PowerScale, Isilon OneFS: HBase-Performancetests auf Isilon
Summary: In diesem Artikel werden die Performance-Benchmarking-Tests auf einem Isilon X410-Cluster mit der Yahoo Cloud Serving Benchmarking (YCSB)-Suite und Cloudera Data Hub (CDH) 5.10 veranschaulicht. ...
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Symptoms
Nicht erforderlich
Cause
Nicht erforderlich
Resolution
HINWEIS: Dieses Thema gehört zum Infohub Verwenden von Hadoop mit OneFS.
Einführung
Auf einem Isilon X410-Cluster wurde eine Reihe von Performancebenchmarkingtests mit der YCSB Benchmarking Suite und CDH 5.10 durchgeführt.
Die Labortestumgebung wurde mit fünf Isilon x410-Nodes konfiguriert, auf denen OneFS v8.0.0.4 und höher v8.0.1.1 ausgeführt wird. Es wurden Benchmarks für das Streaming von großen NFS-Blöcken (Network File System) ausgeführt. Das erwartete theoretische aggregierte Maximum für die Tests lag bei ~700 MB/s (3,5 GB/s) Schreibvorgängen und ~1 GB/s Lesevorgängen (5 GB/s) pro Node.
Die (9) Compute-Nodes sind Dell PowerEdge FC630-Server mit CentOS v7.3.1611, die jeweils mit 2 x 18C/36T-Intel Xeon® CPU E5-2697 v4 @ 2,30 GHz mit 512 GB RAM konfiguriert sind. Lokaler Speicher sind 2 x SSD in RAID 1, formatiert als XFS für Betriebssystem- und Scratch-Speicherplatz oder Spill-Dateien.
Es gab auch drei zusätzliche Edge-Server, die verwendet wurden, um die YCSB-Last zu steuern.
Das Back-end-Netzwerk zwischen Rechner-Nodes und Isilon besteht aus 10 Gbit/s mit festgelegten Jumbo-Frames (MTU = 9162) für die NICs und die Switchports.
Die Komponenten der Hadoop-Testkonfiguration (Abbildung 1)
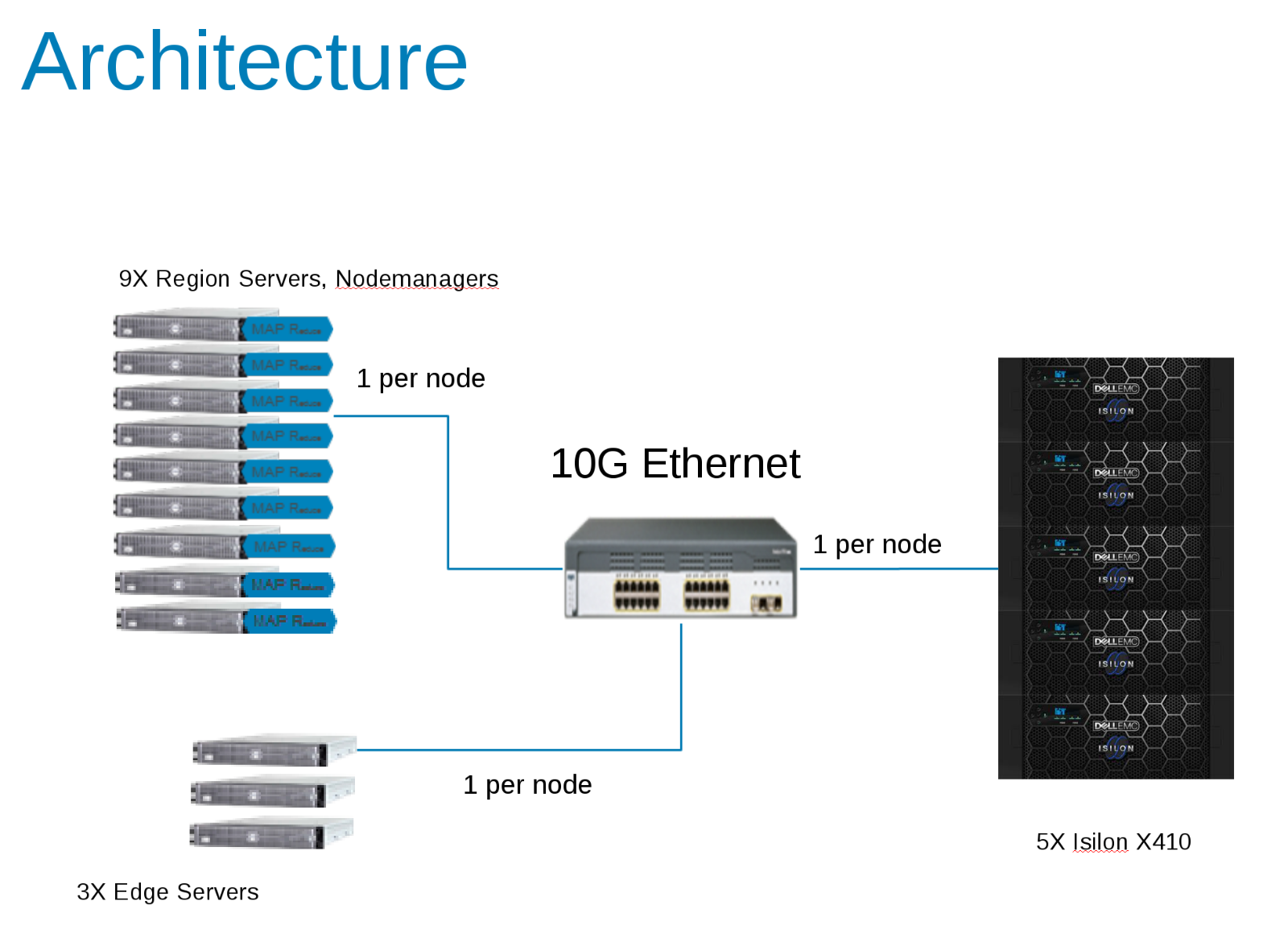
CDH 5.10 wurde für die Ausführung in einer Zugriffszone auf dem Isilon-Cluster konfiguriert. Servicekonten wurden im lokalen Isilon-Anbieter und lokal in den Clientdateien /etc/passwd erstellt. Alle Tests wurden mit einem grundlegenden Testclient ohne besondere Berechtigungen ausgeführt.
Isilon-Statistiken wurden sowohl mit IIQ als auch mit Grafana/Data Insights-Paket überwacht. Die CDH-Statistiken wurden sowohl mit Cloudera Manager als auch mit Grafana überwacht.
Erste Tests
In der ersten Testreihe sollten die relevanten Parameter auf der HBASE-Seite ermittelt werden, die sich auf die Gesamtleistung auswirken. Das YCSB-Tool wurde verwendet, um die Last für HBASE zu generieren. Dieser erste Test wurde mit einem einzelnen Client (Edgeserver) in der Ladephase von YCSB und 40 Millionen Zeilen durchgeführt. Diese Tabelle wurde vor jeder Ausführung gelöscht.
ycsb load hbase10 -P workloads/workloada1 -p table='ycsb_40Mtable_nr' -p columnfamily=family -threads 256 -p recordcount=40000000
- hbase.regionserver.maxlogs - Maximale Anzahl von WAL-Dateien (Write-Ahead Log): Dieser Wert multipliziert mit der HDFS-Blockgröße (dfs.blocksize) ist die Größe der WAL, die wiedergegeben werden muss, wenn ein Server abstürzt. Dieser Wert verhält sich umgekehrt proportional zur Häufigkeit von Leerungen an die Festplatte.
- hbase.wal.regiongrouping.numgroups - Bei Verwendung von Multiple HDFS WAL als WALProvider wird hier festgelegt, wie viele Write-Ahead-Logs jeder RegionServer ausführen soll. Die Ergebnisse zeigen die Anzahl der HDFS-Pipelines an. Schreibvorgänge für eine bestimmte Region gehen nur an eine einzige Pipeline, wodurch die gesamte RegionServer-Last verteilt wird.
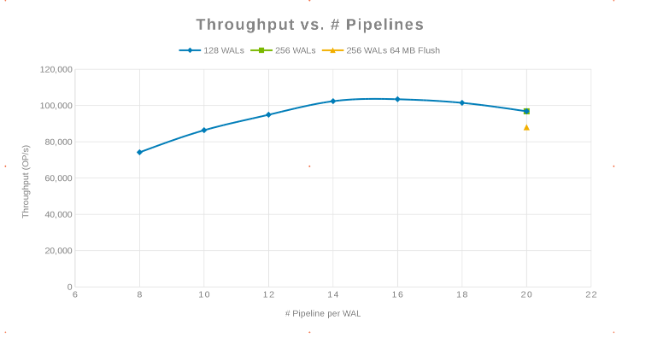
Durchsatz im Vergleich zur Anzahl der Pipelines (Abbildung 2)
Latenz im Vergleich zur Anzahl der Pipelines (Abbildung 3)
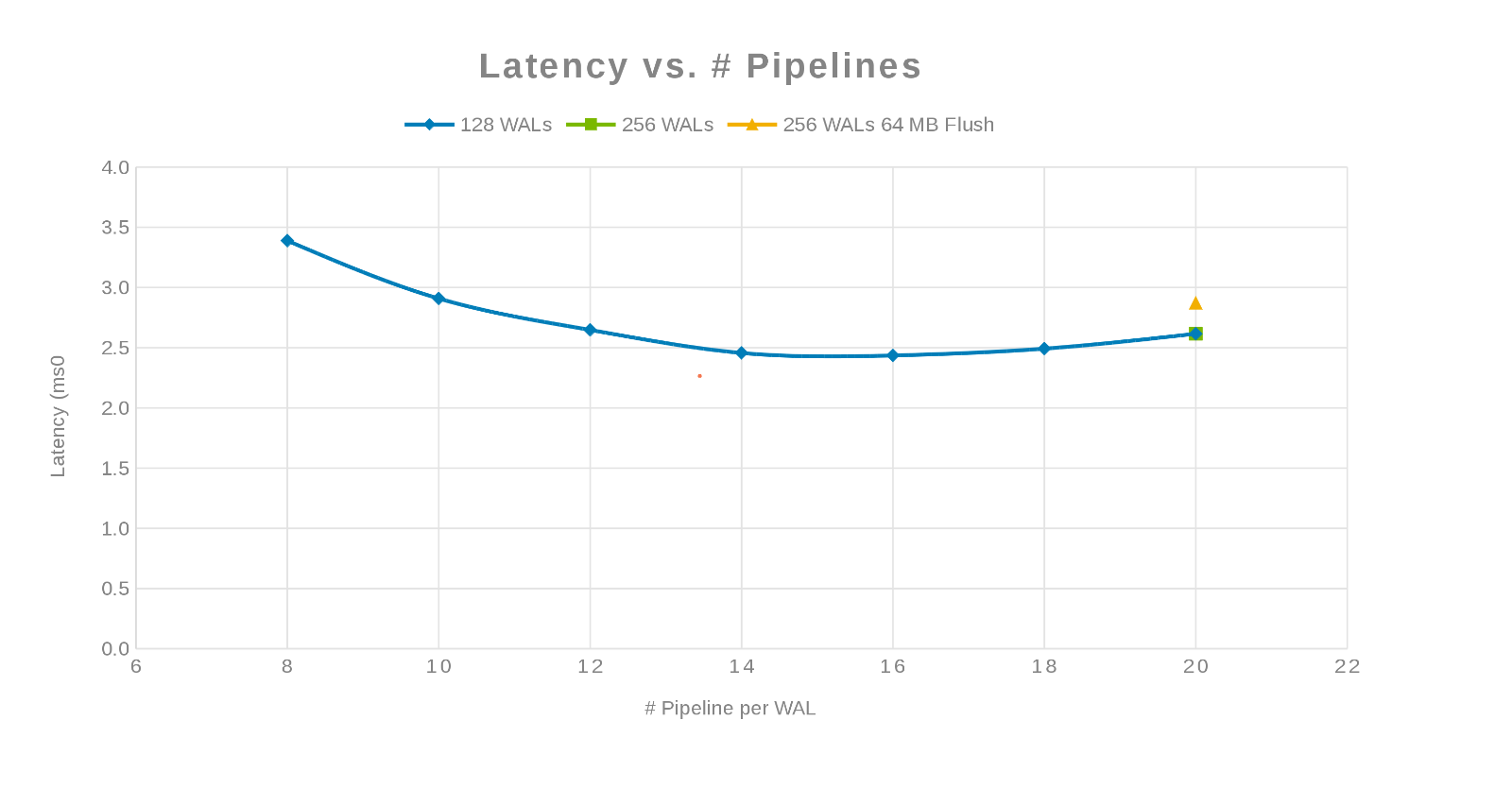
Die Philosophie dabei war, so viele Schreibvorgänge wie möglich zu parallelisieren. Dies wird erreicht, indem die Anzahl der WALs und dann die Anzahl der Threads (Pipeline) pro WAL erhöht wird. Die beiden vorherigen Diagramme zeigen, dass für eine gegebene Zahl für 'maxlogs', 128 oder 256, keine wirkliche Änderung angezeigt wird. Dies weist darauf hin, dass der Test clientseitig keine wirklichen Auswirkungen auf die Ergebnisse hat. Die Anzahl der "Pipelines" pro Datei variierte, was einen Trend zeigte, der den Parameter angibt, der für die Parallelisierung sensibel ist. Die nächste Frage ist, wo ein Isilon-Cluster "im Weg steht", entweder mit Festplatten-I/O, Netzwerk, CPU oder OneFS. Um diese Frage zu beantworten, sehen Sie sich den Isilon-Statistikbericht an.
Die Isilon-Netzwerkauslastung und -last während des Tests (Abbildung 4)
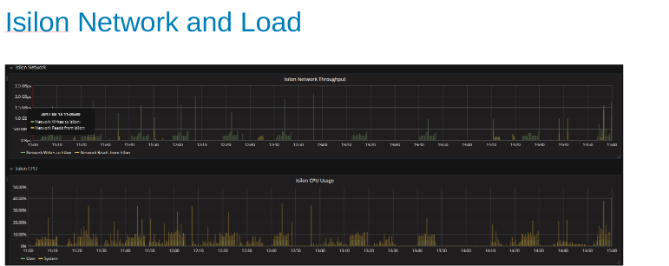
Die Netzwerk- und CPU-Diagramme zeigen uns, dass der Isilon-Cluster nicht ausgelastet ist und Raum für weitere Arbeit bietet. Die CPU würde 80 % betragen und die Netzwerkbandbreite würde mehr als 3 GB/s betragen > .
Diagramme der HDFS-Protokollstatistik und CPU-Auslastung unter HDFS-Protokolllast (Abbildung 5)
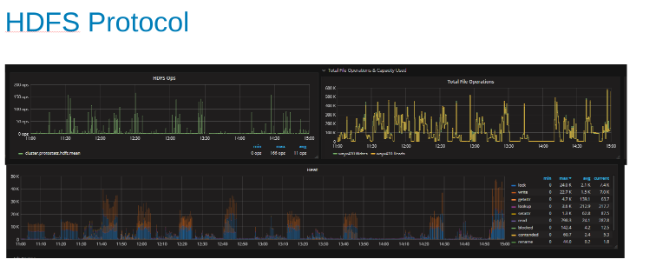
Diese Diagramme zeigen die HDFS-Protokollstatistiken und wie OneFS die Ausgabe übersetzt. Die HDFS-Vorgänge sind Vielfache von dfs.blocksize, hier 256 MB. Interessant ist hierbei, dass das Diagramm "Heat" die OneFS-Dateivorgänge und die Korrelation von Schreibvorgängen und Sperren anzeigt. In diesem Fall fügt HBase die WALs an, sodass OneFS die WAL-Datei für jeden angehängten Schreibvorgang sperrt. Das ist es, was für stabile Schreibvorgänge auf einem geclusterten Dateisystem erwartet wird. Diese scheinen zum limitierenden Faktor in dieser Reihe von Tests beizutragen.
HBase-Updates
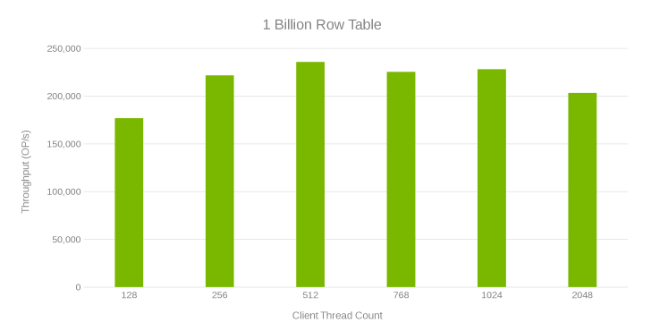
Der nächste Test bestand darin, mehr zu experimentieren, um herauszufinden, was im großen Maßstab passiert. Es wird eine Tabelle mit 1 Milliarde Zeilen erstellt, deren Generierung eine Stunde gedauert hat. Es wird ein YCSB-Test ausgeführt, bei dem 10 Millionen Zeilen mithilfe der "Workloada"-Einstellungen (50/50 Lese-/Schreibzugriff) aktualisiert wurden. Dieser Test wurde auf einem einzigen Client ausgeführt. Der Test wurde in Abhängigkeit von der Anzahl der YCSB-Threads ausgeführt, sodass der höchste Durchsatz generiert werden kann. Außerdem wurden einige Tuninganpassungen durchgeführt und OneFS auf Version 8.0.1.1 aktualisiert, die Leistungsoptimierungen für den Daten-Node-Service bietet. Das folgende Diagramm zeigt die Leistungssteigerung im Vergleich zu den vorherigen Ausführungen. Für diese Ausführungen wird hbase.regionserver.maxlogs auf 256 und hbase.wal.regiongrouping.numgroups auf 20 festgelegt.
Durchsatz und Thread-Anzahl beim Aktualisieren einer Tabelle mit 1 Milliarde Zeilen (Abbildung 6)
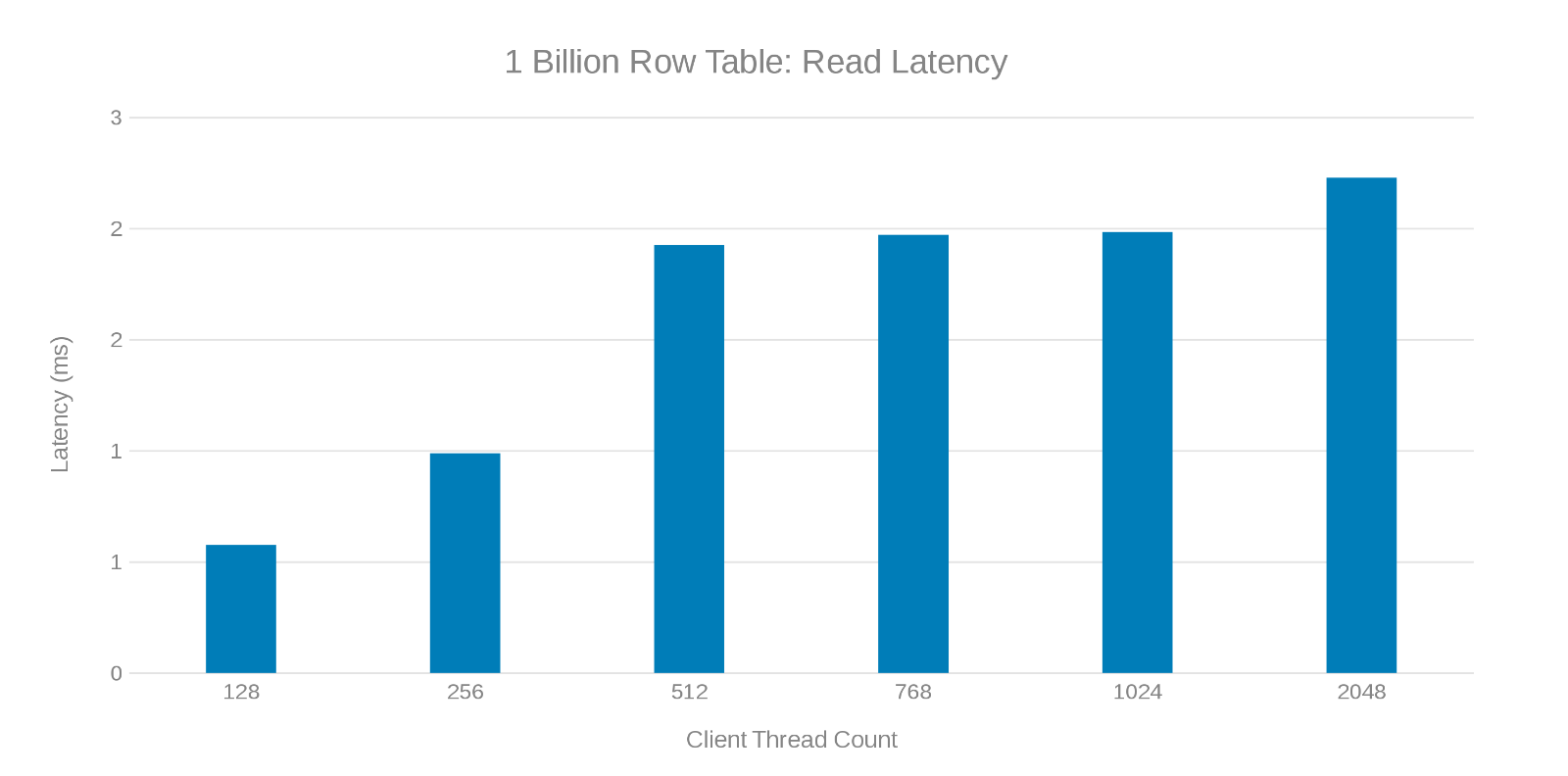
Leselatenz beim Aktualisieren einer Tabelle mit 1 Milliarde Zeilen (Abbildung 7)
Latenz beim Aktualisieren der Tabelle mit 1 Milliarde Zeilen aktualisieren (Abbildung 8)
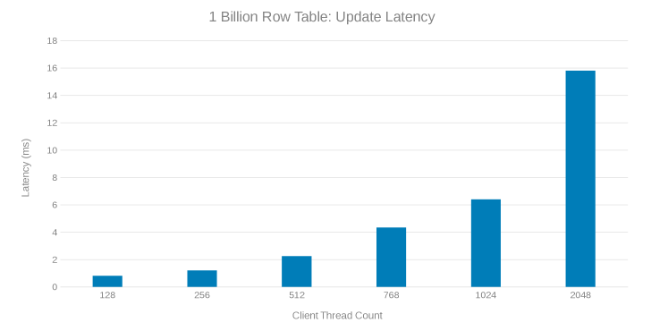
Die Überprüfung dieser Testläufe zeigt einen offensichtlichen Abfall bei hoher Thread-Anzahl, was entweder ein Isilon- oder ein clientseitiges Problem sein kann. Tests zeigen beeindruckende 200.000 Vorgänge pro Sekunde bei einer Update-Latenz von < 3 ms. Jeder der Update-Testläufe war schnell und konnte nacheinander ausgeführt werden. Das folgende Diagramm zeigt eine gleichmäßige Verteilung auf die Isilon-Nodes für jeden Testlauf.
Heat-Diagramm, das die Workload auf jedem Node im Isilon-Cluster anzeigt (Abbildung 9)
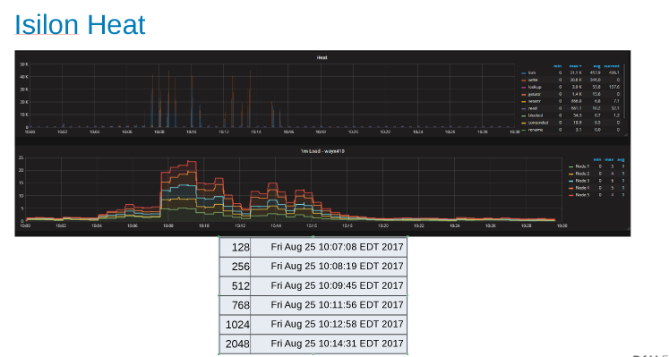
Das Wärmediagramm zeigt, dass es sich bei den Dateivorgängen um Schreibvorgänge und Sperren handelt, die der Anfügeart der WAL-Prozesse entsprechen.
Serverskalierung nach Region
Im nächsten Test sollte ermittelt werden, wie sich die Isilon-Nodes (fünf Nodes) im Vergleich zu einer unterschiedlichen Anzahl von Regionsservern schlagen würden. Das gleiche Aktualisierungsskript, das im vorherigen Test ausgeführt wurde, wurde mit einer Tabelle mit einer Milliarde Zeilen und einem Update mit 10 Millionen Zeilen mit "workloada" ausgeführt. Für den Test wurde ein einzelner Client mit YCSB-Threads verwendet, die auf 51 festgelegt waren. Für maxlogs und Pipelines wird die gleiche Einstellung angewendet (256 bzw. 20).
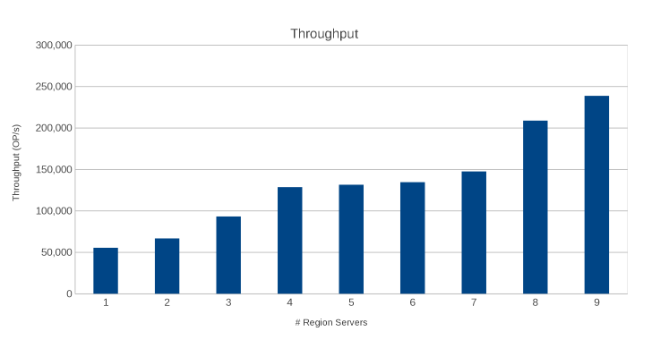
Durchsatz über Regionsserver hinweg (Abbildung 10)
Latenz zwischen regionalen Servern (Abbildung 11)
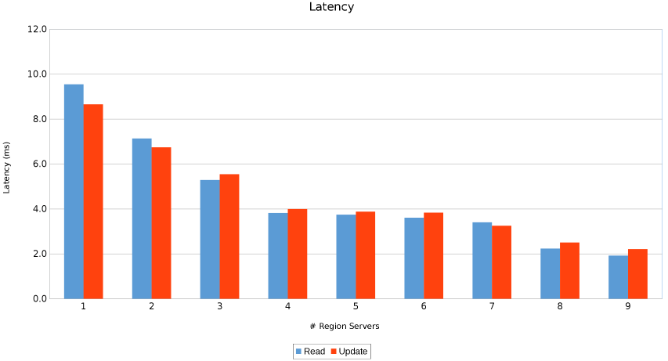
Die Ergebnisse sind informativ, wenn auch nicht überraschend. Die Scale-out-Beschaffenheit von HBase in Kombination mit der Scale-out-Beschaffenheit von Isilon deutet darauf hin, dass mehr besser ist. Dieser Test wird für Kunden empfohlen, um ihn im Rahmen ihrer eigenen Dimensionierungsübung in ihren Umgebungen auszuführen. Hier gibt es neun Server, die fünf Isilon-Nodes pushen, und es sieht so aus, als ob es noch Platz für weitere gibt, bevor der Punkt der abnehmenden Rendite erreicht ist.
Mehr Clients
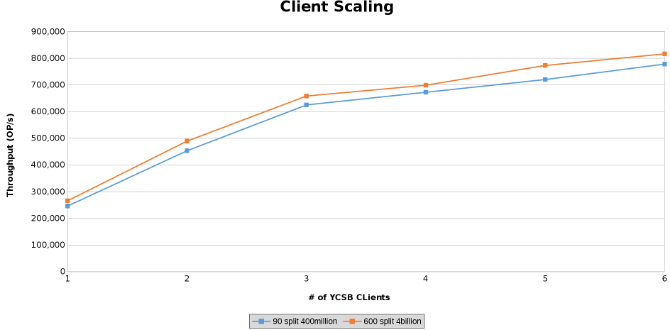
Die letzte Testreihe diente dazu, die Grenzen der Hardware-Konfiguration auszutesten. Dies geschah, um die Obergrenze für die zu testenden Parameter zu bestimmen. In dieser Testreihe werden zwei zusätzliche Server verwendet, auf denen Clients ausgeführt werden. Darüber hinaus werden zwei YCSB-Clients von jedem Server ausgeführt, was jeweils bis zu sechs Clients zulässt. Jeder Client steuerte 512 Threads, was insgesamt 4096 Threads ergibt. Es wurden zwei verschiedene Tabellen erstellt. Eine Tabelle mit 4 Milliarden Zeilen, aufgeteilt in 600 Regionen, und eine andere mit 400 Millionen Zeilen, aufgeteilt in 90 Regionen.
In diesem Diagramm wird der Durchsatz der Vorgänge beim Testen der Clientskalierung dargestellt (Abbildung 12).
Messung der Leselatenz beim Testen der Clientskalierung (Abbildung 13)
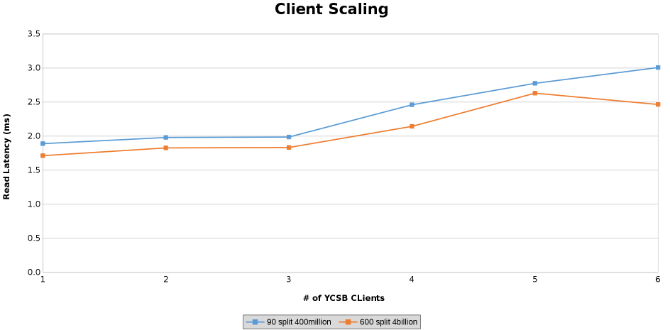
Messung der Updatelatenz beim Testen der Clientskalierung (Abbildung 14)
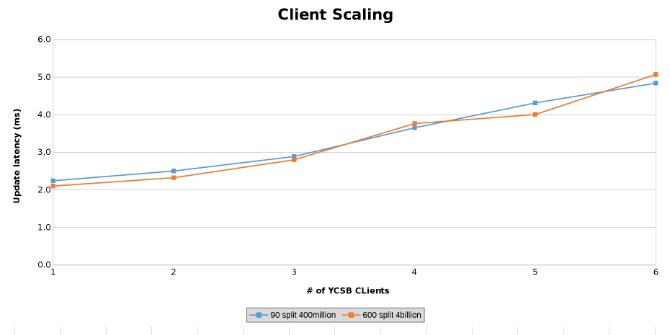
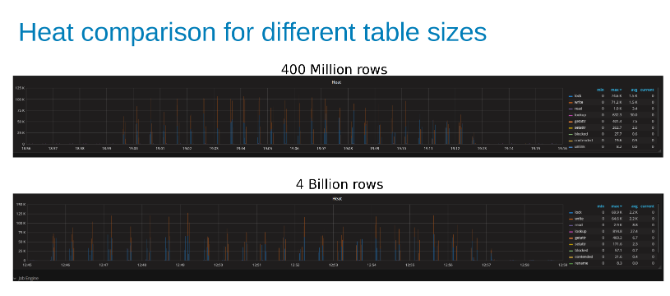
Die folgenden Diagramme zeigen, dass die Größe der Tabelle in diesem Test kaum eine Rolle spielt. Die Isilon Heat-Diagramme zeigen erneut, dass es einige prozentuale Unterschiede bei der Anzahl der Dateivorgänge gibt. Die meisten Unterschiede entsprachen den Unterschieden zwischen einer Tabelle mit 4 Milliarden Zeilen und einer Tabelle mit 400 Millionen Zeilen.
Vergleich der Isilon-Workload-Wärme bei der Aktualisierung einer Tabelle mit 400 Millionen Zeilen im Vergleich zu einer Tabelle mit 4 Milliarden Zeilen (Abbildung 15).
Entscheidung
HBase ist ein guter Kandidat für die Ausführung auf Isilon, vor allem wegen der Scale-out-zu-Scale-out-Architekturen. HBase cachingt einen Großteil selbst, und durch die Aufteilung der Tabelle auf eine große Anzahl von Regionen kann HBase mit den Daten horizontal skaliert werden. Mit anderen Worten, es kümmert sich gut um seine eigenen Anforderungen, und das Dateisystem ist für die Ausfallsicherheit von Anwendungen da. Die Tests waren nicht in der Lage, die Last so weit zu treiben, dass die Dinge kaputt gingen. Wenn HBase für 800.000 Vorgänge mit einer Latenz von weniger als 3 ms ausgelegt ist, wird sie von dieser Architektur unterstützt. HBase unterstützt eine Vielzahl von Leistungsanpassungen und -optimierungen sowohl für die Clientseite als auch für HBase selbst. Das Testen all dieser Anpassungen und Optimierungen ging über den Rahmen dieses Tests hinaus.Affected Products
Isilon, PowerScale OneFSArticle Properties
Article Number: 000128942
Article Type: Solution
Last Modified: 11 Mar 2026
Version: 7
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.