Řadič Dell iDRAC hlásí chybu nesprávné jednotky NVMe v clusteru vSAN s povolenou deduplikací.
Shrnutí: V clusteru OSA (Original Storage Architecture) Dell vSAN s povolenou deduplikací dochází k poruchám disků hlášeným na zařízeních NVMe. Cluster vSAN OSA je nakonfigurován se zařízeními NVMe jako úrovní cache a SAS jako úrovněmi kapacity. Závady disků jsou nesprávně hlášeny na discích NVMe, které jsou nakonfigurovány jako vrstvy cache pro cluster vSAN OSA, i když k selhání dochází na discích SAS účastnících se úrovně kapacity. ...
Příznaky
Server BMC/Dell iDRAC může hlásit protokol událostí, jak je uvedeno níže v protokolu systémových událostí (SEL).

Protokol Lifecycle Log (LCL) v řadiči Dell iDRAC může hlásit závadu disku PDR1001 jak je uvedeno níže.

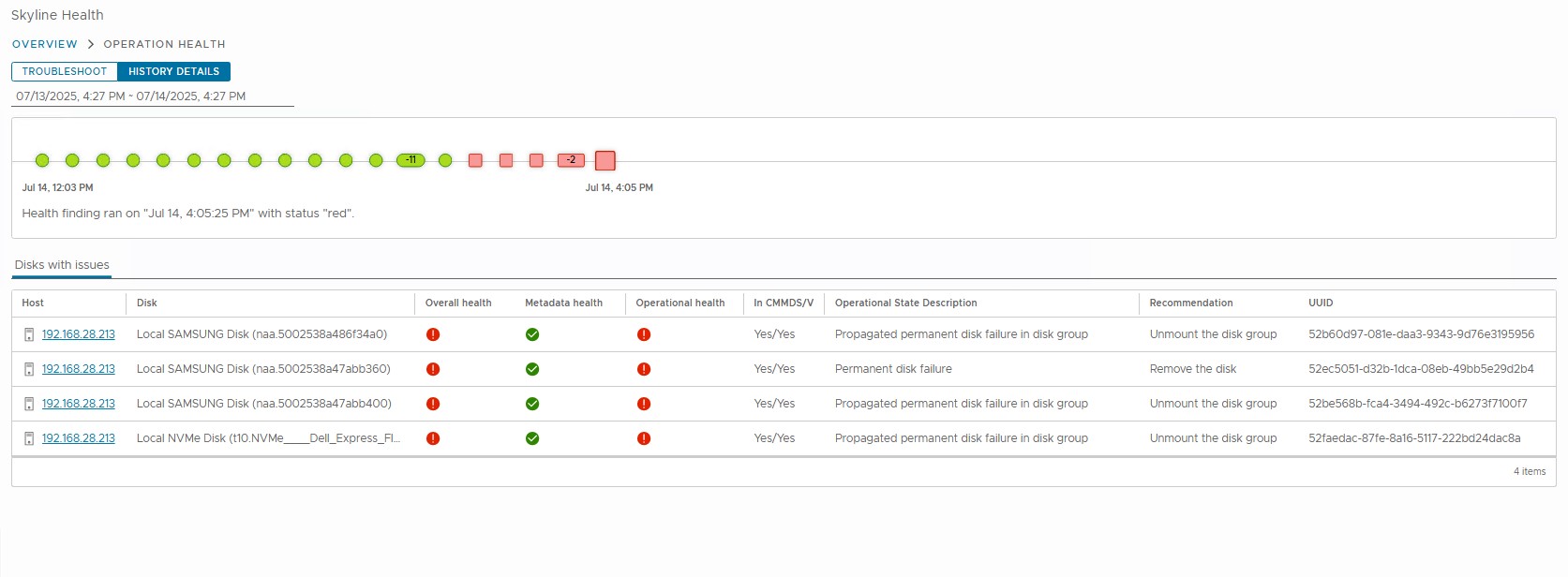
Z pohledu clusteru vSAN OSA si můžete všimnout, že celá skupina disků, ve které se nachází vadný disk, je označena jako ztráta trvalého disku (PDL). Jedná se o očekávané chování, když je v prostředí vSAN OSA povolena deduplikace. To znamená, že když dojde k selhání jedné ze zúčastněných jednotek v dané skupině disků vSAN OSA s povolenou deduplikací pro cluster, podle očekávání se celá skupina disků označí jako PDL a Není v pořádku.
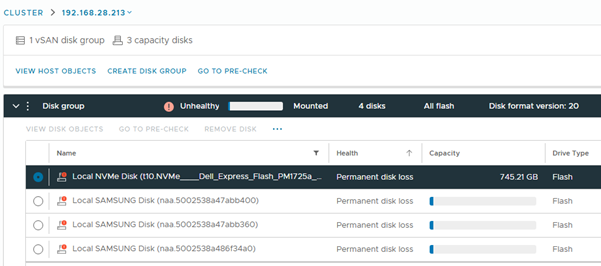
Z pohledu řadiče iDRAC je však odpovídající zařízení NVMe z vrstvy cache hlášeno jako vadné.
Příčina
Výše uvedené příznaky představují očekávané chování jak ze strany vSAN OSA , tak z pohledu řadiče Dell iDRAC. Očekávaný design PDR1001 hlášení Dell iDRAC pouze na zařízeních NVMe, a nikoli na zařízeních SAS/SATA. vSAN OSA pomocí daemona lsud zapisuje stav jednotky kontrolky LED selhání do řadiče iDRAC přes rozhraní IPMI. V tomto případě, i když se původní chyba týká konkrétního disku účastnícího se vrstvy kapacity, ovlivní celou skupinu disků s povolenou deduplikací. Proto systém ESXi také odesílá chybu všech disků do řadiče BMC/iDRAC.
Řešení
Pokud je cluster vSAN OSA povolen s deduplikací, očekává se, že jakékoli selhání disku ve skupině disků selže v celé skupině disků. Existuje několik metod, jak identifikovat vadnou jednotku, která způsobuje selhání skupiny disků. Před výměnou se tedy vyplatí dvakrát zkontrolovat závady disku pomocí některé z následujících metod.
- Přihlaste se k hostiteli ESXi pomocí SSH
- Přejděte do vsandevicemonitord.log umístění /var/run/log a vyhledejte následující položky: Můžete vidět položky, kde je vadný disk hlášen jako Disk_Under_PERM_Error a zbývající disk je označen jako DISKGROUP_UNDER_PERM_ERROR
2025-07-14T09:58:44ZIn(14)vsandevicemonitord[2104122]:[768345735872]:Device t10.NVMe____Dell_Express_Flash_PM1725a_800GB_SFF____8302B071E7382500 state is DISKGROUP_UNDER_PERM_ERROR2025-07-14T09:58:44Z In(14) vsandevicemonitord[2104122]: [768345735872]: Device naa.5002538a486f34a0 state is DISKGROUP_UNDER_PERM_ERROR2025-07-14T09:58:44Z In(14) vsandevicemonitord[2104122]: [768345735872]: Device naa.5002538a47abb360 state is DISK_UNDER_PERM_ERROR2025-07-14T09:58:44Z In(14) vsandevicemonitord[2104122]: [768345735872]: Device naa.5002538a47abb400 state is DISKGROUP_UNDER_PERM_ERROR
3. Pomocí následujícího příkazu vyhoďte identifikátor zařízení a vyhledejte pevný disk.
~# esxcli storage core device physical get -d <NAA ID of the device>Physical Location: enclosure 3 slot 0
4. Případně můžete pomocí následujícího příkazu identifikovat vadnou jednotku ve skupině disků. Může se stát, že rozdíl v celkovém stavu hlášený jako červený (Failed) pro vadný disk a červený (FAILED, PROPAGATED) pro zbývající disk ve skupině disků.
~# esxcli vsan debug disk listUUID: 52faedac-87fe-8a16-5117-222bd24dac8a Name: t10.NVMe____Dell_Express_Flash_PM1725a_800GB_SFF____8302B071E7382500 Owner: he-dhcp-pnw-192-168-28-213.helab.in Version: 20 Disk Group: 52faedac-87fe-8a16-5117-222bd24dac8a Disk Tier: Cache SSD: true In Cmmds: true In Vsi: true Fault Domain: N/A Model: Dell Express Flash PM1725a 800GB SFF Encryption: false Compression: true Deduplication: true Dedup Ratio: N/A Overall Health: red(FAILED,PROPAGATED) Metadata Health: green Operational Health: red Congestion Health: State: green Congestion Value: 0 Congestion Area: none All Congestion Fields: Space Health:
UUID: 52ec5051-d32b-1dca-08eb-49bb5e29d2b4 Name: naa.5002538a47abb360 Owner: he-dhcp-pnw-192-168-28-213.helab.in Version: 20 Disk Group: 52faedac-87fe-8a16-5117-222bd24dac8a Disk Tier: Capacity SSD: true In Cmmds: true In Vsi: true Fault Domain: N/A Model: MZILS3T8HMLH0D3 Encryption: false Compression: true Deduplication: true Dedup Ratio: 0.61x Overall Health: red(FAILED) Metadata Health: green Operational Health: red Congestion Health: State: green Congestion Value: 0 Congestion Area: none All Congestion Fields: Space Health: State: green Capacity: 3387.72 GB Used: 121.89 GB Reserved: 20.23 GB UUID: 52be568b-fca4-3494-492c-b6273f7100f7 Name: naa.5002538a47abb400 Owner: he-dhcp-pnw-192-168-28-213.helab.in Version: 20 Disk Group: 52faedac-87fe-8a16-5117-222bd24dac8a Disk Tier: Capacity SSD: true In Cmmds: true In Vsi: true Fault Domain: N/A Model: MZILS3T8HMLH0D3 Encryption: false Compression: true Deduplication: true Dedup Ratio: 0.61x Overall Health: red(FAILED,PROPAGATED) Metadata Health: green Operational Health: red Congestion Health: State: green Congestion Value: 0 Congestion Area: none All Congestion Fields:
5. Při použití Skyline Health karta Operation Health odráží trvalé selhání disku a propagované trvalé selhání disku.