Dell EMC Ready-løsning for HPC PixStor-lagring – NVMe-nivå
Summary: Blogg for en HPC-lagringsløsningskomponent, inkludert arkitektur sammen med ytelsesevaluering.
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Symptoms
Forfattet av Mario Gallegos fra HPC og AI Innovation Lab i juni 2020
Blogg for en HPC-lagringsløsningskomponent, inkludert arkitektur sammen med ytelsesevaluering.
Blogg for en HPC-lagringsløsningskomponent, inkludert arkitektur sammen med ytelsesevaluering.
Resolution
Dell EMC Ready Solution for HPC PixStor Storage
NVMe-nivå
Innholdsfortegnelse
Sekvensiell IOzone ytelse N-klienter til N-filer
Sekvensiell IOR-ytelse N-klienter til 1-fil
Tilfeldige små blokker IOzone Performance N-klienter til N-filer
Metadataytelse med MDtest ved bruk av 4 KiB-filer
Konklusjoner og fremtidig arbeid
Innledning
Dagens HPC-miljøer har økte krav til lagring med svært høy hastighet, og med CPU-er med høyere antall, raskere nettverk og større minne ble lagring flaskehalsen i mange arbeidsbelastninger. Disse HPC-kravene med høy etterspørsel dekkes vanligvis av parallelle filsystemer (PFS) som gir samtidig tilgang til en enkelt fil eller et sett med filer fra flere noder, og distribuerer data veldig effektivt og sikkert til flere LUN-er på tvers av flere servere. Disse filsystemene er normalt spinnende mediebasert for å gi den høyeste kapasiteten til lavest mulig kostnad. Hastigheten og ventetiden til roterende medier kan imidlertid oftere og oftere ikke holde tritt med kravene til mange moderne HPC-arbeidsbelastninger, noe som krever bruk av flash-teknologi i form av burstbuffere, raskere nivåer eller til og med veldig raske riper, lokalt eller distribuert. DellEMC Ready Solution for HPC PixStor Storagebruker NVMe-noder som komponent for å dekke slike nye krav til høy båndbredde, i tillegg til å være fleksible, skalerbare, effektive og pålitelige.
Løsningsarkitektur
Denne bloggen er en del av en serie med løsninger for parallellfilsystem (PFS) for HPC-miljøer, spesielt for DellEMC Ready Solution for HPC PixStor Storage, der DellEMC PowerEdge R640-servere med NVMe-stasjoner brukes som et raskt flashbasert nivå.
PixStor PFS-løsningen inkluderer det utbredte General Parallel File System, også kjent som Spectrum Scale. ArcaStream inneholder også mange andre programvarekomponenter for å gi avansert analyse, forenklet administrasjon og overvåking, effektivt filsøk, avanserte gateway-funksjoner og mer.
NVMe-nodene som presenteres i denne bloggen, gir et svært høytytende flashbasert nivå for PixStor-løsningen. Ytelsen og kapasiteten for dette NVMe-nivået kan skaleres ut av flere NVMe-noder. Økt kapasitet leveres ved å velge riktige NVMe-enheter som støttes i PowerEdge R640.
Figur 1 viser referansearkitekturen som viser en løsning med 4 NVMe-noder ved hjelp av High Demand Metadata Module, som håndterer alle metadata i den testede konfigurasjonen. Årsaken er at disse NVMe-nodene for øyeblikket ble brukt som databaserte lagringsmål. NVMe-nodene kan imidlertid også brukes til å lagre data og metadata, eller til og med som et raskere flash-alternativ til metadatamodulen med høy etterspørsel, hvis ekstreme metadatakrav krever det. Disse konfigurasjonene for NVMe-nodene ble ikke testet som en del av dette arbeidet, men vil bli testet i fremtiden.
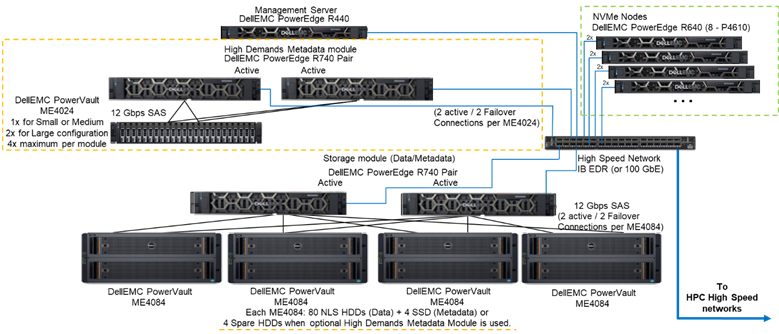
Figur 1 – Referansearkitektur
Løsningskomponenter
Denne løsningen bruker den nyeste Intel Xeon 2. generasjons skalerbare Xeon-prosessoren, også kalt Cascade Lake-prosessorer og den raskeste tilgjengelige RAM-en (2933 MT/s), bortsett fra administrasjonsnodene for å holde dem kostnadseffektive. I tillegg ble løsningen oppdatert til den nyeste versjonen av PixStor (5.1.3.1) som støtter RHEL 7.7 og OFED 5.0, som vil være de støttede programvareversjonene ved utgivelsestidspunktet.
Hver NVMe-node har åtte Dell P4610-enheter som er konfigurert som åtte RAID 10-enheter på tvers av et par servere, ved hjelp av en NVMe over Fabric-løsning for å tillate dataredundans, ikke bare på enhetsnivå, men på servernivå. Når data går inn eller ut av en av disse RAID10-enhetene, brukes i tillegg alle de 16 diskene på begge serverne, noe som øker båndbredden til tilgangen til alle stasjonene. Derfor er den eneste begrensningen for disse komponentene at de må selges og brukes parvis. Alle NVMe-diskene som støttes av PowerEdge R640, kan brukes i denne løsningen, men P4610 har en sekvensiell båndbredde på 3200 MB/s for både lesing og skriving, samt høye tilfeldige IOPS-spesifikasjoner, som er fine funksjoner når du prøver å skalere estimere antall par som trengs for å oppfylle kravene til dette flashnivået.
Hver R640-server har to HCA-er, Mellanox ConnectX-6 Single Port VPI HDR100, som brukes som EDR 100 Gb IB-tilkoblinger. NVMe-nodene er imidlertid klare til å støtte HDR100-hastigheter når de brukes med HDR-kabler og -brytere. Testing av HDR100 på disse nodene er utsatt som en del av HDR100-oppdateringen for hele PixStor-løsningen. Begge CX6-grensesnittene brukes til å synkronisere data for RAID 10 (NVMe over struktur) og som tilkobling for filsystemet. I tillegg gir de maskinvareredundans på adapteren, porten og kabelen. For redundans på svitsjnivå kreves toporters CX6 VPI-adaptere, men de må anskaffes som S&-komponenter.
For å karakterisere ytelsen til NVMe-noder, fra systemet avbildet i figur 1, ble bare metadatamodulen med høy etterspørsel og NVMe-nodene brukt.
Tabell 1 inneholder listen over hovedkomponenter for løsningen. Fra listen over disker som støttes i ME4024, ble 960 GB SSD-er brukt til metadata og var de som ble brukt til ytelseskarakterisering, og raskere stasjoner kan gi bedre tilfeldige IOP-er og kan forbedre metadataoperasjoner for oppretting/fjerning. Alle NVMe-enheter som støttes på PowerEdge R640, støttes for NVMe-nodene.
Tabell 1 Komponenter som skal brukes ved utgivelse og de som brukes i testmiljøet
|
Ved utgivelse |
||
|
Intern tilkoblingsmulighet |
Dell Networking S3048-ON Gigabit Ethernet |
|
|
Undersystem for datalagring |
1 til 4 x Dell EMC PowerVault ME4084 1 x til 4 x Dell EMC PowerVault ME484 (én per ME4084) |
|
|
Valgfritt undersystem for lagring av metadata med høy etterspørsel |
1 til 2 Dell EMC PowerVault ME4024 (4 ME4024 om nødvendig, bare stor konfigurasjon) |
|
|
RAID-lagringskontrollere |
12 Gbps SAS |
|
|
Prosessor |
NVMe-noder |
2 Intel Xeon Gold 6230, 2,1 GHz, 20 kjerner, 40 |
|
Metadata med høy etterspørsel |
||
|
Lagringsnode |
||
|
Administrasjonsnode |
2 Intel Xeon Gold 5220, 2,2 GHz, 18 kjerner, 36 tråder |
|
|
Minne |
NVMe-noder |
12 x 16 GiB 2933 MT/s RDIMM-er (192 GiB) |
|
Metadata med høy etterspørsel |
||
|
Lagringsnode |
||
|
Administrasjonsnode |
12 x 16 GB DIMM-er, 2666 MT/s (192 GiB) |
|
|
Operativsystem |
CentOS 7.7 |
|
|
Kjerneversjon |
3.10.0-1062.12.1.el7.x86_64 |
|
|
PixStor programvare |
5.1.3.1 |
|
|
Programvare for filsystem |
Spektrumskala (GPFS) 5.0.4-3 med NVMesh 2.0.1 |
|
|
Nettverkstilkobling med høy ytelse |
NVMe-noder: 2x ConnectX-6 InfiniBand som bruker EDR/100 GbE |
|
|
Bryter med høy ytelse |
2 Mellanox SB7800 |
|
|
OFED Version (BIOS-versjon) |
Mellanox OFED 5.0-2.1.8.0 |
|
|
Lokale disker (OS og analyse/overvåking) |
Alle servere unntatt de som er oppført NVMe-noder 3 x 480 GB SSD SAS3 (RAID1 + HS) for operativsystem3 x 480 GB SSD SAS3 (RAID1 + HS) for operativsystem PERC H730P RAID-kontroller PERC H740P RAID-kontroller Administrasjonsnode 3 x 480 GB SSD SAS3 (RAID1 + HS) for operativsystem med PERC H740P RAID-kontroller |
|
|
Systemadministrasjon |
iDRAC 9 Enterprise + DellEMC OpenManage |
|
Karakterisering av ytelse
For å karakterisere denne nye Ready Solution-komponenten ble følgende ytelsesprøver brukt:
·IOzone N til N sekvensiell
·IOR N til 1 sekvensiell
·IOzone tilfeldig
·MDtest
For alle referansene som er nevnt ovenfor, hadde testsengen klientene som beskrevet i tabell 2 nedenfor. Siden antall behandlingsnoder tilgjengelig for testing bare var 16, da et høyere antall tråder var nødvendig, ble disse trådene likt fordelt på beregningsnodene (dvs. 32 tråder = 2 tråder per node, 64 tråder = 4 tråder per node, 128 tråder = 8 tråder per node, 256 tråder = 16 tråder per node, 512 tråder = 32 tråder per node, 1024 tråder = 64 tråder per node). Hensikten var å simulere et høyere antall samtidige klienter med det begrensede antallet tilgjengelige beregningsnoder. Siden noen referanser støtter et høyt antall tråder, ble det brukt en maksimumsverdi på opptil 1024 (spesifisert for hver test), samtidig som man unngikk overdreven kontekstveksling og andre relaterte bivirkninger fra å påvirke ytelsesresultatene.
Tabell 2 Klient test seng
|
Antall klientnoder |
16 |
|
Klientnode |
C6320 |
|
Prosessorer per klientnode |
2x Intel (R) Xeon (R) Gold E5-2697v4 18 kjerner @ 2,30 GHz |
|
Minne per klientnode |
8 x 16 GiB, 2400 MT/s RDIMM-er (128 GiB) |
|
BIOS |
2.8.0 |
|
OS-kjerne |
3.10.0-957.10.1 |
|
Programvare for filsystem |
Spektrumskala (GPFS) 5.0.4-3 med NVMesh 2.0.1 |
Sekvensiell IOzone ytelse N-klienter til N-filer
Sekvensielle N-klienter til N-filers ytelse ble målt med IOzone versjon 3.487. Testene som ble utført varierte fra en enkelt tråd opp til 1024 tråder i trinn på potenser på to.
Caching-effekter på serverne ble minimert ved å sette GPFS-sidebassenget justerbart til 16GiB og bruke filer større enn to ganger den størrelsen. Det er viktig å merke seg at for GPFS angir den justerbare mengden minne som brukes til hurtigbufring av data, uavhengig av hvor mye RAM som er installert og ledig. Det er også viktig å merke seg at mens blokkstørrelsen for store, sekvensielle overføringer er 1 MiB i tidligere DellEMC HPC-løsninger, ble GPFS formatert med 8 MiB-blokker, og derfor brukes denne verdien på referansemålingen for optimal ytelse. Det kan se for stort ut og tilsynelatende kaste bort for mye plass, men GPFS bruker tildeling av underblokker for å forhindre den situasjonen. I den nåværende konfigurasjonen ble hver blokk delt inn i 256 underblokker på 32 KiB hver.
Følgende kommandoer ble brukt til å utføre referanseindeksen for skriving og lesing, der $Threads var variabelen med antall tråder som ble brukt (1 til 1024 økt i potens av to), og trådliste var filen som tildelte hver tråd på en annen node, ved hjelp av rund robin for å spre dem homogent over de 16 beregningsnodene.
For å unngå mulige databufringseffekter fra klientene, var den totale datastørrelsen på filene dobbelt så mye RAM som i klientene som ble brukt. Det vil si at siden hver klient har 128 GiB RAM, for tråder teller lik eller over 16 tråder, var filstørrelsen 4096 GiB delt på antall tråder (variabelen $Size nedenfor ble brukt til å administrere den verdien). For de tilfellene med mindre enn 16 tråder (som innebærer at hver tråd kjørte på en annen klient), ble filstørrelsen fast til dobbelt så mye minne per klient, eller 256 GiB.
iozone -i0 -c -e -w -r 8M -s $ G -t $Threads -+n -+m ./threadlist
iozone -i1 -c -e -w -r 8M -s $ G -t $Threads -+n -+m ./threadlist
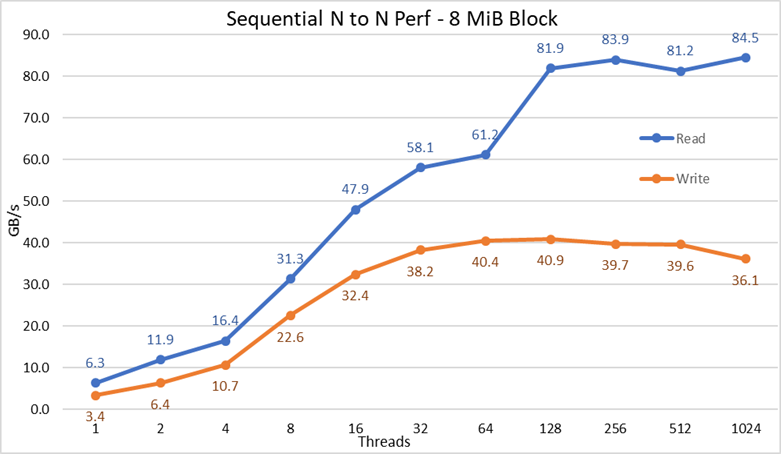
Figur 2 N-til-N sekvensiell ytelse
Fra resultatene kan vi observere at skriveytelsen stiger med antall tråder som brukes, og når deretter et platå på rundt 64 tråder for skriving og 128 tråder for lesing. Da stiger leseytelsen også raskt med antall tråder, og forblir deretter stabil til maksimalt antall tråder som IOzone tillater er nådd, og derfor er sekvensiell ytelse for store filer stabil selv for 1024 samtidige klienter. Skriveytelsen faller ca. 10 % ved 1024 tråder. Siden klientklyngen har mindre kjerner enn dette antallet kjerner, er det imidlertid usikkert om ytelsesfallet skyldes bytte og lignende kostnader som ikke observeres i roterende medier (siden NVMe-ventetiden er svært lav sammenlignet med roterende medier), eller om RAID 10-datasynkroniseringen blir en flaskehals. Det trengs flere oppdragsgivere for å avklare dette punktet. En anomali på avlesningene ble observert ved 64 tråder, der ytelsen ikke skalerte med den hastigheten som ble observert for tidligere datapunkter, og deretter på neste datapunkt beveger seg til en verdi svært nær den vedvarende ytelsen. Mer testing er nødvendig for å finne årsaken til en slik anomali, men er utenfor omfanget av denne bloggen.
Maksimal leseytelse for lesing var lavere enn den teoretiske ytelsen til NVMe-enhetene (~102 GB/s), eller ytelsen til EDR-koblinger, selv om man antar at én kobling hovedsakelig ble brukt for NVMe over strukturtrafikk (4x EDR BW ~96 GB/s).
Dette er imidlertid ikke en overraskelse siden maskinvarekonfigurasjonen ikke er balansert med hensyn til NVMe-enhetene og IB HCA-er under hver CPU-kontakt. Én CX6-adapter er under CPU1, mens CPU2 har alle NVMe-enhetene og den andre CX6-adapteren. All lagringstrafikk som bruker den første HCA-en, må bruke UPI-er for å få tilgang til NVMe-enhetene. I tillegg må enhver kjerne i CPU1 som brukes, få tilgang til enheter eller minne som er tilordnet CPU2, slik at datalokaliteten lider, og UPI-koblinger brukes. Det kan forklare reduksjonen for maksimal ytelse, sammenlignet med den maksimale ytelsen til NVMe-enhetene eller linjehastigheten for CX6 HCA-er. Alternativet for å fikse denne begrensningen er å ha en balansert maskinvarekonfigurasjon som innebærer å redusere tettheten til halvparten ved å bruke en R740 med fire x16-spor og bruke to x16 PCIe-utvidelser for å distribuere NVMe-enheter likt på to CPUer og ha en CX6 HCA under hver CPU.
Sekvensiell IOR-ytelse N-klienter til 1 fil
Sekvensielle N-klienter til én enkelt delt filytelse ble målt med IOR versjon 3.3.0, assistert av OpenMPI v4.0.1 for å kjøre ytelsesprøven over de 16 databehandlingsnodene. Testene som ble utført varierte fra en tråd opp til 512 tråder siden det ikke var nok kjerner for 1024 eller flere tråder. Disse ytelsestestene brukte 8 MiB-blokker for optimal ytelse. Den forrige ytelsestestdelen har en mer fullstendig forklaring på hvorfor det er viktig.
Databufringseffekter ble minimert ved å sette GPFS-sidebassenget justerbart til 16 GiB, og den totale filstørrelsen var dobbelt så mye RAM som i klientene som ble brukt. Det vil si at siden hver klient har 128 GiB RAM, for tråder teller lik eller over 16 tråder, var filstørrelsen 4096 GiB, og like mye av den totale ble delt på antall tråder (variabelen $Size nedenfor ble brukt til å administrere den verdien). For de tilfellene med mindre enn 16 tråder (som innebærer at hver tråd kjørte på en annen klient), var filstørrelsen dobbelt så mye minne per klient som ble brukt ganger antall tråder, eller med andre ord, hver tråd ble bedt om å bruke 256 GiB.
Følgende kommandoer ble brukt til å utføre referanseindeksen for skriving og lesing, der $Threads var variabelen med antall tråder som ble brukt (1 til 1024 økt i potens av to), og my_hosts.$Threads er den tilsvarende filen som tildelte hver tråd på en annen node, ved hjelp av rund robin for å spre dem homogent over de 16 beregningsnodene.
mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads --mca btl_openib_allow_ib 1 --mca pml ^ucx --oversubscribe --prefix /mmfs1/perftest/ompi /mmfs1/perftest/lanl_ior/bin/ior -a POSIX -v -i 1 -d 3 -e -k -o /mmfs1/perftest/tst.file -w -s 1 -t 8m -b $ G
mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads --mca btl_openib_allow_ib 1 --mca pml ^ucx --oversubscribe --prefix /mmfs1/perftest/ompi /mmfs1/perftest/lanl_ior/bin/ior -a POSIX -v -i 1 -d 3 -e -k -o /mmfs1/perftest/tst.file -r -s 1 -t 8m -b $ G
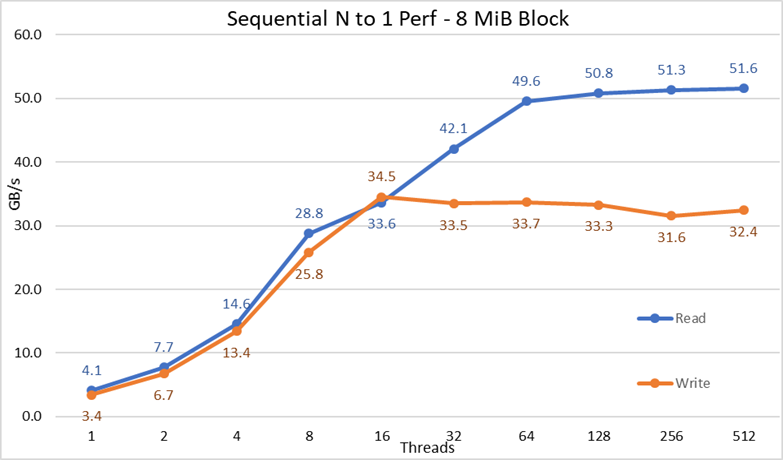
Figur 3 N til 1 – sekvensiell ytelse
Fra resultatene kan vi observere lese- og skriveytelsen er høy uavhengig av det implisitte behovet for låsemekanismer, siden alle tråder får tilgang til samme fil. Ytelsen stiger igjen veldig raskt med antall tråder som brukes, og når deretter et platå som er relativt stabilt for leser og skriver hele veien til maksimalt antall tråder som brukes på denne testen. Legg merke til at maksimal leseytelse var 51,6 GB/s ved 512 tråder, men platået i ytelse er nådd på omtrent 64 tråder. Legg også merke til at maksimal skriveytelse på 34,5 GB/s ble oppnådd ved 16 tråder og nådde et platå som kan observeres inntil maksimalt antall tråder som brukes.
Tilfeldige små blokker IOzone ytelse N-klienter til N-filer
Ytelsen til tilfeldige N-klienter til N-filer ble målt med IOzone versjon 3.487. Testene som ble utført varierte fra en enkelt tråd opp til 1024 tråder i trinn på potenser på to.
Testene som ble utført varierte fra én tråd opp til 512 tråder siden det ikke var nok klientkjerner for 1024 tråder. Hver tråd brukte en annen fil, og trådene ble tildelt round robin på klientnodene. Denne referansetesten brukte 4 KiB-blokker for å etterligne trafikk fra små blokker og bruke en kødybde på 16. Resultatene fra storløsningen og kapasitetsutvidelsen sammenlignes.
Caching-effekter ble igjen minimert ved å sette GPFS-sidebassenget tunable til 16GiB, og for å unngå mulige databufringseffekter fra klientene, var den totale datastørrelsen på filene dobbelt så mye RAM som i klientene som ble brukt. Det vil si at siden hver klient har 128 GiB RAM, for tråder teller lik eller over 16 tråder, var filstørrelsen 4096 GiB delt på antall tråder (variabelen $Size nedenfor ble brukt til å administrere den verdien). For de tilfellene med mindre enn 16 tråder (som innebærer at hver tråd kjørte på en annen klient), ble filstørrelsen fast til dobbelt så mye minne per klient, eller 256 GiB.
iozone -i0 -I -c -e -w -r 8M -s $ G -t $Threads -+n -+m ./nvme_threadlist <= Opprett filene sekvensielt
iozone -i2 -I -c -O -w -r 4k -s $ G -t $Threads -+n -+m ./nvme_threadlist <= Utfør tilfeldige leser og skriver.
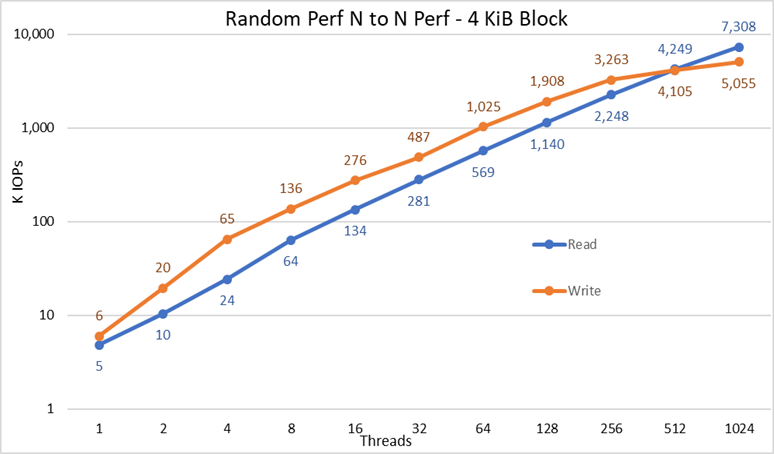
Figur 4 N til N Tilfeldig ytelse
Fra resultatene kan vi observere at skriveytelsen starter med en høy verdi på 6K IOps og stiger jevnt opp til 1024 tråder der det ser ut til å nå et platå med over 5M IOPS hvis flere tråder kunne brukes. Leseytelsen starter derimot ved 5K IOPS-er og øker ytelsen jevnt med antall tråder som brukes (husk at antall tråder dobles for hvert datapunkt) og når maksimal ytelse på 7,3 M IOPS ved 1024 tråder uten tegn til å nå et platå. Bruk av flere tråder vil kreve mer enn de 16 databehandlingsnodene for å unngå ressurssult og overdreven bytte som kan redusere tilsynelatende ytelse, der NVMe-nodene faktisk kan opprettholde ytelsen.
Metadataytelse med MDtest ved hjelp av 4 KiB-filer
Metadataytelsen ble målt med MDtest versjon 3.3.0, assistert av OpenMPI v4.0.1 for å kjøre ytelsesprøven over de 16 databehandlingsnodene. Testene som ble utført varierte fra én tråd opp til 512 tråder. Referanseindeksen ble brukt for filer bare (ingen kataloger metadata), får antall oppretter, statistikk, leser og fjerner løsningen kan håndtere, og resultatene ble kontrastert med stor størrelse løsning.
Den valgfrie High Demand Metadata Module ble brukt, men med en enkelt ME4024-array, selv om den store konfigurasjonen og testet i dette arbeidet ble utpekt til å ha to ME4024. Årsaken til å bruke den metadatamodulen er at disse NVMe-nodene for øyeblikket bare brukes som lagringsmål for data. Nodene kan imidlertid brukes til å lagre data og metadata, eller til og med som et flash-alternativ for metadatamodulen med høy etterspørsel, hvis ekstreme metadatakrav krever det. Disse konfigurasjonene ble ikke testet som en del av dette arbeidet.
Siden den samme metadatamodulen med høy etterspørsel har blitt brukt til tidligere ytelsestesting av DellEMC Ready Solution for HPC PixStor Storage-løsningen, vil metadataresultatene være svært like sammenlignet med tidligere bloggresultater. Av den grunn ble studien med tomme filer ikke gjort, og i stedet ble 4 KiB-filer brukt. Siden 4KiB-filer ikke passer inn i en inode sammen med metadatainformasjonen, vil NVMe-noder bli brukt til å lagre data for hver fil. Derfor kan MDtest gi en grov ide om ytelsen til små filer for lesing og resten av metadataoperasjonene.
Følgende kommando ble brukt til å utføre referansen, hvor $Threads var variabelen med antall tråder som ble brukt (1 til 512 økt i potenser på to), og my_hosts.$Threads er den tilsvarende filen som tildelte hver tråd på en annen node, ved hjelp av rund robin for å spre dem homogent over de 16 beregningsnoder. I likhet med Random IO-referansen var det maksimale antallet tråder begrenset til 512, siden det ikke er nok kjerner for 1024 tråder, og kontekstveksling ville påvirke resultatene, og rapportere et tall lavere enn den virkelige ytelsen til løsningen.
mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads --prefix /mmfs1/perftest/ompi --mca btl_openib_allow_ib 1 /mmfs1/perftest/lanl_ior/bin/mdtest -v -d /mmfs1/perftest/ -i 1 -b $Directories -z 1 -L -I 1024 -y -u -t -F -w 4K -e 4K
Siden ytelsesresultatene kan påvirkes av det totale antallet IOPS, antall filer per katalog og antall tråder, ble det besluttet å holde fast totalt antall filer til 2 MiB-filer (2 ^ 21 = 2097152), antall filer per katalog fast ved 1024, og antall kataloger varierte ettersom antall tråder endret som vist i tabell 3.
Tabell 3 MDtestdistribusjon av filer på kataloger
|
Antall tråder |
Antall kataloger per tråd |
Totalt antall filer |
|
1 |
2048 |
2,097,152 |
|
2 |
1024 |
2,097,152 |
|
4 |
512 |
2,097,152 |
|
8 |
256 |
2,097,152 |
|
16 |
128 |
2,097,152 |
|
32 |
64 |
2,097,152 |
|
64 |
32 |
2,097,152 |
|
128 |
16 |
2,097,152 |
|
256 |
8 |
2,097,152 |
|
512 |
4 |
2,097,152 |
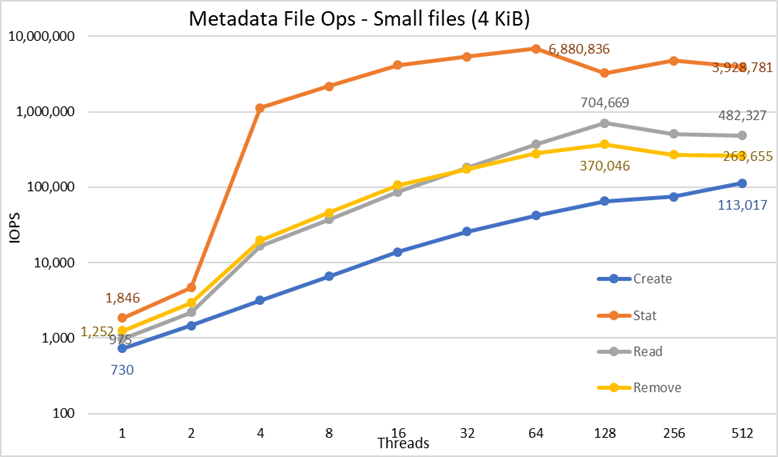
Figur 5 Metadataytelse – 4 KiB-filer
Legg først merke til at den valgte skalaen var logaritmisk med grunntall 10, for å tillate sammenligning av operasjoner som har forskjeller med flere størrelsesordener; Ellers vil noen av operasjonene se ut som en flat linje nær 0 på lineær skala. En logggraf med base 2 kan være mer passende, siden antall tråder økes i potenser på 2, men grafen vil se veldig lik ut, og folk har en tendens til å håndtere og huske bedre tall basert på potenser på 10.
Systemet får svært gode resultater som tidligere rapportert med Stat-operasjoner som når toppverdien ved 64 tråder med nesten 6.9M op / s og reduseres deretter for høyere gjengetall som når et platå. Opprettede operasjoner når maksimalt 113K op/s ved 512 tråder, så det forventes å fortsette å øke hvis flere klientnoder (og kjerner) brukes. Reads and Remove-operasjonene nådde sitt maksimum på 128 tråder, og oppnådde sitt høydepunkt på nesten 705K op/s for Reads og 370K op/s for removes, og deretter når de platåer. Stat-operasjoner har mer variabilitet, men når de når toppverdien, faller ikke ytelsen under 3,2 millioner op/s for statistikk. Opprett og fjern er mer stabile når de når et platå og forblir over 265K op / s for fjerning og 113K op / s for Create. Til slutt når avlesningene et platå med ytelse over 265K op/s.
Konklusjoner og fremtidig arbeid
NVMe-nodene er et viktig tillegg til HPC-lagringsløsningen for å gi et svært høyt ytelsesnivå med god tetthet, svært høy tilfeldig tilgangsytelse og svært høy sekvensiell ytelse. I tillegg skaleres løsningen ut i kapasitet og ytelse lineært etter hvert som flere NVMe-nodemoduler legges til. Ytelsen fra NVMe-nodene kan overses i tabell 4, forventes å være stabil, og disse verdiene kan brukes til å estimere ytelsen for et annet antall NVMe-noder.
Vær imidlertid oppmerksom på at hvert par med NVMe-noder vil gi halvparten av et hvilket som helst tall som vises i tabell 4.
Denne løsningen gir HPC-kunder et svært pålitelig, parallelt filsystem som brukes av mange av de 500 største HPC-klyngene. I tillegg gir den eksepsjonelle søkefunksjoner, avansert overvåking og administrasjon, og å legge til valgfrie gatewayer tillater fildeling via allestedsnærværende standardprotokoller som NFS, SMB og andre til så mange klienter som nødvendig.
Tabell 4: Topp og vedvarende ytelse for to par NVMe-noder
|
|
Førsteklasses ytelse |
Vedvarende ytelse |
||
|
Skrive |
Lese |
Skrive |
Lese |
|
|
Store sekvensielle N-klienter til N-filer |
40,9 GB/s |
84,5 GB/s |
40 GB/s |
81 GB/s |
|
Store sekvensielle N-klienter til én delt fil |
34,5 GB/s |
51,6 GB/s |
31,5 GB/s |
50 GB/s |
|
Tilfeldige små blokker N-klienter til N-filer |
5,06 MIOPS |
7.31MIOPS |
5 MIOPS |
7.3 MIOPS |
|
Metadata: Opprett 4KiB-filer |
113K IOps |
113K IOps |
||
|
Metadata Stat 4KiB-filer |
6,88 M IOps |
3,2 M IOps |
||
|
Metadata Les 4KiB-filer |
705K IOps |
500 K IOps |
||
|
Metadata Fjern 4KiB-filer |
370K IOps |
265 000 IOps |
||
Siden NVMe-noder bare ble brukt til data, kan mulig fremtidig arbeid inkludere bruk av dem for data og metadata og ha et selvstendig flashbasert nivå med bedre metadataytelse på grunn av høyere båndbredde og lavere ventetid for NVMe-enheter sammenlignet med SAS3 SSD-er bak RAID-kontrollere. Alternativt, hvis en kunde har ekstremt høye metadatakrav og krever en løsning som er tettere enn det metadatamodulen med høy etterspørsel kan tilby, kan noen eller alle distribuerte RAID 10-enheter brukes for metadata på samme måte som RAID 1-enheter på ME4024-enhetene brukes nå.
En annen blogg som skal slippes snart, vil karakterisere PixStor Gateway-nodene, som gjør det mulig å koble PixStor-løsningen til andre nettverk ved hjelp av NFS- eller SMB-protokoller og kan skalere ut ytelsen. Løsningen vil også bli oppdatert til HDR100 veldig snart, og en annen blogg forventes å snakke om det arbeidet.
Affected Products
High Performance Computing Solution ResourcesArticle Properties
Article Number: 000130558
Article Type: Solution
Last Modified: 21 Feb 2021
Version: 3
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.