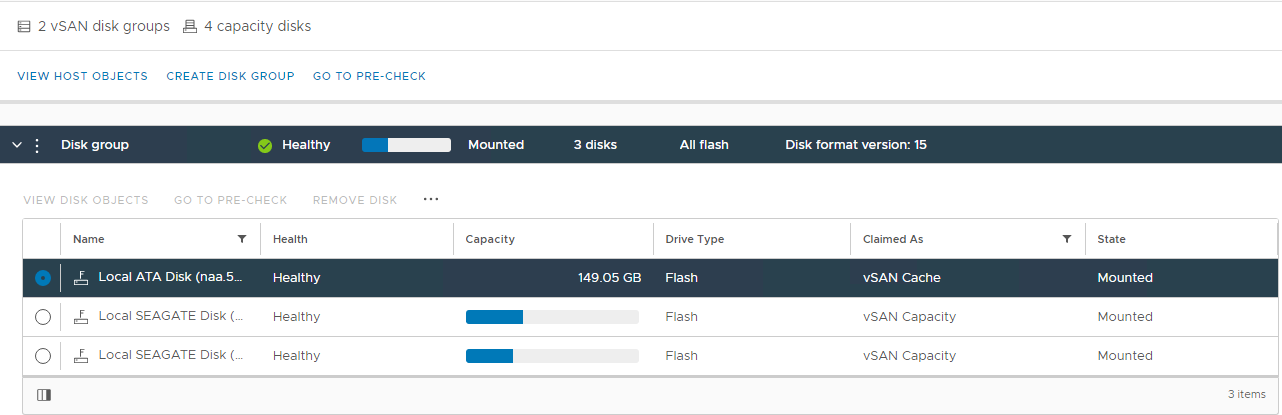 vSAN-schijfgroep Hier kunt u controleren of een schijf wordt gedetecteerd als:
vSAN-schijfgroep Hier kunt u controleren of een schijf wordt gedetecteerd als:
Ongezonde
niet-gekoppelde
permanente schijfstoring
met 0 capaciteit
Schijf niet werkende
schijf afwezig
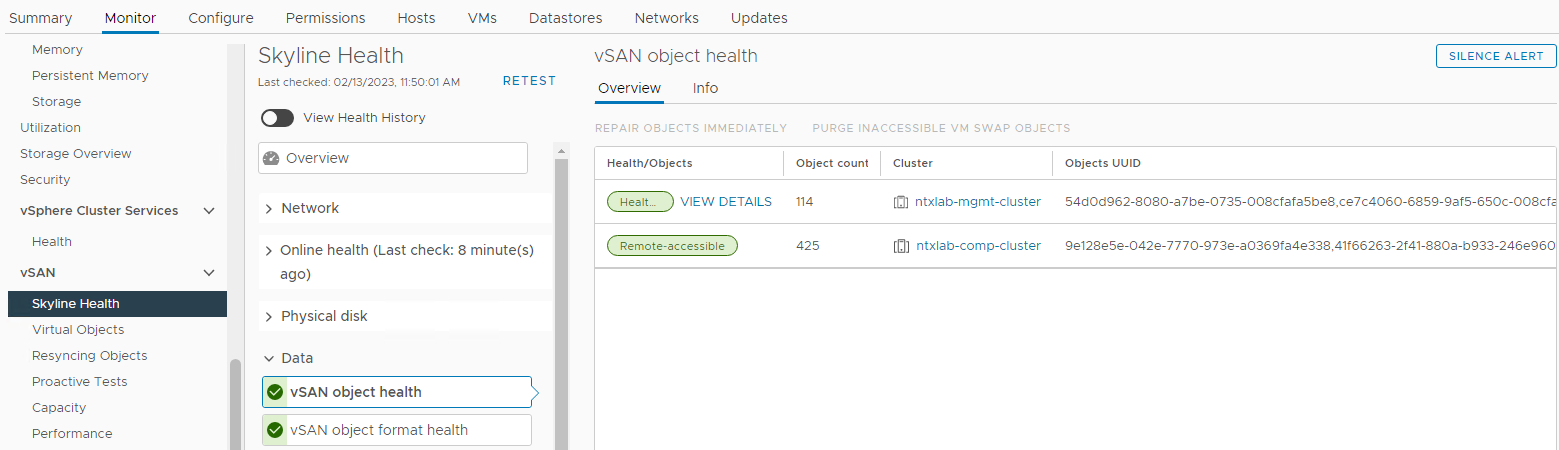
Controleer ook of er schijfgerelateerde alarmen zijn die worden geactiveerd vanuit de sectie vSAN Skyline Health:
Inventaris > Host en clusters > vSAN Cluster > Monitor > vSAN > Skyline Health > Fysieke schijf
Afbeelding 3: Skyline-gezondheidsweergave
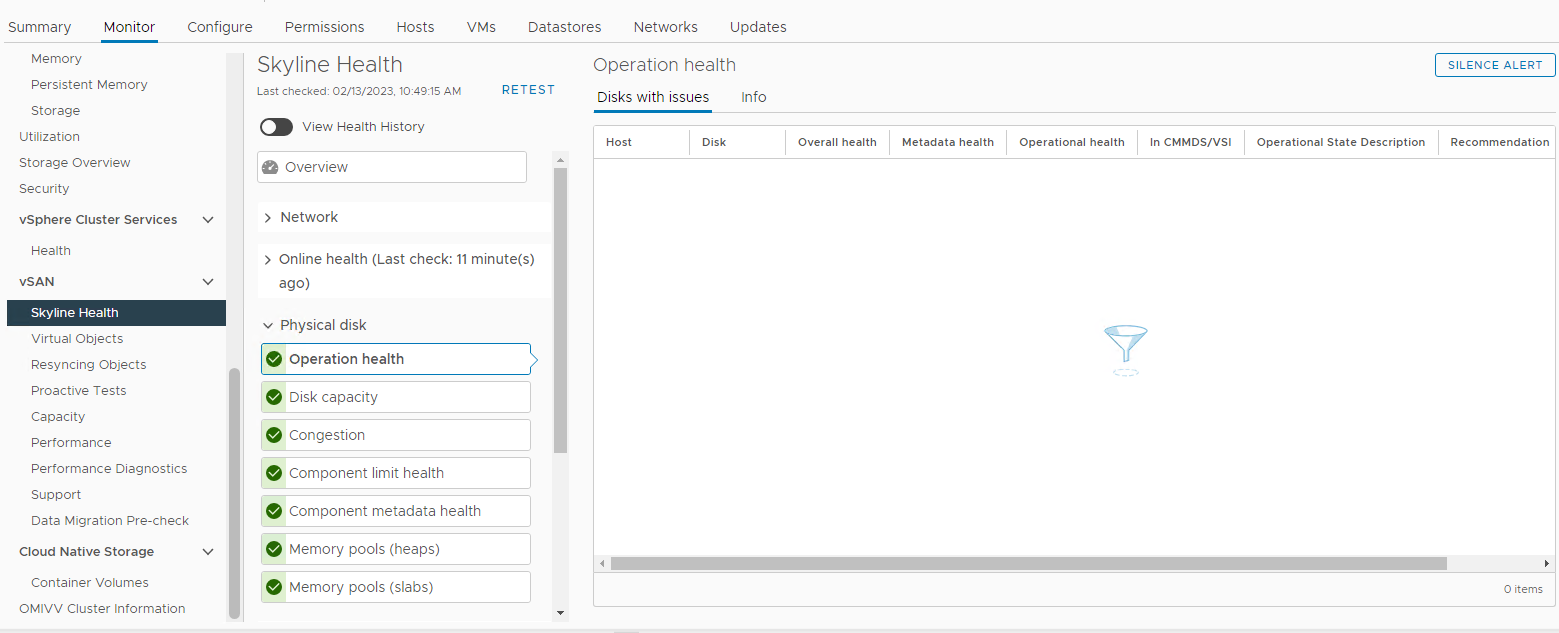
Hier kunt u controleren of een van de volgende alarmen is geactiveerd:
Impending permanent disk failure, data is being evacuated (Health state - Yellow).
Impending permanent disk failure, data evacuation failed due to insufficient resources (Health state - Red).
Impending permanent disk failure, data evacuation failed due to inaccessible objects (Health state - Red).
Impending permanent disk failure, data evacuation completed (Health state - Yellow)
U kunt ook de schijfstatus controleren in de lijst met opslagapparaten van de betreffende host:
Inventaris > Host en clusters > Betrokken vSAN-cluster > Host vSAN ESXi-host > storage-apparaten configureren Afbeelding > 4:>
Weergave
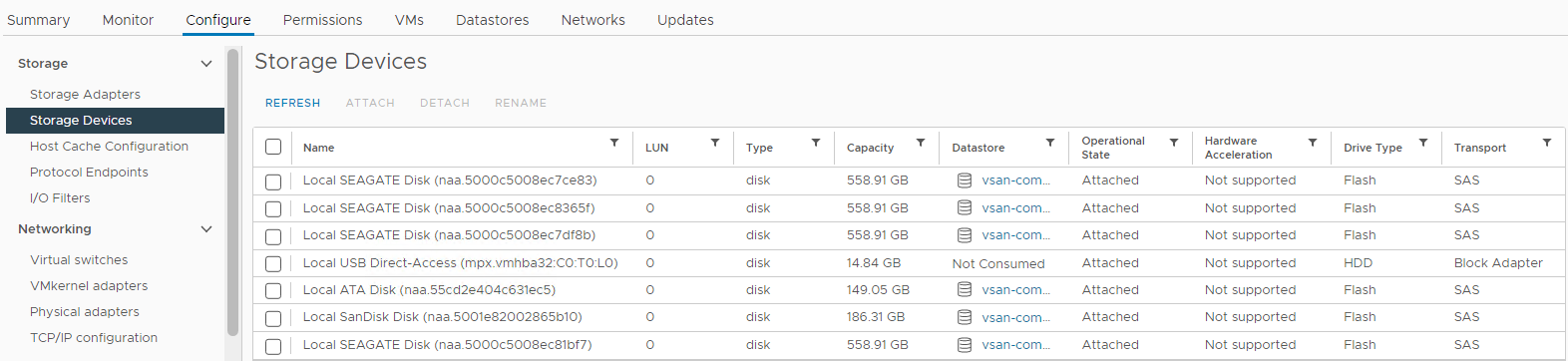
hoststorageapparaten Hier kunt u controleren of de status van een schijf is:
0 Capaciteit
Schijf afwezig
Schijf ontkoppeld
Controleer of er een hersynchronisatie plaatsvindt:
Inventaris > Host en clusters > vSAN Cluster > Monitor > vSAN > Resyncing Objects:
Afbeelding 5: Weergave Objecten opnieuw synchroniseren
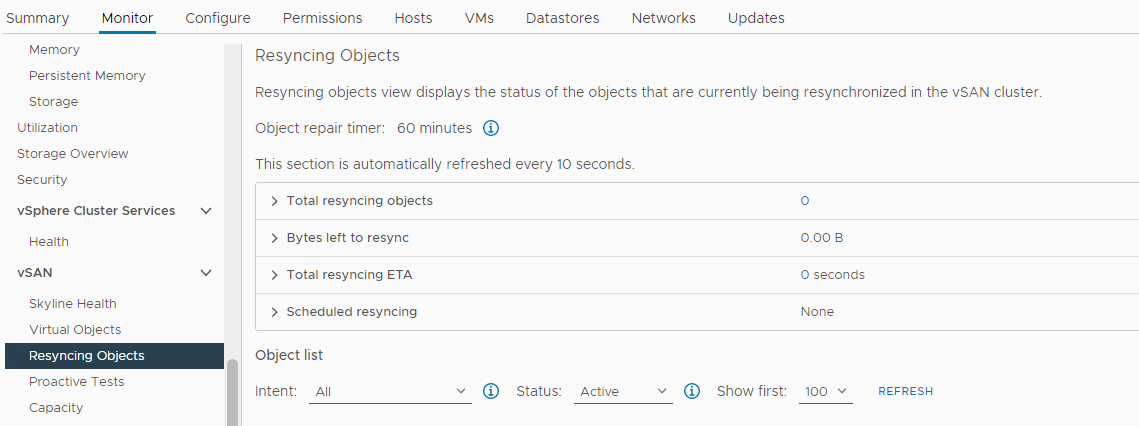
Controleer de status van vSAN-objecten:
Inventaris > Host en clusters vSAN-clustermonitor >> vSAN > Skyline-statusgegevens >> VSAN-objectstatus Afbeelding 6: weergave vSAN-objectstatus >
De volgende stap is het verzamelen van meer informatie over het probleem via CLI en het controleren van de logboeken:
Controleren op vSAN fysieke schijfstatus van CLI:
Verbinden via SSH met de getroffen host en de volgende opdrachten uitvoeren:
vdq -qH
Vink de "IsPDL" (permanent apparaatverlies) parameter. Als het gelijk is aan 1, gaat de schijf verloren.
Voorbeeld:
DiskResults:
DiskResult[0]:
Name: naa.600508b1001c4b820b4d80f9f8acfa95
VSANUUID: 5294bbd8-67c4-c545-3952-7711e365f7fa
State: In-use for VSAN
ChecksumSupport: 0
Reason: Non-local disk
IsSSD?: 0
IsCapacityFlash?: 0
IsPDL?: 0
<<truncated>>
DiskResult[18]:
Name:
VSANUUID: 5227c17e-ec64-de76-c10e-c272102beba7
State: In-use for VSAN
ChecksumSupport: 0
Reason: None
IsSSD?: 0
IsCapacityFlash?: 0
IsPDL?: 1
vdq -iH
Controleer of er een schijf ontbreekt in de schijfgroep.
Voorbeeld:
Mappings: DiskMapping[0]: SSD: naa.58ce38ee2016ffe5 MD: naa.5002538a4819e3e0 DiskMapping[2]: SSD: naa.58ce38ee2016fe55 MD: naa.5002538a48199ca0 MD: naa.5002538a48199e20 MD: naa.5002538a48199e00
esxcli vsan storage list
Controleer de "In CMMDS" parameter. Als dit niet het geval is, gaat de communicatie verloren op schijf.
Voorbeeld:
Device: Unknown
Display Name: Unknown
Is SSD: false
VSAN UUID: 529cadbc-acd1-b588-8643-68336d5512d6
VSAN Disk Group UUID:
VSAN Disk Group Name:
Used by this host: false
In CMMDS: false
On-disk format version: <Unknown>
Deduplication: false
Compression: false
Checksum:
Checksum OK: false
Is Capacity Tier: false
for i in `esxcli storage core device list | grep ^naa` ; do echo $i; esxcli storage core device smart get -d $i; done.
Controleer op lees-/schrijffouten met de smart get-opdracht.
Voorbeeld:
naa.55cd2e404c1f35a1 Parameter Value Threshold Worst Raw -------------------------- ----- --------- ----- --- Health Status OK N/A N/A N/A Media Wearout Indicator 100 0 100 86 Read Error Count 130 39 130 133 Power-on Hours 100 0 100 110 Power Cycle Count 100 0 100 106 Drive Temperature 100 0 100 26 Uncorrectable Sector Count 100 0 100 0
naa.55cd2e404c1f35a5 Parameter Value Threshold Worst Raw -------------------------- ----- --------- ----- --- Health Status OK N/A N/A N/A Media Wearout Indicator 100 0 100 10 Read Error Count 130 39 130 53 Power-on Hours 100 0 100 110 Power Cycle Count 100 0 100 106 Drive Temperature 100 0 100 27 Uncorrectable Sector Count 100 0 100 0
esxcli vsan storage list | grep "VSAN Disk Group UUID:" | sort | uniq -c
Controleer of er schijfgroepen beschikbaar zijn.
Voorbeeld:
2 VSAN Disk Group UUID: 5203424c-ee56-497d-75d1-fcf73ae997cb 2 VSAN Disk Group UUID: 52af8e5c-77d1-b552-3310-ec5fef09edf4
while true;do echo " ****************************************** "; echo "" > /tmp/resyncStats.txt ;cmmds-tool find -t DOM_OBJECT -f json |grep uuid |awk -F \" '{print $4}' |while read i;do pendingResync=$(cmmds-tool find -t DOM_OBJECT -f json -u $i|grep -o "\"bytesToSync\": [0-9]*,"|awk -F " |," '{sum+=$2} END{print sum / 1024 / 1024 / 1024;}');if [ ${#pendingResync} -ne 1 ]; then echo "$i: $pendingResync GiB";fi;done |tee -a /tmp/resyncStats.txt;total=$(cat /tmp/resyncStats.txt |awk '{sum+=$2} END{print sum}');echo "Total: $total GiB" |tee -aa /tmp/resyncStats.txt;total=$(cat /tmp/resyncStats.txt |grep Total);totalObj=$(cat /tmp/resyncStats.txt|grep -vE " 0 GiB|Total"|wc -l);echo "`date +%Y-%m-%dT%H:%M:%SZ` $total ($totalObj objects)" >> /tmp/totalHistory.txt; echo `date `; sleep 60; done
Controleer of er bewerkingen voor hersynchronisatie aan de gang zijn of zijn vastgelopen.
Voorbeeld:
Total: 0 GiB Mon Feb 13 17:32:06 UTC 2023
Druk op Ctrl+C om de opdracht te stoppen.
cmmds-tool find -f python | grep CONFIG_STATUS -B 4 -A 6 | grep 'uuid\|content' | grep -o 'state\\\":\ [0-9]*' | sort | uniq -c
Controleer de staat van de componenten.
Healthy -- state 7
Inaccessible -- state 13
Absent or Degraded -- state 15
Voorbeeld:
425 state\": 7
De locatie van de defecte SSD of HARDE SCHIJF identificeren via de CLI:
Maak een lijst van alle beschikbare apparaten:
esxcli storage core device list | grep "naa" | awk '{print $1}' | grep "naa"
Voorbeeld:
naa.5000c500852df8d3 naa.55cd2e404c1f35a1 naa.55cd2e404c1f35a5 naa.5000c500852dd5e7
Controleer de locatie met behulp van elke schijf naa uit de lijst:
esxcli storage core device physical get -d
Voorbeeld:
esxcli storage core device physical get -d naa.5000c500852df8d3 esxcli storage core device physical get -d naa.55cd2e404c1f35a1 esxcli storage core device physical get -d naa.55cd2e404c1f35a5 esxcli storage core device physical get -d naa.5000c500852dd5e7 Physical Location: enclosure 65535 slot 0 Physical Location: enclosure 65535 slot 1 Physical Location: enclosure 65535 slot 2 Physical Location: enclosure 65535 slot 3
De defecte HARDE SCHIJF of SSD identificeren als de apparaatnaam ontbreekt:
Het is mogelijk dat de defecte schijf niet wordt gedetecteerd en niet kan worden geïdentificeerd met behulp van de bijbehorende naa. In dit scenario is het nodig om alle schijven te lokaliseren en de schijf die niet fysiek is gelokaliseerd, is de schijf die defect is.
Hier is een script dat kan worden gebruikt om de taak iets sneller uit te voeren:
echo "=============Physical disks placement=============="
echo ""
esxcli storage core device list | grep "naa" | awk '{print $1}' | grep "naa" | while read in; do
echo "$in"
esxcli storage core device physical get -d "$in"
sleep 1
echo "===================================================="
done
Relevante vSAN-logboeken voor storagegerelateerde problemen:
/var/log/vmkernel.log
Problemen met lezen en schrijven naar vSAN-schijven, vSAN-hosthartslagen, PDL's, SCSI-sensecodes en I/O-aanvragen (lezen/schrijven) en clusterlidmaatschapsinformatie.
Voorbeeld:
2021-06-22T12:02:08.408Z cpu30:1001397101)ScsiDeviceIO: PsaScsiDeviceTimeoutHandlerFn:12834: TaskMgmt op to cancel IO succeeded for device naa.55cd2e404b7736d0 and the IO did not complete. WorldId 0, Cmd 0x28, CmdSN = 0x428.Cancelling of IO will be 2021-06-22T12:02:08.408Z cpu30:1001397101)retried.
/var/log/vobd.log
Rapporten over de status van de schijf, permanent verloren schijven (PDL's), schijflatentie en rapporten over wanneer een host de onderhoudsmodus activeert en afsluit.
Voorbeeld:
2022-05-31T11:42:46.065Z: [vSANCorrelator] 10605891965954us: [vob.vsan.lsom.devicerepair] vSAN device 521a74ce-c980-c16c-ff3d-38a036233daf is being repaired due to I/O failures, and will be out of service until the repair is complete. If the device is part of a dedup disk group, the entire disk group will be out of service until the repair is complete. 2022-05-31T11:42:46.065Z: [vSANCorrelator] 10606062774178us: [esx.problem.vob.vsan.lsom.devicerepair] Device 521a74ce-c980-c16c-ff3d-38a036233daf is in offline state and is getting repaired
/var/log/vsandevicemonitord.log
Hiermee kunt u bepalen of de schijf als ongezond is gemarkeerd vanwege overmatige overbelasting van logboeken of I/O-latentie.
Voorbeeld:
INFO vsandevicemonitord WARNING - WRITE Average Latency on VSAN device naa.50000xxxxxxxx has exceeded threshold value 2000000 us 2 times. INFO vsandevicemonitord Tier 2 (naa.50000xxxxxxxx) as unhealthy
Additional Information
Bekijk deze video:
VMware: Probleemoplossingsgids voor vSAN fysieke schijven
Duur: 00:10:19 (uu:mm:ss)
Indien beschikbaar kunnen de taalinstellingen voor ondertiteling (ondertiteling) worden gekozen met behulp van het CC-pictogram in deze videospeler.
Je kunt deze video ook bekijken op YouTube.