VMware:vSAN 實體磁碟故障診斷指南
Summary: 這是一般故障診斷指南,可協助識別 vSAN 叢集中的實體磁碟是否有問題。
Instructions
從 Web UI 檢查 vSAN 實體磁碟狀態:
連線至 vCenter Server Web 用戶端,並從以下位置檢查磁碟狀態:
庫存 > 主機和叢集 > vSAN 叢集設定 >> vSAN > 磁碟管理
圖1:vSAN 磁碟管理檢視
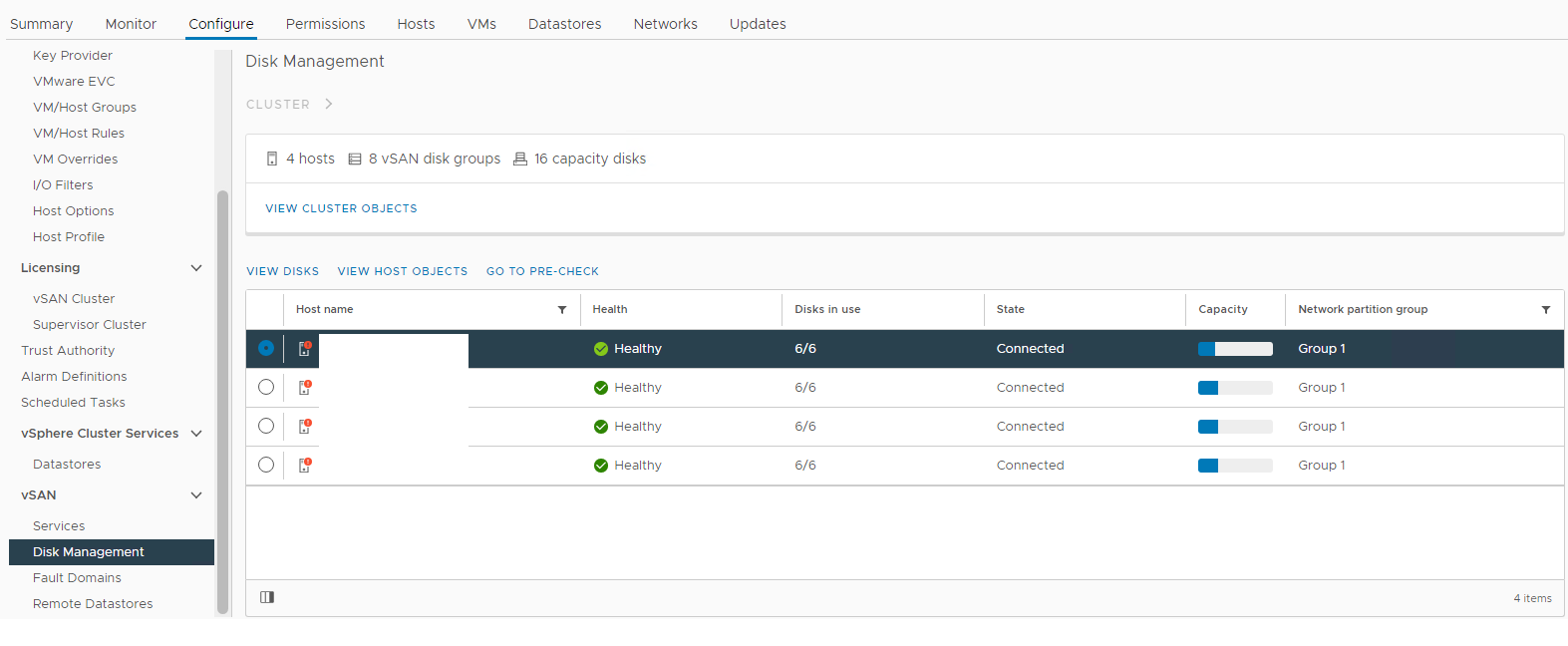
選取受影響的主機,然後展開「檢視磁碟」區段:
圖2:vSAN 磁碟群組檢視
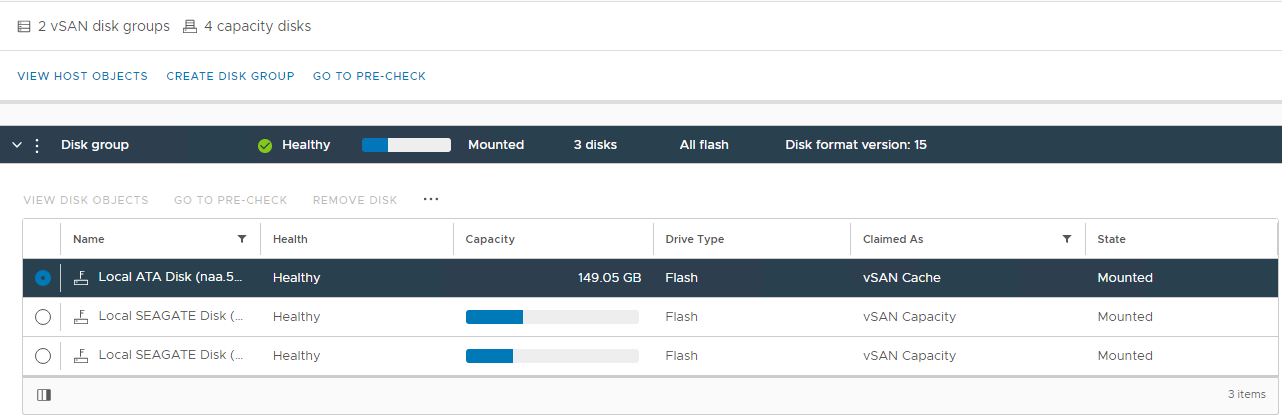
您可以在這裡確認是否有偵測到磁碟:
不健全
狀況 已卸載
0 容量
永久磁碟故障
磁碟關閉
缺少
磁碟 此外,請檢查從 vSAN Skyline 健全狀況區段觸發的磁碟相關警報:
庫存 > 主機和叢集 > vSAN 叢集 > 監控 > vSAN > Skyline 執行狀況 > 實體磁碟
圖 3:天際線健康檢視
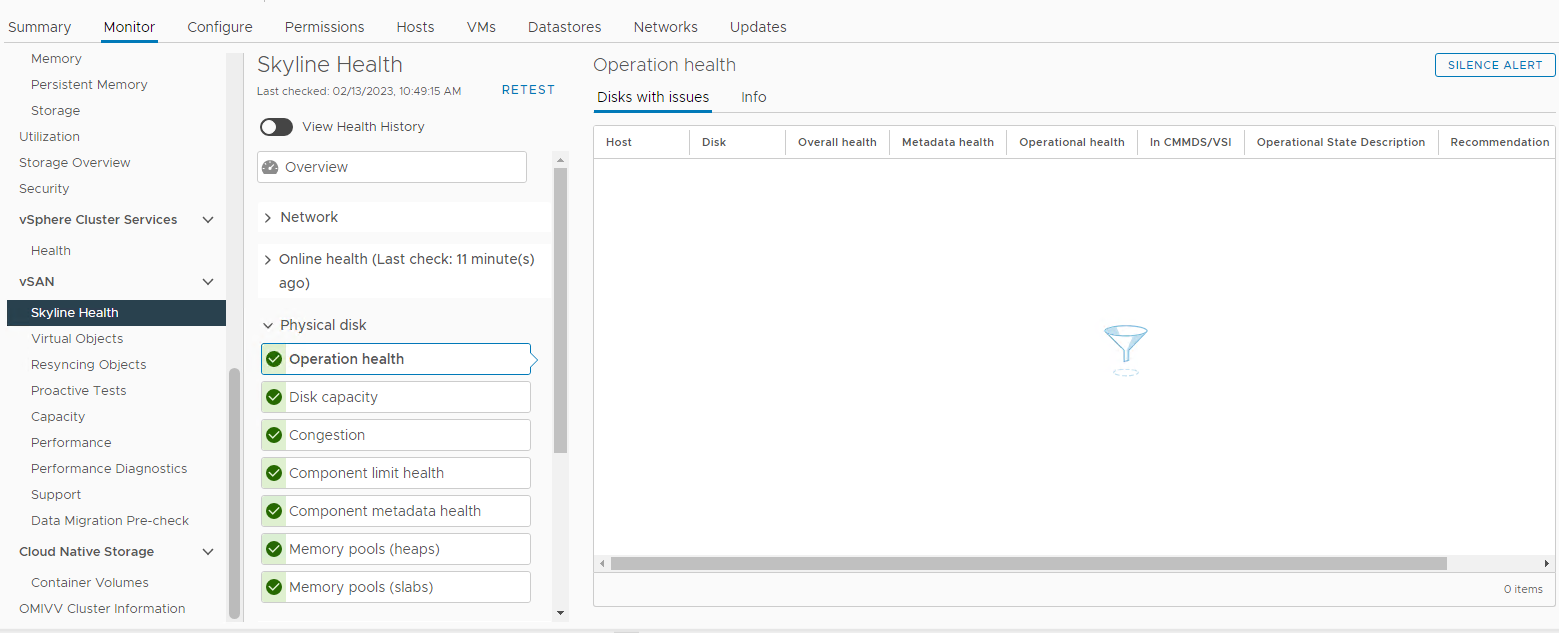
您可以在此處確認是否觸發了以下任何警報:
Impending permanent disk failure, data is being evacuated (Health state - Yellow).
Impending permanent disk failure, data evacuation failed due to insufficient resources (Health state - Red).
Impending permanent disk failure, data evacuation failed due to inaccessible objects (Health state - Red).
Impending permanent disk failure, data evacuation completed (Health state - Yellow)
此外,您也可以從受影響主機的儲存裝置清單中檢查磁碟狀態:
庫存 > 主機和叢集 > vSAN 叢集 > 受影響的 vSAN ESXi 主機 > 配置 > 儲存 > 裝置
圖4:主機儲存裝置檢視
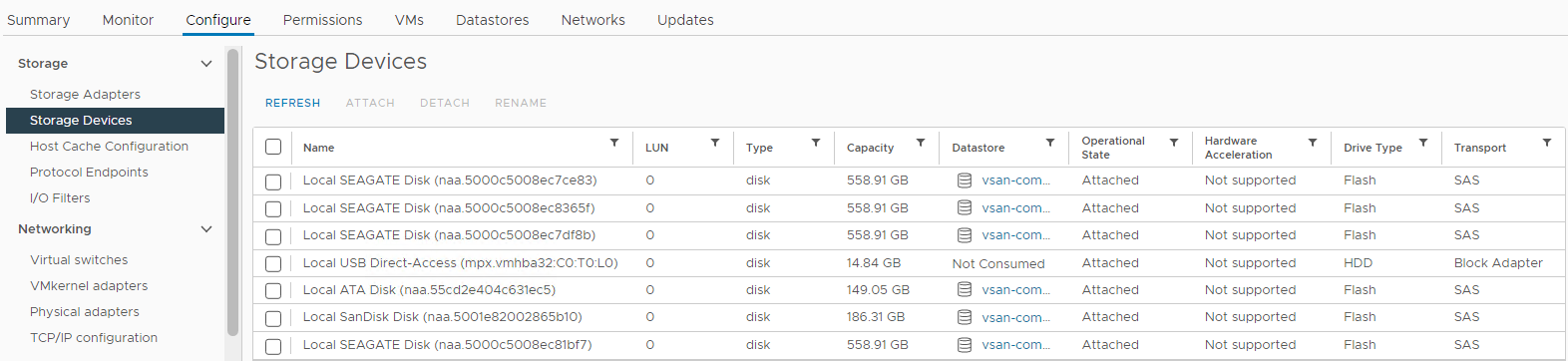
您可以在這裡確認磁碟狀態是否為:
0 容量
磁碟不存在
,磁碟已取消掛接
確認是否正在重新同步:
庫存 > 主機和叢集 > vSAN 叢集 > 監控 > vSAN > 重新同步物件:
圖5:重新同步物件檢視
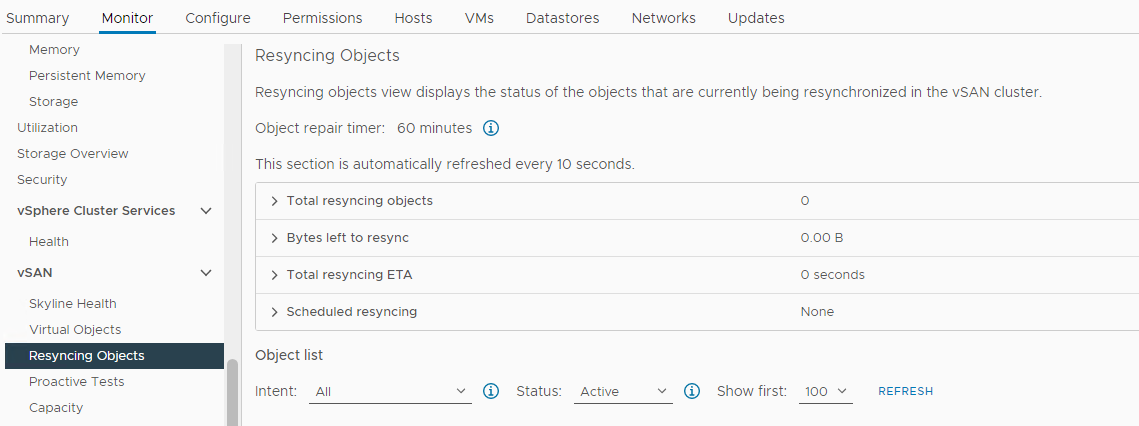
確認 vSAN 物件的狀態:
庫存>主機和叢集 > vSAN 叢集>監控 vSAN > 天際線執行狀況>資料 >> vSAN 物件執行狀況
圖6:vSAN 物件執行狀況檢視
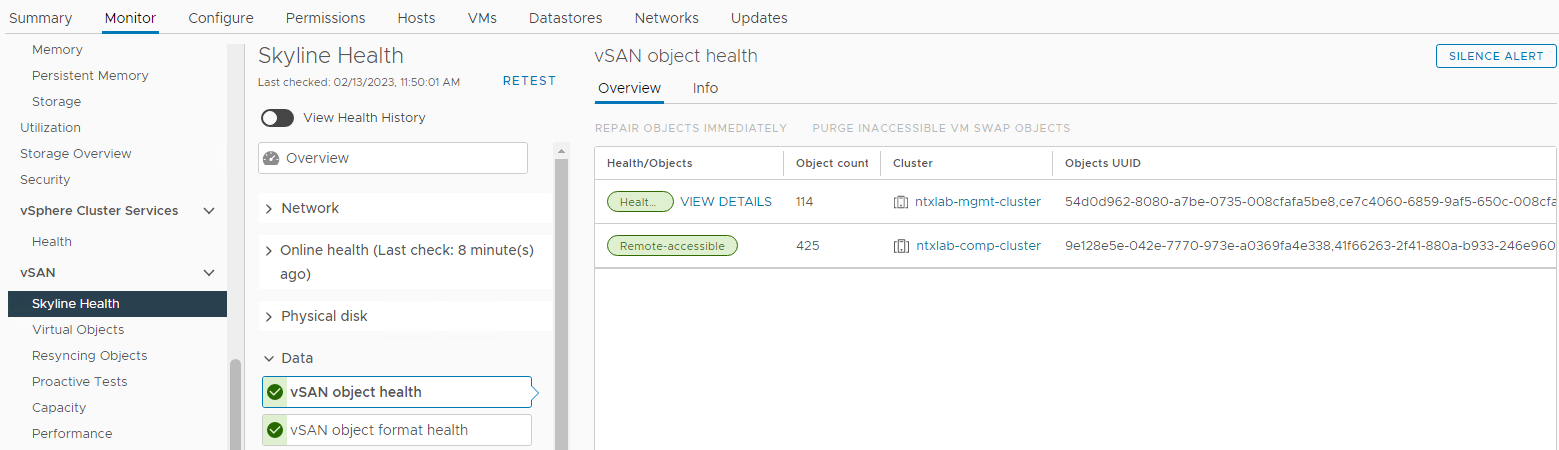
下一步是透過 CLI 收集此問題的詳細資訊,並檢查記錄:
從 CLI 檢查 vSAN 實體磁碟狀態:
透過 SSH 連線至受影響的主機,然後執行下列命令:
vdq -qH
檢查”IsPDL」(永久裝置遺失) 參數。如果等於 1,則磁碟丟失。
範例:
DiskResults:
DiskResult[0]:
Name: naa.600508b1001c4b820b4d80f9f8acfa95
VSANUUID: 5294bbd8-67c4-c545-3952-7711e365f7fa
State: In-use for VSAN
ChecksumSupport: 0
Reason: Non-local disk
IsSSD?: 0
IsCapacityFlash?: 0
IsPDL?: 0
<<truncated>>
DiskResult[18]:
Name:
VSANUUID: 5227c17e-ec64-de76-c10e-c272102beba7
State: In-use for VSAN
ChecksumSupport: 0
Reason: None
IsSSD?: 0
IsCapacityFlash?: 0
IsPDL?: 1
vdq -iH
檢查磁碟群組中是否有遺失的磁碟。
範例:
Mappings: DiskMapping[0]: SSD: naa.58ce38ee2016ffe5 MD: naa.5002538a4819e3e0 DiskMapping[2]: SSD: naa.58ce38ee2016fe55 MD: naa.5002538a48199ca0 MD: naa.5002538a48199e20 MD: naa.5002538a48199e00
esxcli vsan storage list
檢查 "In CMMDS參數。如果為 false,則與磁碟的通信將丟失。
範例:
Device: Unknown
Display Name: Unknown
Is SSD: false
VSAN UUID: 529cadbc-acd1-b588-8643-68336d5512d6
VSAN Disk Group UUID:
VSAN Disk Group Name:
Used by this host: false
In CMMDS: false
On-disk format version: <Unknown>
Deduplication: false
Compression: false
Checksum:
Checksum OK: false
Is Capacity Tier: false
for i in `esxcli storage core device list | grep ^naa` ; do echo $i; esxcli storage core device smart get -d $i; done.
檢查 smart get 命令的讀取/寫入錯誤。
範例:
naa.55cd2e404c1f35a1 Parameter Value Threshold Worst Raw -------------------------- ----- --------- ----- --- Health Status OK N/A N/A N/A Media Wearout Indicator 100 0 100 86 Read Error Count 130 39 130 133 Power-on Hours 100 0 100 110 Power Cycle Count 100 0 100 106 Drive Temperature 100 0 100 26 Uncorrectable Sector Count 100 0 100 0
naa.55cd2e404c1f35a5 Parameter Value Threshold Worst Raw -------------------------- ----- --------- ----- --- Health Status OK N/A N/A N/A Media Wearout Indicator 100 0 100 10 Read Error Count 130 39 130 53 Power-on Hours 100 0 100 110 Power Cycle Count 100 0 100 106 Drive Temperature 100 0 100 27 Uncorrectable Sector Count 100 0 100 0
esxcli vsan storage list | grep "VSAN Disk Group UUID:" | sort | uniq -c
檢查可用的磁碟群組。
範例:
2 VSAN Disk Group UUID: 5203424c-ee56-497d-75d1-fcf73ae997cb 2 VSAN Disk Group UUID: 52af8e5c-77d1-b552-3310-ec5fef09edf4
while true;do echo " ****************************************** "; echo "" > /tmp/resyncStats.txt ;cmmds-tool find -t DOM_OBJECT -f json |grep uuid |awk -F \" '{print $4}' |while read i;do pendingResync=$(cmmds-tool find -t DOM_OBJECT -f json -u $i|grep -o "\"bytesToSync\": [0-9]*,"|awk -F " |," '{sum+=$2} END{print sum / 1024 / 1024 / 1024;}');if [ ${#pendingResync} -ne 1 ]; then echo "$i: $pendingResync GiB";fi;done |tee -a /tmp/resyncStats.txt;total=$(cat /tmp/resyncStats.txt |awk '{sum+=$2} END{print sum}');echo "Total: $total GiB" |tee -aa /tmp/resyncStats.txt;total=$(cat /tmp/resyncStats.txt |grep Total);totalObj=$(cat /tmp/resyncStats.txt|grep -vE " 0 GiB|Total"|wc -l);echo "`date +%Y-%m-%dT%H:%M:%SZ` $total ($totalObj objects)" >> /tmp/totalHistory.txt; echo `date `; sleep 60; done
檢查重新同步作業是否正在進行或停滯。
範例:
Total: 0 GiB Mon Feb 13 17:32:06 UTC 2023
按下 Ctrl+C 以停止命令。
cmmds-tool find -f python | grep CONFIG_STATUS -B 4 -A 6 | grep 'uuid\|content' | grep -o 'state\\\":\ [0-9]*' | sort | uniq -c
檢查元件的狀態。
Healthy -- state 7
Inaccessible -- state 13
Absent or Degraded -- state 15
範例:
425 state\": 7
如何透過 CLI 識別故障的 SSD 或硬碟位置:
列出所有可用的裝置:
esxcli storage core device list | grep "naa" | awk '{print $1}' | grep "naa"
範例:
naa.5000c500852df8d3 naa.55cd2e404c1f35a1 naa.55cd2e404c1f35a5 naa.5000c500852dd5e7
使用清單中的每個磁碟 naa 檢查位置:
esxcli storage core device physical get -d
範例:
esxcli storage core device physical get -d naa.5000c500852df8d3 esxcli storage core device physical get -d naa.55cd2e404c1f35a1 esxcli storage core device physical get -d naa.55cd2e404c1f35a5 esxcli storage core device physical get -d naa.5000c500852dd5e7 Physical Location: enclosure 65535 slot 0 Physical Location: enclosure 65535 slot 1 Physical Location: enclosure 65535 slot 2 Physical Location: enclosure 65535 slot 3
如果缺少裝置名稱,如何識別故障的硬碟或 SSD:
可能是由於偵測不到故障的磁碟,因此無法使用對應的 naa 來識別。在這種情況下,需要找到所有磁碟,而不在物理位置的磁碟將是失敗的磁碟。
下面是一個可用於稍快地執行任務的腳本:
echo "=============Physical disks placement=============="
echo ""
esxcli storage core device list | grep "naa" | awk '{print $1}' | grep "naa" | while read in; do
echo "$in"
esxcli storage core device physical get -d "$in"
sleep 1
echo "===================================================="
done
vSAN 相關記錄,以解決儲存裝置相關問題:
/var/log/vmkernel.log
讀取和寫入 vSAN 磁碟、vSAN 主機活動訊號、PDL、SCSI 感應代碼和 I/O 要求 (讀取/寫入) 和叢集成員資格資訊時出現問題。
範例:
2021-06-22T12:02:08.408Z cpu30:1001397101)ScsiDeviceIO: PsaScsiDeviceTimeoutHandlerFn:12834: TaskMgmt op to cancel IO succeeded for device naa.55cd2e404b7736d0 and the IO did not complete. WorldId 0, Cmd 0x28, CmdSN = 0x428.Cancelling of IO will be 2021-06-22T12:02:08.408Z cpu30:1001397101)retried.
/var/log/vobd.log
報告磁碟健全狀況、永久裝置遺失的磁碟 (PDL)、磁碟延遲,以及主機進入和結束維護模式的時間報告。
範例:
2022-05-31T11:42:46.065Z: [vSANCorrelator] 10605891965954us: [vob.vsan.lsom.devicerepair] vSAN device 521a74ce-c980-c16c-ff3d-38a036233daf is being repaired due to I/O failures, and will be out of service until the repair is complete. If the device is part of a dedup disk group, the entire disk group will be out of service until the repair is complete. 2022-05-31T11:42:46.065Z: [vSANCorrelator] 10606062774178us: [esx.problem.vob.vsan.lsom.devicerepair] Device 521a74ce-c980-c16c-ff3d-38a036233daf is in offline state and is getting repaired
/var/log/vsandevicemonitord.log
它可協助您判斷磁碟是否因為過多的記錄壅塞或 I/O 延遲而標記為不健全。
範例:
INFO vsandevicemonitord WARNING - WRITE Average Latency on VSAN device naa.50000xxxxxxxx has exceeded threshold value 2000000 us 2 times. INFO vsandevicemonitord Tier 2 (naa.50000xxxxxxxx) as unhealthy
Additional Information
請參閱此影片:
VMware:vSAN 實體磁碟故障診斷指南
持續時間:00:10:19 (小時:分鐘:秒)
當可用時,您可以使用此影像播放器上的 CC 圖示來選擇隱藏式輔助字幕 (字幕) 語言設定。
您也可以在 YouTube 上觀看此影片。