Solutions Dell EMC Ready pour le stockage HPC PixStor - Niveau NVMe
Summary: Blog présentant les composants d’une solution de stockage HPC, notamment son architecture et l’évaluation de ses performances.
Symptoms
Blog présentant les composants d’une solution de stockage HPC, notamment son architecture et l’évaluation de ses performances.
Resolution
Solutions Dell EMC Ready pour le stockage HPC PixStor
Niveau NVMe
Sommaire
Caractérisation des performances
Performances IOzone séquentielles N clients vers N fichiers
Performances IOR séquentielles N clients vers 1 fichier
Petits blocs aléatoires, performances IOzone séquentielles N clients vers N fichiers
Performances des métadonnées avec MDtest à l’aide de fichiers de 4 Kio
Introduction
De nos jours, les environnements HPC ont de plus en plus besoin de stockage très haut débit. Et avec la hausse du nombre de processeurs, le déploiement de réseaux plus rapides et l’augmentation de la capacité de mémoire, le stockage a fini par devenir un goulot d’étranglement pour de nombreuses charges applicatives. Ces exigences HPC très strictes sont généralement couvertes par des systèmes de fichiers parallèles (PFS) qui fournissent un accès simultané à un seul fichier ou à un ensemble de fichiers à partir de plusieurs nœuds, en distribuant très efficacement et en toute sécurité les données sur plusieurs LUN réparties sur plusieurs serveurs. Ces systèmes de fichiers utilisent normalement des supports tournants pour délivrer une capacité maximale au moindre coût. Mais il s’avère de plus en plus que la rapidité et la latence des supports tournants ne suffisent plus à répondre aux exigences de nombreuses charges applicatives HPC modernes, qui nécessitent d’utiliser la technologie Flash pour les mémoires tampons de pic, les niveaux plus rapides ou même pour le stockage scratch très rapide (local ou distribué). Dell EMC Ready Solution for HPC PixStor Storage utilise des nœuds NVMe comme composants pour s’adapter à ces nouveaux besoins très stricts en matière de bande passante, en plus d’être flexibles, évolutifs, efficaces et fiables.
Architecture de la solution
Cet article de blog fait partie d’une série consacrée aux solutions de système de fichiers parallèles (PFS) pour les environnements HPC, en particulier pour Dell EMC Ready Solution for HPC PixStor Storage, où les serveurs Dell EMC PowerEdge R640 équipés de disques NVMe sont utilisés comme niveau de stockage Fast Flash.
La solution PixStor PFS intègre le très connu General Parallel File System, également appelé Spectrum Scale. ArcaStream inclut également de nombreux autres composants logiciels pour fournir une analytique avancée, une administration et une surveillance simplifiées, une recherche de fichiers efficace, des fonctionnalités de passerelle avancées et bien plus encore.
Les nœuds NVMe présentés dans ce blog fournissent un niveau Flash hautes performances pour la solution PixStor. Il est possible de faire évoluer les performances et la capacité de ce niveau NVMe en mode scale-out par l’ajout de nœuds NVMe supplémentaires. Pour augmenter la capacité, sélectionnez les appareils NVMe appropriés pris en charge par le serveur PowerEdge R640.
La Figure 1 présente l’architecture de référence représentant une solution comportant 4 nœuds NVMe utilisant le module de métadonnées à forte demande, qui gère l’ensemble des métadonnées dans la configuration testée. La raison en est que, pour l’instant, ces nœuds NVMe n’étaient utilisés uniquement comme cibles de stockage de données. Les nœuds NVMe peuvent cependant aussi être utilisés pour stocker des données et des métadonnées, ou même comme alternative Flash plus rapide au High Demand Metadata Module, si des exigences de métadonnées extrêmes l’exigent. Ces configurations pour les nœuds NVMe n’ont pas été testées dans le cadre de cet article, mais le seront à l’avenir.
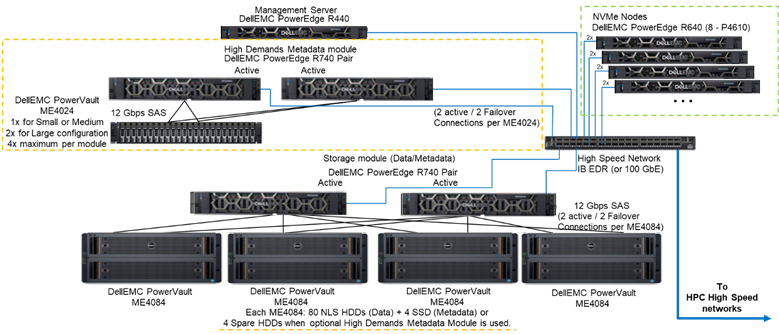
Figure 1 Architecture de référence
Composants de la solution
Cette solution utilise les derniers processeurs Intel Xeon Scalable de 2e génération, également appelés Cascade Lake, et la RAM la plus rapide disponible (2 933 MT/s), sauf pour les nœuds de gestion afin d’en réduire le coût. La solution a également été mise à jour vers la dernière version de PixStor (5.1.3.1) qui prend en charge RHEL 7.7 et OFED 5.0, les versions logicielles qui seront prises en charge au moment du lancement.
Chaque nœud NVMe dispose de huit appareils Dell P4610 configurés en tant qu’appareils RAID 10 sur une paire de serveurs, à l’aide d’une solution NVMe over Fabrics pour permettre la redondance des données non seulement au niveau des appareils, mais aussi au niveau du serveur. En outre, lorsque des données transitent sur l’un de ces appareils RAID 10, les 16 disques des deux serveurs sont utilisés, ce qui augmente la bande passante d’accès à celle de l’ensemble des disques. Par conséquent, la seule restriction pour ces composants est qu’ils doivent être vendus et utilisés par paires. Tous les disques NVMe pris en charge par le serveur PowerEdge R640 peuvent être utilisés dans cette solution. Toutefois, le P4610 dispose d’une bande passante séquentielle de 3 200 Mo/s en lecture et en écriture. Il offre également des IOPS aléatoires élevées, un avantage intéressant pour estimer le nombre de paires nécessaires pour répondre aux exigences de ce niveau Flash lorsque l’on cherche à faire évoluer la configuration.
Chaque serveur R640 dispose de deux adaptateurs HCA Mellanox ConnectX-6 simple port VPI HDR100 utilisés comme connexions EDR IB 100 Gb. Les nœuds NVMe prennent toutefois en charge les vitesses HDR100 lorsqu’ils sont utilisés avec des câbles et des commutateurs HDR. Le test du HDR100 sur ces nœuds est reporté dans le cadre de la mise à jour du HDR100 pour l’ensemble de la solution PixStor. Les deux interfaces CX6 sont utilisées pour synchroniser les données pour le RAID 10 (NVMe over Fabrics) et pour assurer la connectivité pour le système de fichiers. En outre, elles fournissent une redondance matérielle au niveau de l’adaptateur, du port et du câble. Pour la redondance au niveau du commutateur, des adaptateurs CX6 VPI double port sont nécessaires, mais ils doivent être achetés en tant que composants S&P.
Pour caractériser les performances des nœuds NVMe, à partir du système représenté dans la Figure 1, seuls le module de métadonnées à forte demande et les nœuds NVMe ont été utilisés.
Le Tableau 1 répertorie la liste des principaux composants de la solution. Dans la liste des disques pris en charge dans la baie ME4024, les disques SSD de 960 Gbit ont été utilisés pour les métadonnées et pour la caractérisation des performances. Les disques plus rapides peuvent délivrer de meilleures IOPS aléatoires et améliorer les opérations de création/suppression de métadonnées. Tous les appareils NVMe pris en charge sur le serveur PowerEdge R640 sont pris en charge pour les nœuds NVMe.
Tableau 1 Composants utilisés à la date de lancement et composants utilisés sur le banc d’essai
|
À la date de publication |
||
|
Connectivité Internet |
Dell Networking S3048-ON Gigabit Ethernet |
|
|
Sous-système de stockage de données |
1 à 4 baies Dell EMC PowerVault ME4084 1 à 4 baies Dell EMC PowerVault ME484 (une par ME4084) |
|
|
Sous-système de stockage High Demand Metadata en option |
1 à 2 baies Dell EMC PowerVault ME4024 (4 ME4024 si nécessaire, pour grande configuration uniquement) |
|
|
Contrôleurs de stockage RAID |
SAS 12 Gbit/s |
|
|
Processeur |
Nœuds NVMe |
2 processeurs Intel Xeon Gold 6230 2.1G, 20C/40T |
|
High Demand Metadata |
||
|
Nœud de stockage |
||
|
Nœud de gestion |
2 processeurs Intel Xeon Gold 5220 2.2G, 18C/36T |
|
|
Mémoire |
Nœuds NVMe |
12 barrettes RDIMM de 16 Gio à 2 933 MT/s (192 Gio) |
|
High Demand Metadata |
||
|
Nœud de stockage |
||
|
Nœud de gestion |
12 barrettes DIMM de 16 Go à 2 666 MT/s (192 Gio) |
|
|
Système d’exploitation |
CentOS 7.7 |
|
|
Version du noyau |
3.10.0-1062.12.1.el7.x86_64 |
|
|
Logiciel PixStor |
5.1.3.1 |
|
|
Logiciel de système de fichiers |
Spectrum Scale (GPFS) 5.0.4-3 avec NVMesh 2.0.1 |
|
|
Connectivité réseau hautes performances |
Nœuds NVMe : 2 ports ConnectX-6 InfiniBand avec EDR/100 GbE |
|
|
Commutateur hautes performances |
2 commutateurs Mellanox SB7800 |
|
|
Version OFED |
Mellanox OFED 5.0-2.1.8.0 |
|
|
Disques locaux (système d’exploitation et analyse/surveillance) |
Tous les serveurs, à l’exception de ceux répertoriés nœuds NVMe 3 disques SSD SAS3 de 480 Go (RAID1 + HS) pour le système d’exploitation 3 disques SSD SAS3 de 480 Go (RAID1 + HS) pour le système d’exploitation Contrôleur RAID PERC H730P Contrôleur RAID PERC H740P Nœud de gestion 3 disques SSD SAS3 de 480 Go (RAID1 + HS) pour le système d’exploitation avec contrôleur RAID PERC H740P |
|
|
Gestion de systèmes |
iDRAC 9 Enterprise + Dell EMC OpenManage |
|
Caractérisation des performances
Pour caractériser ce nouveau composant Ready Solution, les benchmarks suivants ont été utilisés :
· IOzone N à N en mode séquentiel
· IOR N à 1 en mode séquentiel
· IOzone en mode aléatoire
· MDtest
Pour tous les benchmarks répertoriés ci-dessus, le banc d’essai a utilisé les clients décrits dans le Tableau 2 ci-dessous. Étant donné que le nombre de nœuds de calcul disponibles pour les tests n’était que de 16, lorsqu’un plus grand nombre de threads était nécessaire, ces threads ont été répartis équitablement sur les nœuds de calcul (c’est-à-dire 32 threads = 2 threads par nœud, 64 threads = 4 threads par nœud, 128 threads = 8 threads par nœud, 256 threads = 16 threads par nœud, 512 threads = 32 threads par nœud, 1 024 threads = 64 threads par nœud). L’objectif était de simuler un plus grand nombre de clients simultanés avec le nombre limité de nœuds de calcul disponibles. Comme certains benchmarks prennent en charge un grand nombre de threads, une valeur maximale de 1 024 a été utilisée (spécifiée pour chaque test), tout en évitant qu’une commutation de contexte excessive et d’autres effets secondaires associés aient des répercussions sur les résultats des performances.
Tableau 2 Banc d’essai client
|
Nombre de nœuds client |
16 |
|
Nœud client |
C6320 |
|
Processeurs par nœud client |
2 processeurs Intel(R) Xeon(R) Gold E5-2697v4 18 cœurs à 2,30 GHz |
|
Mémoire par nœud client |
8 barrettes RDIMM de 16 Gio à 2 400 MT/s (128 Gio) |
|
BIOS |
2.8.0 |
|
Noyau du système d’exploitation |
3.10.0-957.10.1 |
|
Logiciel de système de fichiers |
Spectrum Scale (GPFS) 5.0.4-3 avec NVMesh 2.0.1 |
Performances IOzone séquentielles N clients vers N fichiers
Les performances séquentielles de N clients vers N fichiers ont été mesurées avec IOzone version 3.487. Les tests ont été exécutés dans plusieurs configurations allant d’un thread à 1 024 threads, par incréments de puissance de deux.
Les effets de mise en cache sur les serveurs ont été minimisés en réglant le pool de pages GPFS à 16 Gio et en utilisant des fichiers plus de deux fois plus volumineux. Il est important de noter que pour GPFS, ce paramètre réglable définit la quantité maximale de mémoire utilisée pour la mise en cache des données, quelle que soit la quantité de mémoire RAM installée et disponible. Par ailleurs, dans les précédentes solutions HPC de Dell EMC, la taille de bloc pour les transferts séquentiels volumineux était de 1 Mio ; GPFS ayant été formaté avec 8 blocs de 8 Mio, cette valeur a été utilisée sur le benchmark pour obtenir des performances optimales. Cela peut sembler trop volumineux et donner l’impression de gaspiller trop d’espace, mais GPFS utilise l’allocation de sous-blocs pour éviter cette situation. Dans la configuration actuelle, chaque bloc était subdivisé en 256 sous-blocs de 32 Kio chacun.
Les commandes suivantes ont été utilisées pour exécuter le benchmark pour les opérations de lecture et d’écriture, « $Threads » étant la variable correspondant au nombre de threads utilisés (de 1 à 1 024, incrémentés par puissances de deux), et « threadlist » le fichier correspondant qui a alloué chaque thread sur un nœud différent, en utilisant une permutation circulaire pour les répartir de manière homogène sur les 16 nœuds de calcul.
Pour éviter tout effet de mise en cache des données des clients, la taille totale des données des fichiers était deux fois supérieure à la quantité totale de RAM des clients utilisés. Cela signifie que, puisque chaque client dispose de 128 Gio de RAM, pour les configurations supérieures ou égales à 16 threads, la taille de fichier était de 4 096 Gio divisés par le nombre de threads (la variable $Size ci-dessous a été utilisée pour gérer cette valeur). Dans les configurations à moins de 16 threads (ce qui implique que chaque thread s’exécute sur un client différent), la taille de fichier a été fixée à deux fois la quantité de mémoire par client, soit 256 Gio.
iozone -i0 -c -e -w -r 8M -s $ G -t $Threads -+n -+m ./threadlist
iozone -i1 -c -e -w -r 8M -s $ G -t $Threads -+n -+m ./threadlist
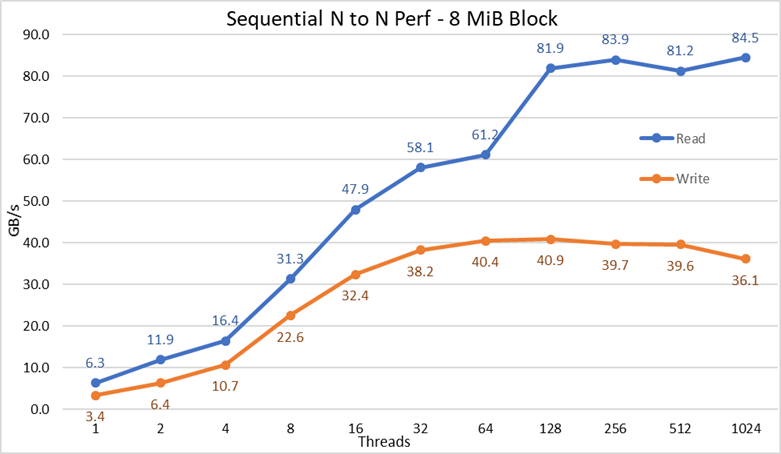
Figure 2 Performances séquentielles N à N
À partir des résultats, nous pouvons observer que les performances d’écriture augmentent avec le nombre de threads utilisés, jusqu’à atteindre un plateau à environ 64 threads pour les écritures et à 128 threads pour les lectures. Les performances de lecture augmentent également rapidement avec le nombre de threads, puis restent stables jusqu’à ce que le nombre maximal de threads autorisé par IOzone soit atteint. Par conséquent, les performances séquentielles de fichiers volumineux sont stables, même pour 1 024 clients simultanés. Les performances d’écriture chutent d’environ 10 % à 1 024 threads. Toutefois, étant donné que le cluster client dispose d’un nombre de cœurs inférieur, il n’est pas certain que la baisse des performances soit due à une permutation et à une surcharge similaire qui n’est pas observée sur les supports tournants (car la latence NVMe est très faible par rapport à celle des supports tournants), ou que la synchronisation des données RAID 10 devienne un goulot d’étranglement. Des clients supplémentaires sont nécessaires pour clarifier ce point. Lors des lectures, une anomalie a été observée à 64 threads, où les performances n’évoluaient pas à la vitesse observée sur les points de données précédents, avant de passer à une valeur très proche des performances soutenues au point de données suivant. Il faudrait effectuer d’autres tests pour comprendre la cause de cette anomalie, mais ce point n’est pas abordé dans ce blog.
Les performances de lecture maximales étaient inférieures aux performances théoriques des appareils NVMe (~102 Go/s) ou aux performances des liaisons EDR, même en supposant qu’une seule liaison était principalement utilisée pour le trafic NVMe over Fabrics (4 liaisons EDR pour une bande passante d’environ 96 Go/s).
Cela n’est pas surprenant, car la configuration matérielle n’est pas équilibrée par rapport aux appareils NVMe et aux adaptateurs HCA IB sous chaque socket de processeur. L’un des adaptateurs CX6 est rattaché au CPU1, tandis que le CPU2 regroupe l’ensemble des appareils NVMe et des adaptateurs CX6 secondaires. Tout trafic de stockage utilisant le premier HCA doit utiliser les UPI pour accéder aux appareils NVMe. En outre, les cœurs du processeur 1 utilisé doivent accéder à des appareils ou à la mémoire attribuée au processeur 2, ce qui affecte la localité des données et implique l’utilisation de liaisons UPI. Cela peut expliquer la réduction des performances maximales comparativement aux performances maximales des appareils NVMe ou à la vitesse de ligne des adaptateurs HCA CX6. La solution pour corriger cette limitation consiste à disposer d’une configuration matérielle équilibrée, ce qui implique de réduire la densité de moitié en utilisant un serveur R740 avec quatre logements x16 et en utilisant deux modules d’extension PCIe x16 pour répartir équitablement les appareils NVMe sur deux processeurs, et de disposer d’un adaptateur HCA CX6 sous chaque processeur.
Performances IOR séquentielles N clients vers 1 fichier
Les performances séquentielles de N clients vers un seul fichier partagé ont été mesurées avec iOR version 3.3.0, en utilisant OpenMPI v4.0.1 pour exécuter le benchmark sur les 16 nœuds de calcul. Les tests ont été exécutés dans plusieurs configurations variant d’un seul thread à 512 threads, car il n’y avait pas assez de cœurs pour 1 024 threads ou plus. Ces tests de benchmark ont utilisé des blocs de 8 Mio pour produire des performances optimales. La section précédente sur les tests de performances explique plus en détail pourquoi cela est important.
Les effets de mise en cache des données ont été minimisés en réglant le pool de pages GPFS sur 16 Gio, et la taille totale des fichiers était deux fois supérieure à la quantité totale de RAM des clients utilisés. Cela signifie que, puisque chaque client dispose de 128 Gio de RAM, pour les configurations supérieures ou égales à 16 threads, la taille de fichier était de 4 096 Gio, et une quantité égale à cette valeur totale a été divisée par le nombre de threads (la variable $Size ci-dessous a été utilisée pour gérer cette valeur). Dans les configurations à moins de 16 threads (ce qui implique que chaque thread s’exécutait sur un client différent), la taille de fichier était deux fois supérieure à la quantité de mémoire par client utilisée multipliée par le nombre de threads ; en d’autres termes, chaque thread devait utiliser 256 Gio.
Les commandes suivantes ont été utilisées pour exécuter le benchmark pour les opérations de lecture et d’écriture, « $Threads » étant la variable correspondant au nombre de threads utilisés (de 1 à 1 024, incrémentés par puissances de deux), et « my_hosts.$Threads » le fichier correspondant qui a alloué chaque thread sur un nœud différent, en utilisant une permutation circulaire pour les répartir de manière homogène sur les 16 nœuds de calcul.
mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads --mca btl_openib_allow_ib 1 --mca pml ^ucx --oversubscribe --prefix /mmfs1/perftest/ompi /mmfs1/perftest/lanl_ior/bin/ior -a POSIX -v -i 1 -d 3 -e -k -o /mmfs1/perftest/tst.file -w -s 1 -t 8m -b $ G
mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads --mca btl_openib_allow_ib 1 --mca pml ^ucx --oversubscribe --prefix /mmfs1/perftest/ompi /mmfs1/perftest/lanl_ior/bin/ior -a POSIX -v -i 1 -d 3 -e -k -o /mmfs1/perftest/tst.file -r -s 1 -t 8m -b $ G
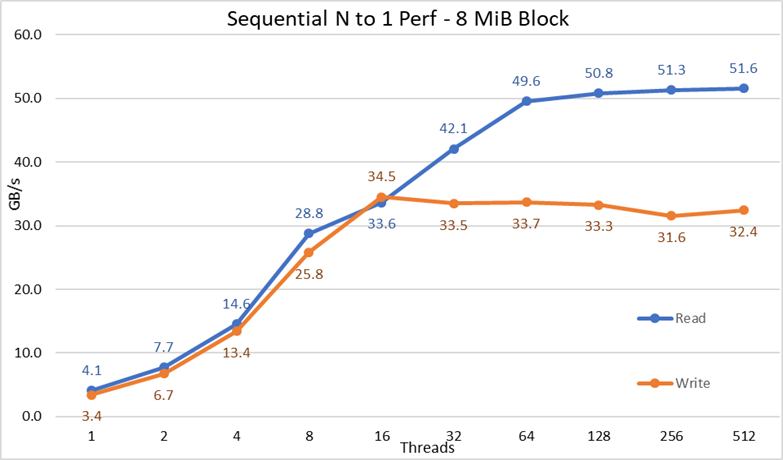
Figure 3 Performances séquentielles N à 1
À partir des résultats, nous pouvons observer que les performances de lecture et d’écriture sont élevées, indépendamment du fait que des mécanismes de verrouillage soient implicitement nécessaires car tous les threads accèdent au même fichier. Les performances augmentent à nouveau très rapidement avec le nombre de threads utilisés, puis atteignent un plateau relativement stable pour les lectures et les écritures jusqu’à atteindre le nombre maximal de threads utilisés lors de ce test. À noter que les performances de lecture maximales étaient de 51,6 Go/s à 512 threads, mais que le plateau de performances est atteint à environ 64 threads. De même, les performances d’écriture maximales de 34,5 Go/s ont été atteintes à 16 threads et ont atteint un plateau qui peut être observé jusqu’au nombre maximal de threads utilisés.
Petits blocs aléatoires, performances IOzone séquentielles N clients vers N fichiers
Les performances séquentielles N clients vers N fichiers ont été mesurées avec IOzone version 3.487. Les tests ont été exécutés dans plusieurs configurations allant d’un thread à 1 024 threads, par incréments de puissance de deux.
Les tests ont été exécutés dans plusieurs configurations variant d’un seul thread à 512 threads, car il n’y avait pas assez de cœurs clients pour 1 024 threads. Chaque thread utilisait un fichier différent et les threads ont été attribués selon une permutation circulaire sur les nœuds client. Ce test de benchmark a utilisé des blocs de 4 Kio pour émuler le trafic de petits blocs et utiliser une profondeur de file d’attente de 16. Une comparaison est effectuée entre les résultats de la solution à grande échelle et ceux de l’extension de la capacité.
Là encore, les effets de mise en cache ont été minimisés en réglant le pool de pages GPFS sur 16 Gio. Pour éviter tout effet possible de mise en cache des données des clients, la taille totale des données des fichiers était deux fois supérieure à la quantité totale de RAM des clients utilisés. Cela signifie que, puisque chaque client dispose de 128 Gio de RAM, pour les configurations supérieures ou égales à 16 threads, la taille de fichier était de 4 096 Gio divisés par le nombre de threads (la variable $Size ci-dessous a été utilisée pour gérer cette valeur). Dans les configurations à moins de 16 threads (ce qui implique que chaque thread s’exécute sur un client différent), la taille de fichier a été fixée à deux fois la quantité de mémoire par client, soit 256 Gio.
iozone -i0 -I -c -e -w -r 8M -s $ G -t $Threads -+n -+m ./nvme_threadlist <= Create the files sequentially
iozone -i2 -I -c -O -w -r 4k -s $ G -t $Threads -+n -+m ./nvme_threadlist <= Perform the random reads and writes.
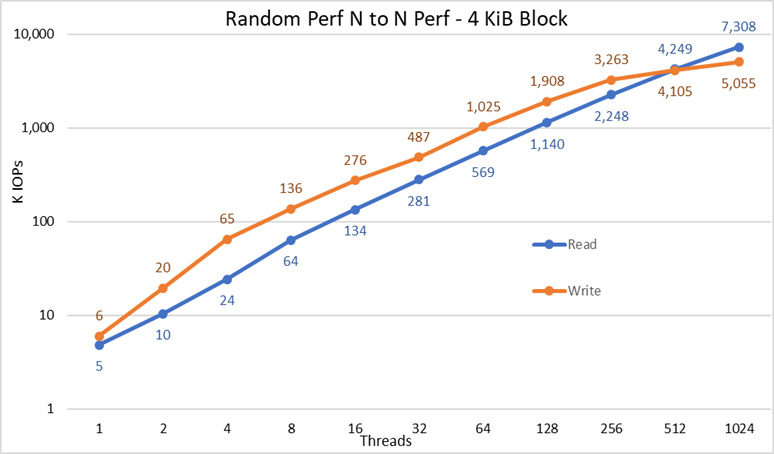
Figure 4 Performances aléatoires N à N
À partir des résultats, nous pouvons observer que les performances d’écriture commencent à une valeur élevée de 6 000 IOPS et augmentent régulièrement jusqu’à 1 024 threads, où elles semblent atteindre un plateau à plus de 5 millions d’IOPS si davantage de threads pouvaient être utilisés. En revanche, les performances de lecture commencent à 5 000 IOPS et augmentent régulièrement avec le nombre de threads utilisés (gardez à l’esprit que le nombre de threads est doublé pour chaque point de données). Elles atteignent les performances maximales de 7,3 millions d’IOPS à 1 024 threads, sans signe laissant penser qu’elles atteignent un plateau. L’utilisation d’un plus grand nombre de threads nécessite plus de 16 nœuds de calcul pour éviter une pénurie de ressources et une permutation excessive qui peuvent réduire les performances apparentes, là où les nœuds NVMe pourraient en fait maintenir les performances.
Performances des métadonnées avec MDtest à l’aide de fichiers de 4 Kio
Les performances des métadonnées ont été mesurées avec MDtest version 3.3.0, en utilisant OpenMPI v4.0.1 pour exécuter le benchmark sur les 16 nœuds de calcul. Les tests exécutés ont utilisé de 1 à 512 threads. Le benchmark a été utilisé pour les fichiers uniquement (pas de métadonnées de répertoires) pour obtenir le nombre de créations, de statistiques, de lectures et de suppressions que la solution est capable de gérer, et les résultats ont été comparés à ceux de la solution de grande taille.
Le High Demand Metadata Module en option a été utilisé, mais avec une seule baie ME4024, même si la configuration de grande taille testée était conçue pour supporter deux baies ME4024. L’utilisation de ce module de métadonnées est due au fait que ces nœuds NVMe sont actuellement utilisés comme cibles de stockage pour les données uniquement. Les nœuds peuvent cependant être utilisés pour stocker des données et des métadonnées, ou même comme alternative Flash au High Demand Metadata Module, si des exigences de métadonnées extrêmes l’exigent. Ces configurations n’ont pas été testées dans le cadre de cet article.
Dans la mesure où le même High Demand Metadata Module a été utilisé pour l’analyse comparative précédente de Dell EMC Ready Solution for HPC PixStor Storage, les résultats des métadonnées seront très similaires à ceux des précédents articles de blog. Pour cette raison, aucune étude n’a été effectuée avec des fichiers vides ; des fichiers de 4 Kio ont donc été utilisés. Étant donné que les fichiers de 4 Ko ne peuvent pas tenir dans un inode avec les informations de métadonnées, des nœuds NVMe seront utilisés pour stocker les données de chaque fichier. Par conséquent, le benchmark MDtest peut donner une idée approximative des performances des fichiers de petite taille pour les lectures et le reste des opérations de métadonnées.
La commande suivante a été utilisée pour exécuter le benchmark, « $Threads » étant la variable correspondant au nombre de threads utilisés (de 1 à 512, incrémentés par puissances de deux), et my_hosts.$Threads le fichier correspondant qui a alloué chaque thread sur un nœud différent, en utilisant une permutation circulaire pour les répartir de manière homogène sur les 16 nœuds de calcul. Comme dans le cas du benchmark d’E/S aléatoires, le nombre maximal de threads a été limité à 512, car il n’y a pas suffisamment de cœurs pour 1 024 threads et la commutation de contexte affecterait les résultats, en signalant un nombre inférieur aux performances réelles de la solution.
mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads --prefix /mmfs1/perftest/ompi --mca btl_openib_allow_ib 1 /mmfs1/perftest/lanl_ior/bin/mdtest -v -d /mmfs1/perftest/ -i 1 -b $Directories -z 1 -L -I 1024 -y -u -t -F -w 4K -e 4K
Étant donné que les résultats des performances peuvent être affectés par le nombre total d’IOPS, le nombre de fichiers par répertoire et le nombre de threads, il a été décidé de fixer le nombre total de fichiers à 2 Mio (2^21 = 2 097 152), de fixer le nombre de fichiers par répertoire à 1 024 et de faire varier le nombre de répertoires en fonction du nombre de threads, comme indiqué dans le Tableau 3.
Tableau 3 Distribution des fichiers sur les répertoires avec MDtest
|
Nombre de threads |
Nombre de répertoires par thread |
Nombre total de fichiers |
|
1 |
2048 |
2 097 152 |
|
2 |
1 024 |
2 097 152 |
|
4 |
512 |
2 097 152 |
|
8 |
256 |
2 097 152 |
|
16 |
128 |
2 097 152 |
|
32 |
64 |
2 097 152 |
|
64 |
32 |
2 097 152 |
|
128 |
16 |
2 097 152 |
|
256 |
8 |
2 097 152 |
|
512 |
4 |
2 097 152 |
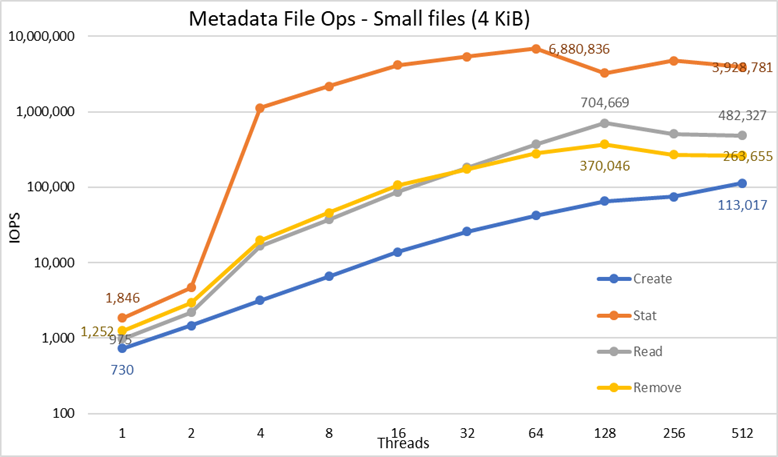
Figure 5 Performances des métadonnées - Fichiers de 4 Kio
Tout d’abord, notez que nous avons choisi une échelle logarithmique en base 10 pour pouvoir comparer des opérations qui ont des différences de plusieurs ordres de grandeur. Sinon, certaines opérations ressembleraient à une ligne plate proche de 0 sur une échelle linéaire. Un graphique logarithmique en base 2 pourrait être plus approprié, car le nombre de threads augmente par puissance de 2, mais le graphique aurait une apparence très similaire et les gens ont tendance à mieux gérer et mémoriser les nombres basés sur des puissances de 10.
Le système donne de très bons résultats, comme indiqué précédemment avec des opérations de statistiques qui atteignent la valeur maximale à 64 threads avec presque 6,9 millions d’opérations par seconde, puis diminuent pour des nombres de threads plus élevés atteignant un plateau. Les opérations de création atteignent les performances maximales de 113 000 opérations par seconde sur 512 threads. Elles devraient donc continuer à augmenter si davantage de nœuds clients (et de cœurs) sont utilisés. Les opérations de lecture et de suppression ont atteint leur maximum à 128 threads, atteignant leur pic à près de 705 000 opérations par seconde pour les lectures et 370 000 opérations par seconde pour les suppressions, avant d’atteindre des plateaux. Les opérations de statistiques sont plus variables, mais une fois qu’elles atteignent leur valeur maximale, les performances ne passent pas en-deçà de 3,2 millions d’opérations par seconde. La création et la suppression sont plus stables une fois qu’elles atteignent un plateau et restent supérieures à 265 000 opérations par seconde pour la suppression et 113 000 opérations par seconde pour la création. Pour finir, les lectures atteignent un plateau avec des performances supérieures à 265 000 opérations par seconde.
Conclusions et travaux futurs
Les nœuds NVMe introduits dans la solution de stockage HPC sont essentiels pour fournir un niveau très hautes performances, avec une bonne densité ainsi que des performances d’accès aléatoire et des performances séquentielles très élevées. En outre, la solution évolue de manière linéaire en termes de capacité et de performances à mesure que davantage de modules de nœuds NVMe sont ajoutés. Les performances des nœuds NVMe présentées dans le Tableau 4 sont censées être stables, et ces valeurs peuvent être utilisées pour estimer les performances pour un nombre différent de nœuds NVMe.
Toutefois, gardez à l’esprit que les nombres indiqués dans le Tableau 4 doivent être divisés par deux pour chaque paire de nœuds NVMe.
Cette solution fournit aux clients HPC un système de fichiers parallèle très fiable utilisé par la plupart des 500 principaux clusters HPC. En outre, elle offre des fonctionnalités de recherche exceptionnelles, des capacités de surveillance et de gestion avancées, et l’ajout de passerelles en option permet le partage de fichiers via des protocoles standard aussi courants que NFS, SMB, etc., avec autant de clients que nécessaire.
Tableau 4 Performances maximales et continues pour 2 paires de nœuds NVMe
|
|
Performances maximales |
Performances continues |
||
|
Écriture |
Read |
Écriture |
Read |
|
|
Mode séquentiel volumineux N clients vers N fichiers |
40,9 Go/s |
84,5 Go/s |
40 Go/s |
81 Go/s |
|
Mode séquentiel volumineux N clients vers un seul fichier partagé |
34,5 Go/s |
51,6 Go/s |
31,5 Go/s |
50 Go/s |
|
Mode aléatoire avec petits blocs N clients vers N fichiers |
5,06 millions d’IOPS |
7,31 millions d’IOPS |
5 millions d’IOPS |
7,3 millions d’IOPS |
|
Métadonnées, opérations de création, fichiers de 4 Kio |
113 000 IOPS |
113 000 IOPS |
||
|
Métadonnées, opérations de statistiques, fichiers de 4 Kio |
6,88 millions d’IOPS |
3,2 millions d’IOPS |
||
|
Métadonnées, opérations de lecture, fichiers de 4 Kio |
705 000 IOPS |
500 000 IOPS |
||
|
Métadonnées, opérations de suppression, fichiers de 4 Kio |
370 000 IOPS |
265 000 IOPS |
||
Comme les nœuds NVMe ont été utilisés uniquement pour les données, nous pouvons envisager dans les travaux futurs de les utiliser pour les données et les métadonnées, et disposer d’un niveau Flash autonome offrant de meilleures performances de métadonnées en raison de la bande passante plus élevée et de la latence plus faible des appareils NVMe par rapport aux disques SSD SAS3 derrière les contrôleurs RAID. Par ailleurs, si un client a des exigences extrêmement élevées en matière de métadonnées et a besoin d’une solution plus dense que ce que peut fournir le High Demand Metadata Module, certains appareils RAID 10 distribués (voire tous) peuvent être utilisés pour les métadonnées de la même manière que les appareils RAID 1 sont actuellement utilisés sur les baies ME4024.
Dans un prochain article de blog, nous présenterons les nœuds PixStor Gateway, qui permettent de connecter la solution PixStor à d’autres réseaux à l’aide de protocoles NFS ou SMB et de faire évoluer les performances. De plus, la solution sera bientôt mise à jour vers HDR100, ce qui devrait faire l’objet d’un autre article de blog.