Dell EMC Ready Solution for HPC PixStor Storage - Tier NVMe (in inglese)
Summary: Blog per un componente della soluzione di storage HPC, che include l'architettura e la valutazione delle prestazioni.
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Symptoms
Autore: Mario Gallegos di HPC and AI Innovation Lab, giugno 2020
Blog per un componente della soluzione di storage HPC, che include l'architettura e la valutazione delle prestazioni.
Blog per un componente della soluzione di storage HPC, che include l'architettura e la valutazione delle prestazioni.
Resolution
Dell EMC Ready Solution per HPC nello storage PixStor (in inglese)
Tier NVMe
Sommario
Caratterizzazione delle prestazioni
Prestazioni IOzone sequenziali da N client a N file
Prestazioni IOR sequenziali da N client a 1 file
Prestazioni IOzone per piccoli blocchi casuali da N client a N file
Prestazioni dei metadati con MDtest con file da 4 KiB
Introduzione
Gli ambienti HPC di oggi hanno aumentato la domanda di storage ad altissima velocità e, con un numero superiore di CPU, reti più veloci e memoria di dimensioni maggiori, lo storage stava diventando il collo di bottiglia in molti carichi di lavoro. Questi requisiti ad alte prestazioni tipici dei sistemi HPC (High Performance Computing) sono generalmente soddisfatti dai file system paralleli (PFS), che consentono l'accesso simultaneo a un singolo file o a un insieme di file da parte di più nodi, distribuendo i dati in modo efficiente e sicuro su più LUN e attraverso diversi server. Questi file system sono in genere basati su supporti rotanti per fornire la massima capacità al costo più contenuto. Tuttavia, sempre più spesso, la velocità e la latenza dei supporti rotanti non sono in grado di soddisfare le esigenze di molti carichi di lavoro HPC moderni, rendendo necessario l'impiego della tecnologia Flash sotto forma di burst buffer, tier più veloci o persino aree di scratch, locali o distribuite, ad altissime prestazioni. DellEMC Ready Solution for HPC PixStor Storage utilizza nodi NVMe come componente per rispondere a queste nuove esigenze di elevata larghezza di banda, offrendo al contempo una soluzione flessibile, scalabile, efficiente e affidabile.
Architettura della soluzione
Questo blog fa parte di una serie dedicata alle soluzioni basate su file system paralleli (PFS) per ambienti HPC, in particolare a DellEMC Ready Solution for HPC PixStor Storage, in cui i server DellEMC PowerEdge R640 con unità NVMe vengono utilizzati come tier flash ad alte prestazioni.
La soluzione PixStor PFS include il diffuso General Parallel File System, noto anche come Spectrum Scale. ArcaStream integra numerosi altri componenti software per fornire analisi avanzate, amministrazione e monitoraggio semplificati, ricerca efficiente dei file, funzionalità gateway avanzate e molto altro ancora.
I nodi NVMe presentati in questo blog forniscono un tier flash ad alte prestazioni per la soluzione PixStor. Le prestazioni e la capacità di questo tier NVMe possono essere ampliate aggiungendo ulteriori nodi NVMe. La capacità aggiuntiva viene ottenuta selezionando i dispositivi NVMe appropriati supportati nei PowerEdge R640.
La Figura 1 illustra l'architettura di riferimento che rappresenta una soluzione con 4 nodi NVMe e il modulo dei metadati ad alte prestazioni, che gestisce tutti i metadati nella configurazione testata. In questa configurazione, i nodi NVMe sono stati utilizzati esclusivamente come destinazioni di storage dei dati. Tuttavia, i nodi NVMe possono anche essere configurati per archiviare dati e metadati oppure come alternativa Flash più veloce al modulo dei metadati ad alte prestazioni, nel caso di carichi di lavoro con esigenze estreme di gestione dei metadati. Tali configurazioni dei nodi NVMe non sono state testate nell'ambito di questo lavoro, ma verranno valutate in futuro.
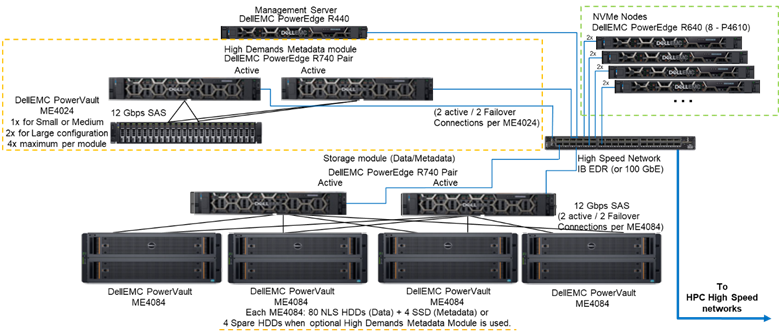
Figura 1 Architettura di riferimento
Componenti della soluzione
Questa soluzione utilizza le più recenti CPU scalabili Intel Xeon di seconda generazione, note anche come CPU Cascade Lake, e la RAM più veloce disponibile (2.933 MT/s), ad eccezione dei nodi di gestione, per mantenerle più economiche. Inoltre, la soluzione è stata aggiornata alla versione più recenti di PixStor (5.1.3.1), che supporta RHEL 7.7 e OFED 5.0, ossia le versioni software che saranno supportate al momento del rilascio.
Ogni nodo NVMe è dotato di 8 dispositivi Dell P4610, configurati come otto dispositivi RAID10 distribuiti su una coppia di server, utilizzando una soluzione NVMe over Fabrics (NVMe-oF) che consente la ridondanza dei dati non solo a livello di dispositivo, ma anche a livello di server. Inoltre, ogni volta che i dati vengono scritti o letti da uno di questi dispositivi RAID10, vengono utilizzate tutte le 16 unità presenti in entrambi i server, aumentando la larghezza di banda complessiva fino a quella totale di tutti i dischi. Pertanto, l'unico vincolo per questi componenti è che devono essere venduti e utilizzati in coppia. Tutte le unità NVMe supportate da PowerEdge R640 possono essere impiegate in questa soluzione; tuttavia, P4610 offre una larghezza di banda sequenziale di 3.200 MB/s sia in lettura che in scrittura, oltre a specifiche di IOPS casuali molto elevate, caratteristiche utili per stimare con precisione il numero di coppie necessarie a soddisfare i requisiti di questo tier Flash.
Ogni server R640 è dotato di 2 schede HCA Mellanox ConnectX-6 Single Port VPI HDR100, utilizzate come connessioni IB EDR a 100 Gb. Tuttavia, i nodi NVMe sono già predisposti per supportare velocità HDR100 quando vengono utilizzati con cavi e switch HDR. I test HDR100 su questi nodi sono stati rimandati e verranno eseguiti nell'ambito dell'aggiornamento HDR100 dell'intera soluzione PixStor. Entrambe le interfacce CX6 vengono utilizzate per sincronizzare i dati di RAID10 (NVMe over Fabrics) e per la connettività del file system. Inoltre, forniscono ridondanza hardware a livello di scheda, porta e cavo. Per la ridondanza a livello di switch, sono richieste schede CX6 VPI a porta doppia, che tuttavia devono essere acquistate come componenti S&P.
Per la caratterizzazione delle prestazioni dei nodi NVMe, dal sistema illustrato in Figura 1 sono stati utilizzati solo il modulo dei metadati ad alte prestazioni e i nodi NVMe.
La Tabella 1 riporta l'elenco dei principali componenti della soluzione. Dall'elenco delle unità supportate in ME4024 sono state impiegate unità SSD da 960 GB per i metadati, utilizzate anche per la caratterizzazione delle prestazioni. Unità più veloci possono offrire IOPS casuali superiori e migliorare le operazioni di creazione/rimozione dei metadati. Tutti i dispositivi NVMe supportati su PowerEdge R640 saranno supportati anche per i nodi NVMe.
Tabella 1 Componenti da utilizzare al momento del rilascio e componenti utilizzati nel banco di prova
|
Al rilascio |
||
|
Connettività interna |
Gigabit Ethernet con Dell Networking S3048-ON |
|
|
Sottosistema di storage dei dati |
Da 1 a 4 Dell EMC PowerVault ME4084 Da 1 a 4 Dell EMC PowerVault ME484 (uno per ME4084) |
|
|
Sottosistema opzionale di storage metadati high-demand |
Da 1 a 2 Dell EMC PowerVault ME4024 (4 ME4024 se necessario, solo configurazione di grandi dimensioni) |
|
|
Controller di storage RAID |
SAS da 12 Gbps |
|
|
Processore |
Nodi NVMe |
2 Intel Xeon Gold 6230 da 2,1 G, 20 C/40 T |
|
Metadati high-demand |
||
|
Storage node |
||
|
Management node |
2 Intel Xeon Gold 5220 da 2,2 G, 18 C/36 T |
|
|
Memoria |
Nodi NVMe |
12 RDIMM da 16 GiB a 2.933 MT/s (192 GiB) |
|
Metadati high-demand |
||
|
Storage node |
||
|
Management node |
12 DIMM da 16 GB, 2.666 MT/s (192 GiB) |
|
|
Sistema operativo |
CentOS 7.7 |
|
|
Versione del kernel |
3.10.0-1062.12.1.el7.x86_64 |
|
|
Software PixStor |
5.1.3.1 |
|
|
Software del file system |
Spectrum Scale (GPFS) 5.0.4-3 con NVMesh 2.0.1 |
|
|
Connettività di rete a prestazioni elevate |
Nodi NVMe: 2 ConnectX-6 InfiniBand che utilizzano EDR/100 GbE |
|
|
Switch a prestazioni elevate |
2 Mellanox SB7800 |
|
|
Versione di OFED |
Mellanox OFED 5.0-2.1.8.0 |
|
|
Dischi locali (sistema operativo e analisi/monitoraggio) |
Tutti i server eccetto quelli elencati Nodi NVMe 3 SSD SAS3 da 480 GB (RAID1 + HS) per il sistema operativo 3 SSD SAS3 da 480 GB (RAID1 + HS) per il sistema operativo Controller RAID PERC H730P Controller RAID PERC H740P Management node 3 SSD SAS3 da 480 GB (RAID1 + HS) per il sistema operativo con controller RAID PERC H740P |
|
|
Gestione dei sistemi |
iDRAC 9 Enterprise + Dell EMC OpenManage |
|
Caratterizzazione delle prestazioni
Per caratterizzare questo nuovo componente Ready Solutions, sono stati utilizzati i seguenti benchmark:
· IOzone da N a N sequenziale
· IOR da N a 1 sequenziale
· IOzone casuale
· MDtest
Per tutti i benchmark elencati in precedenza, il banco di prova ha usato i client descritti nella Tabella 2 riportata di seguito. Poiché il numero di nodi di elaborazione disponibili per il test era di soli 16, quando era richiesto un numero più elevato di thread, questi thread venivano distribuiti equamente sui nodi di elaborazione (ossia 32 thread = 2 thread per nodo, 64 thread = 4 thread per nodo, 128 thread = 8 thread per nodo, 256 thread = 16 thread per nodo, 512 thread = 32 thread per nodo, 1.024 thread = 64 thread per nodo). L'intenzione era quella di simulare un numero più elevato di client simultanei con il numero limitato di nodi di elaborazione disponibili. Poiché alcuni benchmark supportano un numero elevato di thread, è stato utilizzato un valore massimo fino a 1.024 (specificato per ogni test), evitando al contempo che un eccessivo cambio di contesto e altri effetti collaterali correlati influissero sui risultati delle prestazioni.
Tabella 2 Banco di prova client
|
Numero di nodi client |
16 |
|
Nodo client |
C6320 |
|
Processori per nodo client |
2 Intel(R) Xeon(R) Gold E5-2697v4 a 18 core, 2,30 GHz |
|
Memoria per nodo client |
8 RDIMM da 16 GiB 2.400 MT/s (128 GiB) |
|
BIOS |
2.8.0 |
|
OS Kernel |
3.10.0-957.10.1 |
|
Software del file system |
Spectrum Scale (GPFS) 5.0.4-3 con NVMesh 2.0.1 |
Prestazioni IOzone sequenziali da N client a N file
Le prestazioni sequenziali da N client a N file sono state misurate con IOzone versione 3.487. I test eseguiti variavano da single thread fino a 1.024 thread in incrementi di due.
Gli effetti di caching sono stati ridotti al minimo impostando il pool di pagine GPFS regolabile su 16 GiB e utilizzando file di dimensioni due volte superiori. Questo va notato per GPFS che regolano la quantità massima di memoria utilizzata per la memorizzazione nella cache dei dati, indipendentemente dalla quantità di RAM installata e libera. Inoltre, è importante notare che, sebbene nelle precedenti soluzioni HPC Dell EMC le dimensioni del blocco per i trasferimenti sequenziali di grandi dimensioni siano pari a 1 MiB, GPFS è stato formattato con blocchi da 8 MiB e quindi tale valore viene utilizzato nel benchmark per prestazioni ottimali. Potrebbe sembrare troppo grande e apparire come un eccessivo spreco di spazio, ma GPFS utilizza l'allocazione dei sottoblocchi per evitare questa situazione. Nella configurazione corrente, ciascun blocco è stato suddiviso in 256 blocchi secondari da 32 KiB ciascuno.
I seguenti comandi sono stati utilizzati per eseguire i benchmark di scrittura e lettura, dove $Threads rappresentava la variabile contenente il numero di thread utilizzati (da 1 a 1.024, incrementati come potenze di due), e threadlist era il file che allocava ciascun thread a un nodo diverso, distribuendoli in modo omogeneo tra i 16 nodi di elaborazione tramite Round Robin.
Per evitare possibili effetti di caching dei dati dai client, la dimensione totale dei file è stata impostata pari al doppio della quantità totale di RAM presente nei client utilizzati. In pratica, poiché ogni client dispone di 128 GiB di RAM, per conteggi di thread pari o superiori a 16, la dimensione del file è stata impostata su 4.096 GiB divisa per il numero di thread (per gestire tale valore è stata utilizzata la variabile $Size riportata di seguito). Per i casi con meno di 16 thread (il che implica che ogni thread veniva eseguito su un client diverso), la dimensione del file è stata fissata a 256 GiB, ovvero il doppio della memoria per client.
iozone -i0 -c -e -w -r 8M -s $ G -t $Threads -+n -+m ./threadlist
iozone -i1 -c -e -w -r 8M -s $ G -t $Threads -+n -+m ./threadlist
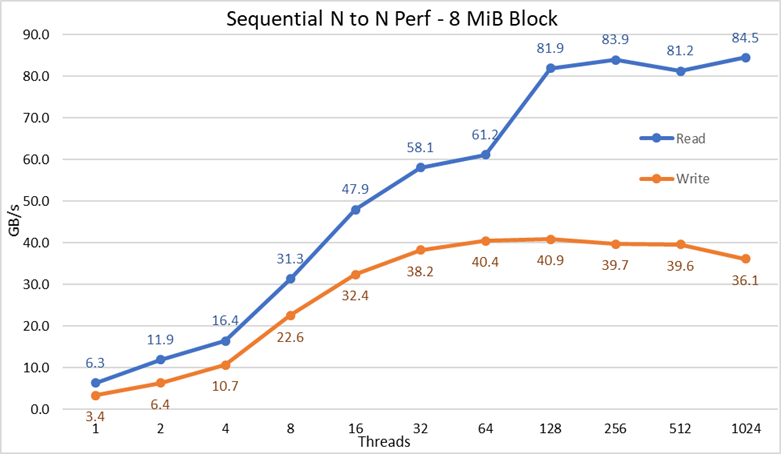
Figura 2 Prestazioni sequenziali da N a N
Dai risultati si può osservare che le prestazioni in scrittura aumentano con il numero di thread utilizzati, per poi raggiungere un plateau intorno a 64 thread per le scritture e 128 thread per le letture. Le prestazioni in lettura crescono rapidamente con l'aumentare dei thread e poi si mantengono stabili fino al numero massimo di thread consentito da IOzone; di conseguenza, le prestazioni sequenziali su file di grandi dimensioni rimangono costanti anche con 1.024 client concorrenti. Le prestazioni in scrittura mostrano un calo di circa il 10% a 1.024 thread. Tuttavia, poiché il cluster di client dispone di un numero di core inferiore, non è certo se tale riduzione sia dovuta a swapping o ad altri overhead non rilevabili sui supporti rotanti (dato che la latenza NVMe è molto più bassa rispetto a quella dei supporti rotanti) oppure se la sincronizzazione dei dati RAID10 rappresenti un collo di bottiglia. Sono necessari più clienti per chiarire questo aspetto. È stata inoltre rilevata un'anomalia nelle letture a 64 thread, dove le prestazioni non sono aumentate con lo stesso andamento osservato nei data point precedenti, ma nel data point successivo sono tornate a un valore molto vicino alle prestazioni sostenute. Sono necessari ulteriori test per identificare la causa di tale anomalia, ma ciò esula dallo scopo di questo blog.
Le prestazioni massime in lettura risultano inferiori alle prestazioni teoriche dei dispositivi NVMe (circa 102 GB/s) o alle prestazioni dei collegamenti EDR, anche ipotizzando che uno di essi fosse utilizzato principalmente per il traffico NVMe over Fabrics (4 × EDR BW circa 96 GB/s).
Tuttavia, questo risultato non è sorprendente, poiché la configurazione hardware non è bilanciata in termini di distribuzione dei dispositivi NVMe e delle schede HCA IB tra i due socket CPU. Una scheda CX6 è collegata alla CPU1, mentre la CPU2 ospita tutti i dispositivi NVMe e la seconda scheda CX6. Di conseguenza, qualsiasi traffico di storage che utilizzi la prima scheda HCA deve utilizzare i collegamenti UPI per accedere ai dispositivi NVMe. Inoltre, qualsiasi core in esecuzione sulla CPU1 deve accedere a dispositivi o memoria assegnati alla CPU2, con conseguente riduzione della località dei dati e utilizzo dei collegamenti UPI. Questo può spiegare la diminuzione delle prestazioni massime rispetto a quelle teoriche dei dispositivi NVMe o alla velocità di linea delle schede CX6 HCA. L'alternativa per risolvere questa limitazione è adottare una configurazione hardware bilanciata, il che comporta la riduzione della densità a metà utilizzando un sistema R740 con quattro slot x16 e due expander PCIe x16 per distribuire equamente i dispositivi NVMe tra le due CPU e avere una scheda HCA CX6 collegata a ciascuna CPU.
Prestazioni IOR sequenziali da N client a 1 file
Le sequenziali da N client a un singolo file condiviso sono state misurate con IOR versione 3.3.0, assistita da OpenMPI v4.0.1, per eseguire il benchmark sui 16 nodi di elaborazione. I test eseguiti variavano da 1 fino a 512 thread, poiché non erano presenti core sufficienti per almeno 1.024 thread. Questo test di benchmark ha utilizzato block da 8 MiB per prestazioni ottimali. La sezione precedente sui test di prestazioni fornisce una spiegazione più completa del motivo per cui questo aspetto è importante.
Gli effetti di caching dei dati sono stati ridotti al minimo impostando il pool di pagine GPFS regolabile su 16 GiB, mentre la dimensione totale dei file era pari al doppio della quantità totale di RAM presente nei client utilizzati. In pratica, poiché ogni client dispone di 128 GiB di RAM, per conteggi di thread pari o superiori a 16, la dimensione del file è stata impostata su 4.096 GiB e una quantità uguale del totale è stata divisa per il numero di thread (per gestire tale valore è stata utilizzata la variabile $Size riportata di seguito). Per i casi con meno di 16 thread (il che implica che ogni thread veniva eseguito su un client diverso), la dimensione del file era pari a due volte la memoria per client utilizzata, moltiplicata per il numero di thread: in altre parole, a ciascun thread venivano assegnati 256 GiB.
I seguenti comandi sono stati utilizzati per eseguire i benchmark di scrittura e lettura, dove $Threads rappresentava la variabile contenente il numero di thread utilizzati (da 1 a 1.024, incrementati come potenze di due), e my_hosts.$Threads era il file corrispondente che allocava ciascun thread a un nodo diverso, distribuendoli in modo omogeneo tra i 16 nodi di elaborazione tramite Round Robin.
mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads --mca btl_openib_allow_ib 1 --mca pml ^ucx --oversubscribe --prefix /mmfs1/perftest/ompi /mmfs1/perftest/lanl_ior/bin/ior -a POSIX -v -i 1 -d 3 -e -k -o /mmfs1/perftest/tst.file -w -s 1 -t 8m -b $ G
mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads --mca btl_openib_allow_ib 1 --mca pml ^ucx --oversubscribe --prefix /mmfs1/perftest/ompi /mmfs1/perftest/lanl_ior/bin/ior -a POSIX -v -i 1 -d 3 -e -k -o /mmfs1/perftest/tst.file -r -s 1 -t 8m -b $ G
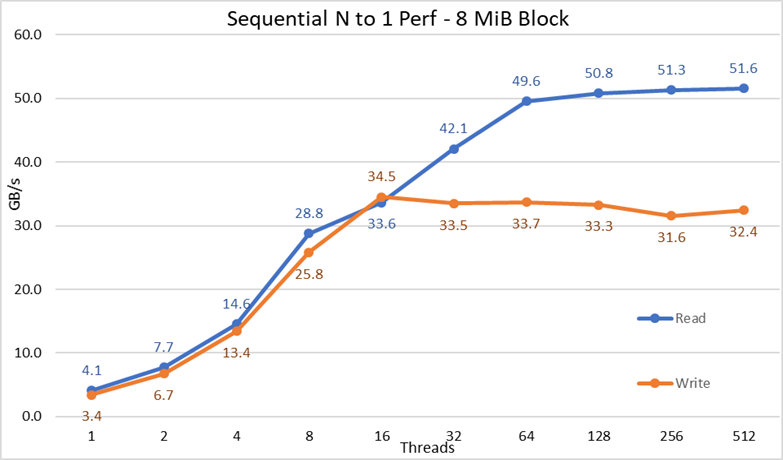
Figura 3 Prestazioni sequenziali da N a 1
Dai risultati si può osservare che le prestazioni in lettura e scrittura sono elevate, indipendentemente dalla necessità implicita di meccanismi di blocco, poiché tutti i thread accedono allo stesso file. Le prestazioni aumentano nuovamente in modo molto rapido con il numero di thread utilizzati e poi raggiungono un plateau relativamente stabile, sia per le letture che per le scritture, fino al numero massimo di thread impiegati in questo test. Si noti che le prestazioni massime in lettura sono state di 51,6 GB/s con 512 thread, ma il plateau delle prestazioni viene raggiunto intorno ai 64 thread. Allo stesso modo, le prestazioni massime in scrittura, pari a 34,5 GB/s, sono state ottenute con 16 thread e il plateau rimane osservabile fino al numero massimo di thread utilizzato.
Prestazioni IOzone per piccoli blocchi casuali da N client a N file
Le prestazioni sequenziali da N client a N file sono state misurate con IOzone versione 3.487. I test eseguiti variavano da single thread fino a 1.024 thread in incrementi di due.
I test eseguiti variavano da 1 fino a 512 thread, poiché non erano presenti core sufficienti core di client per 1.024 thread. Ogni thread utilizzava un file diverso e ai thread veniva assegnato Round Robin sui nodi client. Questo test di benchmark ha utilizzato blocchi da 4 KiB per emulare il traffico di piccoli blocchi e utilizzare una profondità della coda di 16. I risultati ottenuti dalla soluzione di grandi dimensioni e quelli relativi all'espansione della capacità sono stati messi a confronto.
Gli effetti di caching sono stati nuovamente ridotti al minimo impostando il pool di pagine GPFS regolabile su 16 GiB e, per evitare possibili effetti di caching dei dati dai client, la dimensione totale dei file è stata impostata pari al doppio della quantità totale di RAM presente nei client utilizzati. In pratica, poiché ogni client dispone di 128 GiB di RAM, per conteggi di thread pari o superiori a 16, la dimensione del file è stata impostata su 4.096 GiB divisa per il numero di thread (per gestire tale valore è stata utilizzata la variabile $Size riportata di seguito). Per i casi con meno di 16 thread (il che implica che ogni thread veniva eseguito su un client diverso), la dimensione del file è stata fissata a 256 GiB, ovvero il doppio della memoria per client.
iozone -i0 -I -c -e -w -r 8M -s $ G -t $Threads -+n -+m ./nvme_threadlist <= Create the files sequentially
iozone -i2 -I -c -O -w -r 4k -s $ G -t $Threads -+n -+m ./nvme_threadlist <= Perform the random reads and writes.

Figura 4 Prestazioni casuali da N a N
Dai risultati si può osservare che le prestazioni in scrittura partono da un valore elevato di circa 6.000 IOPS e aumentano progressivamente fino a 1.024 thread, dove sembrano raggiungere un plateau con oltre 5 milioni di IOPS, valore che potrebbe continuare a crescere se fosse possibile utilizzare un numero maggiore di thread. Le prestazioni in lettura, invece, iniziano da circa 5.000 IOPS e aumentano costantemente con il numero di thread utilizzati (tenendo presente che il numero di thread raddoppia a ogni data point), raggiungendo una prestazione massima di 7,3 milioni di IOPS a 1.024 thread, senza evidenza di plateau. L'utilizzo di un numero maggiore di thread richiederebbe più di 16 nodi di elaborazione, al fine di evitare esaurimento delle risorse ed eccessivo swapping, fattori che potrebbero ridurre le prestazioni apparenti. In tali condizioni, i nodi NVMe potrebbero in realtà mantenere il livello di prestazioni osservato.
Prestazioni dei metadati con MDtest con file da 4 KiB
Le prestazioni dei metadati sono state misurate con MDtest versione 3.3.0, assistita da OpenMPI v4.0.1, per eseguire il benchmark sui 16 nodi di elaborazione. I test eseguiti variavano da un singolo thread fino a 512 thread. Il benchmark è stato utilizzato esclusivamente per i file (senza includere i metadati delle directory), misurando il numero di operazioni di creazione, statistica, lettura e rimozione che la soluzione è in grado di gestire; i risultati sono stati poi confrontati con quelli della soluzione di grandi dimensioni.
È stato impiegato il modulo opzionale High Demand Metadata, ma con un singolo array ME4024, anche se la configurazione di grandi dimensioni testata in questo lavoro prevedeva due array ME4024. La ragione di questa scelta risiede nel fatto che, attualmente, i nodi NVMe vengono utilizzati come destinazioni di storage solo dati. Tuttavia, i nodi possono essere configurati per archiviare dati e metadati oppure come alternativa Flash per il modulo dei metadati ad alte prestazioni, nel caso di carichi di lavoro con esigenze estreme di gestione dei metadati. Queste configurazioni non sono state testate nell'ambito di questo lavoro.
Poiché lo stesso modulo High Demand Metadata è stato utilizzato anche nei benchmark precedenti della soluzione DellEMC Ready Solution for HPC PixStor Storage, i risultati sui metadati saranno molto simili a quelli riportati nei blog precedenti. Per questo motivo, non è stato effettuato lo studio con file vuoti, ma sono stati utilizzati file da 4 KiB. Poiché i file da 4 KiB non possono essere contenuti interamente in un inode insieme alle relative informazioni di metadati, i nodi NVMe vengono utilizzati per archiviare i dati di ciascun file. Di conseguenza, MDtest fornisce un'indicazione approssimativa delle prestazioni sui file di piccole dimensioni, sia per le operazioni di lettura, sia per le altre operazioni sui metadati.
Il seguente comando è stato utilizzato per eseguire il benchmark, dove $Threads rappresentava la variabile contenente il numero di thread utilizzati (da 1 a 512, incrementati come potenze di due), e my_hosts.$Threads era il file corrispondente che allocava ciascun thread a un nodo diverso, distribuendoli in modo omogeneo tra i 16 nodi di elaborazione tramite Round Robin. Analogamente al benchmark di IO casuale, il numero massimo di thread è stato limitato a 512, poiché non sono presenti core sufficienti per 1024 thread e il cambio di contesto avrebbe influito sui risultati, riportando un numero inferiore rispetto alle prestazioni reali della soluzione.
mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads --prefix /mmfs1/perftest/ompi --mca btl_openib_allow_ib 1 /mmfs1/perftest/lanl_ior/bin/mdtest -v -d /mmfs1/perftest/ -i 1 -b $Directories -z 1 -L -I 1024 -y -u -t -F -w 4K -e 4K
Poiché i risultati delle prestazioni possono essere influenzati dal numero totale di IOPS, dal numero di file per directory e dal numero di thread, è stato deciso di mantenere fisso il numero totale di file in 2 file MiB (2^21 = 2.097.152), il numero di file per directory fisso a 1.024 e il numero di directory variato al variare del numero di thread, come illustrato nella Tabella 3.
Tabella 3 Distribuzione MDtest dei file sulle directory
|
Numero di thread |
Numero di directory per thread |
Numero totale di file |
|
1 |
2048 |
2.097.152 |
|
2 |
1024 |
2.097.152 |
|
4 |
512 |
2.097.152 |
|
8 |
256 |
2.097.152 |
|
16 |
128 |
2.097.152 |
|
32 |
64 |
2.097.152 |
|
64 |
32 |
2.097.152 |
|
128 |
16 |
2.097.152 |
|
256 |
8 |
2.097.152 |
|
512 |
4 |
2.097.152 |
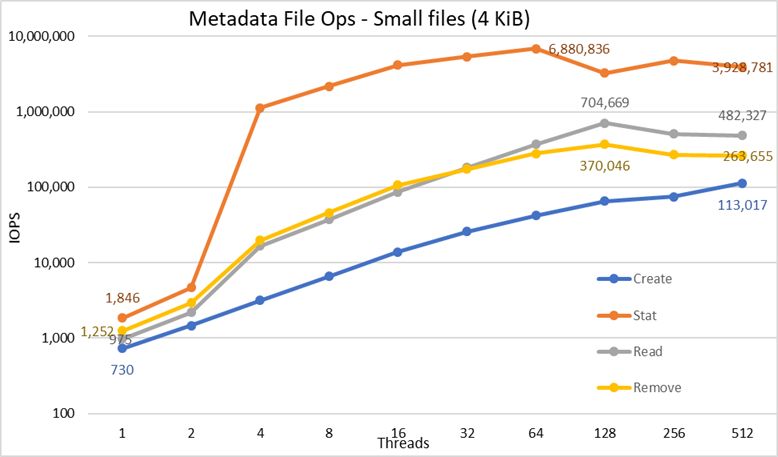
Figura 5 Prestazioni dei metadati - File da 4 KiB
In primo luogo, si noti che è stata scelta la scala logaritmica con base 10, per consentire il confronto di operazioni che presentano differenze di diversi ordini di grandezza; altrimenti, alcune operazioni sarebbero apparse come una linea piatta vicina allo 0 su una scala lineare. Un grafico logaritmico con base 2 potrebbe essere più appropriato, poiché il numero di thread aumenta per potenze di 2, ma il grafico sembrerebbe molto simile e le persone tendono a gestire e ricordare meglio i valori basati su potenze di 10.
Il sistema mostra risultati molto buoni, come già riportato in precedenza, con le operazioni di statistica che raggiungono il valore di picco a 64 thread, con quasi 6,9 milioni di operazioni al secondo, per poi diminuire ai valori superiori di thread fino a raggiungere un plateau. Le operazioni di creazione raggiungono il massimo di 113.000 operazioni al secondo con 512 thread e si prevede che possano continuare a crescere se vengono utilizzati più nodi client (e core). Le operazioni di lettura e rimozione raggiungono il massimo a 128 thread, con picchi rispettivamente di circa 705.000 operazioni al secondo per le letture e 370.000 per le rimozioni, dopodiché si stabilizzano in un plateau. Le operazioni di statistica hanno più variabilità, ma una volta raggiunto il valore di picco, le prestazioni non scendono al di sotto di 3,2 milioni operazioni al secondo. Le operazioni di creazione e rimozione sono più stabili una volta raggiunto un plateau e rimangono al di sopra di 265.000 operazioni al secondo per la rimozione e 113.000 per la creazione. Infine, le letture raggiungono un plateau con prestazioni superiori a 265.000 operazioni al secondo.
Conclusioni e lavoro futuro
I nodi NVMe rappresentano un'importante aggiunta alla soluzione di storage HPC, in quanto forniscono un tier ad altissime prestazioni, caratterizzato da elevata densità, altissime prestazioni in accesso casuale e altissime prestazioni sequenziali. Inoltre, la soluzione scala linearmente in termini di capacità e prestazioni man mano che vengono aggiunti ulteriori moduli di nodi NVMe. Le prestazioni dei nodi NVMe, riassunte nella Tabella 4, sono previste come stabili e i valori riportati possono essere utilizzati per stimare le prestazioni per un numero diverso di nodi NVMe.
È importante tuttavia ricordare che ogni coppia di nodi NVMe fornisce la metà dei valori mostrati nella Tabella 4.
Questa soluzione fornisce ai clienti HPC un file system parallelo molto affidabile utilizzato da molti dei primi 500 cluster HPC. Inoltre, mette a disposizione funzionalità avanzate di ricerca, monitoraggio e gestione e, tramite l'aggiunta di gateway opzionali, consente la condivisione dei file tramite protocolli standard ampiamente diffusi come NFS, SMB e altri, verso un numero di client qualsiasi.
Tabella 4 Prestazioni di picco e sostenute per 2 coppie di nodi NVMe
|
|
Prestazioni di picco |
Prestazioni sostenute |
||
|
Write |
Read |
Write |
Read |
|
|
Sequenziali di grandi dimensioni da N client a N file |
40,9 GB/s |
84,5 GB/s |
40 GB/s |
81 GB/s |
|
Sequenziali di grandi dimensioni da N client a file singolo condiviso |
34,5 GB/s |
51,6 GB/s |
31,5 GB/s |
50 GB/s |
|
Blocchi casuali di piccole dimensioni da N client a N file |
5.06MIOPS |
7.31MIOPS |
5 MIOPS |
7,3 MIOPS |
|
File da 4KiB per creazione di metadati |
113.000 IOPS |
113.000 IOPS |
||
|
File da 4KiB per statistiche di metadati |
6,88 MLN IOPS |
3,2 milioni di IOPS |
||
|
File da 4KiB per lettura di metadati |
705.000 IOPS |
500.000 IOPS |
||
|
File da 4KiB per rimozione di metadati |
370.000 IOPS |
265.000 IOPS |
||
Poiché i nodi NVMe sono stati utilizzati esclusivamente per i dati, possibili sviluppi futuri potrebbero includere l'uso degli stessi per dati e metadati, realizzando così un tier completamente basato su Flash, con prestazioni dei metadati superiori grazie alla maggiore larghezza di banda e alla minore latenza dei dispositivi NVMe rispetto alle unità SSD SAS3 collegate a controller RAID. In alternativa, se un cliente presenta esigenze di metadati estremamente elevate e necessita di una soluzione più densa rispetto a quanto offerto dal modulo per metadati ad alte prestazioni, è possibile utilizzare alcuni o tutti i dispositivi RAID10 distribuiti per i metadati, nello stesso modo in cui oggi vengono utilizzati i dispositivi RAID1 negli array ME4024.
Un prossimo blog caratterizzerà i nodi gateway PixStor, che consentono di collegare la soluzione PixStor ad altre reti tramite i protocolli NFS o SMB e che possono scalare le prestazioni in modo orizzontale. Inoltre, la soluzione sarà aggiornata a HDR100 molto presto e un altro articolo sarà dedicato a descrivere tale aggiornamento.
Affected Products
High Performance Computing Solution ResourcesArticle Properties
Article Number: 000130558
Article Type: Solution
Last Modified: 21 Feb 2021
Version: 3
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.