Dell EMC-färdig lösning för lagring med HPC PixStor – NVMe-nivå
Summary: Blogg om en komponent i HPC-lagringslösningen, inklusive arkitektur och prestandautvärdering.
Symptoms
Blogg om en komponent i HPC-lagringslösningen, inklusive arkitektur och prestandautvärdering.
Resolution
Dell EMC-färdig lösning för lagring med HPC PixStor
NVMe-nivå
Innehållsförteckning
Sekventiell IOzone-prestanda N klienter till N-filer
Sekventiell IOR-prestanda N klienter till 1 fil
Slumpmässiga små block IOzone Performance N klienter till N filer
Metadataprestanda med MDtest med 4 KiB-filer
slutsatser och framtida arbete
Introduktion
Dagens HPC-miljöer har ökat kraven på lagring med mycket hög hastighet, och med processorer med högre antal, snabbare nätverk och större minne blev lagringen flaskhalsen i många arbetsbelastningar. Dessa HPC-krav med höga krav täcks vanligtvis av parallella filsystem (PFS) som ger samtidig åtkomst till en enda fil eller en uppsättning filer från flera noder, vilket på ett mycket effektivt och säkert sätt distribuerar data till flera LUN över flera servrar. Dessa filsystem är normalt spinnmedia baserade för att ge högsta kapacitet till lägsta kostnad. Men allt oftare kan hastigheten och latensen hos snurrande medier inte hålla jämna steg med kraven för många moderna HPC-arbetsbelastningar, vilket kräver användning av flashteknik i form av burst-buffertar, snabbare nivåer eller till och med mycket snabba repor, lokala eller distribuerade. DellEMC Ready Solution för HPC PixStor-lagringanvänder NVMe-noder som komponent för att täcka sådana nya krav på hög bandbredd, utöver att den är flexibel, skalbar, effektiv och tillförlitlig.
Lösningsarkitektur
Den här bloggen är del i en serie PFS-lösningar (Parallel File System) för HPC-miljöer, i synnerhet för DellEMC Ready Solution för HPC PixStor-lagring, där DellEMC PowerEdge R640-servrar med NVMe-enheter används som en snabb flashbaserad nivå.
PixStor PFS-lösningen inkluderar det utbredda General Parallel File System, även känt som Spectrum Scale. ArcaStream innehåller också många andra programvarukomponenter för att tillhandahålla avancerad analys, förenklad administration och övervakning, effektiv filsökning, avancerade gatewayfunktioner och mer.
NVMe-noderna som presenteras i den här bloggen ger en flashbaserad nivå med mycket hög prestanda för PixStor-lösningen. Prestanda och kapacitet för den här NVMe-nivån kan skalas ut av ytterligare NVMe-noder. Ökad kapacitet tillhandahålls genom att välja lämpliga NVMe-enheter som stöds i PowerEdge R640.
Bild 1 visar referensarkitekturen som visar en lösning med 4 NVMe-noder med hjälp av metadatamodulen med hög efterfrågan, som hanterar alla metadata i den testade konfigurationen. Anledningen är att dessa NVMe-noder för närvarande används som lagringsmål för endast data. NVMe-noderna kan dock också användas för att lagra data och metadata, eller till och med som ett snabbare flash-alternativ till den efterfrågade metadatamodulen, om extrema metadatakrav kräver det. Dessa konfigurationer för NVMe-noderna testades inte som en del av det här arbetet, men kommer att testas i framtiden.
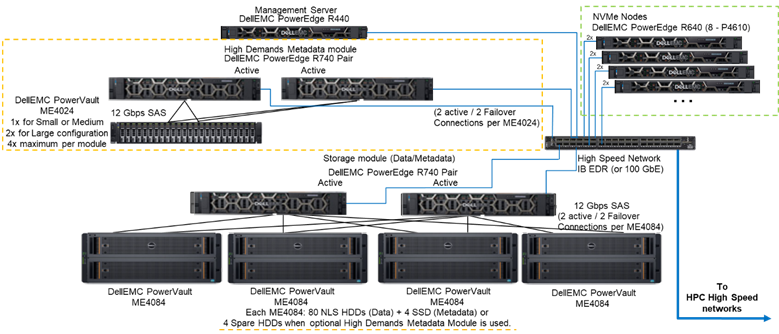
Bild 1 Referensarkitektur
Lösningens komponenter
Denna lösning använder den senaste Intel Xeonandra generationens skalbara Xeon CPU:er, även kallade Cascade Lake-processorer och det snabbaste RAM-minnet som finns tillgängligt (2 933 MT/s), förutom hanteringsnoderna för att hålla dem kostnadseffektiva. Dessutom uppdaterades lösningen till den senaste versionen av PixStor (5.1.3.1) som stöder RHEL 7.7 och OFED 5.0 som kommer att vara de mjukvaruversioner som stöds vid lanseringen.
Varje NVMe-nod har åtta Dell P4610-enheter som är konfigurerade som åtta RAID 10-enheter över ett par servrar, med hjälp av en NVMe over Fabric-lösning för att möjliggöra dataredundans inte bara på enhetsnivå utan även på servernivå. När data överförs till eller från en av dessa RAID10-enheter används dessutom alla 16 enheter i båda servrarna, vilket ökar bandbredden för åtkomsten till alla enheter. Därför är den enda begränsningen för dessa komponenter att de måste säljas och användas i par. Alla NVMe-enheter som stöds av PowerEdge R640 kan användas i den här lösningen, men P4610 har en sekventiell bandbredd på 3 200 MB/s för både läsningar och skrivningar, samt höga slumpmässiga IOPS-specifikationer, vilket är bra funktioner när man försöker skala uppskatta antalet par som behövs för att uppfylla kraven för den här flashnivån.
Varje R640-server har två HCA:er: Mellanox ConnectX-6 med en port, VPI HDR100 som används som EDR 100 Gb IB-anslutningar. NVMe-noderna är dock redo att stödja HDR100-hastigheter när de används med HDR-kablar och switchar. Testning av HDR100 på dessa noder skjuts upp som en del av HDR100-uppdateringen för hela PixStor-lösningen. Båda CX6-gränssnitten används för att synkronisera data för RAID 10 (NVMe over fabric) och som anslutning för filsystemet. Dessutom tillhandahåller de maskinvaruredundans vid adaptern, porten och kabeln. För redundans på switchnivå krävs CX6 VPI-adaptrar med dubbla portar, men de måste införskaffas som S&P-komponenter.
För att karakterisera prestandan hos NVMe-noder användes endast metadatamodulen med hög efterfrågan och NVMe-noderna från systemet som visas i figur 1.
I tabell 1 visas en lista över lösningens huvudkomponenter. I listan över enheter som stöds i ME4024 kan nämnas att 960 Gb SSD-hårddiskar användes för metadata och var de som användes för prestandakarakterisering. Snabbare enheter kan ge bättre slumpvisa IOPS och kan förbättra åtgärder för att skapa/ta bort metadata. Alla NVMe-enheter som stöds på PowerEdge R640 kommer att stödjas för NVMe-noderna.
Tabell 1 Komponenter som ska användas vid frisläppning och de som används i testbädden
|
Vid lansering |
||
|
Interna anslutningsmöjligheter |
Dell Networking S3048-ON Gigabit Ethernet |
|
|
Undersystem för datalagring |
1 till 4 gånger Dell EMC PowerVault ME4084 1 till 4 Dell EMC PowerVault ME484 (en per ME4084) |
|
|
Metadatalagringsundersystem med hög efterfrågan som tillval |
1 till 2 × Dell EMC PowerVault ME4024 (4 × ME4024 om det behövs, endast stor konfiguration) |
|
|
RAID-lagringsstyrenheter |
12 Gbit/s SAS |
|
|
Processor |
NVMe-noder |
2 × Intel Xeon Gold 6230 2,1 G, 20 kärnor/40 trådar |
|
Metadata med hög efterfrågan |
||
|
Lagringsnod |
||
|
Hanteringsnod |
2 × Intel Xeon Gold 5220, 2,2 G, 18 kärnor/36 trådar |
|
|
Minne |
NVMe-noder |
12 × 16 GiB 2 933 MT/s RDIMM (192 GiB) |
|
Metadata med hög efterfrågan |
||
|
Lagringsnod |
||
|
Hanteringsnod |
12 × 16 GB DIMM-moduler, 2 666 MT/s (192 GiB) |
|
|
Operativsystem |
CentOS 7.7 |
|
|
Kernel-version |
3.10.0-1062.12.1.el7.x86_64 |
|
|
PixStor-programvara |
5.1.3.1 |
|
|
Filsystemprogramvara |
Spectrum Scale (GPFS) 5.0.4-3 med NVMesh 2.0.1 |
|
|
Nätverksanslutning med hög prestanda |
NVMe-noder: 2 × ConnectX-6 InfiniBand med EDR/100 GbE |
|
|
Omkopplare med hög prestanda |
2 × Mellanox SB7800 |
|
|
OFED Version |
Mellanox OFED 5.0-2.1.8.0 |
|
|
Lokala diskar (OS och analys/övervakning) |
Alla servrar utom de som anges NVMe-noder 3 × 480 GB SSD SAS3 (RAID1 + HS) för OS3 × 480 GB SSD SAS3 (RAID1 + HS) för OS PERC H730P RAID-styrenhet PERC H740P RAID-kontroller Hanteringsnod 3 × 480 GB SSD SAS3 (RAID1 + HS) för OS med PERC H740P RAID-kontroller |
|
|
Systemhantering |
iDRAC 9 Enterprise + DellEMC OpenManage |
|
Karakterisering av prestanda
Följande prestandatest användes för att karakterisera den nya komponenten Ready Solution :
·IOzon N till N sekventiell
·IOR N till 1 sekventiell
·IOzone slumpmässigt
·MDtest
För alla riktmärken som anges ovan hade testbädden de kunder som beskrivs i tabell 2 nedan. Eftersom antalet beräkningsnoder som var tillgängliga för testning endast var 16, när ett högre antal trådar krävdes, fördelades dessa trådar jämnt på beräkningsnoderna (dvs. 32 trådar = 2 trådar per nod, 64 trådar = 4 trådar per nod, 128 trådar = 8 trådar per nod, 256 trådar = 16 trådar per nod, 512 trådar = 32 trådar per nod, 1 024 trådar = 64 trådar per nod). Avsikten var att simulera ett högre antal samtidiga klienter med det begränsade antalet tillgängliga beräkningsnoder. Eftersom vissa prestandatest stöder ett stort antal trådar användes ett maxvärde på upp till 1024 (anges för varje test), samtidigt som man undvek överdriven kontextväxling och andra relaterade biverkningar från att påverka prestandaresultaten.
Tabell 2 Testbädd för kunder
|
Antal klientnoder |
16 |
|
Klientnod |
C6320 |
|
Processorer per klientnod |
2x Intel(R) Xeon(R) Gold E5-2697v4, 18 kärnor @ 2,30 GHz |
|
Minne per klientnod |
8 RDIMM-moduler på 8 × 16 GiB, 2 400 MT/s (128 GiB) |
|
BIOS |
2.8.0 |
|
OS-kärna |
3.10.0-957.10.1 |
|
Filsystemprogramvara |
Spectrum Scale (GPFS) 5.0.4-3 med NVMesh 2.0.1 |
Sekventiell IOzone-prestanda N klienter till N-filer
Prestanda för sekventiella N-klienter till N-filer mättes med IOzone version 3.487. Testerna som utfördes varierade från en tråd upp till 1024 trådar i steg om två.
Cachningseffekter på servrarna minimerades genom att ställa in GPFS-sidpoolen som kan ställas in på 16GiB och använda filer som är större än två gånger den storleken. Det är viktigt att notera att för GPFS ställer den inställbara in den maximala mängden minne som används för cachelagring av data, oavsett mängden RAM-minne som är installerat och ledigt. Det är också viktigt att notera att medan blockstorleken för stora sekventiella överföringar i tidigare DellEMC HPC-lösningar var 1 MiB, formaterades GPFS med 8 MiB-block och därför används det värdet i prestandatestet för optimal prestanda. Det kan se för stort ut och tydligen slösa för mycket utrymme, men GPFS använder subblockallokering för att förhindra den situationen. I den aktuella konfigurationen var varje block indelat i 256 underblock med 32 KiB vardera.
Följande kommandon användes för att köra riktmärket för skrivningar och läsningar, där $Threads var variabeln med antalet trådar som användes (1 till 1024 ökat i potenser av två), och threadlist var filen som allokerade varje tråd på en annan nod, med resursallokering för att sprida dem homogent över de 16 beräkningsnoderna.
För att undvika eventuella datacacheeffekter från klienterna var den totala datastorleken för filerna dubbelt så stor som den totala mängden RAM-minne i klienterna som användes. Det innebär att eftersom varje klient har 128 GiB RAM-minne var filstorleken 4096 GiB för trådar som var lika med eller över 16 trådar dividerat med antalet trådar (variabeln $Size nedan användes för att hantera det värdet). I de fall med mindre än 16 trådar (vilket innebär att varje tråd kördes på en annan klient) fastställdes filstorleken till dubbelt så mycket minne per klient eller 256 GiB.
iozone -i0 -c -e -w -r 8M -s $ G -t $Threads -+n -+m ./threadlist
iozone -i1 -c -e -w -r 8M -s $ G -t $Threads -+n -+m ./threadlist
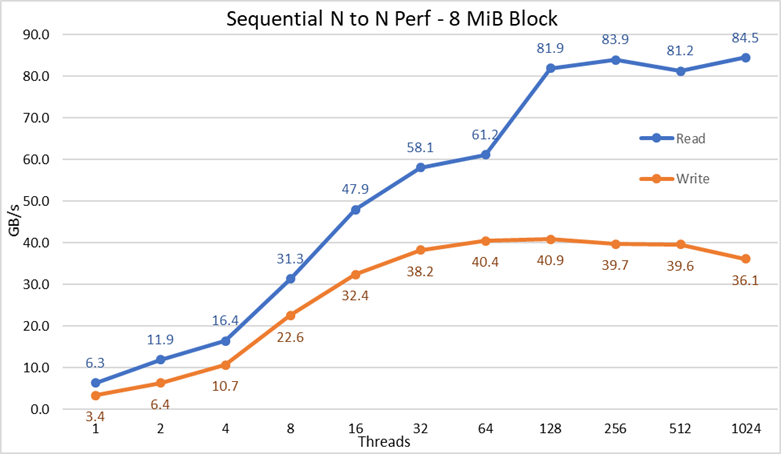
Bild 2 N till N sekventiell prestanda
Från resultaten kan vi se att skrivprestandan ökar med antalet trådar som används och sedan når en platå på cirka 64 trådar för skrivningar och 128 trådar för läsningar. Då ökar läsprestandan också snabbt med antalet trådar och förblir sedan stabil tills det maximala antalet trådar som IOzone tillåter uppnås, och därför är prestanda för stora filer stabila även för 1024 samtidiga klienter. Skrivprestanda sjunker med cirka 10 % vid 1024 trådar. Men eftersom klientklustret har färre kärnor än så antal kärnor är det osäkert om prestandaminskningen beror på växling och liknande kostnader som inte observerats i snurrande medier (eftersom NVMe-latensen är mycket låg jämfört med snurrande medier) eller om RAID 10-datasynkroniseringen håller på att bli en flaskhals. Det behövs fler kunder för att klargöra detta. En avvikelse i läsningarna observerades vid 64 trådar, där prestanda inte skalades med den hastighet som observerades för tidigare datapunkter, och sedan på nästa datapunkt flyttas till ett värde som ligger mycket nära den varaktiga prestandan. Fler tester behövs för att hitta orsaken till en sådan avvikelse, men ligger utanför ramen för den här bloggen.
Den maximala läsprestandan för läsningar var lägre än NVMe-enheternas teoretiska prestanda (~102 GB/s) eller prestandan för EDR-länkar, även om man antar att en länk främst användes för NVMe över strukturtrafik (4x EDR BW ~96 GB/s).
Det är dock inte så konstigt eftersom maskinvarukonfigurationen inte är balanserad med avseende på NVMe-enheterna och IB HCA:erna under varje processorsockel. En CX6-adapter finns under CPU1, medan CPU2 har alla NVMe-enheter och den andra CX6-adaptern. All lagringstrafik som använder det första HCA:t måste använda UPI:erna för att få åtkomst till NVMe-enheterna. Dessutom måste alla kärnor i CPU1 som används komma åt enheter eller minne som tilldelats CPU2, så dataplatsen blir lidande och UPI-länkar används. Det kan förklara minskningen för maximal prestanda jämfört med maximal prestanda för NVMe-enheterna eller linjehastigheten för CX6 HCA:er. Alternativet för att åtgärda den begränsningen är att ha en balanserad maskinvarukonfiguration, vilket innebär att minska densiteten till hälften genom att använda en R740 med fyra x16-kortplatser och använda två x16 PCIe-expandrar för att jämnt fördela NVMe-enheter på två processorer och ha en CX6 HCA under varje processor.
Sekventiell IOR-prestanda N-klienter till 1 fil
Prestanda för sekventiella N-klienter till en enda delad fil mättes med IOR version 3.3.0, med hjälp av OpenMPI v4.0.1 för att köra prestandatestet över de 16 beräkningsnoderna. Testerna som utfördes varierade från en tråd upp till 512 trådar eftersom det inte fanns tillräckligt med kärnor för 1024 eller fler trådar. I dessa prestandatest användes 8 MiB-block för optimal prestanda. I det tidigare avsnittet om prestandatest finns en mer fullständig förklaring till varför det är viktigt.
Effekterna av datacachning minimerades genom att ställa in GPFS-sidpoolen som kunde ställas in på 16GiB och den totala filstorleken var dubbelt så stor som den totala mängden RAM-minne i klienterna som användes. Det innebär att eftersom varje klient har 128 GiB RAM-minne var filstorleken 4096 GiB för trådantal som var lika med eller över 16 trådar, och en lika stor mängd av den summan dividerades med antalet trådar (variabeln $Size nedan användes för att hantera det värdet). I de fall med mindre än 16 trådar (vilket innebär att varje tråd kördes på en annan klient) var filstorleken dubbelt så mycket minne per klient som användes gånger antalet trådar, eller med andra ord ombads varje tråd att använda 256 GiB.
Följande kommandon användes för att köra riktmärket för skrivningar och läsningar, där $Threads var variabeln med antalet trådar som användes (1 till 1024 ökat i potenser av två) och my_hosts.$Threads är motsvarande fil som allokerade varje tråd på en annan nod, med resursallokering för att sprida dem homogent över de 16 beräkningsnoderna.
mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads --mca btl_openib_allow_ib 1 --mca pml ^ucx --oversubscribe --prefix /mmfs1/perftest/ompi /mmfs1/perftest/lanl_ior/bin/ior -a POSIX -v -i 1 -d 3 -e -k -o /mmfs1/perftest/tst.file -w -s 1 -t 8m -b $ G
mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads --mca btl_openib_allow_ib 1 --mca pml ^ucx --oversubscribe --prefix /mmfs1/perftest/ompi /mmfs1/perftest/lanl_ior/bin/ior -a POSIX -v -i 1 -d 3 -e -k -o /mmfs1/perftest/tst.file -r -s 1 -t 8m -b $ G
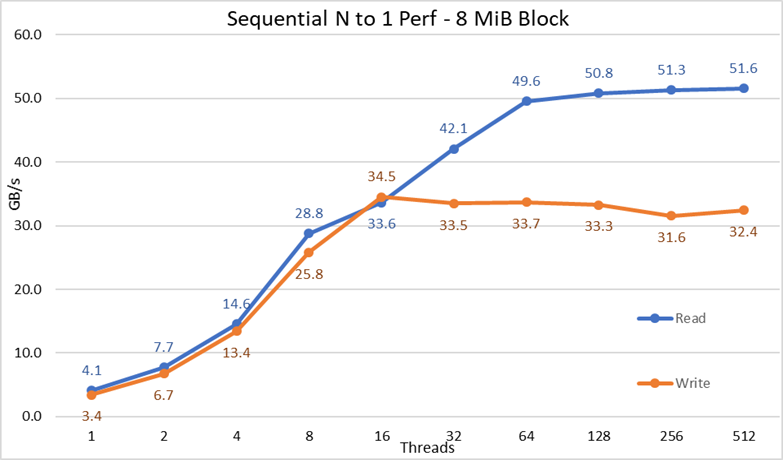
Bild 3 N till 1 Sekventiell prestanda
Från resultaten kan vi observera att läs- och skrivprestanda är hög oavsett det implicita behovet av låsningsmekanismer eftersom alla trådar har åtkomst till samma fil. Prestandan ökar igen mycket snabbt med antalet trådar som används och når sedan en platå som är relativt stabil för läsningar och skrivningar hela vägen till det maximala antalet trådar som används i det här testet. Observera att den maximala läsprestandan var 51,6 GB/s vid 512 trådar, men platån i prestanda nås vid cirka 64 trådar. Observera också att den maximala skrivprestandan på 34,5 GB/s uppnåddes vid 16 trådar och nådde en platå som kan observeras tills det maximala antalet trådar som används.
Slumpmässiga små block IOzone Performance N klienter till N filer
Prestanda för slumpmässiga N klienter till N-filer mättes med IOzone version 3.487. Testerna som utfördes varierade från en tråd upp till 1024 trådar i steg om två.
Testerna som utfördes varierade från en tråd upp till 512 trådar eftersom det inte fanns tillräckligt med klientkärnor för 1 024 trådar. Varje tråd använde en annan fil och trådarna tilldelades resursallokering på klientnoderna. I det här benchmark-testet användes 4 KiB-block för att emulera trafik med små block och använda ett ködjup på 16. Resultat från den stora lösningen och kapacitetsutbyggnaden jämförs.
Cachningseffekterna minimerades återigen genom att ställa in GPFS-sidpoolen som kunde ställas in på 16GiB och för att undvika eventuella datacachningseffekter från klienterna var den totala datastorleken på filerna dubbelt så stor som den totala mängden RAM-minne i klienterna som användes. Det vill säga, eftersom varje klient har 128 GiB RAM, för trådantal som är lika med eller över 16 trådar, var filstorleken 4096 GiB dividerat med antalet trådar (variabeln $Size nedan användes för att hantera det värdet). I de fall med mindre än 16 trådar (vilket innebär att varje tråd kördes på en annan klient) fastställdes filstorleken till dubbelt så mycket minne per klient eller 256 GiB.
iozone -i0 -I -c -e -w -r 8M -s $ G -t $Threads -+n -+m ./nvme_threadlist <= Skapa filerna sekventiellt
iozone -i2 -I -c -O -w -r 4k -s $ G -t $Threads -+n -+m ./nvme_threadlist <= Utför slumpmässiga läsningar och skrivningar.
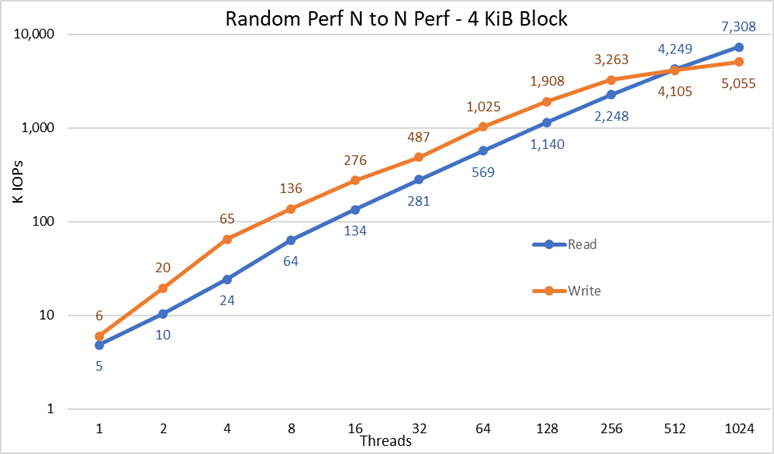
Bild 4 N till N Slumpmässig prestanda
Från resultaten kan vi se att skrivprestandan börjar vid ett högt värde på 6K IOps och stiger stadigt upp till 1024 trådar där det verkar nå en platå med över 5M IOPS om fler trådar kan användas. Läsprestanda å andra sidan börjar vid 5K IOPS och ökar prestandan stadigt med antalet trådar som används (tänk på att antalet trådar fördubblas för varje datapunkt) och når maximal prestanda på 7,3 M IOPS vid 1024 trådar utan tecken på att nå en platå. Om du använder fler trådar krävs mer än de 16 beräkningsnoderna för att undvika resurssvält och överdriven växling som kan sänka skenbar prestanda, där NVMe-noderna i själva verket skulle kunna upprätthålla prestandan.
Metadataprestanda med MDtest med 4 KiB-filer
Metadataprestanda mättes med MDtest version 3.3.0, med hjälp av OpenMPI v4.0.1 för att köra prestandatestet över de 16 beräkningsnoderna. Testerna som utfördes varierade från enkel tråd upp till 512 trådar. Prestandatestet användes endast för filer (inga katalogmetadata), för att hämta antalet skapanden, statistik, läsningar och borttagningar som lösningen kan hantera, och resultaten kontrasterades mot den stora lösningen.
Den valfria High Demand Metadata Module användes, men med en enda ME4024-array, även den stora konfigurationen och testad i detta arbete var avsedd att ha två ME4024s. Anledningen till att använda den metadatamodulen är att dessa NVMe-noder för närvarande endast används som lagringsmål för data. Noderna kan dock användas för att lagra data och metadata, eller till och med som ett flash-alternativ för den efterfrågade metadatamodulen, om extrema metadatakrav kräver det. Dessa konfigurationer testades inte som en del av detta arbete.
Eftersom samma High Demand Metadata-modul har använts för tidigare benchmarking av DellEMC Ready Solution för HPC PixStor-lagringslösningen kommer metadataresultaten att vara mycket lika jämfört med tidigare bloggresultat. Av den anledningen gjordes inte studien med tomma filer, utan istället användes 4 KiB-filer. Eftersom 4KiB-filer inte får plats i en inod tillsammans med metadatainformationen används NVMe-noder för att lagra data för varje fil. Därför kan MDtest ge en ungefärlig uppfattning om små filers prestanda för läsningar och resten av metadataåtgärderna.
Följande kommando användes för att köra prestandatestet, där $Threads var variabeln med antalet trådar som användes (1 till 512 ökat i potenser av två) och my_hosts.$Threads är motsvarande fil som allokerade varje tråd på en annan nod, med resursallokering för att sprida dem homogent över de 16 beräkningsnoderna. På samma sätt som med det slumpmässiga IO-riktmärket begränsades det maximala antalet trådar till 512, eftersom det inte finns tillräckligt med kärnor för 1024 trådar och kontextväxling skulle påverka resultatet och rapportera ett tal som är lägre än lösningens verkliga prestanda.
mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads --prefix /mmfs1/perftest/ompi --mca btl_openib_allow_ib 1 /mmfs1/perftest/lanl_ior/bin/mdtest -v -d /mmfs1/perftest/ -i 1 -b $Directories -z 1 -L -I 1024 -y -u -t -F -w 4K -e 4K
Eftersom prestandaresultaten kan påverkas av det totala antalet IOPS, antalet filer per katalog och antalet trådar, beslutades det att behålla det totala antalet filer till 2 MiB-filer (2^21 = 2097152), antalet filer per katalog som fastställts till 1024 och antalet kataloger varierade när antalet trådar ändrades enligt tabell 3.
Tabell 3 MDtest distribution av filer på kataloger
|
Antal trådar |
Antal kataloger per tråd |
Totalt antal filer |
|
1 |
2048 |
2,097,152 |
|
2 |
1024 |
2,097,152 |
|
4 |
512 |
2,097,152 |
|
8 |
256 |
2,097,152 |
|
16 |
128 |
2,097,152 |
|
32 |
64 |
2,097,152 |
|
64 |
32 |
2,097,152 |
|
128 |
16 |
2,097,152 |
|
256 |
8 |
2,097,152 |
|
512 |
4 |
2,097,152 |
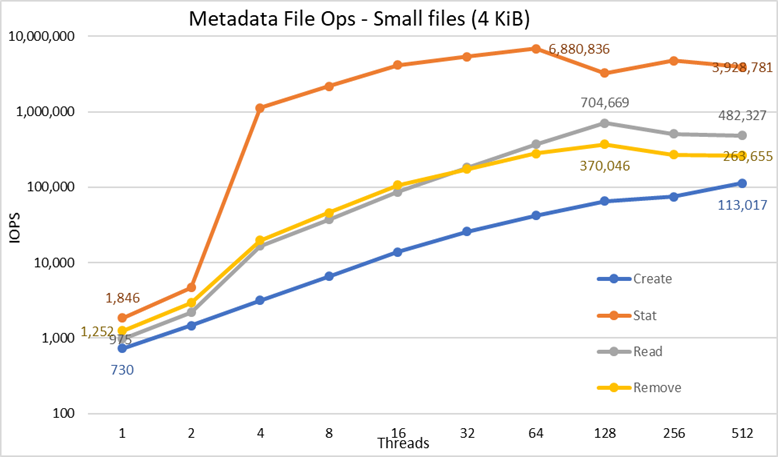
Bild 5 Metadataprestanda – 4 KiB-filer
Lägg först märke till att den valda skalan var logaritmisk med basen 10, för att möjliggöra jämförelse av operationer som har skillnader med flera storleksordningar; Annars skulle vissa av åtgärderna se ut som en platt linje nära 0 på en linjär skala. Ett logaritmiskt diagram med bas 2 kan vara lämpligare, eftersom antalet trådar ökas i potenser av 2, men grafen skulle se väldigt likadan ut och folk tenderar att hantera och komma ihåg bättre siffror baserat på potenser av 10.
Systemet får mycket bra resultat som tidigare rapporterats med Stat-operationer som når toppvärdet vid 64 trådar med nästan 6,9 M op/s och sedan reduceras för högre trådantal som når en platå. Skapandeåtgärder når maximalt 113 K op/s vid 512 trådar, så de förväntas fortsätta att öka om fler klientnoder (och kärnor) används. Reads and Removes-åtgärder uppnådde sitt maximum på 128 trådar, och nådde sin topp på nästan 705 K op/s för läsningar och 370 K op/s för borttagningar, och sedan når de platåer. Statistikoperationer har mer variabilitet, men när de når sitt toppvärde sjunker prestandan inte under 3,2 miljoner op/s för statistik. Skapa och ta bort är mer stabila när de når en platå och förblir över 265 K op/s för borttagning och 113 K op/s för Skapa. Slutligen når läsningar en platå med prestanda över 265 K op/s.
Slutsatser och framtida arbete
NVMe-noderna är ett viktigt tillägg till HPC-lagringslösningen eftersom de ger en nivå med mycket höga prestanda med god densitet, mycket hög prestanda för slumpmässig åtkomst och mycket hög sekventiell prestanda. Dessutom skalas lösningen ut linjärt i kapacitet och prestanda när fler NVMe-nodmoduler läggs till. Prestanda från NVMe-noderna kan ses i tabell 4, förväntas vara stabil och dessa värden kan användas för att uppskatta prestanda för ett annat antal NVMe-noder.
Tänk dock på att varje par NVMe-noder ger hälften av det tal som visas i tabell 4.
Den här lösningen ger HPC-kunder ett mycket tillförlitligt parallellt filsystem som används av många av de 500 främsta HPC-klustren. Dessutom ger den exceptionella sökfunktioner, avancerad övervakning och hantering, och genom att lägga till valfria gateways kan fildelning via allestädes närvarande standardprotokoll som NFS, SMB och andra till så många klienter som behövs.
Tabell 4: Toppprestanda och bibehållen prestanda för två par NVMe-noder
|
|
Prestanda i toppklass |
Bibehållen prestanda |
||
|
Skriva |
Läsa |
Skriva |
Läsa |
|
|
Stora sekventiella N-klienter till N-filer |
40,9 GB/s |
84,5 GB/s |
40 GB/s |
81 GB/s |
|
Stora sekventiella N-klienter till en enda delad fil |
34,5 GB/s |
51,6 GB/s |
31,5 GB/s |
50 GB/s |
|
Slumpmässiga små block N klienter till N filer |
5,06MIOPS |
7.31MIOPS |
5 MIOPS |
7.3 MIOPS |
|
Metadata Skapa 4KiB-filer |
113 K IOps |
113 K IOps |
||
|
Metadata Stat 4KiB-filer |
6,88 M IOps |
3,2 miljoner IOps |
||
|
Metadata Läsa 4KiB-filer |
705 K IOps |
500 K IOps |
||
|
Metadata: Ta bort 4KiB-filer |
370 K IOps |
265 K IOps |
||
Eftersom NVMe-noder endast användes för data kan möjligt framtida arbete inkludera användning av dem för data och metadata och ha en sluten flashbaserad nivå med bättre metadataprestanda på grund av NVMe-enheters högre bandbredd och lägre latens jämfört med SAS3 SSD-hårddiskar bakom RAID-styrenheter. Alternativt, om en kund har extremt höga metadatakrav och behöver en lösning som är mer kompakt än vad den efterfrågade metadatamodulen kan tillhandahålla, kan några eller alla distribuerade RAID 10-enheter användas för metadata på samma sätt som RAID 1-enheter på ME4024s används nu.
En annan blogg som snart kommer att släppas kommer att karakterisera PixStor Gateway-noderna, som gör det möjligt att ansluta PixStor-lösningen till andra nätverk med hjälp av NFS- eller SMB-protokoll och kan skala ut prestanda. Lösningen kommer också att uppdateras till HDR100 mycket snart, och en annan blogg förväntas prata om det arbetet.