VMware : Guide de dépannage des disques physiques vSAN
Résumé: Il s’agit d’un guide de dépannage général permettant d’identifier s’il existe un problème avec un disque physique dans les clusters vSAN.
Instructions
Vérification de l’état du disque physique vSAN à partir de l’interface utilisateur Web :
Connectez-vous au client Web vCenter Server et vérifiez l’état du disque à partir de :
Inventaire > Hôte et clusters > Cluster vSAN Configuration > de la gestion des disques vSAN > Image 1 : vue Gestion des disques vSAN Sélectionnez l’hôte concerné, puis développez la section Afficher le disque :Image 2 : Vue du groupe de disques vSAN Ici, vous pouvez vérifier si un disque est détecté >comme :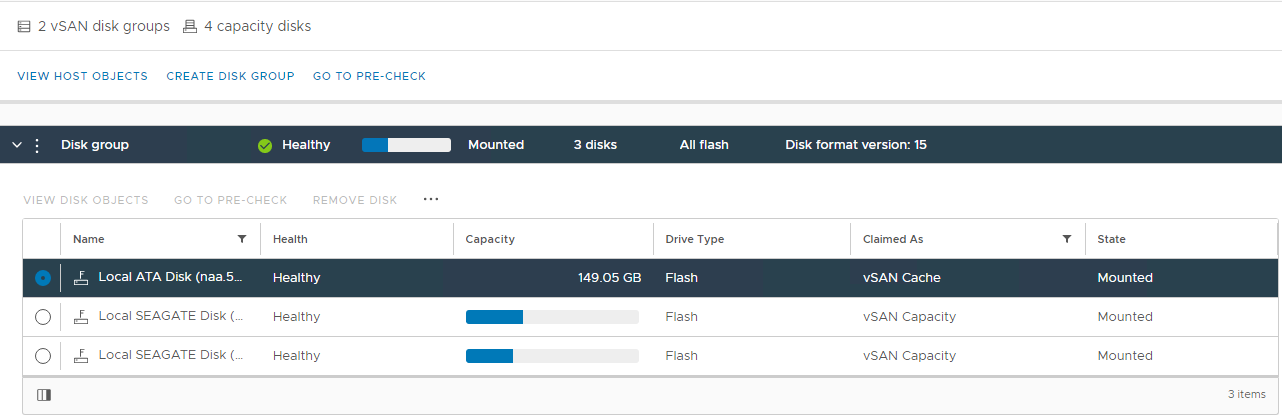
Unhealthy
Unmounted
0 Capacity
permanent disk failure
Disk Down
Disk Absent
En outre, recherchez les alarmes liées aux disques déclenchées à partir de la section Intégrité de Skyline vSAN :
Inventaire > Hôte et clusters > Cluster vSAN Surveiller > vSAN > Intégrité > Skyline Disque physique Image >3 :
Vue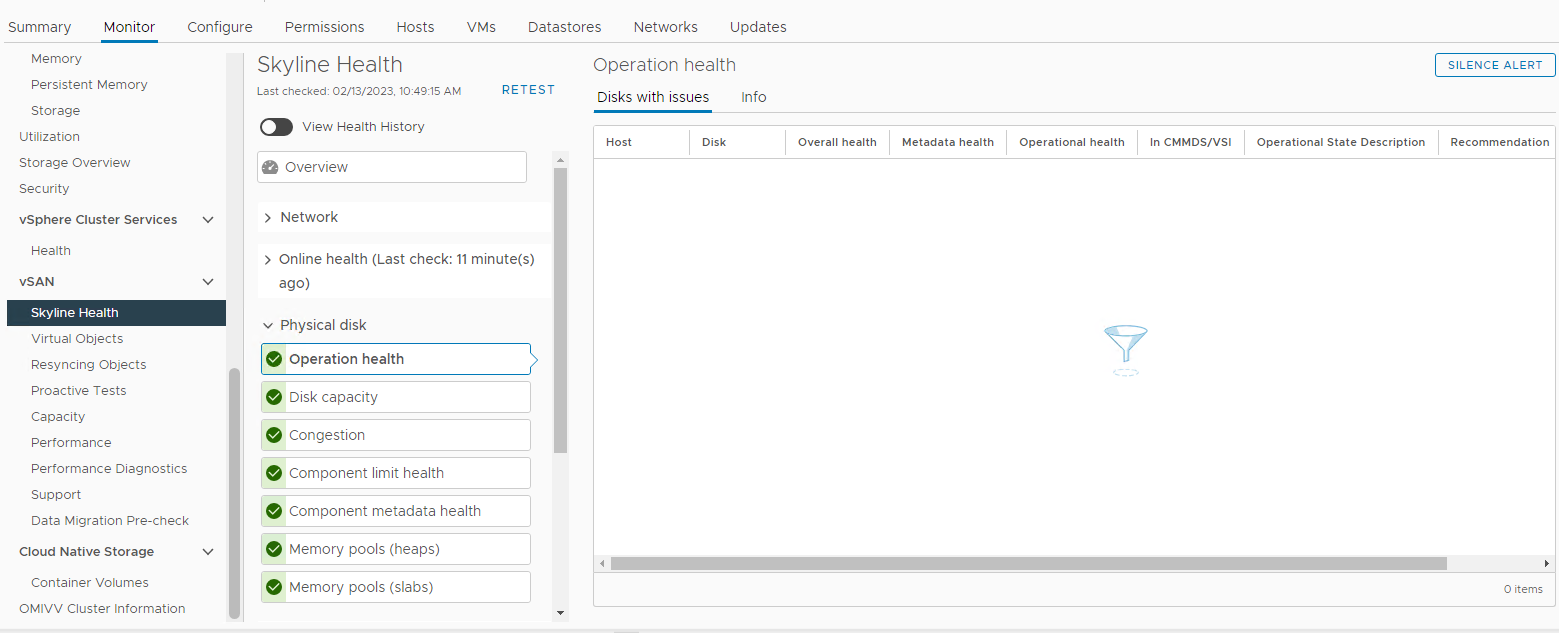
Intégrité Skyline Ici, vous pouvez vérifier si l’une des alarmes suivantes s’est déclenchée :
Impending permanent disk failure, data is being evacuated (Health state - Yellow).Impending permanent disk failure, data evacuation failed due to insufficient resources (Health state - Red).Impending permanent disk failure, data evacuation failed due to inaccessible objects (Health state - Red).Impending permanent disk failure, data evacuation completed (Health state - Yellow)
En outre, vous pouvez vérifier l’état du disque à partir de la liste des périphériques de stockage de l’hôte concerné :
Inventaire > Hôte et clusters > Cluster vSAN Hôte >> ESXi concerné Configurer > le stockage > Périphériques
de stockage Image 4 : Vue
Host Storage Devices Ici, vous pouvez vérifier si l’état d’un disque est :
0 Capacity
Disk Absent
Disk Unmounted
Vérifiez si une resynchronisation est en cours :
Inventaire > Hôte et clusters Surveillance du > cluster >> vSAN Objets de resynchronisation vSAN > :
Image 5 : Resynchronisation de la vue Objects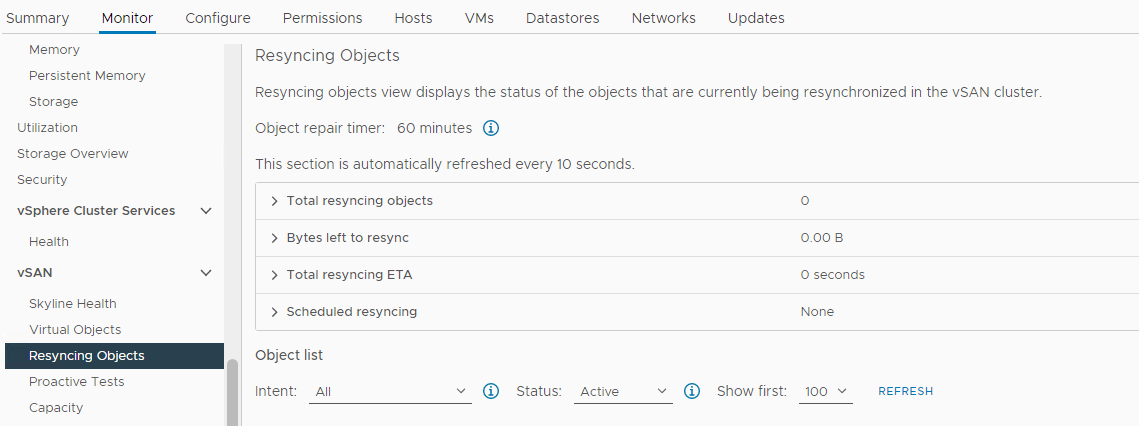
Vérifiez l’état des objets vSAN :
Inventaire > Hôte et clusters Surveillance du cluster > vSAN Données d’intégrité >> vSAN > Skyline Intégrité > de l’objet vSAN Image 6 : vue de l’intégrité de l’objet vSAN >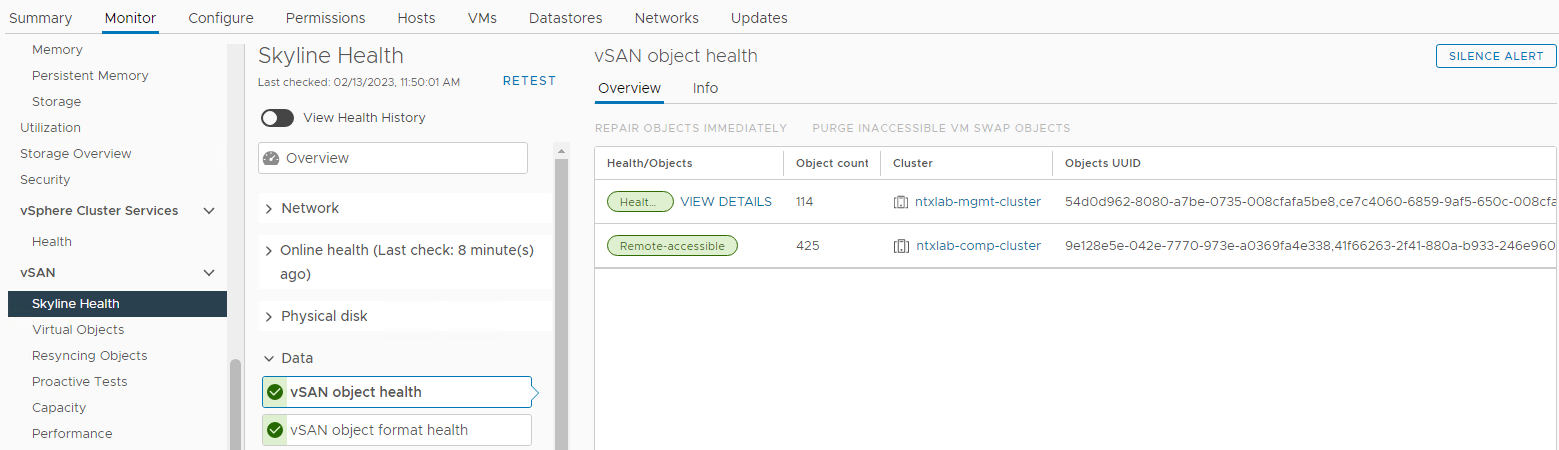
L’étape suivante consiste à recueillir plus d’informations sur le problème via la CLI et à vérifier les journaux :
Vérification de l’état du disque physique vSAN à partir de la CLI :
Connexion via SSH à l’hôte concerné et exécution des commandes suivantes :
vdq -qH
Cochez la case «IsPDL» (perte d’appareil permanente). S’il est égal à 1, le disque est perdu.
Exemple :
DiskResults:
DiskResult[0]:
Name: naa.600508b1001c4b820b4d80f9f8acfa95
VSANUUID: 5294bbd8-67c4-c545-3952-7711e365f7fa
State: In-use for VSAN
ChecksumSupport: 0
Reason: Non-local disk
IsSSD?: 0
IsCapacityFlash?: 0
IsPDL?: 0
<<truncated>>
DiskResult[18]:
Name:
VSANUUID: 5227c17e-ec64-de76-c10e-c272102beba7
State: In-use for VSAN
ChecksumSupport: 0
Reason: None
IsSSD?: 0
IsCapacityFlash?: 0
IsPDL?: 1
vdq -iH
Vérifiez s’il manque un disque dans le groupe de disques.
Exemple :
Mappings: DiskMapping[0]: SSD: naa.58ce38ee2016ffe5 MD: naa.5002538a4819e3e0 DiskMapping[2]: SSD: naa.58ce38ee2016fe55 MD: naa.5002538a48199ca0 MD: naa.5002538a48199e20 MD: naa.5002538a48199e00
esxcli vsan storage list
Vérifiez sur le "In CMMDS" par. Si la valeur est false, la communication est perdue sur le disque.
Exemple :
Device: Unknown
Display Name: Unknown
Is SSD: false
VSAN UUID: 529cadbc-acd1-b588-8643-68336d5512d6
VSAN Disk Group UUID:
VSAN Disk Group Name:
Used by this host: false
In CMMDS: false
On-disk format version: <Unknown>
Deduplication: false
Compression: false
Checksum:
Checksum OK: false
Is Capacity Tier: false
for i in `esxcli storage core device list | grep ^naa` ; do echo $i; esxcli storage core device smart get -d $i; done.
Recherchez les erreurs de lecture/écriture avec la commande smart get.
Exemple :
naa.55cd2e404c1f35a1 Parameter Value Threshold Worst Raw -------------------------- ----- --------- ----- --- Health Status OK N/A N/A N/A Media Wearout Indicator 100 0 100 86 Read Error Count 130 39 130 133 Power-on Hours 100 0 100 110 Power Cycle Count 100 0 100 106 Drive Temperature 100 0 100 26 Uncorrectable Sector Count 100 0 100 0
naa.55cd2e404c1f35a5 Parameter Value Threshold Worst Raw -------------------------- ----- --------- ----- --- Health Status OK N/A N/A N/A Media Wearout Indicator 100 0 100 10 Read Error Count 130 39 130 53 Power-on Hours 100 0 100 110 Power Cycle Count 100 0 100 106 Drive Temperature 100 0 100 27 Uncorrectable Sector Count 100 0 100 0
esxcli vsan storage list | grep "VSAN Disk Group UUID:" | sort | uniq -c
Recherchez les groupes de disques disponibles.
Exemple :
2 VSAN Disk Group UUID: 5203424c-ee56-497d-75d1-fcf73ae997cb 2 VSAN Disk Group UUID: 52af8e5c-77d1-b552-3310-ec5fef09edf4
while true;do echo " ****************************************** "; echo "" > /tmp/resyncStats.txt ;cmmds-tool find -t DOM_OBJECT -f json |grep uuid |awk -F \" '{print $4}' |while read i;do pendingResync=$(cmmds-tool find -t DOM_OBJECT -f json -u $i|grep -o "\"bytesToSync\": [0-9]*,"|awk -F " |," '{sum+=$2} END{print sum / 1024 / 1024 / 1024;}');if [ ${#pendingResync} -ne 1 ]; then echo "$i: $pendingResync GiB";fi;done |tee -a /tmp/resyncStats.txt;total=$(cat /tmp/resyncStats.txt |awk '{sum+=$2} END{print sum}');echo "Total: $total GiB" |tee -aa /tmp/resyncStats.txt;total=$(cat /tmp/resyncStats.txt |grep Total);totalObj=$(cat /tmp/resyncStats.txt|grep -vE " 0 GiB|Total"|wc -l);echo "`date +%Y-%m-%dT%H:%M:%SZ` $total ($totalObj objects)" >> /tmp/totalHistory.txt; echo `date `; sleep 60; done
Vérifiez s’il existe des opérations de resynchronisation en cours ou bloquées.
Exemple :
Total: 0 GiB Mon Feb 13 17:32:06 UTC 2023
Appuyez sur Ctrl+C pour arrêter la commande.
cmmds-tool find -f python | grep CONFIG_STATUS -B 4 -A 6 | grep 'uuid\|content' | grep -o 'state\\\":\ [0-9]*' | sort | uniq -c
Vérifiez l’état des composants.
Healthy -- state 7Inaccessible -- state 13Absent or Degraded -- state 15
Exemple :
425 state\": 7
Identification de l’emplacement du disque SSD ou du disque dur défectueux via l’interface de ligne de commande :
Répertoriez tous les périphériques disponibles :
esxcli storage core device list | grep "naa" | awk '{print $1}' | grep "naa"
Exemple :
naa.5000c500852df8d3 naa.55cd2e404c1f35a1 naa.55cd2e404c1f35a5 naa.5000c500852dd5e7
Vérifiez l’emplacement à l’aide de chaque NAA de disque dans la liste :
esxcli storage core device physical get -d
Exemple :
esxcli storage core device physical get -d naa.5000c500852df8d3 esxcli storage core device physical get -d naa.55cd2e404c1f35a1 esxcli storage core device physical get -d naa.55cd2e404c1f35a5 esxcli storage core device physical get -d naa.5000c500852dd5e7 Physical Location: enclosure 65535 slot 0 Physical Location: enclosure 65535 slot 1 Physical Location: enclosure 65535 slot 2 Physical Location: enclosure 65535 slot 3
Identification du disque dur ou du disque SSD défectueux si le nom de l’appareil est manquant :
Il est possible que le disque défaillant ne soit pas détecté et qu’il ne soit pas possible de l’identifier à l’aide du numéro NAA correspondant. Dans ce scénario, il est nécessaire de localiser tous les disques, et celui qui ne se trouve pas physiquement est celui qui a échoué.
Voici un script qui peut être utilisé pour effectuer la tâche un peu plus rapidement :
echo "=============Physical disks placement=============="
echo ""
esxcli storage core device list | grep "naa" | awk '{print $1}' | grep "naa" | while read in; do
echo "$in"
esxcli storage core device physical get -d "$in"
sleep 1
echo "===================================================="
done
Journaux pertinents vSAN pour les problèmes liés au stockage :
/var/log/vmkernel.log
Problèmes de lecture et d’écriture sur les disques vSAN, les pulsations de l’hôte vSAN, les PDL, les codes de détection SCSI et les demandes d’E/S (lectures/écritures), ainsi que les informations d’appartenance au cluster.
Exemple :
2021-06-22T12:02:08.408Z cpu30:1001397101)ScsiDeviceIO: PsaScsiDeviceTimeoutHandlerFn:12834: TaskMgmt op to cancel IO succeeded for device naa.55cd2e404b7736d0 and the IO did not complete. WorldId 0, Cmd 0x28, CmdSN = 0x428.Cancelling of IO will be 2021-06-22T12:02:08.408Z cpu30:1001397101)retried.
/var/log/vobd.log
Rapports sur l’intégrité des disques, les disques perdus permanents de l’appareil (PDL), la latence des disques et rapports sur le moment où un hôte entre et sort du mode maintenance.
Exemple :
2022-05-31T11:42:46.065Z: [vSANCorrelator] 10605891965954us: [vob.vsan.lsom.devicerepair] vSAN device 521a74ce-c980-c16c-ff3d-38a036233daf is being repaired due to I/O failures, and will be out of service until the repair is complete. If the device is part of a dedup disk group, the entire disk group will be out of service until the repair is complete. 2022-05-31T11:42:46.065Z: [vSANCorrelator] 10606062774178us: [esx.problem.vob.vsan.lsom.devicerepair] Device 521a74ce-c980-c16c-ff3d-38a036233daf is in offline state and is getting repaired
/var/log/vsandevicemonitord.log
Cela vous aide à déterminer si le disque a été marqué comme défectueux en raison d’un encombrement excessif des logs ou de latences d’E/S.
Exemple :
INFO vsandevicemonitord WARNING - WRITE Average Latency on VSAN device naa.50000xxxxxxxx has exceeded threshold value 2000000 us 2 times. INFO vsandevicemonitord Tier 2 (naa.50000xxxxxxxx) as unhealthy