VMware: vSAN Fiziksel Disk Sorun Giderme Rehberi
Summary: Bu belge, vSAN Kümelerindeki fiziksel diskle ilgili bir sorun olup olmadığını belirlemeye yardımcı olan genel bir sorun giderme rehberidir.
Instructions
Web kullanıcı arayüzünden vSAN Fiziksel Disk durumunu kontrol etme:
vCenter Server Web İstemcisine bağlanın ve disk durumunu şuradan kontrol edin:
Stok > Ana Bilgisayar ve Kümeler > vSAN Kümesi vSAN > Disk Yönetimini >>
Yapılandırma Resim 1: vSAN Disk Yönetimi görünümü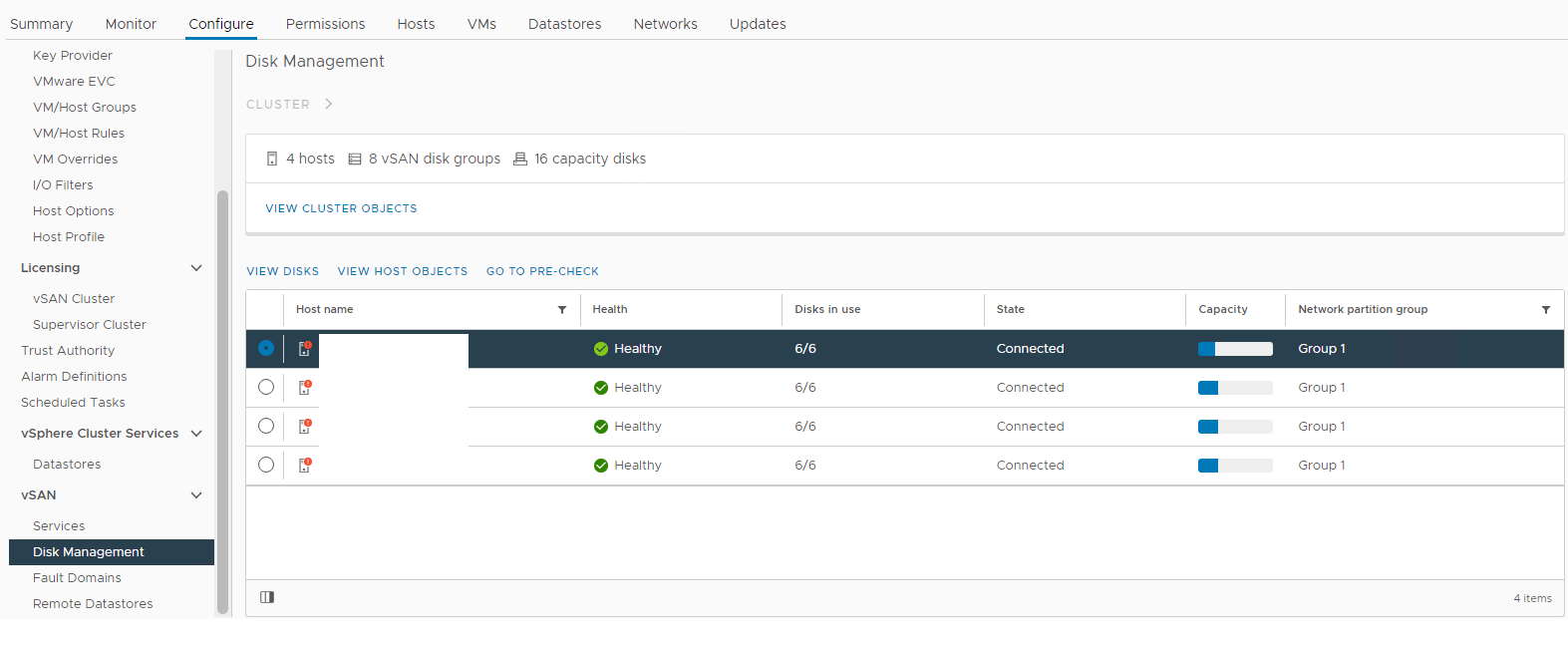
Etkilenen ana bilgisayarı seçin ve ardından disk görünümü bölümünü genişletin:
Resim 2: vSAN Disk Grubu görünümü
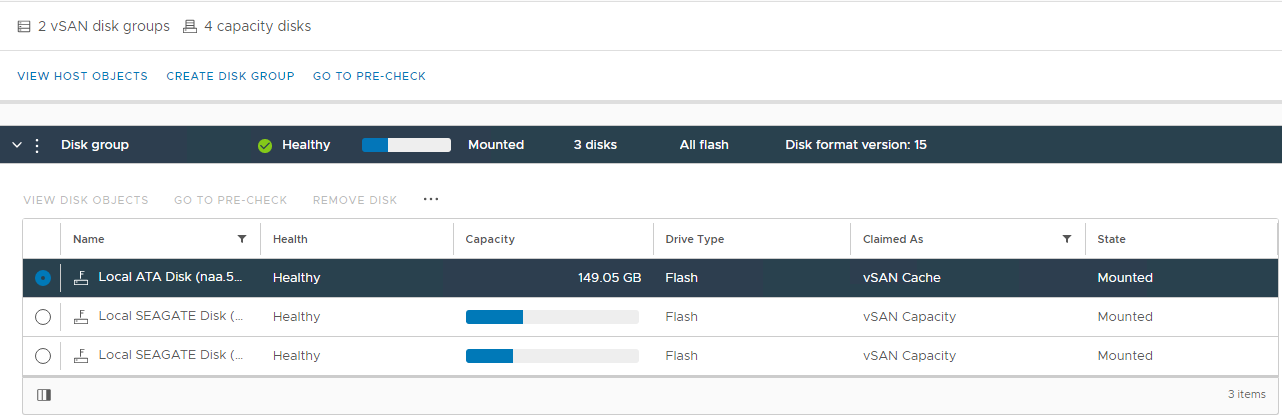
Burada bir diskin şu şekilde algılanıp algılanmadığını doğrulayabilirsiniz:
Sağlıksız
Bağlı
Değil 0 Kapasite
Kalıcı Disk Arızası Disk Kapalı
Disk Yok
Ayrıca, vSAN Skyline Health bölümünden tetiklenen diskle ilgili alarmları kontrol edin:
Stok > Ana Bilgisayar ve Kümeler > vSAN Küme Monitörü >> vSAN > Skyline Sağlık > Fiziksel diski
Resim 3: Skyline Sağlık görünümü
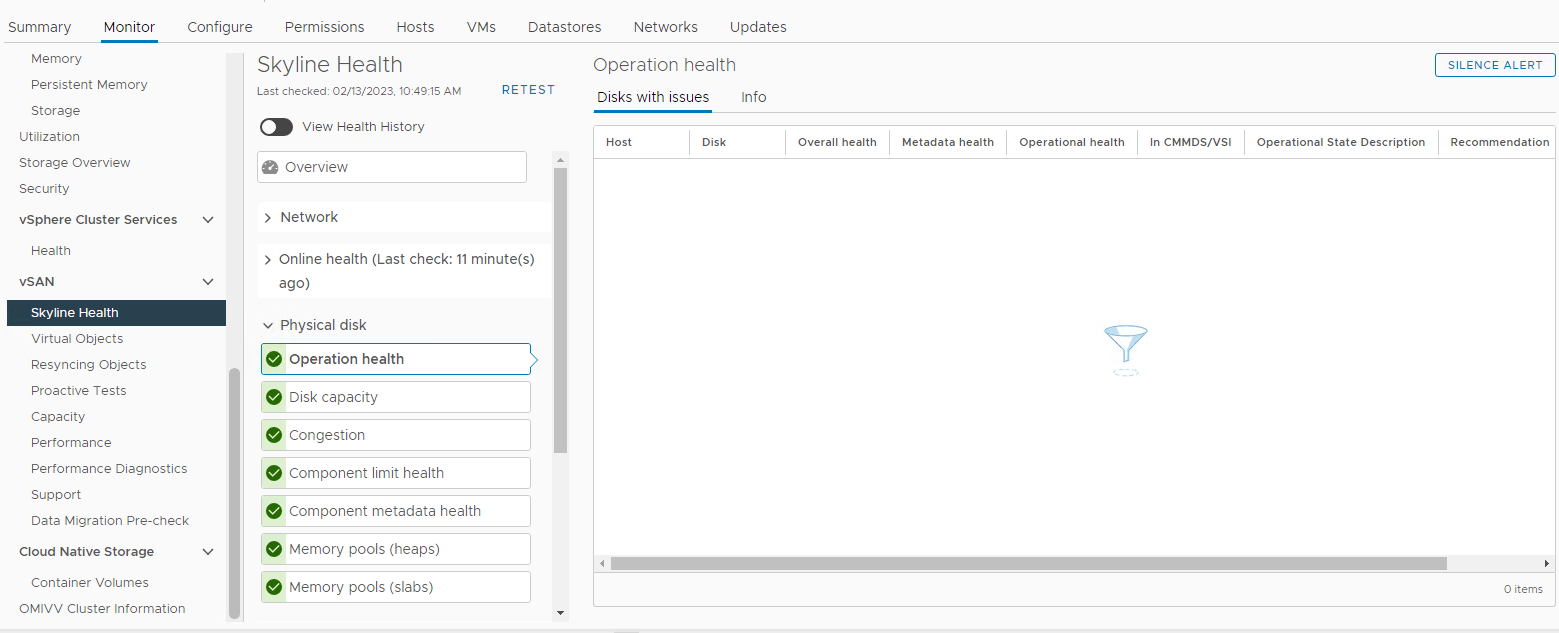
Burada, aşağıdaki alarmlardan herhangi birinin tetiklenip tetiklenmediğini doğrulayabilirsiniz:
Impending permanent disk failure, data is being evacuated (Health state - Yellow).
Impending permanent disk failure, data evacuation failed due to insufficient resources (Health state - Red).
Impending permanent disk failure, data evacuation failed due to inaccessible objects (Health state - Red).
Impending permanent disk failure, data evacuation completed (Health state - Yellow)
Ayrıca disk durumunu, etkilenen ana bilgisayarın Depolama Aygıtları listesinden de kontrol edebilirsiniz:
Stok > Ana Bilgisayar ve Kümeler vSAN Kümesi Etkilenen > vSAN ESXi Ana Bilgisayarı > Depolama > Depolama Aygıtlarını >>
Yapılandırma Resim 4: Ana Bilgisayar Depolama Aygıtları görünümü
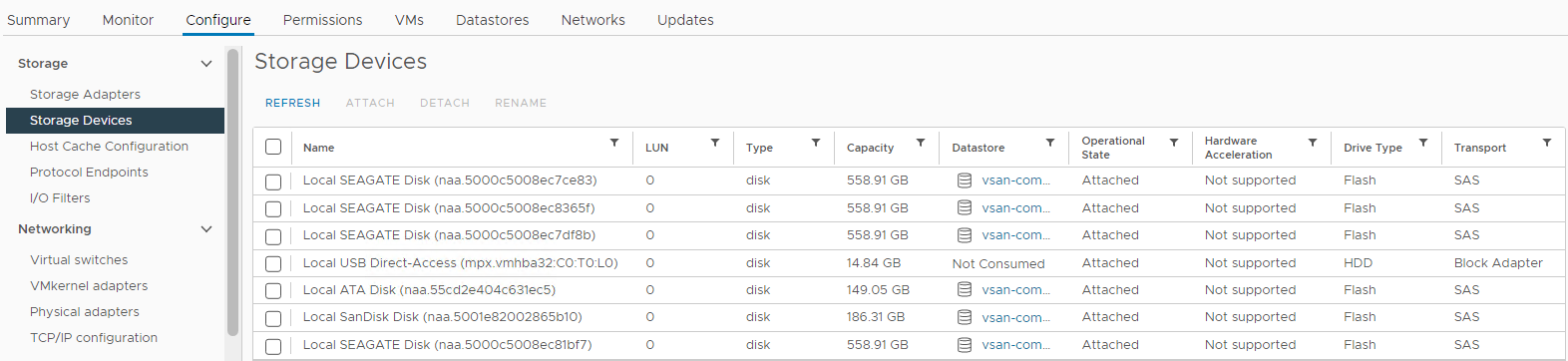
Burada bir disk durumunun şu şekilde olup olmadığını doğrulayabilirsiniz:
0 Capacity Disk Absent
Disk Unmounted
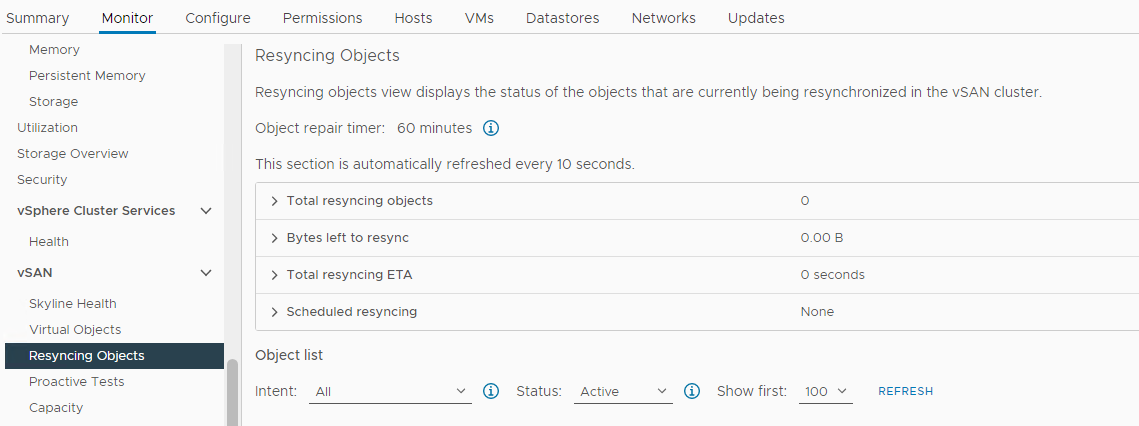
Resync olup olmadığını doğrulayın:
Stok > Ana Bilgisayar ve Kümeler > vSAN Küme Monitörü >> vSAN > Yeniden Senkronizasyon Nesneleri:
Resim 5: Nesneleri Yeniden Senkronize Etme görünümü
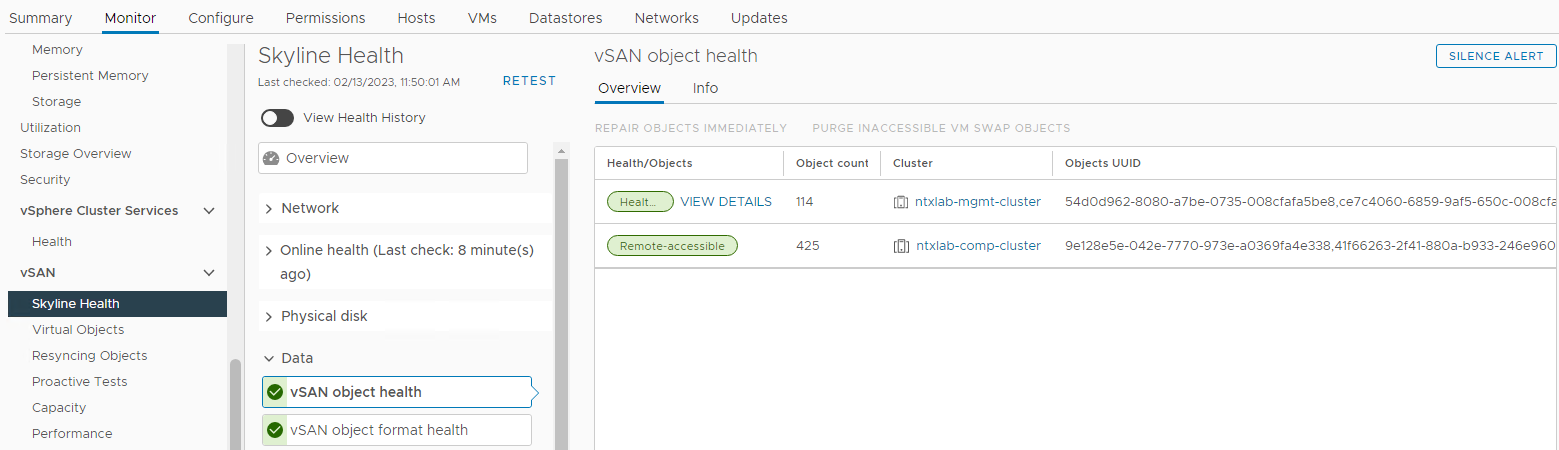
VSAN Nesnelerinin durumunu doğrulayın:
Stok > Ana Bilgisayar ve Kümeler > vSAN Küme Monitörü >> vSAN > Skyline Sağlık > Verileri > vSAN nesne sağlığı
Resim 6: vSAN nesne sağlığı görünümü
Bir sonraki adım, CLI üzerinden sorun hakkında daha fazla bilgi toplamak ve günlükleri kontrol etmektir:
CLI'dan vSAN Fiziksel Disk durumunu kontrol etme:
Etkilenen ana bilgisayara SSH üzerinden bağlanın ve aşağıdaki komutları çalıştırın:
vdq -qH
Kontrol et "IsPDL" (kalıcı cihaz kaybı) parametresi. 1'e eşitse, disk kaybolur.
Örneğin:
DiskResults:
DiskResult[0]:
Name: naa.600508b1001c4b820b4d80f9f8acfa95
VSANUUID: 5294bbd8-67c4-c545-3952-7711e365f7fa
State: In-use for VSAN
ChecksumSupport: 0
Reason: Non-local disk
IsSSD?: 0
IsCapacityFlash?: 0
IsPDL?: 0
<<truncated>>
DiskResult[18]:
Name:
VSANUUID: 5227c17e-ec64-de76-c10e-c272102beba7
State: In-use for VSAN
ChecksumSupport: 0
Reason: None
IsSSD?: 0
IsCapacityFlash?: 0
IsPDL?: 1
vdq -iH
Disk grubunda eksik bir disk olup olmadığını kontrol edin.
Örneğin:
Mappings: DiskMapping[0]: SSD: naa.58ce38ee2016ffe5 MD: naa.5002538a4819e3e0 DiskMapping[2]: SSD: naa.58ce38ee2016fe55 MD: naa.5002538a48199ca0 MD: naa.5002538a48199e20 MD: naa.5002538a48199e00
esxcli vsan storage list
Kontrol edin "In CMMDS" parametresini kullanın. False ise diskle iletişim kaybolur.
Örneğin:
Device: Unknown
Display Name: Unknown
Is SSD: false
VSAN UUID: 529cadbc-acd1-b588-8643-68336d5512d6
VSAN Disk Group UUID:
VSAN Disk Group Name:
Used by this host: false
In CMMDS: false
On-disk format version: <Unknown>
Deduplication: false
Compression: false
Checksum:
Checksum OK: false
Is Capacity Tier: false
for i in `esxcli storage core device list | grep ^naa` ; do echo $i; esxcli storage core device smart get -d $i; done.
Smart get komutuyla okuma/yazma hatalarını kontrol edin.
Örneğin:
naa.55cd2e404c1f35a1 Parameter Value Threshold Worst Raw -------------------------- ----- --------- ----- --- Health Status OK N/A N/A N/A Media Wearout Indicator 100 0 100 86 Read Error Count 130 39 130 133 Power-on Hours 100 0 100 110 Power Cycle Count 100 0 100 106 Drive Temperature 100 0 100 26 Uncorrectable Sector Count 100 0 100 0
naa.55cd2e404c1f35a5 Parameter Value Threshold Worst Raw -------------------------- ----- --------- ----- --- Health Status OK N/A N/A N/A Media Wearout Indicator 100 0 100 10 Read Error Count 130 39 130 53 Power-on Hours 100 0 100 110 Power Cycle Count 100 0 100 106 Drive Temperature 100 0 100 27 Uncorrectable Sector Count 100 0 100 0
esxcli vsan storage list | grep "VSAN Disk Group UUID:" | sort | uniq -c
Kullanılabilir disk gruplarını kontrol edin.
Örneğin:
2 VSAN Disk Group UUID: 5203424c-ee56-497d-75d1-fcf73ae997cb 2 VSAN Disk Group UUID: 52af8e5c-77d1-b552-3310-ec5fef09edf4
while true;do echo " ****************************************** "; echo "" > /tmp/resyncStats.txt ;cmmds-tool find -t DOM_OBJECT -f json |grep uuid |awk -F \" '{print $4}' |while read i;do pendingResync=$(cmmds-tool find -t DOM_OBJECT -f json -u $i|grep -o "\"bytesToSync\": [0-9]*,"|awk -F " |," '{sum+=$2} END{print sum / 1024 / 1024 / 1024;}');if [ ${#pendingResync} -ne 1 ]; then echo "$i: $pendingResync GiB";fi;done |tee -a /tmp/resyncStats.txt;total=$(cat /tmp/resyncStats.txt |awk '{sum+=$2} END{print sum}');echo "Total: $total GiB" |tee -aa /tmp/resyncStats.txt;total=$(cat /tmp/resyncStats.txt |grep Total);totalObj=$(cat /tmp/resyncStats.txt|grep -vE " 0 GiB|Total"|wc -l);echo "`date +%Y-%m-%dT%H:%M:%SZ` $total ($totalObj objects)" >> /tmp/totalHistory.txt; echo `date `; sleep 60; done
Devam eden veya takılmış yeniden senkronizasyon işlemleri olup olmadığını kontrol edin.
Örneğin:
Total: 0 GiB Mon Feb 13 17:32:06 UTC 2023
Komutu durdurmak için Ctrl+C tuşlarına basın.
cmmds-tool find -f python | grep CONFIG_STATUS -B 4 -A 6 | grep 'uuid\|content' | grep -o 'state\\\":\ [0-9]*' | sort | uniq -c
Bileşenlerin durumunu kontrol edin.
Healthy -- state 7
Inaccessible -- state 13
Absent or Degraded -- state 15
Örneğin:
425 state\": 7
Arızalı SSD veya SABİT SÜRÜCÜNÜN CLI üzerinde nerede bulunduğu nasıl belirlenir:
Kullanılabilir tüm aygıtları listeleyin:
esxcli storage core device list | grep "naa" | awk '{print $1}' | grep "naa"
Örneğin:
naa.5000c500852df8d3 naa.55cd2e404c1f35a1 naa.55cd2e404c1f35a5 naa.5000c500852dd5e7
Listeden her bir disk naa'yı kullanarak konumu kontrol edin:
esxcli storage core device physical get -d
Örneğin:
esxcli storage core device physical get -d naa.5000c500852df8d3 esxcli storage core device physical get -d naa.55cd2e404c1f35a1 esxcli storage core device physical get -d naa.55cd2e404c1f35a5 esxcli storage core device physical get -d naa.5000c500852dd5e7 Physical Location: enclosure 65535 slot 0 Physical Location: enclosure 65535 slot 1 Physical Location: enclosure 65535 slot 2 Physical Location: enclosure 65535 slot 3
Aygıt adı eksikse arızalı SABİT SÜRÜCÜ veya SSD'yi belirleme:
Arızalı disk algılanmayabilir ve ilgili naa kullanılarak tanımlanamayabilir. Bu senaryoda, tüm diskleri bulmak gerekir ve fiziksel olarak bulunmayan disk, başarısız olan disktir.
Görevi biraz daha hızlı gerçekleştirmek için kullanılabilecek bir komut dosyası aşağıda verilmiştir:
echo "=============Physical disks placement=============="
echo ""
esxcli storage core device list | grep "naa" | awk '{print $1}' | grep "naa" | while read in; do
echo "$in"
esxcli storage core device physical get -d "$in"
sleep 1
echo "===================================================="
done
Depolama ile ilgili sorunlar için vSAN ile ilgili günlükler:
/var/log/vmkernel.log
vSAN diskleri, vSAN ana bilgisayar kalp atışları, PDL'ler, SCSI algılama kodları ve G/Ç istekleri (Okuma/Yazma) ve küme üyeliği bilgilerini okuma ve yazma sorunları.
Örneğin:
2021-06-22T12:02:08.408Z cpu30:1001397101)ScsiDeviceIO: PsaScsiDeviceTimeoutHandlerFn:12834: TaskMgmt op to cancel IO succeeded for device naa.55cd2e404b7736d0 and the IO did not complete. WorldId 0, Cmd 0x28, CmdSN = 0x428.Cancelling of IO will be 2021-06-22T12:02:08.408Z cpu30:1001397101)retried.
/var/log/vobd.log
Disk durumu, kalıcı aygıt kayıp diskleri (PDL'ler), disk gecikme süresi ve bir ana bilgisayarın bakım moduna ne zaman girip çıktığı hakkında raporlar.
Örneğin:
2022-05-31T11:42:46.065Z: [vSANCorrelator] 10605891965954us: [vob.vsan.lsom.devicerepair] vSAN device 521a74ce-c980-c16c-ff3d-38a036233daf is being repaired due to I/O failures, and will be out of service until the repair is complete. If the device is part of a dedup disk group, the entire disk group will be out of service until the repair is complete. 2022-05-31T11:42:46.065Z: [vSANCorrelator] 10606062774178us: [esx.problem.vob.vsan.lsom.devicerepair] Device 521a74ce-c980-c16c-ff3d-38a036233daf is in offline state and is getting repaired
/var/log/vsandevicemonitord.log
Diskin aşırı günlük tıkanıklığı veya G/Ç gecikmeleri nedeniyle iyi durumda değil olarak işaretlenip işaretlenmediğini belirlemenize yardımcı olur.
Örneğin:
INFO vsandevicemonitord WARNING - WRITE Average Latency on VSAN device naa.50000xxxxxxxx has exceeded threshold value 2000000 us 2 times. INFO vsandevicemonitord Tier 2 (naa.50000xxxxxxxx) as unhealthy
Additional Information
Bu videoyu inceleyin:
VMware: vSAN Fiziksel Disk Sorun Giderme Rehberi
Süre: 00:10:19 (ss:dd:ss)
Mümkün olduğunda, bu video oynatıcıdaki CC simgesi kullanılarak altyazı (altyazılar) dil ayarları seçilebilir.
Bu videoyu YouTube'da da izleyebilirsiniz.