Код події Openshift: 1030NODE0001
Summary: При тривалому високому завантаженні процесора на одному вузлі керуючої площини більший тиск CPU, ймовірно, спричинить аварійне перемикання; збільшити доступний процесор.
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Symptoms
Екстремальний тиск на процесор може спричинити повільну серіалізацію та низьку продуктивність kube-apiserver та etcd. Коли це трапляється, існує ризик, що клієнти бачать невідповідні API-запити, які знову надсилаються,
що створює ще більший тиск на процесор.Це також може спричиняти відмови у живих зондах через повільну чутливість etcd на бекенді. Якщо один kube-apiserver виходить з ладу за цієї умови, ймовірно, ви зіткнетеся з каскадом, оскільки решта kube-apiservers також недостатньо налаштовані.
що створює ще більший тиск на процесор.Це також може спричиняти відмови у живих зондах через повільну чутливість etcd на бекенді. Якщо один kube-apiserver виходить з ладу за цієї умови, ймовірно, ви зіткнетеся з каскадом, оскільки решта kube-apiservers також недостатньо налаштовані.
Cause
Це сповіщення спрацьовує, коли на одному вузлі керуючої площини спостерігається стійке високе навантаження процесора.
Терміновість цього сповіщення визначається тим, як довго вузол підтримує високе навантаження процесора:
.Терміновість цього сповіщення визначається тим, наскільки довго завантаження процесора на всіх трьох вузлах керуючої площини перевищує витривалість двох вузлів керуючої площини.
Терміновість цього сповіщення визначається тим, як довго вузол підтримує високе навантаження процесора:
- Критично
- коли використання процесора на окремому вузлі керуючої площини перевищує 90% понад 1 годину.
- Увага
- коли використання процесора на окремому вузлі керуючої площини перевищує 90% для понад 5 м.
.Терміновість цього сповіщення визначається тим, наскільки довго завантаження процесора на всіх трьох вузлах керуючої площини перевищує витривалість двох вузлів керуючої площини.
- Увага
- коли завантаження процесора на всіх трьох вузлах керуючої площини перевищує, ніж два вузли керуючої площини можуть підтримувати понад 10 м.
Resolution
Діагноз:
Виконайте наступні запити PromQL на веб-консолі OCP для допомоги в діагностиці (Спостерігати → метрики → Запускати запити).Топ-5 контейнерів із найбільшим завантаженням процесора на певному вузлі:
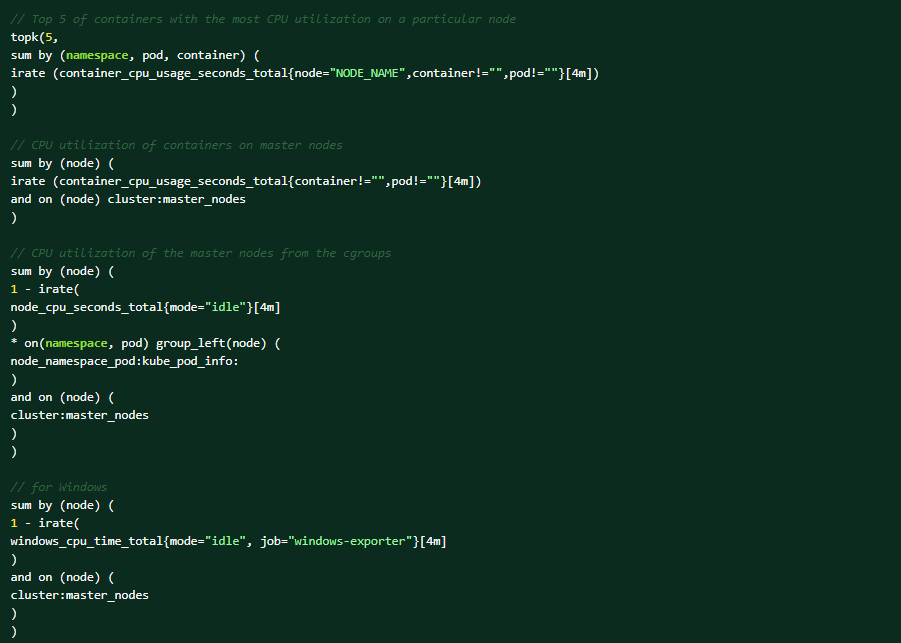
Ось умови, які можуть спричинити попередження:
- з'явилося нове навантаження, яке генерує більше викликів до APISERVER і призводить до високого навантаження процесора. У такому випадку збільште потужність процесора та пам'яті на вузлах керуючої площини.
- сповіщення спрацьовується на основі метрик вузла, тож можливо, що компонент на вузлі спричиняє високе навантаження процесора.
- APISERVER/ETCD обробляє більше запитів через повторні спроби клієнта, спричинені прихованою проблемою.
- нерівномірний розподіл запитів до екземплярів APISERVER через HTTP2 (він мультиплексує запити через одне TCP-з'єднання). Балансувальники навантаження не знаходяться на рівні додатків і тому не розуміють http2.
Пом'якшення наслідків:
- Якщо навантаження створює навантаження на APISERVER, що спричиняє високе навантаження процесора, збільште CPU та пам'ять на вузлах керуючої площини.
- Якщо тривале високе навантаження процесора зумовлене деградацією кластера:
- Визначте корінну причину деградації і визначте подальші кроки відповідно.
Підтримка:
Якщо всі вищезазначені кроки не допоможуть вирішити проблему, зверніться до технічної підтримки Dell EMC для подальшого розслідування.
Additional Information
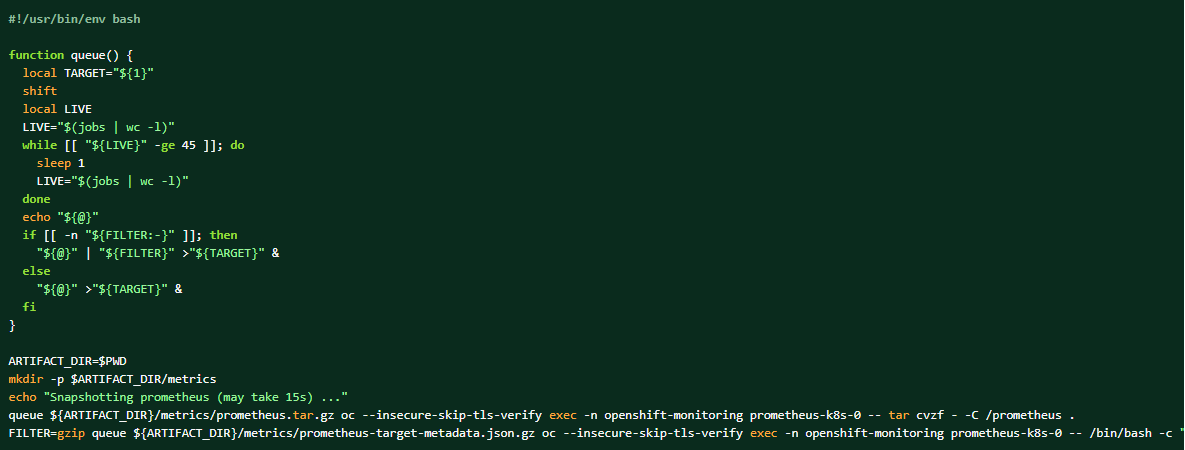
Якщо зібрати логарифмічний пучок, дані Прометея також можуть бути скинуті як комплементарні матеріали.
Як взяти дамп даних кластера Prometheus:
Affected Products
APEX Cloud Platform for Red Hat OpenShiftArticle Properties
Article Number: 000217405
Article Type: Solution
Last Modified: 13 Feb 2026
Version: 3
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.