ECS: RPO für Replikationsgruppe <xx> beträgt X Stunde Y Minuten Z Sekunden und überschreitet den Schwellenwert von 1 Stunde
Zusammenfassung:
In diesem Artikel wird der Symptomcode 1012 – RPO für die Replikationsgruppe erläutert. ist X Stunde Y Minuten Z Sekunden größer als der festgelegte Schwellenwert von 1 Stunde.
Dieser Artikel gilt für
Dieser Artikel gilt nicht für
Dieser Artikel ist nicht an ein bestimmtes Produkt gebunden.
In diesem Artikel werden nicht alle Produktversionen aufgeführt.
Symptome
Ein Dial-Home mit Symptomcode 1012 wurde auf ECS-Codeebene 3.2 und höher mit der folgenden Warnmeldung erzeugt:
<Event>
<SymptomCode>1012</SymptomCode>
<Category>Configuration</Category>
<Severity>Warning</Severity>
<Status>Unknown</Status>
<Component>Object</Component>
<ComponentID></ComponentID>
<SubComponent>RPO</SubComponent>
<SubComponentID></SubComponentID>
<CallHome>true</CallHome>
<FirstTime>2017-12-06T05:08:41.583Z</FirstTime>
<LastTime>2017-12-06T05:08:41.583Z</LastTime>
<Count>0</Count>
<EventData><![CDATA[]]></EventData>
<Description><![CDATA[<b>RPO for replication group rg1 is 1 hour 2 minutes 14 seconds greater than 1 hour threshold set</b>.]]></Description>
</Event>
Das Recover Point Objective (RPO) bezieht sich auf den Zeitpunkt in der Vergangenheit, auf den Sie wiederherstellen können.
Ursache
Diese Warnmeldung wurde generiert, da die RPO den angegebenen Schwellenwert überschritten hat. Der standardmäßige RPO-Schwellenwert beträgt 1 Stunde.
Die Warnmeldung kann auch generiert werden, weil der ECS-Service Chunk Manager (CM) aufgrund von Speicherauslastung auf dem Node neu gestartet wurde. Symptome von CM-Neustarts treten auf, wenn die RPO mehrere Tage andauert und dann nach wenigen Tagen ohne erfolgte Maßnahmen wieder als "Aktuell" zurückkehrt.
Die Warnmeldung kann auch generiert werden, weil der ECS-Service Chunk Manager (CM) aufgrund von Speicherauslastung auf dem Node neu gestartet wurde. Symptome von CM-Neustarts treten auf, wenn die RPO mehrere Tage andauert und dann nach wenigen Tagen ohne erfolgte Maßnahmen wieder als "Aktuell" zurückkehrt.
Lösung
Weitere Informationen zum Überwachen der Replikation von Daten über die virtuellen Rechenzentren (VDCs), die eine Replikationsgruppe bilden, finden Sie unter "ECS UI > Monitor >Geo Replication ". Verwenden Sie die Registerkarte RPO , um das RPO für die betreffende Replikationsgruppe und ihre Remote-VDCs anzuzeigen. Wenn das RPO "Aktuell" ist, bedeutet dies, dass die Warnmeldung vorübergehend war und sich die RPO wieder innerhalb des Schwellenwerts befindet:
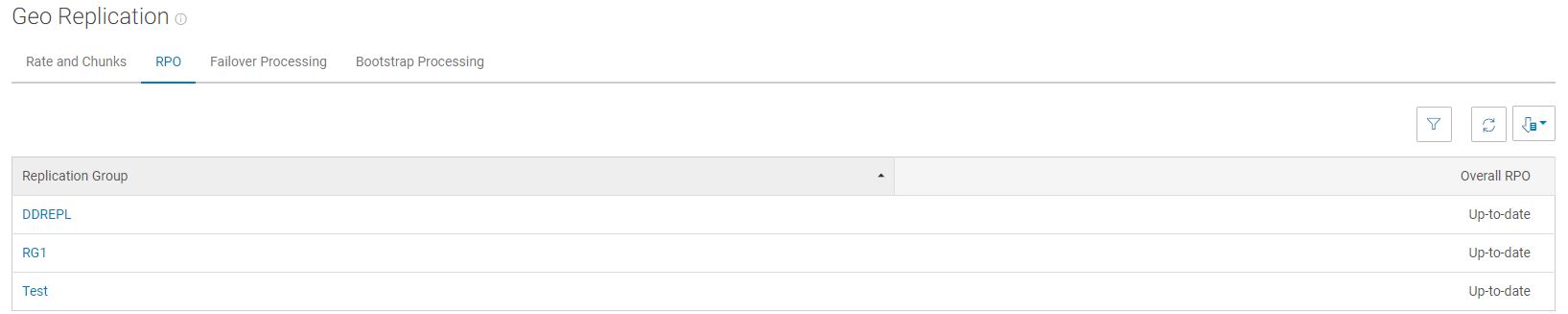
Wenn das RPO über 1 Stunde liegt, wird empfohlen, die Netzwerkverbindung zwischen dem betreffenden und dem Remote-VDC zu überprüfen, um das RPO auf den neuesten Stand zu bringen. Notieren Sie sich außerdem alle laufenden ECS-Upgrades, temporären Standortausfälle (TSO) oder permanenten Standortausfälle (PSO) oder Netzwerkprobleme, die diese Warnmeldung verursachen können.
Führen Sie den folgenden Befehl aus, um zu überprüfen, ob innerhalb des letzten Tages CM-Neustarts stattgefunden haben:
Wenn das RPO über 1 Stunde liegt, wird empfohlen, die Netzwerkverbindung zwischen dem betreffenden und dem Remote-VDC zu überprüfen, um das RPO auf den neuesten Stand zu bringen. Notieren Sie sich außerdem alle laufenden ECS-Upgrades, temporären Standortausfälle (TSO) oder permanenten Standortausfälle (PSO) oder Netzwerkprobleme, die diese Warnmeldung verursachen können.
Führen Sie den folgenden Befehl aus, um zu überprüfen, ob innerhalb des letzten Tages CM-Neustarts stattgefunden haben:
svc_node services -sr -start "1 day ago" svc_node v1.1.3 (svc_tools v1.7.1) Started 2020-03-02 15:15:10 Total Restarts on each node (all services) from 1 day ago to now: Node # Service Restarts -------------------------------- 169.254.1.1 7 169.254.1.2 0 169.254.1.3 0 169.254.1.4 0 169.254.1.5 0 169.254.1.6 0 169.254.1.7 0 169.254.1.8 0 Aggregate restarts on nodes 'all': Time blbsvc cm crdsvc datahd dtq evntsv georcv metrng objctl portal rm rsrcsv sr ss ssm stat trform vnest ---------------------------------------------------------------------------------------------------------------------------------------------------------------- 2020-03-01 15:xx - 1 - - - - - - - - - - - - - - - - 2020-03-01 16:xx - - - - - - - - - - - - - - - - - - 2020-03-01 17:xx - - - - - - - - - - - - - - - - - - 2020-03-01 18:xx - - - - - - - - - - - - - - - - - - 2020-03-01 19:xx - - - - - - - - - - - - - - - - - - 2020-03-01 20:xx - - - - - - - - - - - - - - - - - - 2020-03-01 21:xx - - - - - - - - - - - - - - - - - - 2020-03-01 22:xx - 1 - - - - - - - - - - - - - - - - 2020-03-01 23:xx - - - - - - - - - - - - - - - - - - 2020-03-02 00:xx - - - - - - - - - - - - - - - - - - 2020-03-02 01:xx - - - - - - - - - - - - - - - - - - 2020-03-02 02:xx - 2 - - - - - - - - - - - - - - - - 2020-03-02 03:xx - - - - - - - - - - - - - - - - - - 2020-03-02 04:xx - - - - - - - - - - - - - - - - - - 2020-03-02 05:xx - - - - - - - - - - - - - - - - - - 2020-03-02 06:xx - - - - - - - - - - - - - - - - - - 2020-03-02 07:xx - - - - - - - - - - - - - - - - - - 2020-03-02 08:xx - 3 - - - - - - - - - - - - - - - - 2020-03-02 09:xx - - - - - - - - - - - - - - - - - - 2020-03-02 10:xx - - - - - - - - - - - - - - - - - - 2020-03-02 11:xx - - - - - - - - - - - - - - - - - - 2020-03-02 12:xx - - - - - - - - - - - - - - - - - - 2020-03-02 13:xx - - - - - - - - - - - - - - - - - - 2020-03-02 14:xx - - - - - - - - - - - - - - - - - - 2020-03-02 15:xx - - - - - - - - - - - - - - - - - -Wenn CM-Neustarts festgestellt werden, werden wiederholte Warnmeldungen ohne andere zugehörige Probleme erzeugt. Öffnen Sie einen Service-Request beim Dell Support zur weiteren Überprüfung.
Betroffene Produkte
ECS ApplianceProdukte
ECS Appliance, ECS Appliance Hardware Gen1 U-SeriesArtikeleigenschaften
Artikelnummer: 000168933
Artikeltyp: Solution
Zuletzt geändert: 15 Okt. 2025
Version: 4
Antworten auf Ihre Fragen erhalten Sie von anderen Dell NutzerInnen
Support Services
Prüfen Sie, ob Ihr Gerät durch Support Services abgedeckt ist.