PowerScale, Isilon OneFS: Isilon에서 HBase 성능 테스트(영문)
Summary: 이 문서에서는 YCSB(Yahoo Cloud Serving Benchmarking) 제품군 및 CDH(Cloudera Data Hub) 5.10을 사용하여 Isilon X410 클러스터에서 수행한 성능 벤치마킹 테스트를 설명합니다.
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Symptoms
필요 없음
Cause
필요 없음
Resolution
참고: 이 항목은 OneFS에서 Hadoop 사용 정보 허브의 일부입니다.
소개
일련의 성능 벤치마킹 테스트가 YCSB 벤치마킹 제품군과 CDH 5.10을 사용하여 Isilon X410 클러스터에서 수행되었습니다.
실습 테스트 환경은 OneFS v8.0.0.4 이상 v8.0.1.1을 실행하는 5개의 Isilon x410 노드로 구성되었습니다. NFS(Network File System) 대규모 블록 스트리밍 벤치마크가 실행되었습니다. 테스트에서 예상되는 이론적 최대 총 용량은 노드당 ~700MB/s(3.5GB/s) 쓰기 및 ~1GB/s(5GB/s) 읽기였습니다.
(9) 컴퓨팅 노드는 각각 2x18C/36T-인텔 제온® CPU E5-2697 v4 @ 2.30GHz와 512GB RAM으로 구성된 CentOS v7.3.1611을 실행하는 Dell PowerEdge FC630 서버입니다. 로컬 스토리지는 운영 체제와 스크래치 공간 또는 유출 파일 모두에 대해 XFS로 포맷된 RAID 1의 2xSSD입니다.
또한 YCSB 로드를 구동하는 데 사용된 3개의 추가 엣지 서버도 있었습니다.
컴퓨팅 노드와 Isilon 간의 백엔드 네트워크는 10Gbps이며 NIC 및 스위치 포트에 점보 프레임이 설정(MTU=9162)됩니다.
Hadoop 테스트 구성의 구성 요소(그림 1)
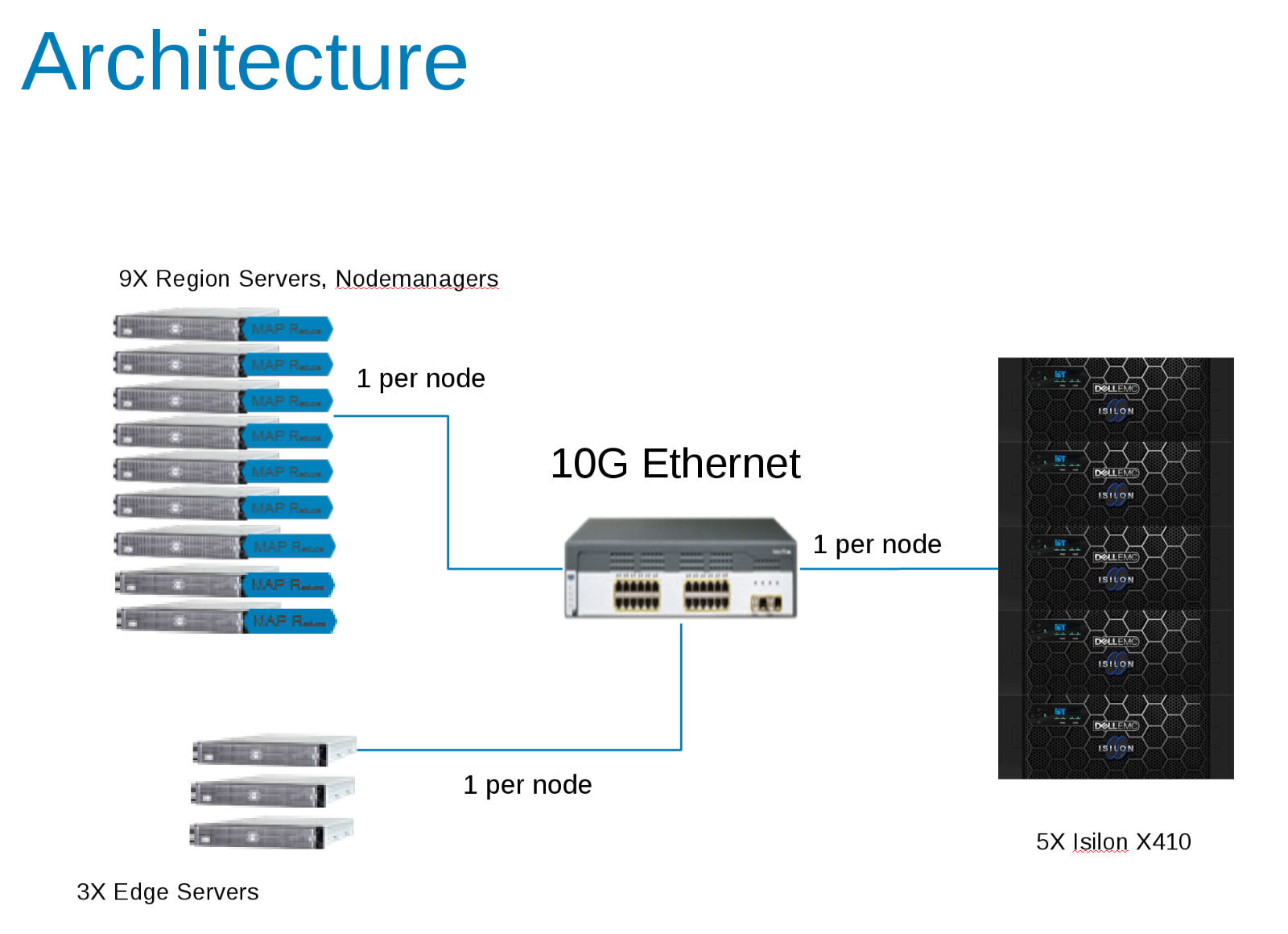
CDH 5.10은 Isilon Cluster의 액세스 존에서 실행되도록 구성되었습니다. 서비스 계정은 Isilon Local 공급업체와 클라이언트 /etc/passwd 파일에서 로컬로 생성되었습니다. 모든 테스트는 특별한 권한 없이 기본 테스트 클라이언트를 사용하여 실행되었습니다.
Isilon 통계는 IIQ 및 Grafana/Data Insights 패키지로 모니터링되었습니다. CDH 통계는 Cloudera Manager와 Grafana를 사용하여 모니터링했습니다.
초기 테스트
처음 일련의 테스트는 HBASE 쪽에서 전체 출력에 영향을 미치는 관련 매개 변수를 확인하는 것이었습니다. YCSB 도구는 HBASE에 대한 부하를 생성하는 데 사용되었습니다. 이 초기 테스트는 YCSB 및 4천만 개 행의 '로드' 단계를 사용하여 단일 클라이언트(에지 서버)를 사용하여 실행되었습니다. 이 테이블은 각 실행 전에 삭제되었습니다.
ycsb load hbase10 -P workloads/workloada1 -p table='ycsb_40Mtable_nr' -p columnfamily=family -threads 256 -p recordcount=40000000
- hbase.regionserver.maxlogs - 최대 WAL(Write-Ahead Log) 파일 수 - 이 값에 HDFS 블록 크기(dfs.blocksize)를 곱한 값은 서버가 충돌할 때 재생해야 하는 WAL의 크기입니다. 이 값은 디스크 플러시 빈도에 반비례합니다.
- hbase.wal.regiongrouping.numgroups - 다중 HDFS WAL을 WALProvider로 사용할 때 각 RegionServer가 실행해야 하는 미리 쓰기 로그 수를 설정합니다. 결과에 HDFS 파이프라인 수가 표시됩니다. 지정된 지역에 대한 쓰기는 단일 파이프라인으로만 이동하여 총 RegionServer 부하를 분산합니다.
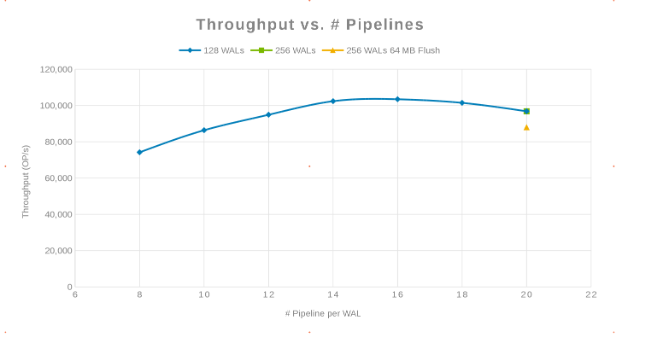
파이프라인 수와 처리량 비교(그림 2)
파이프라인 수와 레이턴시 비교(그림 3)
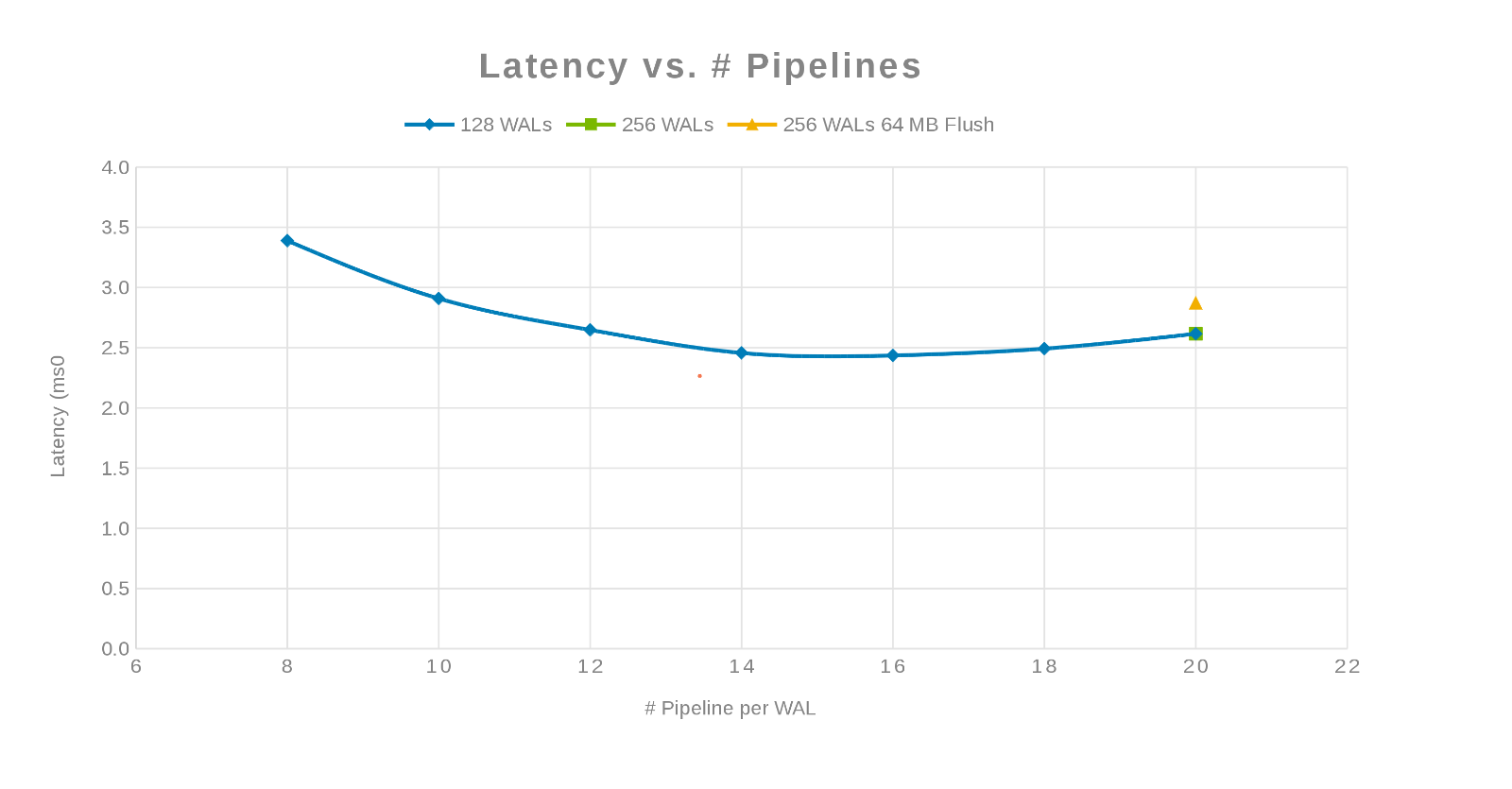
여기서 철학은 가능한 한 많은 쓰기를 병렬화하는 것이 었습니다. WAL의 수를 늘린 다음 WAL당 스레드(파이프라인)의 수를 늘리면 이 작업이 수행됩니다. 앞의 두 차트는 'maxlogs'에 대해 주어진 숫자 128 또는 256에 대해 실제 변화가 표시되지 않음을 보여줍니다. 이는 테스트가 클라이언트 측의 결과에 실제로 영향을 미치지 않음을 나타냅니다. 파일당 '파이프라인'의 수는 다양하여 병렬화에 민감한 매개 변수를 나타내는 추세를 보여주었습니다. 다음 질문은 Isilon 클러스터가 디스크 I/O, 네트워크, CPU 또는 OneFS에서 "방해가 되는" 부분입니다. 이 질문에 대한 답을 찾기 위해 Isilon 통계 보고서를 살펴보십시오.
테스트 중 Isilon 네트워크 활용도 및 로드(그림 4)
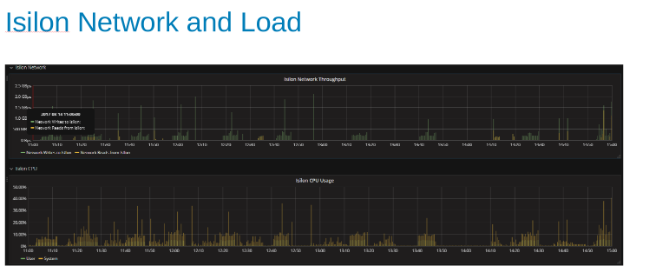
네트워크 및 CPU 그래프를 보면 Isilon 클러스터의 활용도가 낮고 더 많은 작업을 할 수 있는 여지가 있음을 알 수 있습니다. CPU는 80%이고 > 네트워크 대역폭은 3GB/s 이상입니다.
HDFS 프로토콜 부하 상태에서 HDFS 프로토콜 통계 및 CPU 사용률의 플롯(그림 5)
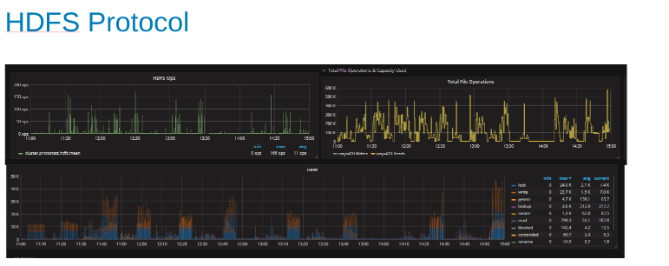
이 그림은 HDFS 프로토콜 통계와 OneFS가 출력을 변환하는 방법을 보여줍니다. HDFS 연산은 dfs.blocksize의 배수이며 여기서는 256MB입니다. 여기서 흥미로운 점은 heat 그래프에 OneFS 파일 작업이 표시되고 쓰기와 잠금의 상관 관계가 표시된다는 것입니다. 이 경우 HBase는 WAL에 추가를 수행하므로 OneFS는 추가되는 각 쓰기에 대해 WAL 파일을 잠급니다. 이는 클러스터 파일 시스템에서 안정적인 쓰기가 필요합니다. 이것들은 이 테스트 세트의 제한 요인에 기여하는 것으로 보입니다.
HBase 업데이트
이 다음 테스트는 대규모로 어떤 일이 일어나는지 찾기 위해 더 많은 실험을 하는 것이었습니다. 생성하는 데 한 시간이 걸린 10억 행 테이블이 만들어집니다. 'workloada' 설정(50/50 읽기/쓰기)을 사용하여 1,000만 개의 행을 업데이트하는 YCSB 테스트가 실행됩니다. 이 테스트는 단일 클라이언트에서 실행되었습니다. 테스트는 가장 많은 처리량을 생성할 수 있도록 YCSB 스레드 수의 함수로 실행되었습니다. 또한 일부 조정이 적용되어 OneFS가 데이터 노드 서비스의 성능을 조정한 v8.0.1.1로 업그레이드되었습니다. 다음 차트는 이전 실행 집합과 비교한 성능 향상을 보여 줍니다. 이러한 실행의 경우 hbase.regionserver.maxlogs는 256으로 설정되고 hbase.wal.regiongrouping.numgroups는 20으로 설정됩니다.
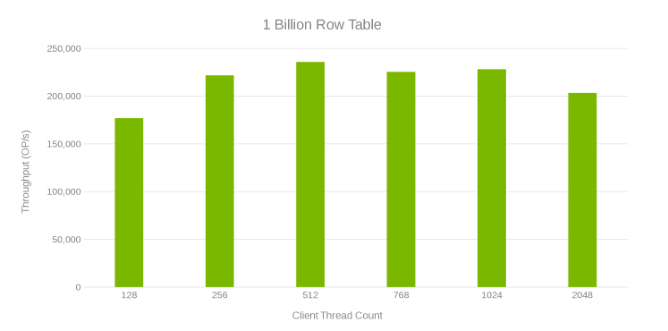
10억 개 행 테이블을 업데이트하는 동안의 처리량 및 스레드 수(그림 6)
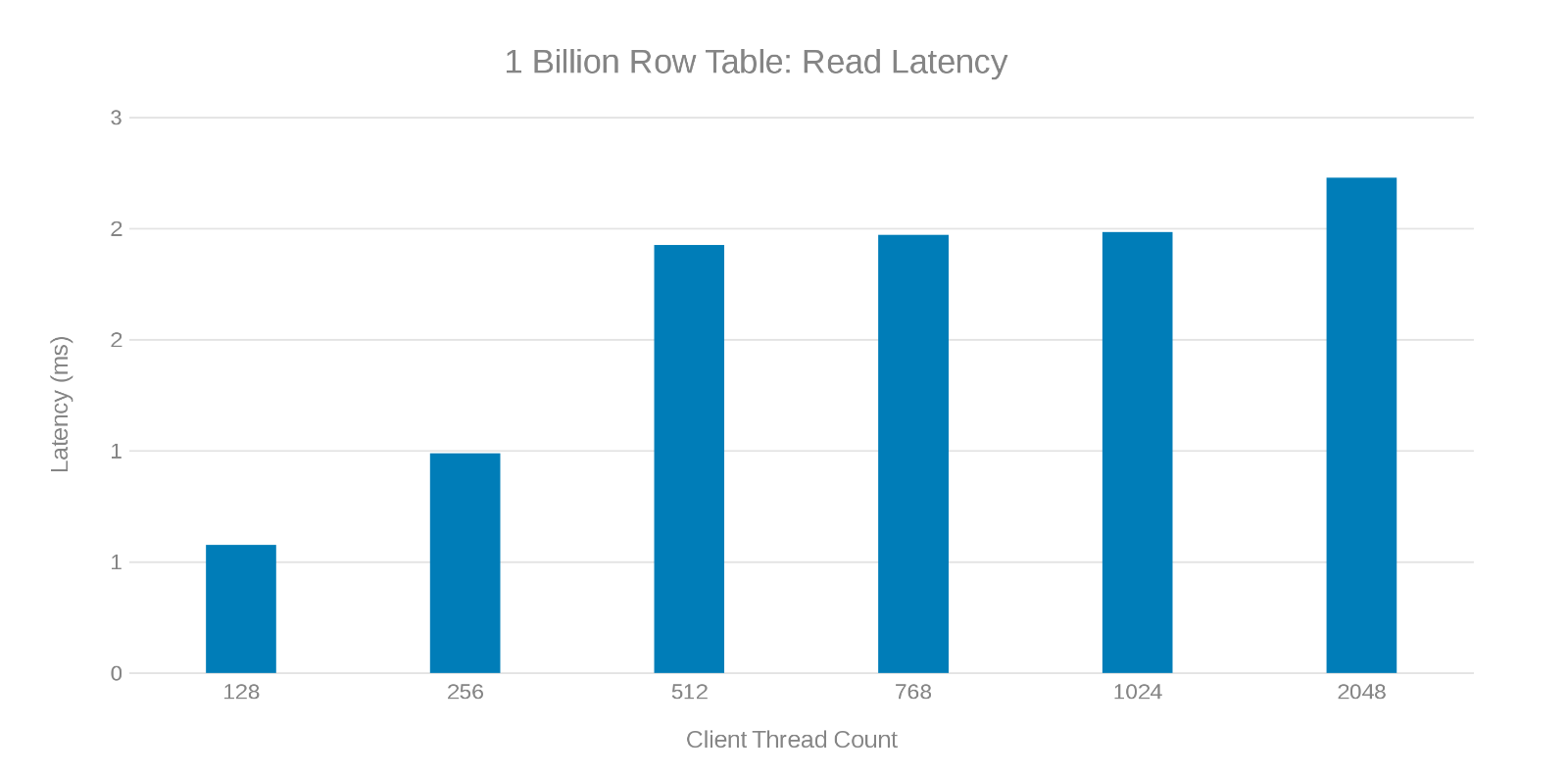
10억 개의 행 테이블을 업데이트하는 동안 읽기 대기 시간(그림 7)
10억 개 행 테이블을 업데이트하는 동안 업데이트 대기 시간(그림 8)
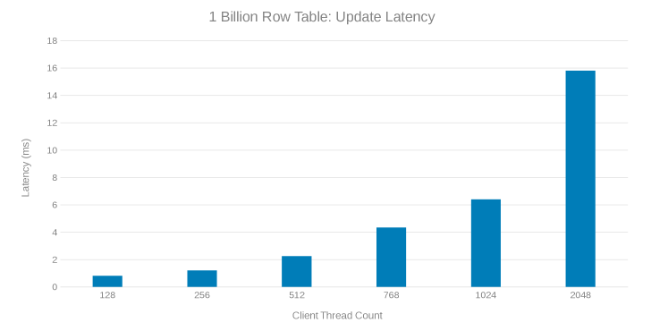
이러한 테스트 실행을 검토하면 스레드 수가 많을 때 성능 저하가 뚜렷하게 나타납니다. 이는 Isilon 또는 클라이언트 측 문제일 수 있습니다. 테스트 결과 3ms의 < 업데이트 대기 시간에서 초당 200,000개의 작업이 수행되는 것으로 나타났습니다. 각 업데이트 테스트 실행은 빠르며 연속적으로 실행할 수 있었습니다. 아래 그래프는 각 테스트 실행에 대한 Isilon 노드 간의 균등한 균형을 보여줍니다.
Isilon Cluster의 각 노드에서 워크로드를 나타내는 히트 그래프(그림 9)
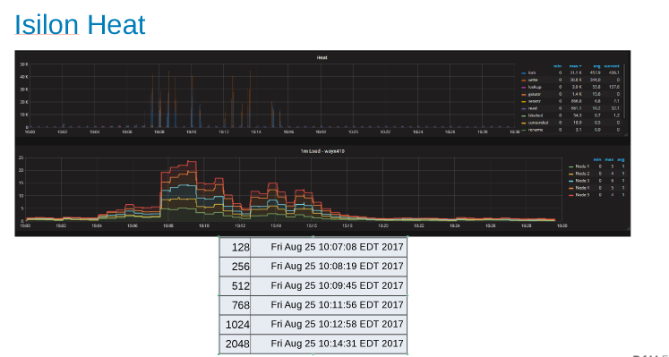
히트 그래프는 파일 작업이 WAL 프로세스의 추가 특성에 해당하는 쓰기 및 잠금임을 보여줍니다.
지역 서버 확장
다음 테스트는 Isilon 노드(5개 노드)가 서로 다른 수의 리전 서버에 대해 어떻게 작동하는지 확인하는 것이었습니다. 이전 테스트에서 실행된 것과 동일한 업데이트 스크립트가 10억 행 테이블과 'workloada'를 사용한 1,000만 행 업데이트를 포함하여 실행되었습니다. 테스트에서는 YCSB 스레드가 51로 설정된 단일 클라이언트를 사용했습니다. maxlogs 및 파이프라인에 대해 동일한 설정이 적용됩니다(각각 256 및 20).
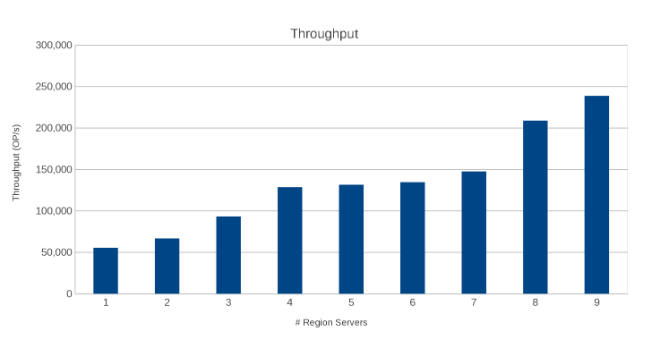
리전 서버 전체의 처리량(그림 10)
리전 서버 간 대기 시간(그림 11)
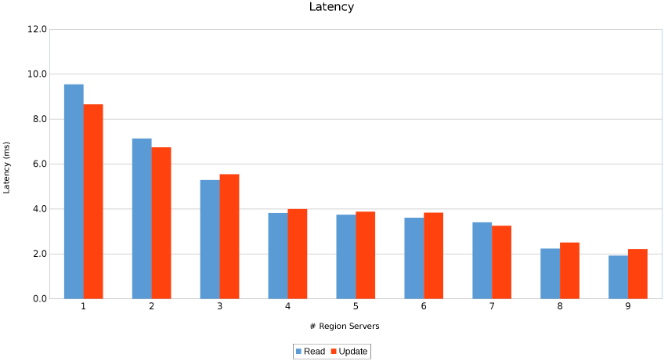
결과는 놀랍지는 않지만 유익합니다. HBase의 스케일 아웃 특성과 Isilon의 스케일 아웃 특성을 고려했을 때 많을수록 좋습니다. 이 테스트는 클라이언트가 자체 사이징 연습의 일부로 환경에서 실행하는 것이 좋습니다. 여기에는 5개의 Isilon 노드를 푸시하는 9개의 서버가 있으며 수익이 감소하는 지점에 도달하기 전에 더 많은 여지가 있는 것으로 보입니다.
더 많은 클라이언트
마지막 일련의 테스트에서는 하드웨어 구성의 한계를 테스트했습니다. 이는 테스트 중인 매개변수의 상한을 결정하기 위해 수행되었습니다. 이 일련의 테스트에서는 클라이언트를 실행하는 데 두 개의 추가 서버가 사용됩니다. 또한 각 서버에서 2개의 YCSB 클라이언트가 실행되어 각각 최대 6개의 클라이언트를 허용합니다. 각 클라이언트는 512개의 스레드를 구동하여 전체 4096개의 스레드를 생성했습니다. 두 개의 서로 다른 테이블이 생성되었습니다. 40억 개의 행이 있는 한 테이블은 600개의 영역으로 분할되고 다른 테이블은 4억 개의 행이 90개 영역으로 분할됩니다.
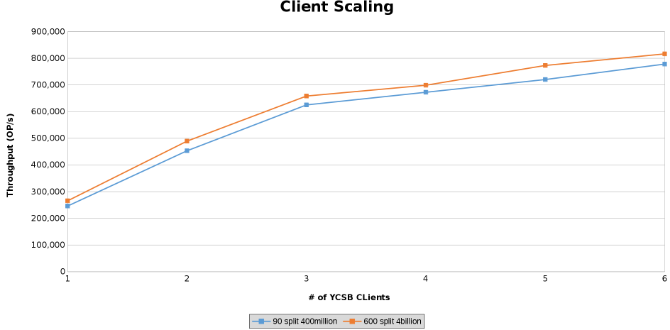
이 그래프는 Client Scaling을 테스트하는 동안의 작업 처리량을 그래프로 나타냅니다(그림 12).
클라이언트 스케일링을 테스트하는 동안의 읽기 레이턴시 측정(그림 13)

클라이언트 확장을 테스트하는 동안 업데이트 레이턴시 측정(그림 14)
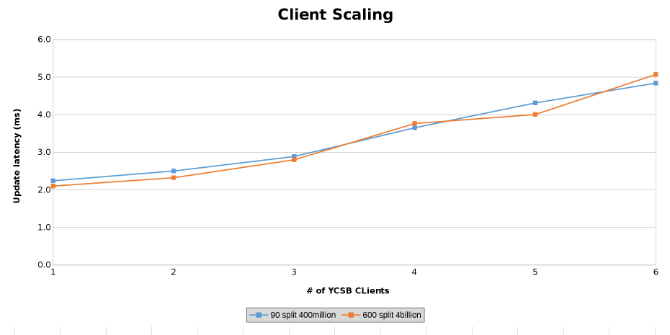
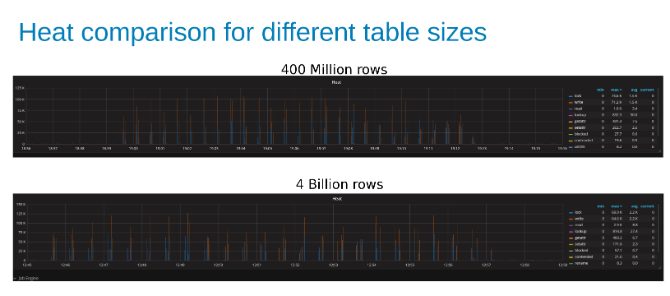
아래 그래프는 이 테스트에서 테이블의 크기가 별로 중요하지 않다는 것을 보여줍니다. Isilon Heat 차트를 보면 파일 작업 수에 약간의 백분율 차이가 있음을 다시 확인할 수 있습니다. 대부분의 차이는 40억 행 테이블과 4억 행 테이블의 차이와 인라인으로 정렬되었습니다.
4억 행 테이블과 4억 행 테이블을 업데이트하는 동안의 Isilon 워크로드 히트 비교( 그림 15)
결론
HBase는 주로 스케일 아웃 아키텍처에서 스케일 아웃할 수 있기 때문에 Isilon에서 실행하기에 적합한 후보입니다. HBase는 많은 자체 캐싱을 수행하며 많은 수의 지역으로 테이블을 분할하여 HBase는 데이터를 사용하여 스케일 아웃할 수 있습니다. 즉, 자체 요구 사항을 잘 처리하고 파일 시스템은 애플리케이션 회복탄력성을 위해 존재한다. 테스트는 물건을 부수는 지점까지 하중을 밀어 넣을 수 없었습니다. HBase가 대기 시간이 3ms 미만인 800,000개 작업을 위해 설계된 경우 이 아키텍처는 이를 지원합니다. HBase는 클라이언트 측과 HBase 자체 모두에 대해 수많은 성능 조정 및 조정을 지원합니다. 이러한 모든 조정 및 조정에 대한 테스트는 이 테스트의 범위를 벗어났습니다.Affected Products
Isilon, PowerScale OneFSArticle Properties
Article Number: 000128942
Article Type: Solution
Last Modified: 11 Mar 2026
Version: 7
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.