VMware: Guia de solução de problemas do disco físico do vSAN
Summary: Este é um guia geral de solução de problemas para ajudar a identificar se há um problema com um disco físico em clusters do vSAN.
Instructions
Verificando o status do disco físico do vSAN na IU da Web:
Conecte-se ao vCenter Server Web Client e verifique o status do disco em:
Inventário > Host e clusters Cluster do vSAN Configurar > o gerenciamento de discos do vSAN > Figura 1: exibição do vSAN Disk Management Selecione o host afetado e, em seguida, expanda a seção de exibição de discos:Figura 2: exibição do grupo de discos do vSAN Aqui você pode verificar se um disco é detectado como:>>
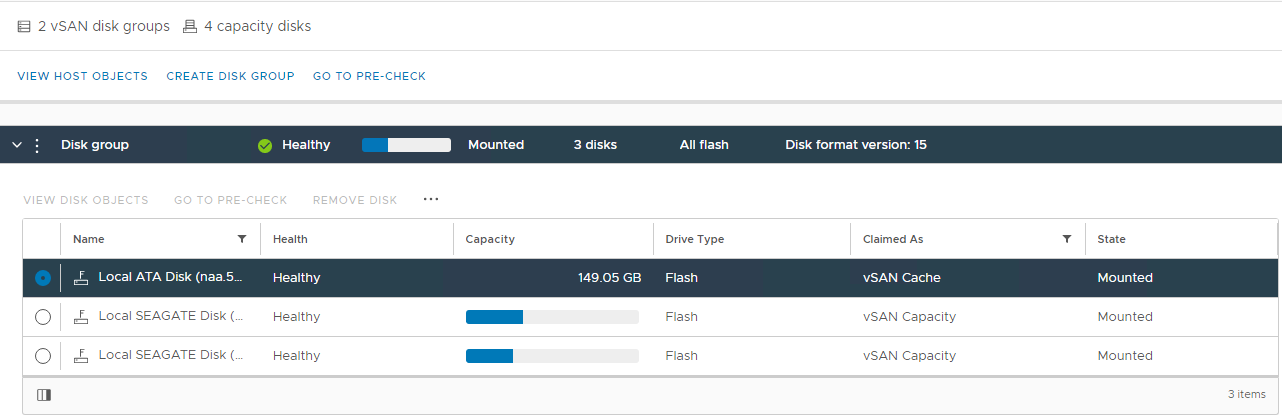
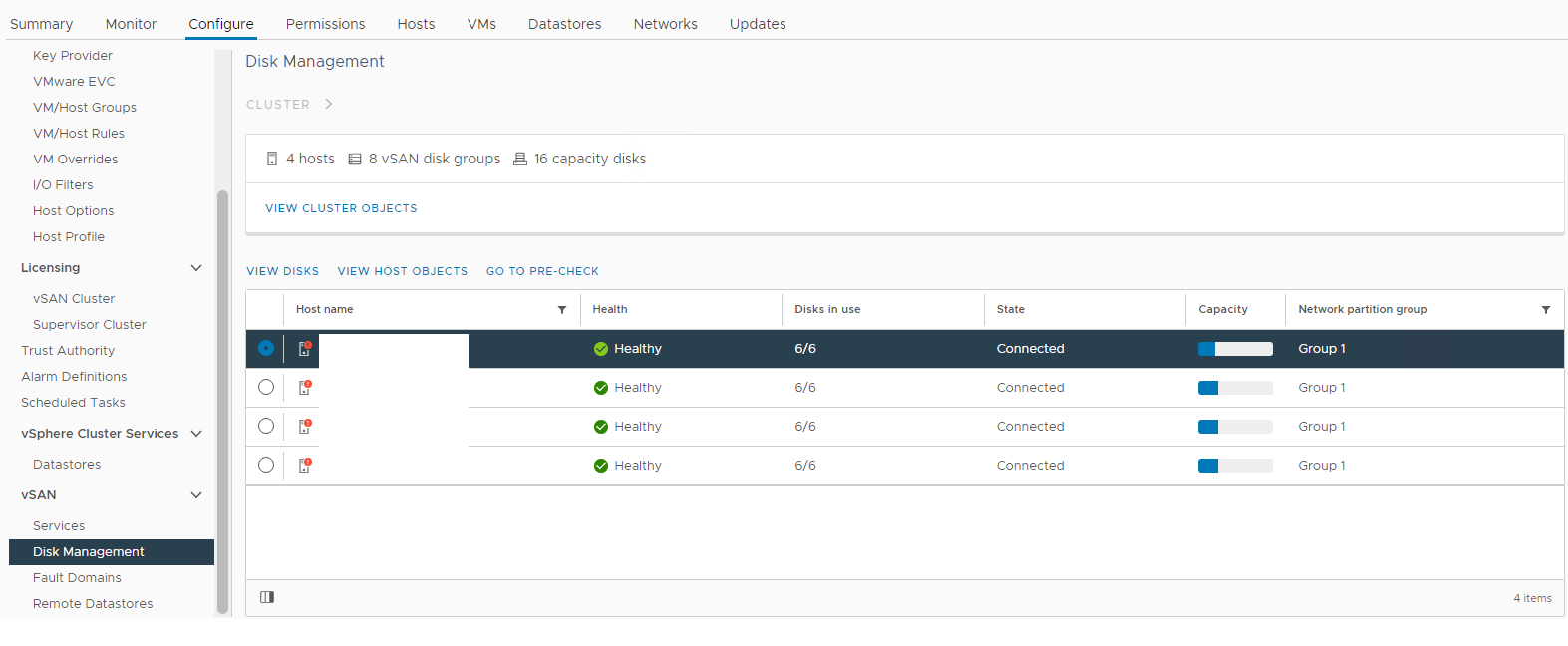
Unhealthy
Desmontado
0 Capacidade
Falha permanente do disco Disco
inativo Disco ausente
Além disso, verifique se há alarmes relacionados ao disco disparados na seção vSAN Skyline Health:
Inventário > Host e clusters Monitorar o cluster > do vSAN Integridade do horizonte do > vSAN > Imagem 3:>>
Visualização
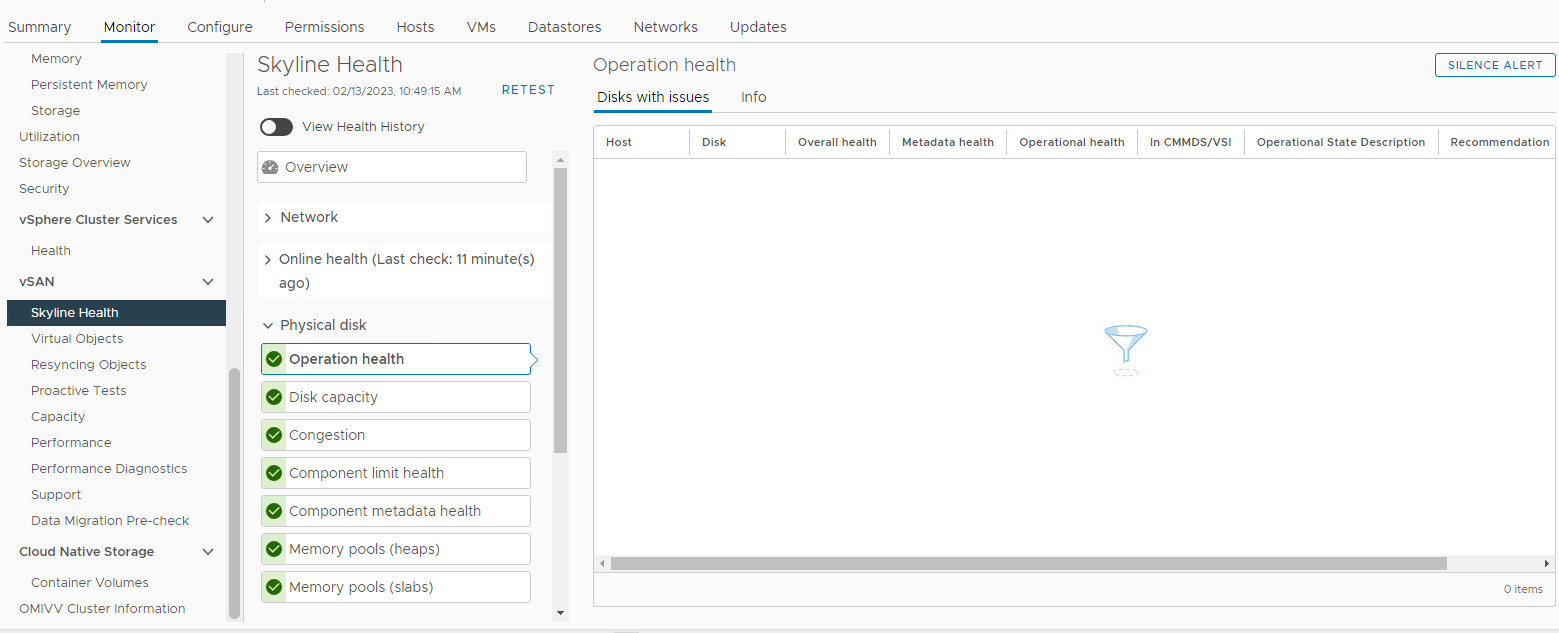
da integridade do horizonte Aqui, você pode verificar se algum dos alarmes a seguir foi acionado:
Impending permanent disk failure, data is being evacuated (Health state - Yellow).
Impending permanent disk failure, data evacuation failed due to insufficient resources (Health state - Red).
Impending permanent disk failure, data evacuation failed due to inaccessible objects (Health state - Red).
Impending permanent disk failure, data evacuation completed (Health state - Yellow)
Além disso, você pode verificar o status do disco na lista de dispositivos de armazenamento do host afetado:
Inventário > Host e clusters > Cluster do vSAN afetado pelo host > do ESXi do vSAN Configurar > dispositivos de armazenamento de armazenamento > Figura >4:
Visualização
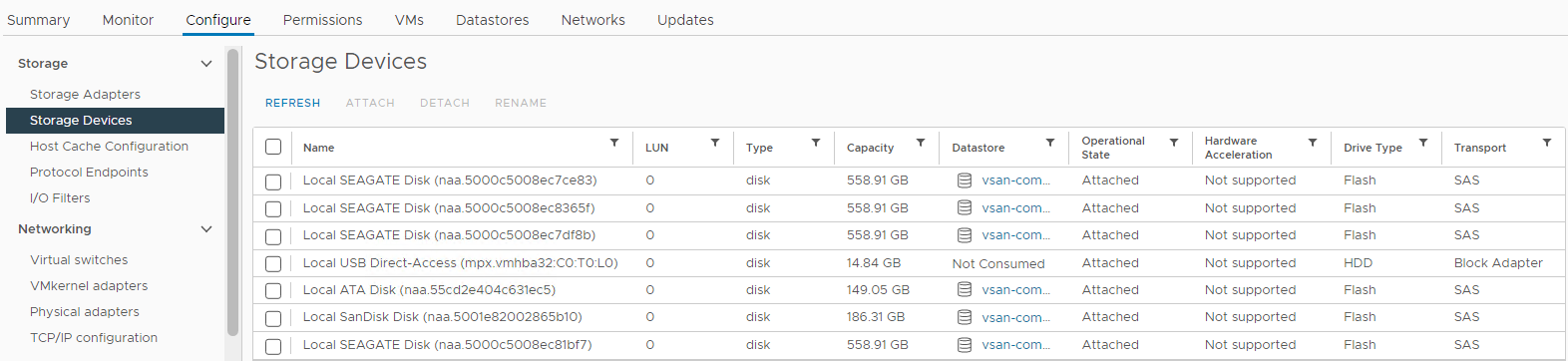
de dispositivos de armazenamento do host Aqui, você pode verificar se o status de um disco é:
0 disco ausente
de capacidade
disco desmontado
Verifique se há uma ressincronização acontecendo:
Inventário > Host e clusters > Cluster vSAN > Monitor > vSAN > Resincronizando objetos:
Figura 5: Exibição Ressincronizando objetos
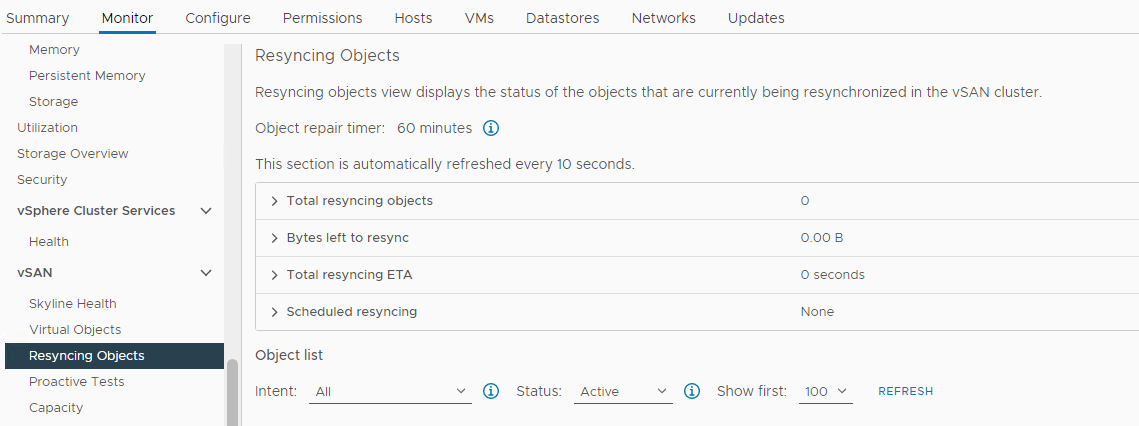
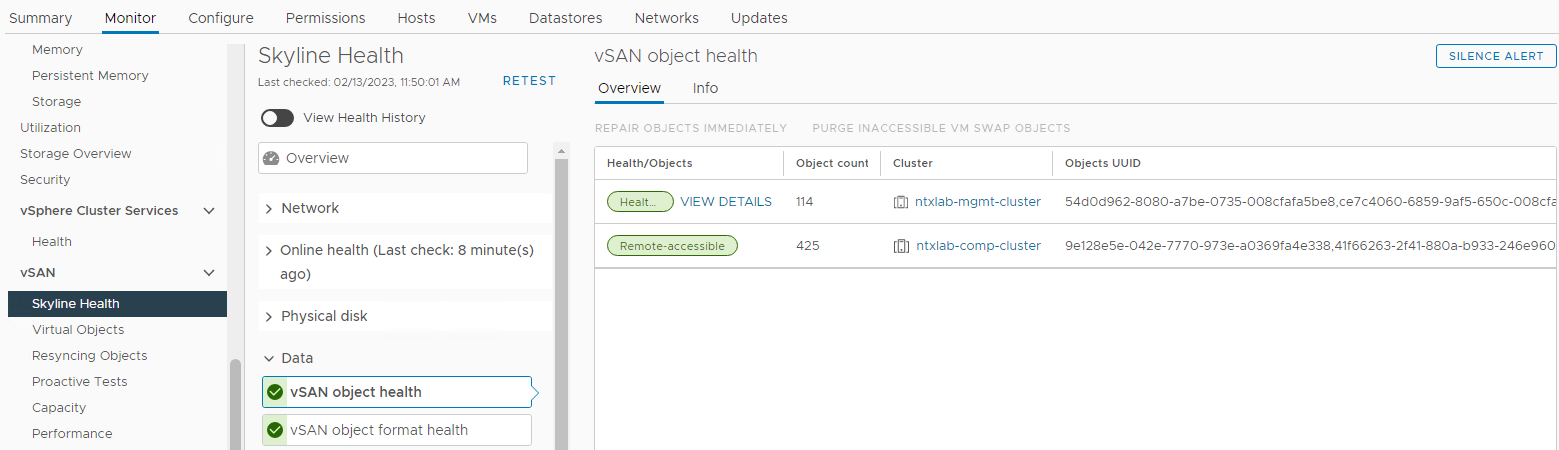
Verifique o status dos objetos vSAN:
Inventário > Host e clusters > Cluster vSAN Monitorar > dados de integridade > do horizonte do > vSAN > Integridade do objeto vSAN Figura 6: exibição da integridade do objeto >vSAN
A próxima etapa é coletar mais informações sobre o problema na CLI e verificar os logs:
Checking for vSAN Physical Disk status from CLI:
Connect over SSH to the affected host e executar os seguintes comandos:
vdq -qH
Marque o "IsPDL" (perda permanente de dispositivo) parâmetro. Se for igual a 1, o disco será perdido.
Exemplo:
DiskResults:
DiskResult[0]:
Name: naa.600508b1001c4b820b4d80f9f8acfa95
VSANUUID: 5294bbd8-67c4-c545-3952-7711e365f7fa
State: In-use for VSAN
ChecksumSupport: 0
Reason: Non-local disk
IsSSD?: 0
IsCapacityFlash?: 0
IsPDL?: 0
<<truncated>>
DiskResult[18]:
Name:
VSANUUID: 5227c17e-ec64-de76-c10e-c272102beba7
State: In-use for VSAN
ChecksumSupport: 0
Reason: None
IsSSD?: 0
IsCapacityFlash?: 0
IsPDL?: 1
vdq -iH
Verifique se há um disco ausente no grupo de discos.
Exemplo:
Mappings: DiskMapping[0]: SSD: naa.58ce38ee2016ffe5 MD: naa.5002538a4819e3e0 DiskMapping[2]: SSD: naa.58ce38ee2016fe55 MD: naa.5002538a48199ca0 MD: naa.5002538a48199e20 MD: naa.5002538a48199e00
esxcli vsan storage list
Verifique o "In CMMDS" parâmetro. Se falso, a comunicação será perdida no disco.
Exemplo:
Device: Unknown
Display Name: Unknown
Is SSD: false
VSAN UUID: 529cadbc-acd1-b588-8643-68336d5512d6
VSAN Disk Group UUID:
VSAN Disk Group Name:
Used by this host: false
In CMMDS: false
On-disk format version: <Unknown>
Deduplication: false
Compression: false
Checksum:
Checksum OK: false
Is Capacity Tier: false
for i in `esxcli storage core device list | grep ^naa` ; do echo $i; esxcli storage core device smart get -d $i; done.
Verifique se há erros de leitura/gravação com o comando smart get.
Exemplo:
naa.55cd2e404c1f35a1 Parameter Value Threshold Worst Raw -------------------------- ----- --------- ----- --- Health Status OK N/A N/A N/A Media Wearout Indicator 100 0 100 86 Read Error Count 130 39 130 133 Power-on Hours 100 0 100 110 Power Cycle Count 100 0 100 106 Drive Temperature 100 0 100 26 Uncorrectable Sector Count 100 0 100 0
naa.55cd2e404c1f35a5 Parameter Value Threshold Worst Raw -------------------------- ----- --------- ----- --- Health Status OK N/A N/A N/A Media Wearout Indicator 100 0 100 10 Read Error Count 130 39 130 53 Power-on Hours 100 0 100 110 Power Cycle Count 100 0 100 106 Drive Temperature 100 0 100 27 Uncorrectable Sector Count 100 0 100 0
esxcli vsan storage list | grep "VSAN Disk Group UUID:" | sort | uniq -c
Verifique se há grupos de discos disponíveis.
Exemplo:
2 VSAN Disk Group UUID: 5203424c-ee56-497d-75d1-fcf73ae997cb 2 VSAN Disk Group UUID: 52af8e5c-77d1-b552-3310-ec5fef09edf4
while true;do echo " ****************************************** "; echo "" > /tmp/resyncStats.txt ;cmmds-tool find -t DOM_OBJECT -f json |grep uuid |awk -F \" '{print $4}' |while read i;do pendingResync=$(cmmds-tool find -t DOM_OBJECT -f json -u $i|grep -o "\"bytesToSync\": [0-9]*,"|awk -F " |," '{sum+=$2} END{print sum / 1024 / 1024 / 1024;}');if [ ${#pendingResync} -ne 1 ]; then echo "$i: $pendingResync GiB";fi;done |tee -a /tmp/resyncStats.txt;total=$(cat /tmp/resyncStats.txt |awk '{sum+=$2} END{print sum}');echo "Total: $total GiB" |tee -aa /tmp/resyncStats.txt;total=$(cat /tmp/resyncStats.txt |grep Total);totalObj=$(cat /tmp/resyncStats.txt|grep -vE " 0 GiB|Total"|wc -l);echo "`date +%Y-%m-%dT%H:%M:%SZ` $total ($totalObj objects)" >> /tmp/totalHistory.txt; echo `date `; sleep 60; done
Verifique se há operações de ressincronização em andamento ou travadas.
Exemplo:
Total: 0 GiB Mon Feb 13 17:32:06 UTC 2023
Pressione Ctrl+C para interromper o comando.
cmmds-tool find -f python | grep CONFIG_STATUS -B 4 -A 6 | grep 'uuid\|content' | grep -o 'state\\\":\ [0-9]*' | sort | uniq -c
Verifique o estado dos componentes.
Healthy -- state 7
Inaccessible -- state 13
Absent or Degraded -- state 15
Exemplo:
425 state\": 7
Como identificar onde a SSD ou a unidade de disco rígido com falha está localizada pela CLI:
Listar todos os dispositivos disponíveis:
esxcli storage core device list | grep "naa" | awk '{print $1}' | grep "naa"
Exemplo:
naa.5000c500852df8d3 naa.55cd2e404c1f35a1 naa.55cd2e404c1f35a5 naa.5000c500852dd5e7
Verifique o local usando cada disco NAA na lista:
esxcli storage core device physical get -d
Exemplo:
esxcli storage core device physical get -d naa.5000c500852df8d3 esxcli storage core device physical get -d naa.55cd2e404c1f35a1 esxcli storage core device physical get -d naa.55cd2e404c1f35a5 esxcli storage core device physical get -d naa.5000c500852dd5e7 Physical Location: enclosure 65535 slot 0 Physical Location: enclosure 65535 slot 1 Physical Location: enclosure 65535 slot 2 Physical Location: enclosure 65535 slot 3
Como identificar o disco rígido ou SSD com falha se o nome do dispositivo estiver faltando:
É possível que o disco com falha não seja detectado e não seja possível identificá-lo usando o NAA correspondente. Nesse cenário, é necessário localizar todos os discos, e o que não está fisicamente localizado seria o que falhou.
Aqui está um script que pode ser usado para executar a tarefa um pouco mais rápido:
echo "=============Physical disks placement=============="
echo ""
esxcli storage core device list | grep "naa" | awk '{print $1}' | grep "naa" | while read in; do
echo "$in"
esxcli storage core device physical get -d "$in"
sleep 1
echo "===================================================="
done
Registros relevantes do vSAN para problemas relacionados a armazenamento:
/var/log/vmkernel.log
Problemas de leitura e gravação em discos do vSAN, heartbeats do host do vSAN, PDLs, códigos de detecção SCSI e solicitações de E/S (leituras/gravações) e informações de associação do cluster.
Exemplo:
2021-06-22T12:02:08.408Z cpu30:1001397101)ScsiDeviceIO: PsaScsiDeviceTimeoutHandlerFn:12834: TaskMgmt op to cancel IO succeeded for device naa.55cd2e404b7736d0 and the IO did not complete. WorldId 0, Cmd 0x28, CmdSN = 0x428.Cancelling of IO will be 2021-06-22T12:02:08.408Z cpu30:1001397101)retried.
/var/log/vobd.log
Relata a integridade do disco, os discos permanentes perdidos do dispositivo (PDLs), a latência do disco e informa quando um host entra e sai do modo de manutenção.
Exemplo:
2022-05-31T11:42:46.065Z: [vSANCorrelator] 10605891965954us: [vob.vsan.lsom.devicerepair] vSAN device 521a74ce-c980-c16c-ff3d-38a036233daf is being repaired due to I/O failures, and will be out of service until the repair is complete. If the device is part of a dedup disk group, the entire disk group will be out of service until the repair is complete. 2022-05-31T11:42:46.065Z: [vSANCorrelator] 10606062774178us: [esx.problem.vob.vsan.lsom.devicerepair] Device 521a74ce-c980-c16c-ff3d-38a036233daf is in offline state and is getting repaired
/var/log/vsandevicemonitord.log
Ele ajuda a determinar se o disco foi marcado como não íntegro devido ao congestionamento excessivo de logs ou latências de E/S.
Exemplo:
INFO vsandevicemonitord WARNING - WRITE Average Latency on VSAN device naa.50000xxxxxxxx has exceeded threshold value 2000000 us 2 times. INFO vsandevicemonitord Tier 2 (naa.50000xxxxxxxx) as unhealthy