OpenShift : Le processus de déploiement du cluster a échoué en raison d’un état de pod statique défectueux.
Résumé: Un problème OpenShift Container Platform entraînant l’échec du déploiement du cluster, l’état statique du pod est passé à terminé.
Symptômes
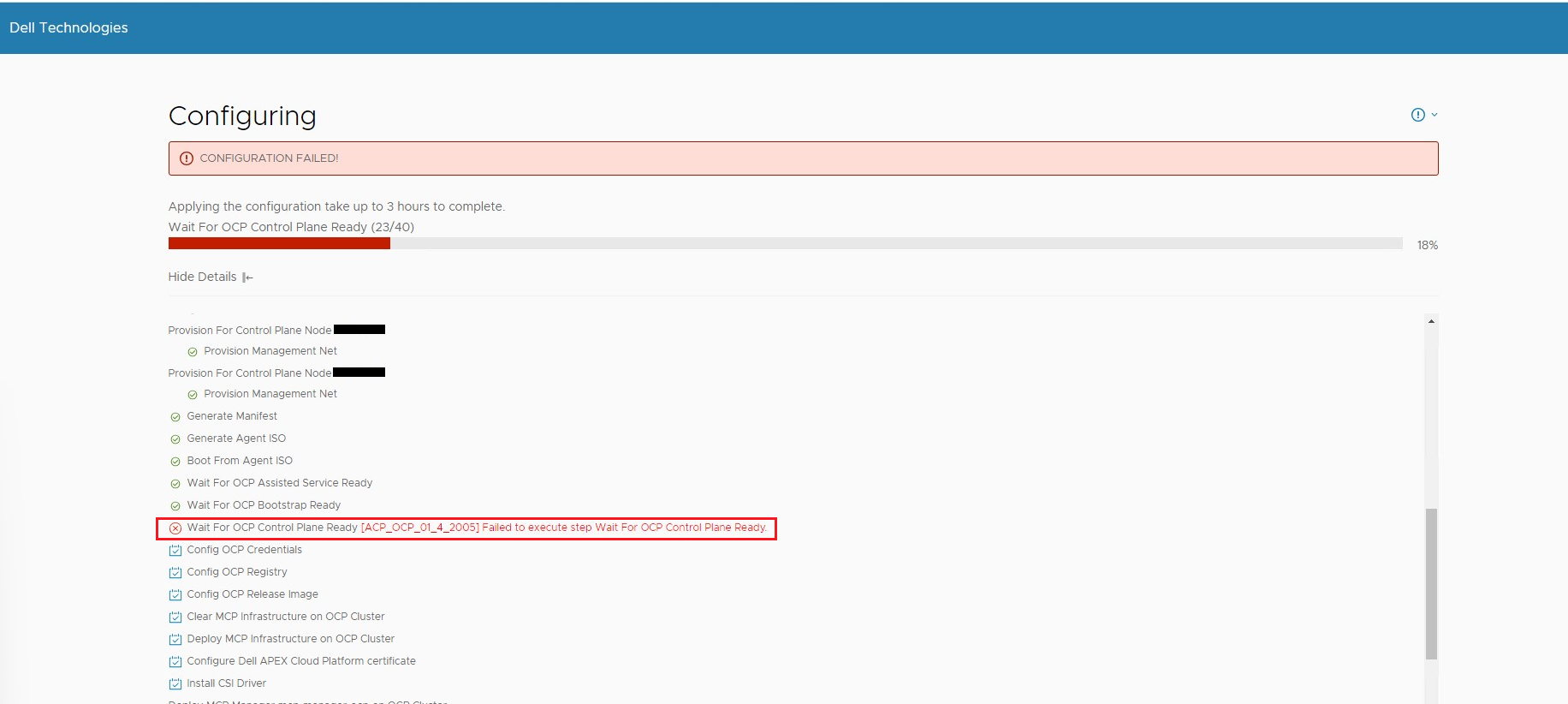
Scénario 1 : Échec du processus de configuration du déploiement du cluster avec l’erreur « Échec de l’exécution de l’étape Attendre que le plan de contrôle OCP soit prêt »
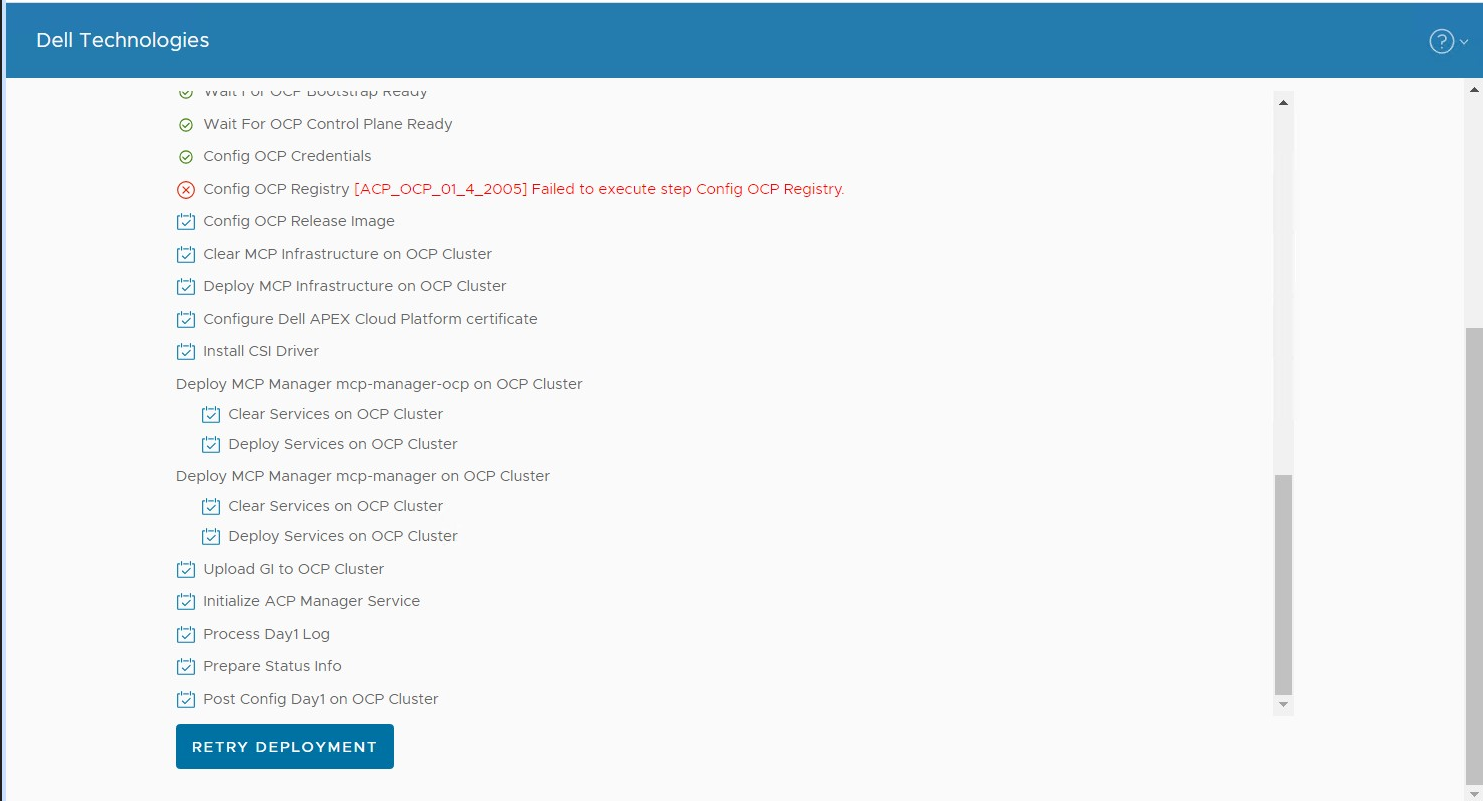
Scénario 2 : Le processus de configuration du déploiement du cluster a échoué avec l’erreur « Échec de l’exécution de l’étape de configuration du registre OCP »
Connectez-vous au nœud principal via SSH (les informations d’identification par défaut sont root/Passw0rd !), exécutez les commandes ci-dessous pour vérifier l’état des pods statiques, clusterversion et clusteroperator.
1. Exécutez la commande suivante :kubectl --kubeconfig="/usr/share/mcp_ocp/pv/mcp-installer-ocp/auth/kubeconfig" get clusterversion
La commande renvoie « kube-scheduler is degraded », par exemple :
| NOM VERSION DISPONIBLE PROGRESSING SINCE STATUS version False False 5h4m Erreur lors du rapprochement 4.13.12 : l’opérateur de cluster kube-scheduler est dégradé |
ou il renvoie « kube-controller-manager is degraded », par exemple :
| NAME VERSION AVAILABLE PROGRESSING SINCE STATUS version False False 5h4m Erreur lors du rapprochement 4.13.12 : l’opérateur de cluster kube-controller-manager est dégradé |
2. Exécutez la commande suivante :
kubectl --kubeconfig="/usr/share/mcp_ocp/pv/mcp-installer-ocp/auth/kubeconfig" get co
Prend que kube-controller-manager est dégradé, par exemple, la commande affiche un kube-controller-manager dégradé avec le message « GuardControllerDegraded : Opérande manquant sur le nœud »
|
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE ...... kube-controller-manager 4.13.12 True True True 4d7h GuardControllerDegraded : [opérande manquant sur le nœud h01-01-compute-02.p82.local, opérande manquant sur le nœud h01-01-compute-03.p82.local]... ...... machine-config 4.13.12 True False True 4d7h Failed to resync 4.13.12 because : error during syncRequiredMachineConfigPools : [expiration du délai d’attente pour la condition, erreur : le maître du pool n’est pas prêt, nouvelle tentative. Status: (pool degraded : true total : 3, ready 1, updated : 1, indisponible : 2)] |
3. Exécutez la commande suivante :
kubectl --kubeconfig="/usr/share/mcp_ocp/pv/mcp-installer-ocp/auth/kubeconfig" get pods -A | grep kube-controller-manager
Prend kube-controller-manager est dégradé, par exemple, la commande affiche un kube-controller-manager est 0/1
|
L’ÉTAT NAME READY REDÉMARRE L’ÂGE installer-4-h01-01-compute-03.p82.local 0/1 Completed 0 4d7h installer-4-h01-01-compute-04.p82.local 0/1 Completed 0 4d7h installer-5-h01-01-compute-03.p82.local 0/1 Completed 0 4d7h installer-5-h01-01-compute-04.p82.local 0/1 Completed 0 4d7h installer-6-h01-01-compute-03.p82.local 0/1 Completed 0 4d7h kube-controller-manager-guard-h01-01-compute-03.p82.local 0/1 Course 0 4d7h kube-controller-manager-guard-h01-01-compute-04.p82.local 1/1 Running 0 4d7h kube-controller-manager-h01-01-compute-04.p82.local 4/4 Running 0 4d7h |
Cause
La cause première est que Kubernetes ne parvient pas à supprimer certains Pod, ce qui entraîne l’exécution de certains services dans un état défectueux.
Résolution
Ce problème sera résolu dans une prochaine version d’OCP.
Pour la version OCP concernée, veuillez suivre les étapes ci-dessous pour contourner le problème :
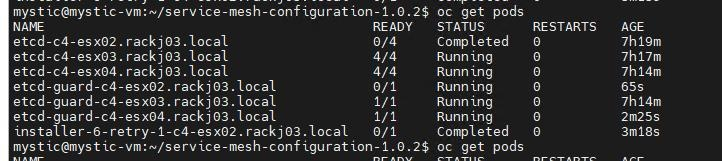
Connexion SSH au nœud identifié. Dans l’exemple ci-dessus, le nom du nœud identifié est « c4-esx02.rackj03.local ».
1. Enregistrez la clé privée correspondant à la clé publique SSH que vous avez générée sur la page Web de l’assistant de déploiement de cluster.
Exécutez la commande : ssh-keygen -t ecdsa -b 521
- Saisissez un nom de fichier pour lequel vous souhaitez enregistrer la clé ou utiliser la valeur par défaut.
- Saisissez une phrase secrète ou utilisez la valeur par défaut.
Votre clé publique a été enregistrée dans /root/.ssh/id_ecdsa.pub
3. Exécutez la commande : sudo systemctl restart kubelet
4. Réessayer le processus de déploiement du cluster à partir de la page Web de l’assistant