「HPC PixStorストレージ向けDell EMC Readyソリューション - NVMe階層(英語)」
Summary: アーキテクチャとパフォーマンス評価を含む、HPCストレージ ソリューション コンポーネントに関するブログ。
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Symptoms
2020年6月にHPCおよびAI Innovation LabのMario Gallegosにより作成されました
アーキテクチャとパフォーマンス評価を含む、HPCストレージ ソリューション コンポーネントに関するブログ。
アーキテクチャとパフォーマンス評価を含む、HPCストレージ ソリューション コンポーネントに関するブログ。
Resolution
HPC PixStorストレージ向けDell EMC Readyソリューション
NVMe階層
目次
シーケンシャルIOzoneパフォーマンス - NクライアントからNファイル
シーケンシャルIORパフォーマンス - Nクライアントから1ファイル
小ブロック サイズでのIOzoneランダム パフォーマンス - NクライアントからNファイル
4 KiBファイルを使用したMDtestによるメタデータ パフォーマンス
概要
今日のHPC環境では、非常に高速なストレージに対する需要が高まっており、CPU数の増加、ネットワークの高速化、メモリーの大容量化により、ストレージは多くのワークロードのボトルネックとなっていました。このような要求の厳しいHPC要件は通常、並列ファイル システム(PFS)によってカバーされます。並列ファイル システムは、複数のノードから単一のファイルまたは一連のファイルへの同時アクセスを提供し、複数のサーバー間で複数のLUNにデータを非常に効率的かつ安全に分散します。これらのファイル システムは通常、最も低いコストで最大の容量を提供するために、回転式メディアをベースに構成されています。しかし、多くの最新のHPCワークロードの要求に対し、回転式メディアの速度やレイテンシーでは対応しきれないケースが増えており、そのためにバースト バッファー、高速階層、あるいは非常に高速なスクラッチ(ローカルまたは分散型)という形で、フラッシュ テクノロジーを使用する必要が高まっています。DellEMC Ready Solution for HPC PixStor Storageは、柔軟性、拡張性、効率性、信頼性に加えて、このような新しい高帯域幅の需要に対応するコンポーネントとしてNVMeノードを使用しています。
ソリューション アーキテクチャ
このブログは、HPC環境向けの並列ファイル システム(PFS)ソリューションのシリーズの一部です。特に、DellEMC Ready Solution for HPC PixStor Storageを対象としており、NVMeドライブを搭載したDellEMC PowerEdge R640サーバーが高速フラッシュ ベースの階層として使用されています。
PixStorのPFSソリューションには、広く普及しているGeneral Parallel File System(Spectrum Scaleとしても知られる)が含まれています。さらにArcaStreamには、 高度な分析、シンプルな管理と監視、効率的なファイル検索、高度なゲートウェイ機能など、多くのソフトウェア コンポーネントが含まれています。
このブログで紹介したNVMeノードは、PixStorソリューションに非常にハイパフォーマンスなフラッシュベースの階層を提供します。このNVMe階層のパフォーマンスと容量は、追加のNVMeノードによってスケールアウトできます。PowerEdge R640でサポートされている適切なNVMeデバイスを選択することで、容量を増やすことができます。
図1は、4つのNVMeノードを使用し、高負荷メタデータ モジュールを使用したソリューションを描写する参照アーキテクチャを示しています。このモジュールは、テストした構成内のすべてのメタデータを処理します。その理由は、現在これらのNVMeノードがデータ専用ストレージ ターゲットとして使用されているためです。ただし、NVMeノードは、極めて高いメタデータが要求される場合には、データおよびメタデータの保存に使用されたり、高負荷メタデータ モジュールの高速なフラッシュ代替としても使用できます。これらのNVMeノードの構成はこの作業ではテストされていませんが、今後テストが予定されています。
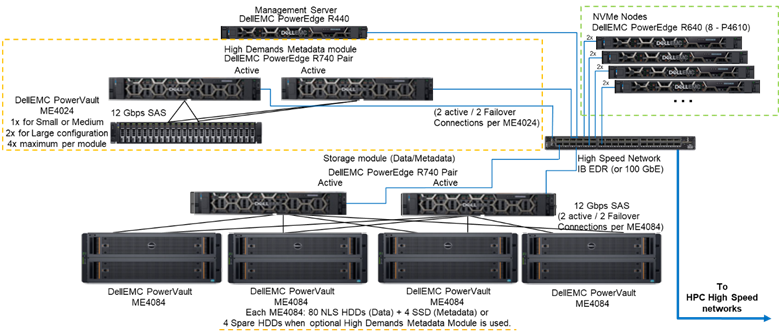
図1参照アーキテクチャ
ソリューション コンポーネント
このソリューションでは、最新のインテルXeon第2世代スケーラブルCPU(別名Cascade Lake CPU)と、使用可能な最速のRAM (2933 MT/s)を採用しています。ただし、管理ノードはコストを抑えるため例外です。さらに、このソリューションは、 リリース時にサポートされるソフトウェア バージョンであるRHEL 7.7とOFED 5.0に対応した最新のPixStorバージョン(5.1.3.1)にアップデートされています。
各NVMeノードには8台のDell P4610デバイスが搭載されており、これらはサーバー ペア間で8台のRAID 10デバイスとして構成されています。NVMe over Fabricソリューションを用いることで、デバイス レベルだけでなくサーバー レベルでもデータの冗長性が確保されています。さらに、これらのRAID10デバイスのいずれかでデータの入出力が行われる際には、両方のサーバーの16台すべてのドライブが使用されるため、アクセスの帯域幅が、すべてのドライブの帯域幅と同じになるように向上します。したがって、これらのコンポーネント対する唯一の制限は、それらをペアで販売し、使用しなければならないことです。このソリューションでは、PowerEdge R640でサポートされているすべてのNVMeドライブを使用できますが、P4610は読み取り/書き込みともにシーケンシャル帯域幅が3200 MB/秒で、高いランダムIOPS仕様も備えているため、このフラッシュ階層の要件を満たすために必要なペアの数をスケールに応じて見積もる際に便利です。
各R640サーバーには、Mellanox ConnectX-6シングル ポートVPI HDR100のHCAが2基搭載されていて、これらはEDR 100 Gb IB接続として使用されています。ただし、NVMeノードはHDRケーブルおよびスイッチとともに使用した場合にHDR100の速度をサポートする準備ができています。これらのノードでのHDR100のテストは、PixStorソリューション全体のHDR100アップデートの一環として後日に実施される予定です。また、両方のCX6インターフェイスは、RAID 10 (NVMe over fabric)のデータ同期とファイル システムの接続に使用されています。さらに、アダプター、ポート、ケーブルでハードウェアの冗長性を提供します。スイッチ レベルでの冗長性を確保するためには、デュアル ポートのCX6 VPIアダプターが必要ですが、これらはS&Pコンポーネントとして調達する必要があります。
図1に示されたシステムにおけるNVMeノードの性能を評価するために、高負荷メタデータ モジュールとNVMeノードのみが使用されました。
表1は、ソリューションの主要なコンポーネントの一覧です。Me4024でサポートされているドライブのリストから、960 GB SSDがメタデータに使用され、性能評価に用いられました。また、より高速なドライブを使用すれば、ランダムIOPSが向上し、メタデータの作成/削除の処理も改善される可能性があります。PowerEdge R640でサポートされているすべてのNVMeデバイスは、NVMeノードでもサポートされます。
表1リリース時に使用されるコンポーネントとテスト ベッドで使用されたコンポーネント
|
リリース時 |
||
|
内部接続 |
Dell Networking S3048-ON Gigabit Ethernet |
|
|
データ ストレージ サブシステム |
1~4 Dell EMC PowerVault ME4084 1~4台のDell EMC PowerVault ME484(ME4084ごとに1台) |
|
|
ハイ デマンド メタデータ ストレージ サブシステム(オプション) |
1~2台のDell EMC PowerVault ME4024(必要に応じて4台のME4024、大規模構成のみ) |
|
|
RAIDストレージ コントローラー |
12 Gbps SAS |
|
|
CPU |
NVMeノード |
2 x インテルXeon Gold 6230、2.1G、20C/40T |
|
ハイ デマンド メタデータ |
||
|
ストレージ ノード |
||
|
管理ノード |
2 x インテルXeon Gold 5220、2.2G、18C/36T |
|
|
メモリー |
NVMeノード |
12 16GiB 2933 MT/s RDIMM (192 GiB) |
|
ハイ デマンド メタデータ |
||
|
ストレージ ノード |
||
|
管理ノード |
12 16GB DIMM、2666 MT/s (192GiB) |
|
|
オペレーティングシステム |
CentOS 7.7 |
|
|
カーネル バージョン |
3.10.0-1062.12.1.el7.x86_64 |
|
|
PixStorソフトウェア |
5.1.3.1 |
|
|
ファイル システム ソフトウェア |
Spectrum Scale (GPFS) 5.0.4-3およびNVMesh 2.0.1 |
|
|
ハイ パフォーマンス ネットワーク接続 |
NVMeノード:2 x ConnectX-6 InfiniBand(EDR/100 GbE対応) |
|
|
ハイ パフォーマンス スイッチ |
2 x Mellanox SB7800 |
|
|
OFEDのバージョン |
Mellanox OFED 5.0-2.1.8.0 |
|
|
ローカル ディスク(OS&分析/監視) |
リストされているNVMeノードを除くすべてのサーバー 3 x 480 GB SSD SAS3 (RAID1 + HS)(OS用) 3 x 480 GB SSD SAS3 (RAID1 + HS)(OS用) PERC H730P RAIDコントローラー PERC H740P RAIDコントローラー 管理ノード 3 x 480GB SSD SAS3 (RAID1 + HS)(OS用。RAIDコントローラーにはPERC H740Pと使用) |
|
|
システム管理 |
iDRAC 9 Enterprise + DellEMC OpenManage |
|
パフォーマンス特性
この新しいReady Solutionコンポーネントの性能を評価するために、次のベンチマークを使用しました。
· IOzone N対Nシーケンシャル
· IOR N対1シーケンシャル
· IOzoneランダム
· MDtest
上記のすべてのベンチマークについて、テスト ベッドには次の表2に記載されているクライアントが使用されました。テストに使用できるコンピューティング ノードの数はわずか16個であったため、より多くのスレッドが必要な場合、それらのスレッドはコンピューティング ノードに均等に分散されました(つまり、32スレッド = ノードあたり2スレッド、64スレッド = ノードあたり4スレッド、128スレッド = ノードあたり8スレッド、256スレッド = ノードあたり16スレッド、512スレッド = ノードあたり32スレッド、1024スレッド = ノードあたり64スレッド)。この目的は、使用できるコンピューティング ノードの数が限られている状態で、より多くの同時クライアント数をシミュレートすることです。一部のベンチマークは多数のスレッドをサポートしているため、各テストで指定された最大1024の値を使用しました。ただし、過度のコンテキスト切り替えやその他の副作用が性能結果に影響を与えないようにしました。
表2クライアント テスト ベッド
|
クライアント ノードの数 |
16 |
|
クライアント ノード |
C6320 |
|
クライアント ノードあたりのプロセッサー数 |
2 x インテル(R) Xeon (R) Gold E5-2697v4 18コア @ 2.30 GHz |
|
クライアント ノードあたりのメモリー |
8 x 16 GiB 2400 MT/s RDIMM (128 GiB) |
|
BIOS |
2.8.0 |
|
OSカーネル |
3.10.0-957.10.1 |
|
ファイル システム ソフトウェア |
Spectrum Scale (GPFS) 5.0.4-3およびNVMesh 2.0.1 |
シーケンシャルIOゾーン パフォーマンス - NクライアントからNファイル
NクライアントからNファイルへのシーケンシャル パフォーマンスは、IOzoneバージョン3.487で測定されました。テストは、単一スレッドから最大1024スレッドまで、2の累乗ごとの増加で実行されました。
サーバーのキャッシュ効果は、調整可能なGPFSページ プールを16 GiBに設定し、ファイル サイズをその2倍以上にすることで、最小限に抑えられました。調整可能なGPFSは、取り付けられているRAMの量や空き容量に関係なく、データのキャッシュに使用されるメモリーの最大量となることに注意してください。また、以前のDell EMC HPCソリューションでは、大規模なシーケンシャル転送のブロック長は1 MiBでしたが、GPFSは8 MiBブロックでフォーマットされているため、最適なパフォーマンスを得るためにベンチマークでその値が使用されていることに注意してください。容量が大きすぎて、スペースが無駄になる可能性がありますが、GPFSはサブブロック割り当てを使用して状況を回避します。現在の構成では、各ブロックは32 KiBの256サブブロックに分割されています。
次のコマンドを使用して書き込みと読み取りのベンチマークを実行しました。ここで、「$Threads」は使用されたスレッド数(1~1024、2乗で増分)を表す変数です。「threadlist」は、各スレッドを異なるノードに割り当てるファイルで、ラウンド ロビンを使用して16個のコンピューティング ノード全体に各スレッドを均一に分散させました。
クライアントからのデータ キャッシュの影響を避けるため、ファイルの合計データ サイズは、使用するクライアントのRAMの合計量の2倍に設定しました。具体的には、各クライアントは128 GiBのRAMを搭載しているため、スレッド数が16以上の場合、ファイル サイズは4096 GiBをスレッド数で割った値になります(この値は次の変数$Sizeで管理しています)。スレッド数が16未満の場合(各スレッドが別々のクライアントで動作していることを意味します)、ファイル サイズはクライアントあたりのメモリー容量の2倍、つまり256 GiBに固定されました。
iozone -i0 -c -e -w -r 8M -s $ G -t $Threads -+n -+m ./threadlist
iozone -i1 -c -e -w -r 8M -s $ G -t $Threads -+n -+m ./threadlist
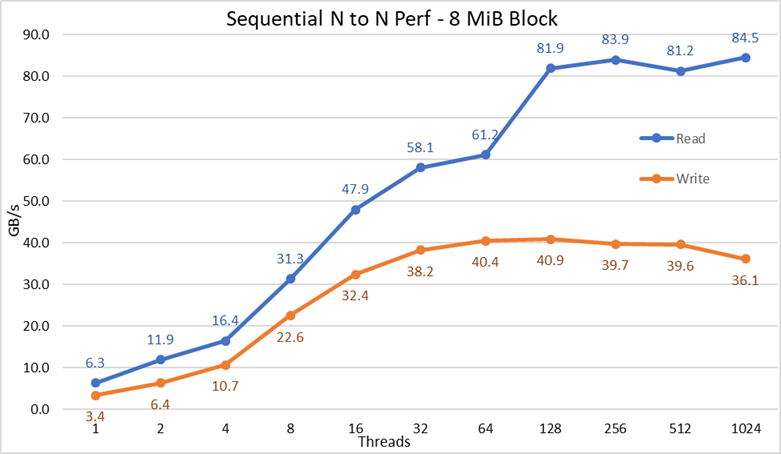
図2 N対Nのシーケンシャル パフォーマンス
結果から分かるように、書き込みパフォーマンスは使用するスレッド数の増加に伴って向上し、約64スレッドで頭打ちになります。一方、読み取りパフォーマンスは約128スレッドでピークに達します。読み取りパフォーマンスも同様に、スレッド数の増加に伴って高速に向上し、IOzoneが許可する最大スレッド数に達するまで安定して推移します。そのため、大容量ファイルのシーケンシャル パフォーマンスは、1024の同時クライアントでも安定しています。なお、書き込みパフォーマンスは1024スレッド時点で約10%低下します。ただし、クライアント クラスターのコア数はそのスレッド数よりも少ないため、パフォーマンスの低下が、回転式メディアで観察されないスワッピングやその他のオーバーヘッド(NVMeのレイテンシーは回転式メディアと比較して非常に低いため)によるものなのか、RAID 10のデータ同期がボトルネックになっているのかは不明です。その点を明確にするには、より多くのクライアントが必要です。読み取りパフォーマンスの異常が64のスレッドで観察されました。それ以前のデータ ポイントで観測された割合でスケーリングせず、次のデータ ポイントでは持続的パフォーマンスに非常に近い値に戻りました。このような異常の原因を見つけるにはさらなるテストが必要ですが、このブログの範囲外です。
読み取りの最大パフォーマンスは、NVMeデバイスの理論上のパフォーマンス(最大102 GB/s)や、EDRリンクのパフォーマンス(たとえ1つのリンクが主にNVMe over Fabricトラフィックに使用されていたと仮定しても、4つで約96 GB/s)を下回りました。
ただし、各CPUソケットのNVMeデバイスとIB HCAのハードウェア構成のバランスが取れていないため、これは驚くことではありません。1つのCX6アダプターはCPU1の下にあり、2つ目のCX6アダプターとすべてのNVMeデバイスはCPU2の下にあります。そのため、最初のHCAを使用するストレージ トラフィックは、UPIを使用してNVMeデバイスにアクセスする必要があります。さらに、CPU1のコアが使用される場合、それらのコアはCPU2に割り当てられたデバイスまたはメモリーにアクセスする必要があるため、データ ローカリティーが低下し、UPIリンクが使用されます。これにより、NVMeデバイスの最大パフォーマンスやCX6 HCAの回線速度と比較して、最大パフォーマンスが低下したことを説明できます。この制限を解消するための代替案は、ハードウェア構成のバランスを取ることです。つまり、4つのx16スロットを備えたR740を使用することで、サーバーあたりの密度を半分に減らし、2つのx16 PCIeエキスパンダーを用いてNVMeデバイスを2つのCPU間で均等に分散し、各CPUに1つずつCX6 HCAを配置するということです。
シーケンシャルIORパフォーマンス - Nクライアントから1ファイル
Nクライアントから単一の共有ファイルへのシーケンシャル パフォーマンスは、IORバージョン3.3.0を使用して測定されました。また、OpenMPI v4.0.1によるアシストにより、16個のコンピューティング ノード上でベンチマークを実行しました。テストは、1スレッドから最大512スレッドまでの範囲で実行されました。これは、1024以上のスレッドに対応できるだけのコア数がなかったためです。このベンチマーク テストでは、最適なパフォーマンスを実現するために8 MiBブロックを使用しました。この制限が重要である理由については、前のパフォーマンス テストのセクションで詳しく説明されています。
データ キャッシュの影響を最小限に抑えるために、GPFSのページ プール値を16 GiBに設定し、ファイルの総サイズは、クライアントの合計RAM容量の2倍に設定しました。すなわち、各クライアントは128 GiBのRAMを持っているため、スレッド数が16以上の場合、ファイル サイズは4096 GiBに設定され、その合計サイズをスレッド数で等分しました(この値の管理には変数$Sizeを使用しました)。16スレッド未満の場合(各スレッドが別々のクライアントで動作していることを意味します)、ファイル サイズは「クライアントあたりのメモリー容量の2倍×スレッド数」となります。言い換えると、各スレッドは256 GiBの使用を要求されました。
次のコマンドを使用して書き込みと読み取りのベンチマークを実行しました。ここで、「$Threads」は使用されたスレッド数(1~1024、2の累乗で増加)を表す変数です。「my_hosts.$Threads」は、各スレッドを異なるノードに割り当てる対応ファイルで、16個のコンピューティング ノードに対してラウンド ロビン方式でスレッドを均一に分散させています。
mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads --mca btl_openib_allow_ib 1 --mca pml ^ucx --oversubscribe --prefix /mmfs1/perftest/ompi /mmfs1/perftest/lanl_ior/bin/ior -a POSIX -v -i 1 -d 3 -e -k -o /mmfs1/perftest/tst.file -w -s 1 -t 8m -b $ G
mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads --mca btl_openib_allow_ib 1 --mca pml ^ucx --oversubscribe --prefix /mmfs1/perftest/ompi /mmfs1/perftest/lanl_ior/bin/ior -a POSIX -v -i 1 -d 3 -e -k -o /mmfs1/perftest/tst.file -r -s 1 -t 8m -b $ G
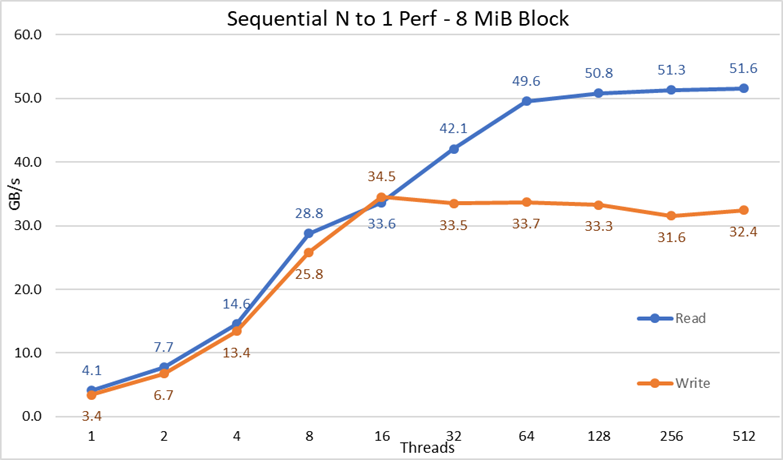
図3 N対1のシーケンシャル パフォーマンス
結果から、すべてのスレッドが同じファイルにアクセスするため、ロック機構の暗黙的な必要性に関係なく、読み取りと書き込みのパフォーマンスが高いことがわかります。パフォーマンスは、スレッドの数の増加に伴って再び急速に上昇し、その後、読み取りと書き込みの両方で比較的安定したプラトーに達し、このテストで使用された最大スレッド数までその状態が維持されました。読み取りパフォーマンスの最大値は、512スレッド時点で51.6 GB/sでしたが、パフォーマンスがプラトーに到達するのは約64スレッドの時点であることに注意してください。同様に、書き込みパフォーマンスの最大値は16スレッド時点で34.5 GB/sに達し、その後も最大スレッド数に至るまでプラトーが継続して観察されました。
小さなブロックを使用したIOzoneランダム パフォーマンス - NクライアントからNファイル
NクライアントからNファイルにアクセスするランダム パフォーマンスは、IOzoneバージョン3.487で測定されました。テストは、単一スレッドから最大1024スレッドまで、2の累乗ごとの増加で実行されました。
テストは、1スレッドから最大512スレッドまでの範囲で実行されました。これは、1024以上のスレッドに対応できるだけのクライアント コア数がなかったためです。各スレッドは異なるファイルを使用して、スレッドはクライアント ノードにラウンド ロビンで割り当てられています。このベンチマーク テストでは、4 KiBのブロックを使用して、小さなブロックのトラフィックをエミュレートし、16のキューの深さを使用しました。大規模ソリューションと容量拡張の結果を比較しました。
キャッシュの影響を再び最小限に抑えるために、GPFSのページ プール値を16 GiBに設定しました。また、クライアントからのデータ キャッシュの影響を避けるため、ファイルの合計データ サイズは、使用するクライアントのRAMの合計量の2倍に設定しました。具体的には、各クライアントは128 GiBのRAMを搭載しているため、スレッド数が16以上の場合、ファイル サイズは4096 GiBをスレッド数で割った値になります(この値は次の変数$Sizeで管理しています)。スレッド数が16未満の場合(各スレッドが別々のクライアントで動作していることを意味します)、ファイル サイズはクライアントあたりのメモリー容量の2倍、つまり256 GiBに固定されました。
iozone -i0 -I -c -e -w -r 8M -s $ G -t $Threads -+n -+m ./nvme_threadlist iozone -i2 -I -c -O -w -r 4k -s $ G -t $Threads -+n -+m ./nvme_threadlist
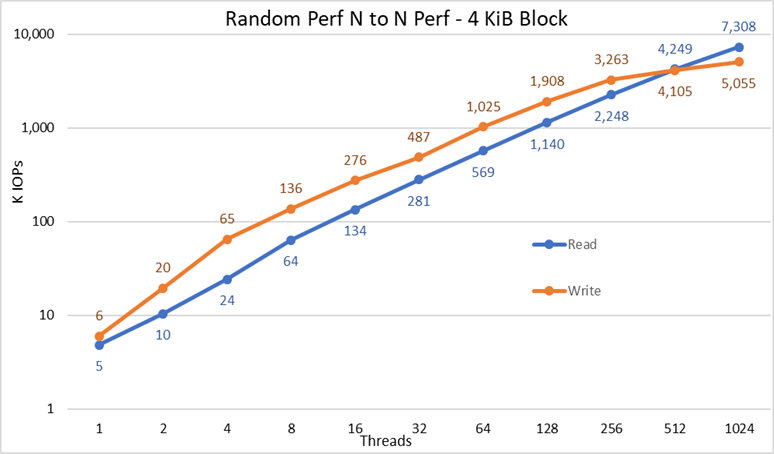
図4 N対Nのランダム パフォーマンス
その結果から、書き込みパフォーマンスは初期値の6K IOPSから始まり、1024スレッドまで着実に上昇します。1024スレッド時点で500万IOPSを超えてプラトーに到達したように見えます(さらにスレッド数を増やせば、より伸びる可能性があります)。一方、読み取りパフォーマンスは5K IOPSから始まり、スレッド数に応じて着実に上昇します(各データ ポイントでスレッド数が2倍になることに注意してください)。また、1024スレッド時点で7.3M IOPSの最大パフォーマンスに達し、プラトーに到達する徴候は見られません。より多くのスレッドを使用するには、コンピューティング ノードを16以上に増やす必要があります。そうしないと、リソースの枯渇や過剰なスワッピングによって見かけ上のパフォーマンスが低下する可能性があるからです。ただし、NVMeノードは実際にはパフォーマンスを維持できる可能性があります。
4 KiBファイルを使用したMDtestによるメタデータ パフォーマンス
メタデータのパフォーマンスは、MDtestバージョン3.3.0で測定されました。また、OpenMPI v4.0.1のアシストにより、16個のコンピューティング ノード上でベンチマークを実行しました。テストは、1つのスレッドから最大512スレッドで実行されました。ベンチマークはファイルのみを対象とし(ディレクトリー メタデータは含まない)、ソリューションが処理できる作成、統計、読み取り、削除の数を取得し、その結果を大規模ソリューションと比較しました。
オプションのHigh Demand Metadata Moduleを使用しましたが、ME4024アレイは1台のみでした。一方で、大規模構成およびこの作業でテストされた構成では2台のME4024があることを前提としていました。メタデータ モジュールを使用する理由は、現在、これらのNVMeノードがデータ専用のストレージ ターゲットとして使用されているためです。ただし、これらのノードは、極めて高いメタデータが要求される場合には、データおよびメタデータの保存に使用されたり、高負荷メタデータ モジュールのフラッシュ代替としても使用できます。これらの構成は、この作業の一環としてテストされていません。
DellEMC Ready Solution for HPC PixStor Storageソリューションの以前のベンチマークにも、同じHigh Demand Metadata Moduleが使用されていたため、今回のメタデータの結果も、以前のブログの結果と非常によく似たものになると考えられます。そのため、空のファイルを含む調査は行わず、代わりに4 KiBファイルを使用しました。4 KiBファイルはメタデータ情報とともにinodeに収まらないため、NVMeノードが各ファイルのデータを格納するために使用されます。したがって、MDtestは、小さなファイルに対する読み取りパフォーマンスおよび他のメタデータ操作のパフォーマンスを大まかに把握できます。
次のコマンドを使用してベンチマークを実行しました。ここで、「$Threads」は使用されたスレッド数(1~512、2のべき乗で増加)を表す変数です。「my_hosts.$Threads」は、各スレッドを16個のコンピューティング ノード全体にラウンド ロビン方式で均一に分散させるための対応ファイルです。ランダムIOベンチマークと同様に、スレッドの最大数は512に制限されました。1024スレッドに十分なコアがなく、コンテキストの切り替えが結果に影響を与えたため、ソリューションの実際のパフォーマンスよりも少ない数値が報告されました。
mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads --prefix /mmfs1/perftest/ompi --mca btl_openib_allow_ib 1 /mmfs1/perftest/lanl_ior/bin/mdtest -v -d /mmfs1/perftest/ -i 1 -b $Directories -z 1 -L -I 1024 -y -u -t -F -w 4K -e 4K
パフォーマンスの結果は、IOPSの合計数、ディレクトリーあたりのファイル数、スレッド数によって影響を受ける可能性があるため、表3に示すように、ファイルの合計数を2 MiBファイル(2^21 = 2097152)に、ディレクトリーあたりのファイル数を1024に固定し、またスレッド数の変更に応じてディレクトリーの数が変わることが決定されました。
表3MDtest:ディレクトリーでのファイルの分配
|
スレッド数 |
スレッドあたりのディレクトリー数 |
ファイルの総数 |
|
1 |
2048 |
2,097,152 |
|
2 |
1024 |
2,097,152 |
|
4 |
512 |
2,097,152 |
|
8 |
256 |
2,097,152 |
|
16 |
128 |
2,097,152 |
|
32 |
64 |
2,097,152 |
|
64 |
32 |
2,097,152 |
|
128 |
16 |
2,097,152 |
|
256 |
8 |
2,097,152 |
|
512 |
4 |
2,097,152 |
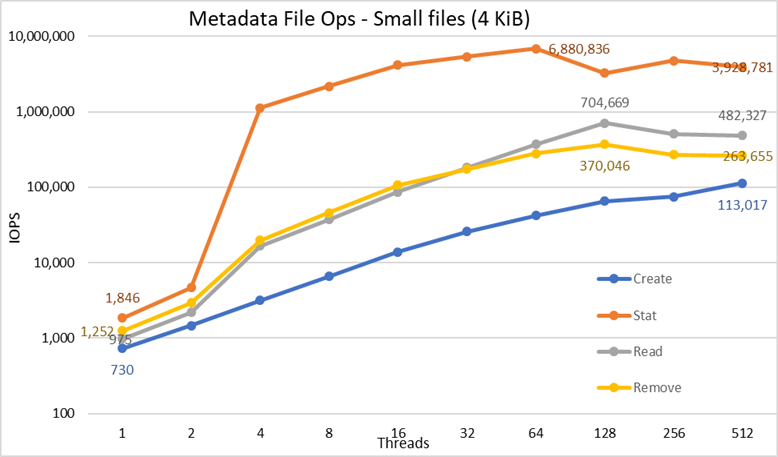
図5 メタデータのパフォーマンス – 4 KiBファイル
まず、選択したスケールが10を基底とする対数スケールであることに注意してください。これは、桁違いの差がある複数の操作を比較するためであり、線形スケールでは一部の操作が0に近いフラットな線のように表示されてしまうためです。スレッドの数が2のべき乗で増加するため、底が2の対数グラフの方が適切である可能性もありますが、グラフの形状自体はほぼ同じになります。一般に、10のべき乗の方が分かりやすく、数値として記憶しやすい傾向があるため、底10が選ばれました。
このシステムは以前に報告されたように非常に良い結果を得ており、Stat操作では64スレッド時に約6.9M op/sのピーク値に達し、その後はスレッド数の増加に伴ってパフォーマンスが低下し、プラトーに到達します。Create操作は、512スレッド時に最大113K op/sに達するため、より多くのクライアント ノード(およびコア)を使用すれば、さらにパフォーマンスが向上する可能性があります。ReadsおよびRemoves操作は128スレッド時に最大に達し、Readsでは約705K op/s、Removesでは約370K op/sに到達した後、プラトーに達します。Stat操作での変動性は高いですが、ピーク値に達した後は、パフォーマンスは3.2M op/sを下回ることはありません。CreateおよびRemoveは、一度プラトーに到達するとより安定し、Createでは113K op/s、Removeでは265K op/s以上を維持します。最終的に、Readは265K op/sを超えるパフォーマンスでプラトーに到達します。
結論および今後の計画
NVMeノードは、HPCストレージ ソリューションに追加された重要なノードです。高密度かつ、非常に高いランダムアクセス パフォーマンスとシーケンシャル パフォーマンスを備え、非常に高性能な階層を提供します。さらに、本ソリューションは、NVMeノード モジュールを追加するにつれて、容量とパフォーマンスが線形的にスケール アウトします。NVMeノードのパフォーマンスは表4にまとめられています。これらの数値は安定しており、異なる数のNVMeノード構成のパフォーマンスを推定する際の目安として使用できます。
ただし、表4に示されている数値は、NVMeノードの1ペアあたりのパフォーマンスの2倍となっていることに注意してください。
このソリューションは、HPCのお客様に、多くの上位500のHPCクラスターで使用される非常に信頼性の高い並列ファイル システムを提供します。さらに、卓越した検索機能、高度なモニタリングと管理を提供し、オプションのゲートウェイを追加することで、NFS、SMBなどのユビキタス標準プロトコルを介して必要な数のクライアントに対してファイル共有を可能にします。
表4 2組のNVMeノードでのピーク時と持続時のパフォーマンス
|
|
ピーク時のパフォーマンス |
継続的なパフォーマンス |
||
|
書き込み |
読み取り |
書き込み |
読み取り |
|
|
大規模 - シーケンシャル - NクライアントからNファイル |
40.9 GB/s |
84.5 GB/s |
40 GB/s |
81 GB/s |
|
大規模 - シーケンシャル - Nクライアントから単一の共有ファイル |
34.5 GB/s |
51.6 GB/s |
31.5 GB/s |
50 GB/s |
|
ランダム - 小さなブロック - NクライアントからNファイル |
5.06 MIOPS |
7.31 MIOPS |
5 MIOPS |
7.3 MIOPS |
|
メタデータ - 作成 - 4KiBファイル |
113K IOps |
113K IOps |
||
|
メタデータ - 統計 - 4KiBファイル |
6.88M IOps |
3.2M IOps |
||
|
メタデータ - 読み取り - 4KiBファイル |
705K IOps |
500K IOps |
||
|
メタデータ - 削除 4KiBファイル |
370K IOps |
265K IOps |
||
NVMeノードはデータにのみ使用されましたが、将来的には、データとメタデータの両方に使用することが考えられます。これにより、自己完結型フラッシュベース階層が構成され、RAIDコントローラー経由のSAS3 SSDと比較して、NVMeデバイスの高帯域、低レイテンシー特性により、より高いメタデータ パフォーマンスが期待できます。また、メタデータの需要が非常に高く、既存の高負荷メタデータ モジュールが提供できるものより高密度のソリューションが求められる場合は、分散RAID 10デバイスの一部またはすべてをメタデータに使用できます。これは、現在ME4024上のRAID 1デバイスが使用されているのと同じ方法です。
今後公開予定の別のブログでは、PixStorゲートウェイ ノードのパフォーマンス評価が行われる予定です。このノードは、PixStorソリューションをNFSやSMBプロトコルを介して他のネットワークに接続でき、パフォーマンスのスケールアウトも可能です。また、このソリューションは近くHDR100にアップデートされる予定であり、その検証についても別のブログで紹介される予定です。
Affected Products
High Performance Computing Solution ResourcesArticle Properties
Article Number: 000130558
Article Type: Solution
Last Modified: 21 Feb 2021
Version: 3
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.