VMware: feilsøkingsveiledning for fysiske vSAN-disker
Summary: Dette er en generell feilsøkingsveiledning som hjelper deg med å identifisere om det er et problem med en fysisk disk i vSAN-klynger.
Instructions
Kontrollere status for fysisk vSAN fra webgrensesnittet:
Koble til vCenter Server Web Client, og kontroller diskstatusen fra:
Lager > Vert og klynger vSAN-klynge >> Konfigurere > vSAN > Disk Management
Bilde 1: vSAN Disk Management-visning
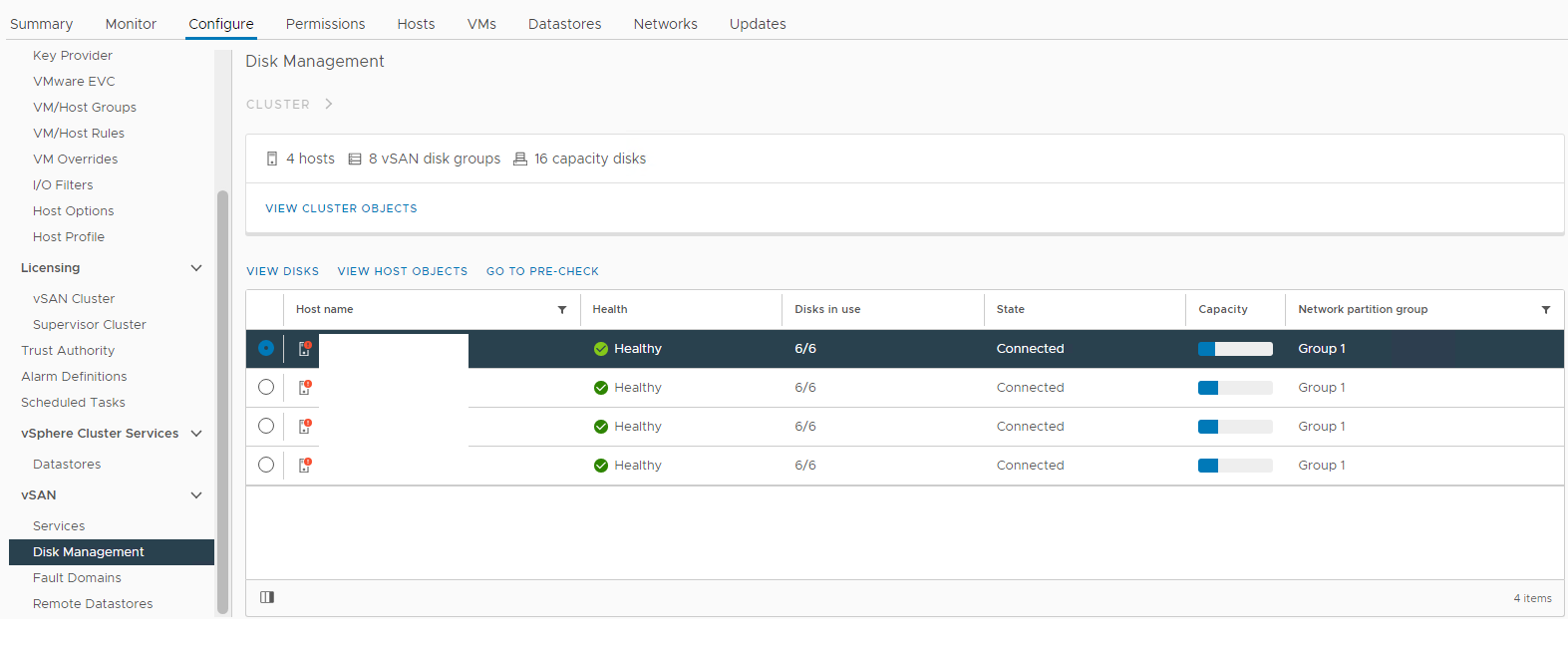 Velg den berørte verten, og utvid deretter visningsdiskdelen:
Velg den berørte verten, og utvid deretter visningsdiskdelen:
Bilde 2: vSAN Disk Group-visning
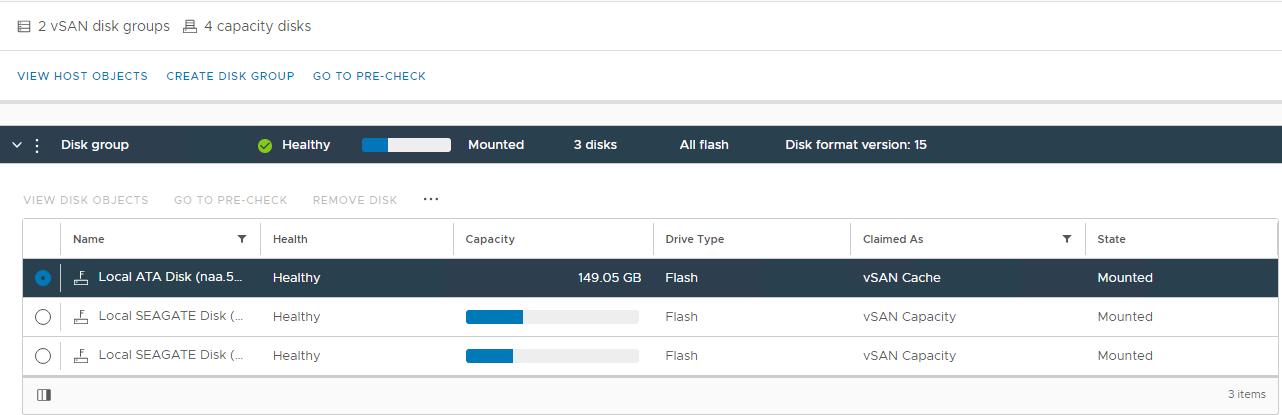
Her kan du kontrollere om en disk oppdages som:
Usunn
Umontert
0 kapasitet
Permanent diskfeil
Disk ned
disk fraværende
Se også etter diskrelaterte alarmer som utløses fra vSAN Skyline Health-delen:
Lager > Vert og klynger > vSAN Cluster > Monitor > vSAN > Skyline Health > Fysisk disk
Bilde 3: Skyline Health-visning
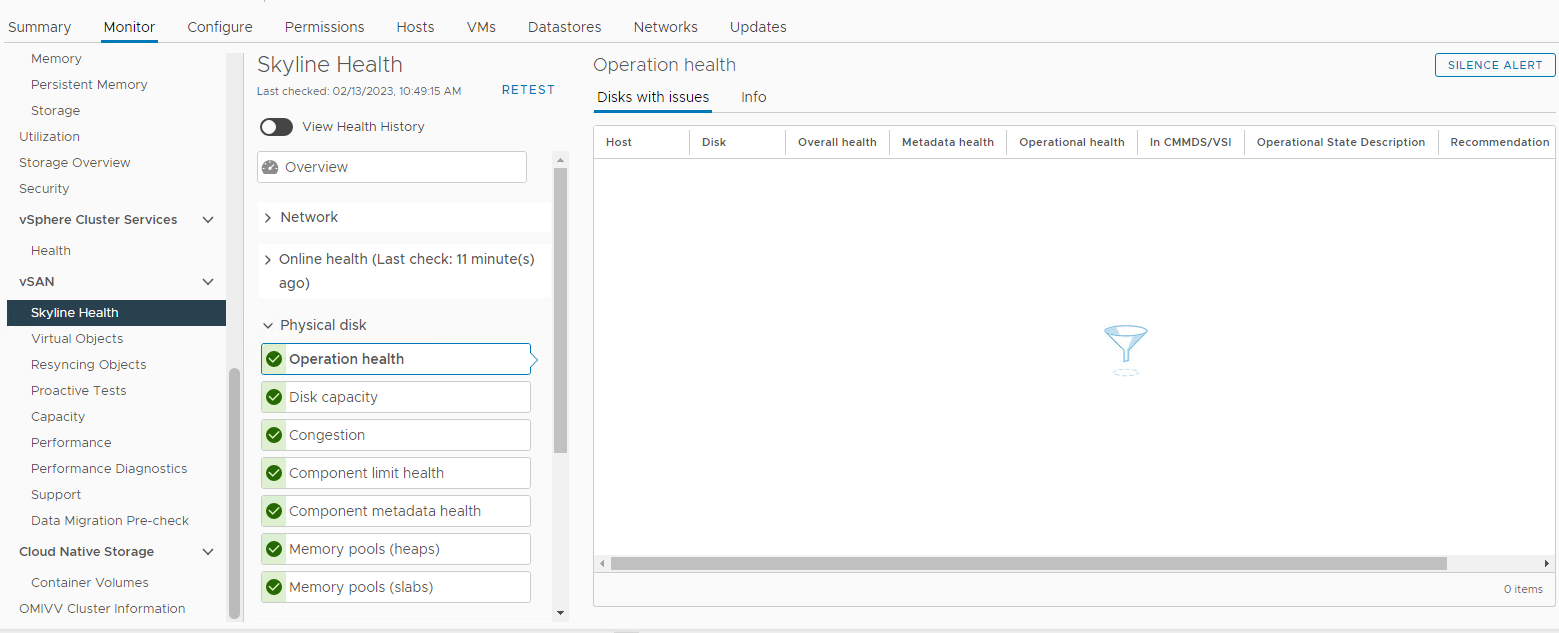
Her kan du kontrollere om noen av følgende alarmer utløses:
Impending permanent disk failure, data is being evacuated (Health state - Yellow).
Impending permanent disk failure, data evacuation failed due to insufficient resources (Health state - Red).
Impending permanent disk failure, data evacuation failed due to inaccessible objects (Health state - Red).
Impending permanent disk failure, data evacuation completed (Health state - Yellow)
Du kan også sjekke diskstatus fra listen over lagringsenheter på den berørte verten:
Lager > Vert og klynger vSAN-klynge >> berørt vSAN ESXi-vert > Konfigurere > lagringslagringsenheter >
Bilde 4: Visning
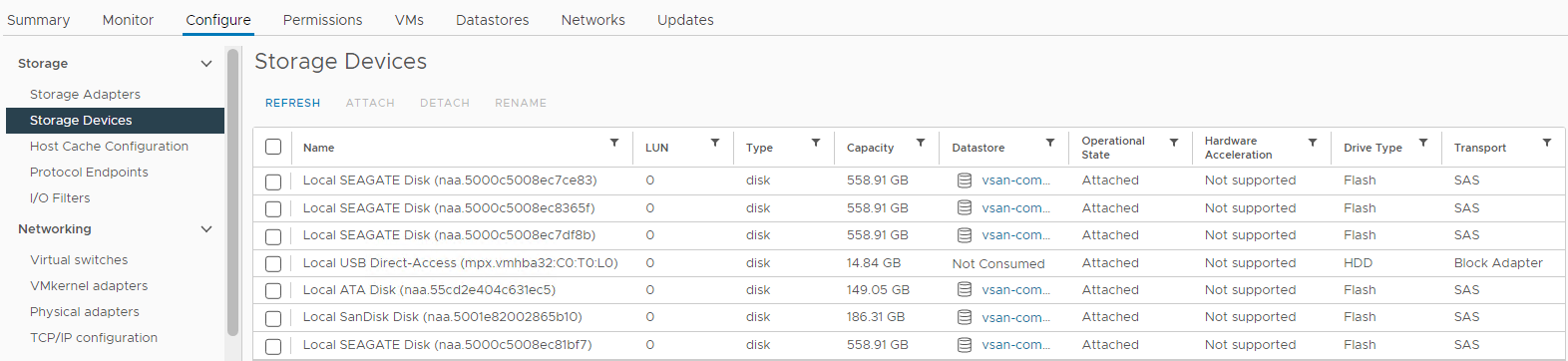
av vertslagringsenheter Her kan du kontrollere om diskstatusen er:
0 Kapasitet
Disk fraværende
disk umontert
Bekreft om det er en Resync skjer:
Lager > Vert og klynger > vSAN Cluster > Monitor > vSAN > Resyncing Objects:
Bilde 5: Visning av nye synkroniseringsobjekter
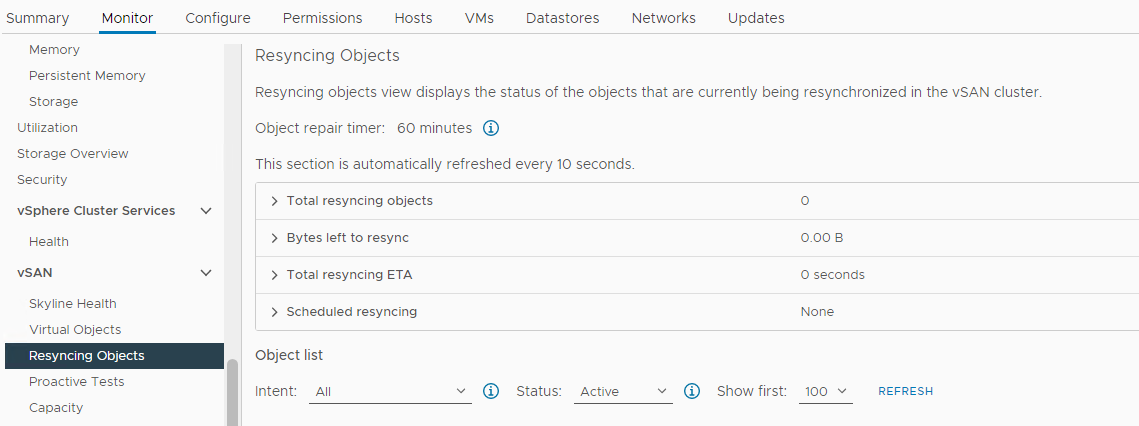
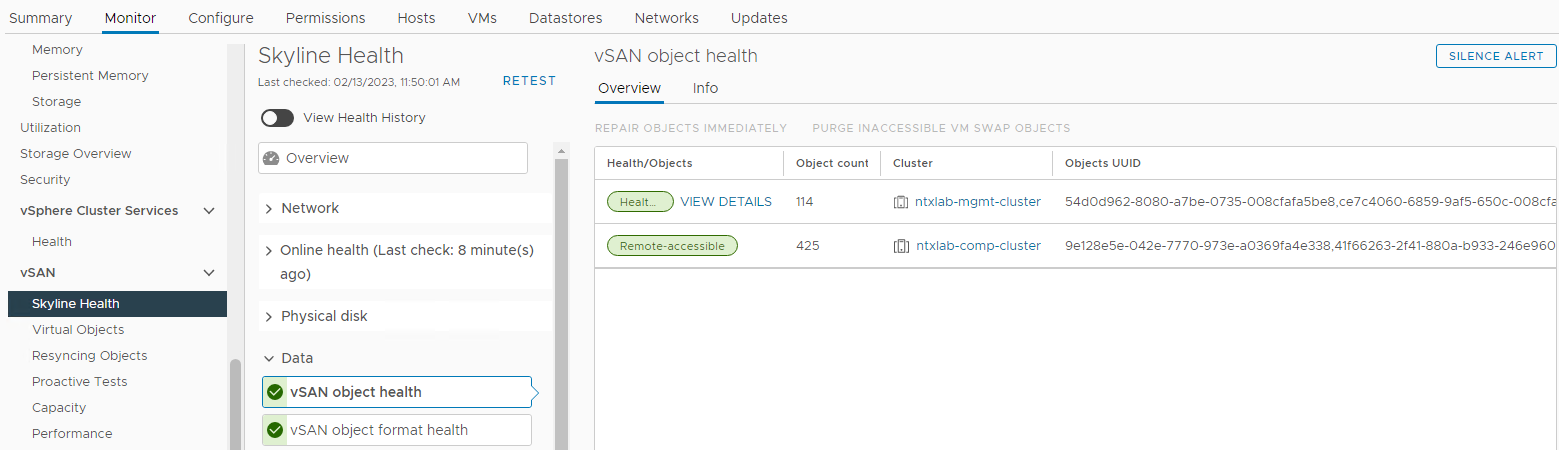
Bekreft statusen til vSAN Objects:
Lager > Vert og klynger vSAN Cluster > Monitor > vSAN > Skyline Health > Data vSAN object health > Bilde 6: vSAN-objekttilstandsvisning >
Det neste trinnet er å samle inn mer informasjon om problemet via CLI og kontrollere loggene:
Kontrollere status for fysisk vSAN fra CLI:
Connect over SSH til den berørte verten, og kjøre følgende kommandoer:
vdq -qH
Sjekk på "IsPDL" (permanent enhetstap) parameter. Hvis det er lik 1, går disken tapt.
Eksempel:
DiskResults:
DiskResult[0]:
Name: naa.600508b1001c4b820b4d80f9f8acfa95
VSANUUID: 5294bbd8-67c4-c545-3952-7711e365f7fa
State: In-use for VSAN
ChecksumSupport: 0
Reason: Non-local disk
IsSSD?: 0
IsCapacityFlash?: 0
IsPDL?: 0
<<truncated>>
DiskResult[18]:
Name:
VSANUUID: 5227c17e-ec64-de76-c10e-c272102beba7
State: In-use for VSAN
ChecksumSupport: 0
Reason: None
IsSSD?: 0
IsCapacityFlash?: 0
IsPDL?: 1
vdq -iH
Kontroller om det mangler en disk fra diskgruppen.
Eksempel:
Mappings: DiskMapping[0]: SSD: naa.58ce38ee2016ffe5 MD: naa.5002538a4819e3e0 DiskMapping[2]: SSD: naa.58ce38ee2016fe55 MD: naa.5002538a48199ca0 MD: naa.5002538a48199e20 MD: naa.5002538a48199e00
esxcli vsan storage list
Sjekk på "In CMMDS" parameter. Hvis falsk, går kommunikasjonen tapt til disken.
Eksempel:
Device: Unknown
Display Name: Unknown
Is SSD: false
VSAN UUID: 529cadbc-acd1-b588-8643-68336d5512d6
VSAN Disk Group UUID:
VSAN Disk Group Name:
Used by this host: false
In CMMDS: false
On-disk format version: <Unknown>
Deduplication: false
Compression: false
Checksum:
Checksum OK: false
Is Capacity Tier: false
for i in `esxcli storage core device list | grep ^naa` ; do echo $i; esxcli storage core device smart get -d $i; done.
Se etter lese-/skrivefeil med Smart Get-kommandoen.
Eksempel:
naa.55cd2e404c1f35a1 Parameter Value Threshold Worst Raw -------------------------- ----- --------- ----- --- Health Status OK N/A N/A N/A Media Wearout Indicator 100 0 100 86 Read Error Count 130 39 130 133 Power-on Hours 100 0 100 110 Power Cycle Count 100 0 100 106 Drive Temperature 100 0 100 26 Uncorrectable Sector Count 100 0 100 0
naa.55cd2e404c1f35a5 Parameter Value Threshold Worst Raw -------------------------- ----- --------- ----- --- Health Status OK N/A N/A N/A Media Wearout Indicator 100 0 100 10 Read Error Count 130 39 130 53 Power-on Hours 100 0 100 110 Power Cycle Count 100 0 100 106 Drive Temperature 100 0 100 27 Uncorrectable Sector Count 100 0 100 0
esxcli vsan storage list | grep "VSAN Disk Group UUID:" | sort | uniq -c
Se etter tilgjengelige diskgrupper.
Eksempel:
2 VSAN Disk Group UUID: 5203424c-ee56-497d-75d1-fcf73ae997cb 2 VSAN Disk Group UUID: 52af8e5c-77d1-b552-3310-ec5fef09edf4
while true;do echo " ****************************************** "; echo "" > /tmp/resyncStats.txt ;cmmds-tool find -t DOM_OBJECT -f json |grep uuid |awk -F \" '{print $4}' |while read i;do pendingResync=$(cmmds-tool find -t DOM_OBJECT -f json -u $i|grep -o "\"bytesToSync\": [0-9]*,"|awk -F " |," '{sum+=$2} END{print sum / 1024 / 1024 / 1024;}');if [ ${#pendingResync} -ne 1 ]; then echo "$i: $pendingResync GiB";fi;done |tee -a /tmp/resyncStats.txt;total=$(cat /tmp/resyncStats.txt |awk '{sum+=$2} END{print sum}');echo "Total: $total GiB" |tee -aa /tmp/resyncStats.txt;total=$(cat /tmp/resyncStats.txt |grep Total);totalObj=$(cat /tmp/resyncStats.txt|grep -vE " 0 GiB|Total"|wc -l);echo "`date +%Y-%m-%dT%H:%M:%SZ` $total ($totalObj objects)" >> /tmp/totalHistory.txt; echo `date `; sleep 60; done
Sjekk om det er pågående eller stopper resynkroniseringsoperasjoner.
Eksempel:
Total: 0 GiB Mon Feb 13 17:32:06 UTC 2023
Trykk CTRL+C for å stoppe kommandoen.
cmmds-tool find -f python | grep CONFIG_STATUS -B 4 -A 6 | grep 'uuid\|content' | grep -o 'state\\\":\ [0-9]*' | sort | uniq -c
Kontroller tilstanden til komponentene.
Healthy -- state 7
Inaccessible -- state 13
Absent or Degraded -- state 15
Eksempel:
425 state\": 7
Slik identifiserer du hvor den defekte SSD eller harddisken er plassert over CLI:
Liste over alle tilgjengelige enheter:
esxcli storage core device list | grep "naa" | awk '{print $1}' | grep "naa"
Eksempel:
naa.5000c500852df8d3 naa.55cd2e404c1f35a1 naa.55cd2e404c1f35a5 naa.5000c500852dd5e7
Kontroller plasseringen ved hjelp av hver disk naa fra listen:
esxcli storage core device physical get -d
Eksempel:
esxcli storage core device physical get -d naa.5000c500852df8d3 esxcli storage core device physical get -d naa.55cd2e404c1f35a1 esxcli storage core device physical get -d naa.55cd2e404c1f35a5 esxcli storage core device physical get -d naa.5000c500852dd5e7 Physical Location: enclosure 65535 slot 0 Physical Location: enclosure 65535 slot 1 Physical Location: enclosure 65535 slot 2 Physical Location: enclosure 65535 slot 3
Slik identifiserer du den defekte HARDDISKEN eller SSD-en hvis enhetsnavnet mangler:
Det er mulig at den defekte disken ikke oppdages og ikke kan identifiseres ved hjelp av tilsvarende naa. I dette scenariet er det nødvendig å finne alle disker, og den som ikke er fysisk plassert, vil være den som mislyktes.
Her er et skript som kan brukes til å utføre oppgaven litt raskere:
echo "=============Physical disks placement=============="
echo ""
esxcli storage core device list | grep "naa" | awk '{print $1}' | grep "naa" | while read in; do
echo "$in"
esxcli storage core device physical get -d "$in"
sleep 1
echo "===================================================="
done
vSAN relevante logger for lagringsrelaterte problemer:
/var/log/vmkernel.log
Problemer med lesing og skriving til vSAN-disker, vSAN-verthjerteslag, PDL-er, SCSI-sensorkoder og I/O-forespørsler (lese/skrive) og informasjon om klyngemedlemskap.
Eksempel:
2021-06-22T12:02:08.408Z cpu30:1001397101)ScsiDeviceIO: PsaScsiDeviceTimeoutHandlerFn:12834: TaskMgmt op to cancel IO succeeded for device naa.55cd2e404b7736d0 and the IO did not complete. WorldId 0, Cmd 0x28, CmdSN = 0x428.Cancelling of IO will be 2021-06-22T12:02:08.408Z cpu30:1001397101)retried.
/var/log/vobd.log
Rapporter om disktilstand, permanente enhetstapte disker (PDL-er), diskventetid og rapporter om når en vert går inn i og avslutter vedlikeholdsmodus.
Eksempel:
2022-05-31T11:42:46.065Z: [vSANCorrelator] 10605891965954us: [vob.vsan.lsom.devicerepair] vSAN device 521a74ce-c980-c16c-ff3d-38a036233daf is being repaired due to I/O failures, and will be out of service until the repair is complete. If the device is part of a dedup disk group, the entire disk group will be out of service until the repair is complete. 2022-05-31T11:42:46.065Z: [vSANCorrelator] 10606062774178us: [esx.problem.vob.vsan.lsom.devicerepair] Device 521a74ce-c980-c16c-ff3d-38a036233daf is in offline state and is getting repaired
/var/log/vsandevicemonitord.log
Det hjelper deg med å finne ut om disken ble merket som usunn på grunn av overdreven overbelastning av loggen eller I/O-ventetider.
Eksempel:
INFO vsandevicemonitord WARNING - WRITE Average Latency on VSAN device naa.50000xxxxxxxx has exceeded threshold value 2000000 us 2 times. INFO vsandevicemonitord Tier 2 (naa.50000xxxxxxxx) as unhealthy
Additional Information
Se denne videoen:
VMware: feilsøkingsveiledning for fysiske vSAN-disker
Varighet: 00:10:19 (hh:mm:ss)
Når språkinnstillingene for teksting (undertekster) er tilgjengelige, kan du velge ved hjelp av CC-ikonet på denne videospilleren.
Du kan også se denne videoen på YouTube.