Dell EMC Ready oplossing voor HPC PixStor-storage - NVMe-klasse (in het Engels)
Summary: Blog voor een HPC-storageoplossingscomponent, inclusief architectuur en prestatie-evaluatie.
Symptoms
Blog voor een HPC-storageoplossingscomponent, inclusief architectuur en prestatie-evaluatie.
Resolution
Dell EMC Ready oplossing voor HPC PixStor-storage (in het Engels)
NVMe-laag
Inhoudsopgave
Karakterisering van prestaties
Sequentiële IOzone-prestaties N-clients naar N-bestanden
Sequentiële IOR Performance N-clients naar 1 bestand
Willekeurige kleine blokken IOzone Performance N clients naar N bestanden
Metadataprestaties met MDtest met behulp van 4 KiB-bestanden
Conclusies en toekomstige werkzaamheden
Inleiding
De huidige HPC-omgevingen hebben hogere eisen voor zeer snelle storage en met het hogere aantal CPU's, snellere netwerken en meer geheugen werd storage de bottleneck in veel workloads. Deze veeleisende HPC-vereisten worden doorgaans gedekt door parallelle bestandssystemen (PFS) die gelijktijdige toegang bieden tot één bestand of een set bestanden van meerdere knooppunten, waardoor data zeer efficiënt en veilig worden gedistribueerd naar meerdere LUN's over verschillende servers. Deze bestandssystemen zijn normaal gesproken gebaseerd op draaiende media om de hoogste capaciteit tegen de laagste kosten te bieden. Steeds vaker kunnen de snelheid en latentie van draaiende media echter niet voldoen aan de eisen van veel moderne HPC-workloads, waardoor het gebruik van flash-technologie nodig is in de vorm van burst-buffers, snellere lagen of zelfs zeer snelle scratch, lokaal of gedistribueerd. De DellEMC Ready oplossing voor HPC PixStor storagemaakt gebruik van NVMe-knooppunten als onderdeel om dergelijke nieuwe hoge bandbreedtevereisten te dekken en is daarnaast flexibel, schaalbaar, efficiënt en betrouwbaar.
Oplossingsarchitectuur
Deze blog maakt deel uit van een serie over PFS-oplossingen (Parallel File System) voor HPC-omgevingen, in het bijzonder voor de DellEMC Ready Solution voor HPC PixStor Storage, waar DellEMC PowerEdge R640-servers met NVMe-schijven worden gebruikt als een op snelle flash gebaseerde laag.
De PixStor PFS-oplossing omvat het wijdverbreide General Parallel File System, ook wel bekend als Spectrum Scale. ArcaStream bevat ook vele andere softwarecomponenten voor geavanceerde analyses, vereenvoudigd beheer en bewaking, efficiënt zoeken naar bestanden, geavanceerde gatewaymogelijkheden en meer.
De NVMe-knooppunten die in deze blog worden gepresenteerd, bieden een zeer krachtige op flash gebaseerde laag voor de PixStor-oplossing. Prestaties en capaciteit voor deze NVMe-laag kunnen worden opgeschaald door extra NVMe-knooppunten. Hogere capaciteit wordt geboden door de juiste NVMe-apparaten te selecteren die worden ondersteund in de PowerEdge R640.
Afbeelding 1 toont de referentiearchitectuur met een oplossing met 4 NVMe-knooppunten die gebruik maken van de veeleisende metadatamodule, die alle metadata in de geteste configuratie verwerkt. De reden hiervoor is dat deze NVMe-knooppunten momenteel worden gebruikt als storagedoelen voor alleen data. De NVMe-knooppunten kunnen echter ook worden gebruikt om gegevens en metadata op te slaan, of zelfs als een sneller flash-alternatief voor de veelgevraagde metadatamodule, als extreme metadata-eisen daarom vragen. Deze configuraties voor de NVMe-knooppunten zijn niet getest als onderdeel van deze werkzaamheden, maar zullen in de toekomst worden getest.
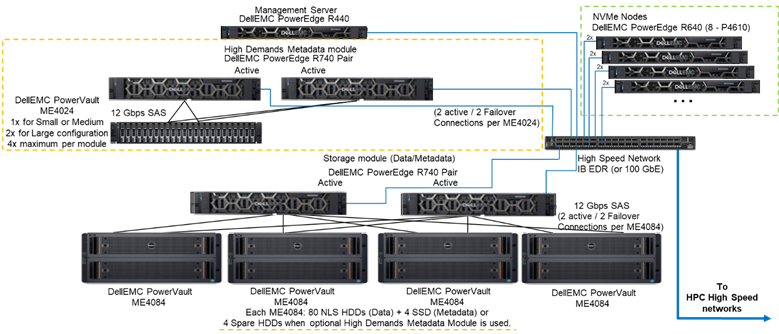
Afbeelding 1 Referentiearchitectuur
Onderdelen van de oplossing
Deze oplossing maakt gebruik van de nieuwste Intel Xeon2e generatie schaalbare Xeon CPU's, ook wel Cascade Lake CPU's genoemd en het snelste RAM-geheugen dat beschikbaar is (2933 MT/s), met uitzondering van de beheerknooppunten om ze rendabel te houden. Daarnaast is de oplossing bijgewerkt naar de nieuwste versie van PixStor (5.1.3.1) die RHEL 7.7 en OFED 5.0 ondersteunt. Dit zijn de ondersteunde softwareversies op het moment van uitgave.
Elk NVMe-knooppunt heeft acht Dell P4610-apparaten die zijn geconfigureerd als acht RAID 10-apparaten op twee servers, met behulp van een NVMe over Fabric-oplossing om dataredundantie mogelijk te maken, niet alleen op apparaatniveau, maar ook op serverniveau. Wanneer data in of uit een van deze RAID10-apparaten gaan, worden bovendien alle 16 schijven in beide servers gebruikt, waardoor de bandbreedte van de toegang tot die van alle schijven toeneemt. Daarom is de enige beperking voor deze componenten dat ze in paren moeten worden verkocht en gebruikt. Alle NVMe-schijven die door de PowerEdge R640 worden ondersteund, kunnen in deze oplossing worden gebruikt, maar de P4610 heeft een sequentiële bandbreedte van 3200 MB/s voor zowel lees- als schrijfbewerkingen, evenals hoge willekeurige IOPS-specificaties. Dit zijn leuke functies bij het schalen van het aantal paren dat nodig is om aan de vereisten van dit flash-niveau te voldoen.
Elke R640-server heeft twee HCA's, Mellanox ConnectX-6 Single Port VPI HDR100 die worden gebruikt als EDR 100 Gb IB-verbindingen. De NVMe-knooppunten zijn echter klaar om HDR100-snelheden te ondersteunen bij gebruik met HDR-kabels en -switches. Het testen van HDR100 op deze knooppunten is uitgesteld als onderdeel van de HDR100-update voor de hele PixStor-oplossing. Beide CX6-interfaces worden gebruikt voor het synchroniseren van data voor de RAID 10 (NVMe over fabric) en als connectiviteit voor het bestandssysteem. Bovendien bieden ze hardwareredundantie bij de adapter, poort en kabel. Voor redundantie op switchniveau zijn CX6 VPI-adapters met twee poorten vereist, maar deze moeten worden aangeschaft als S&P-componenten.
Om de prestaties van NVMe-knooppunten te karakteriseren, werden van het systeem in afbeelding 1 alleen de veelgevraagde metadatamodule en de NVMe-knooppunten gebruikt.
Tabel 1 bevat de lijst met de belangrijkste componenten voor de oplossing. Uit de lijst met schijven die worden ondersteund in de ME4024, werden 960 Gb SSD's gebruikt voor metadata. Dit waren de schijven die werden gebruikt voor prestatiekarakterisering. Snellere schijven kunnen betere willekeurige IOP's bieden en de bewerkingen voor het maken/verwijderen van metagegevens verbeteren. Alle NVMe-apparaten die op de PowerEdge R640 worden ondersteund, worden ondersteund voor de NVMe-knooppunten.
Tabel 1 Componenten die bij de vrijgave moeten worden gebruikt en componenten die in de testbank worden gebruikt
|
Bij vrijgave |
||
|
Interne connectiviteit |
Dell Networking S3048-ON Gigabit Ethernet |
|
|
Subsysteem voor datastorage |
1x tot 4x Dell EMC PowerVault ME4084 1x tot 4x Dell EMC PowerVault ME484 (één per ME4084) |
|
|
Optioneel veeleisend subsysteem voor metadatastorage |
1x tot 2x Dell EMC PowerVault ME4024 (4x ME4024 indien nodig, alleen grote configuratie) |
|
|
RAID-storagecontrollers |
12 Gbps SAS |
|
|
Processor |
NVMe-knooppunten |
2 x Intel Xeon Gold 6230 2,1 G, 20 C/40 T |
|
Veeleisende metadata |
||
|
Storageknooppunt |
||
|
Beheerknooppunt |
2 x Intel Xeon Gold 5220 2,2 G, 18 C/36 T |
|
|
Geheugen |
NVMe-knooppunten |
12 x 16 GiB 2933 MT/s RDIMM's (192 GiB) |
|
Veeleisende metadata |
||
|
Storageknooppunt |
||
|
Beheerknooppunt |
12 x 16 GB DIMM's, 2666 MT/s (192 GiB) |
|
|
Besturingssysteem |
CentOS 7.7 |
|
|
Kernelversie |
3.10.0-1062.12.1.el7.x86_64 |
|
|
PixStor-software |
5.1.3.1 |
|
|
Bestandssysteemsoftware |
Spectrumschaal (GPFS) 5.0.4-3 met NVMesh 2.0.1 |
|
|
Krachtige netwerkconnectiviteit |
NVMe-knooppunten: 2 x ConnectX-6 InfiniBand met EDR/100 GbE |
|
|
High-performance switch |
2x Mellanox SB7800 |
|
|
OFED-versie |
Mellanox OFED 5.0-2.1.8.0 |
|
|
Lokale schijven (besturingssysteem en analyse/bewaking) |
Alle servers behalve de vermelde NVMe-knooppunten 3 x 480 GB SSD SAS3 (RAID1 + HS) voor besturingssysteem3 x 480 GB SSD SAS3 (RAID1 + HS) voor besturingssysteem PERC H730P RAID-controller PERC H740P RAID-controller Beheerknooppunt 3 x 480 GB SSD SAS3 (RAID1 + HS) voor besturingssysteem met PERC H740P RAID-controller |
|
|
Systeembeheer |
iDRAC 9 Enterprise + DellEMC OpenManage |
|
Karakterisering van prestaties
Om dit nieuwe Ready Solution-onderdeel te karakteriseren, zijn de volgende benchmarks gebruikt:
·IOzone N naar N sequentieel
·IOR N naar 1 sequentieel
·IOzone willekeurig
·MDtest
Voor alle hierboven genoemde benchmarks had de testbank de clients zoals beschreven in tabel 2 hieronder. Aangezien het aantal rekenknooppunten dat beschikbaar was voor testen slechts 16 was, werden die threads gelijk verdeeld over de rekenknooppunten wanneer een hoger aantal threads nodig was (d.w.z. 32 threads = 2 threads per knooppunt, 64 threads = 4 threads per knooppunt, 128 threads = 8 threads per knooppunt, 256 threads = 16 threads per knooppunt, 512 threads = 32 threads per knooppunt, 1024 threads = 64 threads per knooppunt). De bedoeling was om een groter aantal gelijktijdige clients te simuleren met het beperkte aantal beschikbare rekenknooppunten. Aangezien sommige benchmarks een groot aantal threads ondersteunen, werd een maximale waarde van maximaal 1024 gebruikt (gespecificeerd voor elke test), terwijl overmatig schakelen tussen contexten en andere gerelateerde bijwerkingen van invloed op de prestatieresultaten werd vermeden.
Tabel 2 Testbank voor clients
|
Aantal clientknooppunten |
16 |
|
Clientknooppunt |
C6320 |
|
Processoren per clientknooppunt |
2 x Intel(R) Xeon(R) Gold E5-2697v4 18 cores @ 2,30 GHz |
|
Geheugen per clientknooppunt |
8 x 16 GiB 2400 MT/s RDIMM's (128 GiB) |
|
BIOS |
2.8.0 |
|
Kernel van besturingssysteem |
3.10.0-957.10.1 |
|
Bestandssysteemsoftware |
Spectrumschaal (GPFS) 5.0.4-3 met NVMesh 2.0.1 |
Sequentiële IOzone-prestaties N-clients naar N-bestanden
De prestaties van sequentiële N-clients naar N-bestanden werden gemeten met IOzone versie 3.487. De uitgevoerde tests varieerden van enkele thread tot 1024 threads in stappen van machten van twee.
Caching-effecten op de servers werden geminimaliseerd door de GPFS-paginapool afstembaar in te stellen op 16GiB en bestanden te gebruiken die groter waren dan twee keer zo groot. Het is belangrijk op te merken dat voor GPFS die afstembaarheid de maximale hoeveelheid geheugen instelt die wordt gebruikt voor het cachen van gegevens, ongeacht de hoeveelheid geïnstalleerd en vrij RAM-geheugen. Belangrijk om op te merken is ook dat, hoewel in eerdere DellEMC HPC-oplossingen de blokgrootte voor grote sequentiële overdrachten 1 MiB is, GPFS was geformatteerd met 8 MiB-blokken en daarom wordt die waarde gebruikt op de benchmark voor optimale prestaties. Dat lijkt misschien te groot en verspilt blijkbaar te veel ruimte, maar GPFS gebruikt subblock-toewijzing om die situatie te voorkomen. In de huidige configuratie was elk blok onderverdeeld in 256 subblokken van elk 32 KiB.
De volgende opdrachten werden gebruikt om de benchmark voor schrijf- en leesbewerkingen uit te voeren, waarbij $Threads de variabele was met het aantal gebruikte threads (1 tot 1024 verhoogd in machten van twee), en threadlist het bestand was dat elke thread op een ander knooppunt toewees, met behulp van round robin om ze homogeen over de 16 rekenknooppunten te verdelen.
Om mogelijke data-caching-effecten van de clients te voorkomen, was de totale datagrootte van de bestanden twee keer de totale hoeveelheid RAM in de gebruikte clients. Dat wil zeggen, aangezien elke client 128 GiB RAM heeft, was de bestandsgrootte voor threads gelijk aan of hoger dan 16 threads 4096 GiB gedeeld door het aantal threads (de variabele $Size hieronder werd gebruikt om die waarde te beheren). Voor die gevallen met minder dan 16 threads (wat impliceert dat elke thread op een andere client werd uitgevoerd), werd de bestandsgrootte vastgesteld op twee keer de hoeveelheid geheugen per client, of 256 GiB.
iozone -i0 -c -e -w -r 8M -s $ G -t $Threads -+n -+m ./threadlist
iozone -i1 -c -e -w -r 8M -s $ G -t $Threads -+n -+m ./threadlist
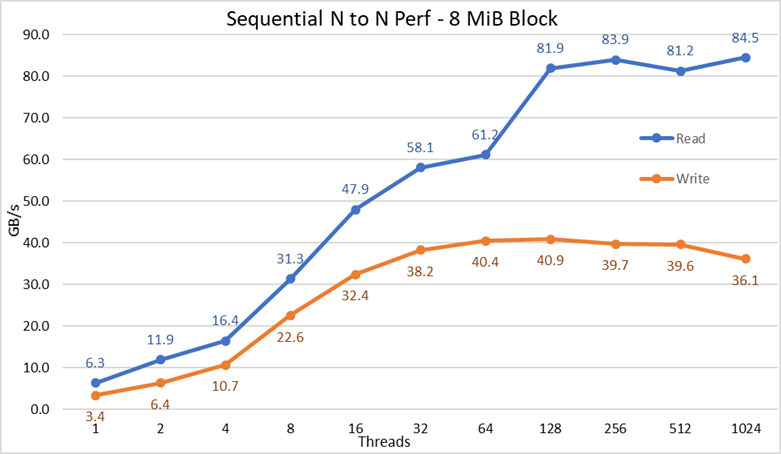
Figuur 2 N tot N sequentiële prestaties
Uit de resultaten kunnen we opmaken dat de schrijfprestaties toenemen met het aantal gebruikte threads en vervolgens een plateau bereiken van ongeveer 64 threads voor schrijfbewerkingen en 128 threads voor leesbewerkingen. Vervolgens nemen de leesprestaties ook snel toe met het aantal threads, en blijven vervolgens stabiel totdat het maximale aantal threads dat IOzone toestaat is bereikt, en daarom zijn de sequentiële prestaties van grote bestanden stabiel, zelfs voor 1024 gelijktijdige clients. De schrijfprestaties dalen met ongeveer 10% bij 1024 threads. Aangezien het clientcluster echter minder dan dat aantal cores heeft, is het onzeker of de daling van de prestaties te wijten is aan swapping en vergelijkbare overhead die niet wordt waargenomen in draaiende media (aangezien de NVMe-latentie erg laag is in vergelijking met draaiende media), of dat de RAID 10-gegevenssynchronisatie een knelpunt wordt. Er zijn meer klanten nodig om dat punt op te helderen. Er werd een afwijking bij de leesbewerkingen waargenomen bij 64 threads, waarbij de prestaties niet werden geschaald met de snelheid die werd waargenomen voor eerdere datapunten, en vervolgens op het volgende gegevenspunt wordt verplaatst naar een waarde die zeer dicht bij de aanhoudende prestaties ligt. Meer testen zijn nodig om de reden voor een dergelijke anomalie te vinden, maar valt buiten het bestek van deze blog.
De maximale leesprestaties voor leesbewerkingen waren lager dan de theoretische prestaties van de NVMe-apparaten (~102 GB/s), of de prestaties van EDR-koppelingen, zelfs als ervan wordt uitgegaan dat één koppeling meestal werd gebruikt voor NVMe over fabric-verkeer (4x EDR BW ~96 GB/s).
Dit is echter geen verrassing, aangezien de hardwareconfiguratie niet gebalanceerd is met betrekking tot de NVMe-apparaten en IB HCA's onder elke CPU-socket. Eén CX6-adapter bevindt zich onder CPU1, terwijl de CPU2 alle NVMe-apparaten heeft en de tweede CX6-adapters. Elk storageverkeer dat gebruikmaakt van de eerste HCA moet de UPI's gebruiken om toegang te krijgen tot de NVMe-apparaten. Bovendien moet elke gebruikte core in CPU1 toegang hebben tot apparaten of geheugen die aan CPU2 zijn toegewezen, waardoor de gegevenslocatie eronder lijdt en UPI-koppelingen worden gebruikt. Dat kan de verlaging voor de maximale prestaties verklaren, vergeleken met de maximale prestaties van de NVMe-apparaten of de lijnsnelheid voor CX6 HCA's. Het alternatief om die beperking op te lossen is het hebben van een gebalanceerde hardwareconfiguratie, wat inhoudt dat de dichtheid tot de helft wordt teruggebracht door een R740 met vier x16-slots te gebruiken en twee x16 PCIe-expanders te gebruiken om NVMe-apparaten gelijkmatig over twee CPU's te verdelen en één CX6 HCA onder elke CPU te hebben.
Sequentiële IOR-prestaties N-clients naar 1 bestand
De prestaties van sequentiële N-clients naar één gedeeld bestand werden gemeten met IOR versie 3.3.0, bijgestaan door OpenMPI v4.0.1 om de benchmark uit te voeren op de 16 rekenknooppunten. De uitgevoerde tests varieerden van één thread tot 512 threads, omdat er niet genoeg cores waren voor 1024 of meer threads. In deze benchmarktests zijn 8 MiB-blokken gebruikt voor optimale prestaties. In het vorige gedeelte over de prestatietest wordt een completere uitleg gegeven waarom dat van belang is.
De effecten van datacaching werden geminimaliseerd door de GPFS-paginapool afstembaar in te stellen op 16GiB en de totale bestandsgrootte was twee keer de totale hoeveelheid RAM in de gebruikte clients. Dat wil zeggen, aangezien elke client 128 GiB RAM heeft, was de bestandsgrootte voor threads gelijk aan of hoger dan 16 threads 4096 GiB, en een gelijke hoeveelheid van dat totaal werd gedeeld door het aantal threads (de variabele $Size hieronder werd gebruikt om die waarde te beheren). Voor die gevallen met minder dan 16 threads (wat impliceert dat elke thread op een andere client draaide), was de bestandsgrootte twee keer de hoeveelheid geheugen per gebruikte client maal het aantal threads, of met andere woorden, elke thread werd gevraagd om 256 GiB te gebruiken.
De volgende opdrachten werden gebruikt om de benchmark voor schrijf- en leesbewerkingen uit te voeren, waarbij $Threads de variabele was met het aantal gebruikte threads (1 tot 1024 verhoogd in machten van twee), en my_hosts.$Threads het overeenkomstige bestand is dat elke thread aan een ander knooppunt heeft toegewezen, met behulp van round robin om ze homogeen te verdelen over de 16 rekenknooppunten.
mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads --mca btl_openib_allow_ib 1 --mca pml ^ucx --oversubscribe --prefix /mmfs1/perftest/ompi /mmfs1/perftest/lanl_ior/bin/ior -a POSIX -v -i 1 -d 3 -e -k -o /mmfs1/perftest/tst.file -w -s 1 -t 8m -b $ G
mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads --mca btl_openib_allow_ib 1 --mca pml ^ucx --oversubscribe --prefix /mmfs1/perftest/ompi /mmfs1/perftest/lanl_ior/bin/ior -a POSIX -v -i 1 -d 3 -e -k -o /mmfs1/perftest/tst.file -r -s 1 -t 8m -b $ G
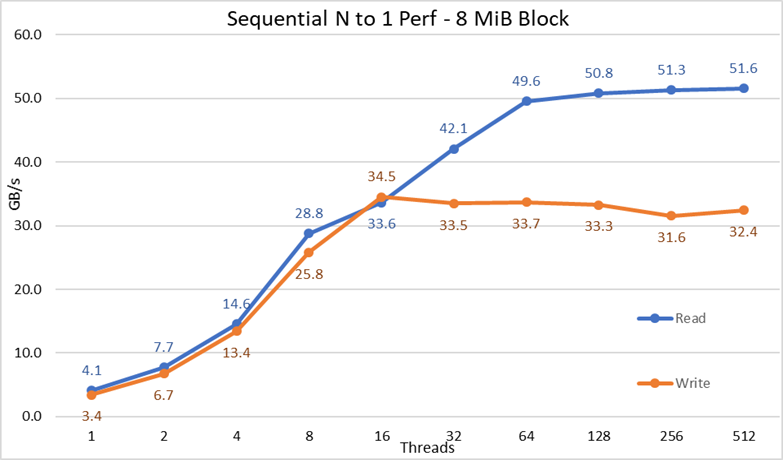
Afbeelding 3 N-naar-1 Sequentiële prestaties
Uit de resultaten blijkt dat de lees- en schrijfprestaties hoog zijn, ongeacht de impliciete noodzaak van vergrendelingsmechanismen, omdat alle threads toegang hebben tot hetzelfde bestand. De prestaties nemen weer zeer snel toe met het aantal gebruikte threads en bereiken vervolgens een plateau dat relatief stabiel is voor lees- en schrijfbewerkingen tot het maximale aantal threads dat in deze test wordt gebruikt. Merk op dat de maximale leesprestaties 51,6 GB/s waren bij 512 threads, maar het plateau in prestaties is het bereik bij ongeveer 64 threads. Merk ook op dat de maximale schrijfprestaties van 34,5 GB/s werden bereikt bij 16 threads en een plateau bereikten dat kan worden waargenomen tot het maximale aantal gebruikte threads.
Willekeurige kleine blokken IOzone Prestaties N clients naar N bestanden
De prestaties van willekeurige N-clients naar N-bestanden werden gemeten met IOzone versie 3.487. De uitgevoerde tests varieerden van enkele thread tot 1024 threads in stappen van machten van twee.
De uitgevoerde tests varieerden van één thread tot 512 threads, omdat er niet genoeg clientcores waren voor 1024 threads. Elke thread gebruikte een ander bestand en de threads kregen round robin toegewezen op de clientknooppunten. In deze benchmarktests zijn 4 KiB-blokken gebruikt voor het emuleren van verkeer van kleine blokken en het gebruik van een wachtrijdiepte van 16. De resultaten van de grootschalige oplossing en de capaciteitsuitbreiding worden vergeleken.
Caching-effecten werden opnieuw geminimaliseerd door de GPFS-paginapool afstembaar in te stellen op 16GiB en om mogelijke data-caching-effecten van de clients te voorkomen, was de totale datagrootte van de bestanden twee keer de totale hoeveelheid RAM in de gebruikte clients. Dat wil zeggen, aangezien elke client 128 GiB RAM heeft, was de bestandsgrootte voor threads gelijk aan of hoger dan 16 threads 4096 GiB gedeeld door het aantal threads (de variabele $Size hieronder werd gebruikt om die waarde te beheren). Voor die gevallen met minder dan 16 threads (wat impliceert dat elke thread op een andere client werd uitgevoerd), werd de bestandsgrootte vastgesteld op twee keer de hoeveelheid geheugen per client, of 256 GiB.
iozone -i0 -I -c -e -w -r 8M -s $ G -t $Threads -+n -+m ./nvme_threadlist <= Maak de bestanden opeenvolgend
iozone -i2 -I -c -O -w -r 4k -s $ G -t $Threads -+n -+m ./nvme_threadlist <= Voer de willekeurige lees- en schrijfbewerkingen uit.
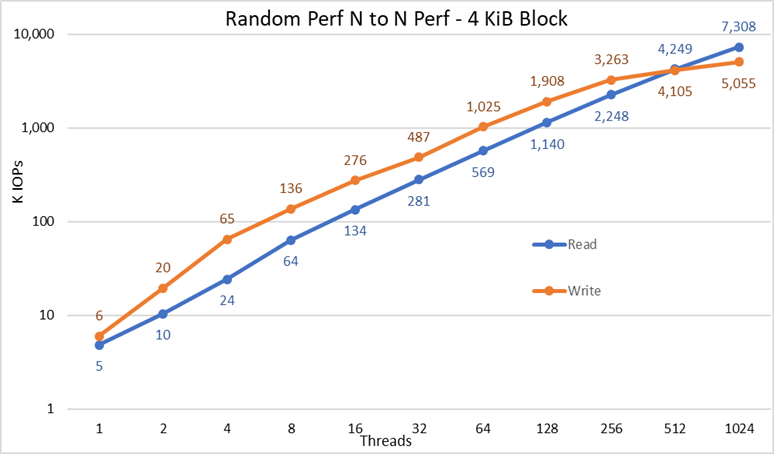
Figuur 4 N tot N willekeurige prestaties
Uit de resultaten kunnen we opmaken dat schrijfprestaties beginnen bij een hoge waarde van 6K IOps en gestaag oplopen tot 1024 threads, waar het een plateau met meer dan 5M IOPS lijkt te bereiken als er meer threads kunnen worden gebruikt. De leesprestaties beginnen daarentegen bij 5K IOPS's en nemen gestaag toe met het aantal gebruikte threads (houd er rekening mee dat het aantal threads voor elk datapunt wordt verdubbeld) en bereiken de maximale prestaties van 7,3 miljoen IOPS bij 1024 threads zonder tekenen van het bereiken van een plateau. Als u meer threads gebruikt, is meer nodig dan de 16 rekenknooppunten om gebrek aan resources en overmatige swapping te voorkomen, wat de schijnbare prestaties kan verlagen, terwijl de NVMe-knooppunten in feite de prestaties kunnen handhaven.
Metadataprestaties met MDtest met 4 KiB-bestanden
Metadataprestaties werden gemeten met MDtest versie 3.3.0, bijgestaan door OpenMPI v4.0.1 om de benchmark uit te voeren op de 16 rekenknooppunten. De uitgevoerde tests varieerden van single thread tot 512 threads. De benchmark werd alleen gebruikt voor bestanden (geen metadata van directories), waarbij het aantal aanmaakacties, statistieken, leesbewerkingen en verwijderingen werd verkregen dat de oplossing aankan, en de resultaten werden afgezet tegen de oplossing voor groot formaat.
De optionele High Demand Metadata Module werd gebruikt, maar met een enkele ME4024-array, zelfs dat de grote configuratie en getest in dit werk was aangewezen om twee ME4024's te hebben. De reden voor het gebruik van die metadatamodule is dat deze NVMe-knooppunten momenteel alleen worden gebruikt als storagedoelen voor data. De knooppunten kunnen echter worden gebruikt om gegevens en metadata op te slaan, of zelfs als flash-alternatief voor de veelgevraagde metadatamodule, als extreme metadata-eisen daarom vragen. Deze configuraties zijn niet getest als onderdeel van deze werkzaamheden.
Aangezien dezelfde veeleisende metadatamodule is gebruikt voor eerdere benchmarking van de DellEMC Ready Solution voor HPC PixStor storageoplossing, zullen de metadataresultaten zeer vergelijkbaar zijn in vergelijking met eerdere blogresultaten. Om die reden is het onderzoek met lege bestanden niet gedaan, maar zijn er 4 KiB-bestanden gebruikt. Aangezien 4KiB-bestanden niet samen met de metadata-informatie in een inode passen, worden NVMe-knooppunten gebruikt om gegevens voor elk bestand op te slaan. Daarom kan MDtest een globaal idee geven van de prestaties van kleine bestanden voor leesbewerkingen en de rest van de metadatabewerkingen.
De volgende opdracht werd gebruikt om de benchmark uit te voeren, waarbij $Threads de variabele was met het aantal gebruikte threads (1 tot 512 verhoogd in machten van twee), en my_hosts.$Threads het corresponderende bestand is dat elke thread op een ander knooppunt heeft toegewezen, met behulp van round robin om ze homogeen te verdelen over de 16 rekenknooppunten. Net als bij de benchmark voor willekeurige IO was het maximale aantal threads beperkt tot 512, omdat er niet genoeg cores zijn voor 1024 threads en contextwisseling de resultaten zou beïnvloeden, omdat een getal lager zou zijn dan de werkelijke prestaties van de oplossing.
mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads --prefix /mmfs1/perftest/ompi --mca btl_openib_allow_ib 1 /mmfs1/perftest/lanl_ior/bin/mdtest -v -d /mmfs1/perftest/ -i 1 -b $Directories -z 1 -L -I 1024 -y -u -t -F -w 4K -e 4K
Aangezien de prestatieresultaten kunnen worden beïnvloed door het totale aantal IOPS, het aantal bestanden per map en het aantal threads, werd besloten om het totale aantal bestanden vast te houden op 2 MiB-bestanden (2^21 = 2097152), het aantal bestanden per map vast te stellen op 1024 en het aantal mappen te variëren naarmate het aantal threads veranderde, zoals weergegeven in tabel 3.
Tabel 3 MDtestverdeling van bestanden op directories
|
Aantal threads |
Aantal mappen per thread |
Totaal aantal bestanden |
|
1 |
2048 |
2,097,152 |
|
2 |
1024 |
2,097,152 |
|
4 |
512 |
2,097,152 |
|
8 |
256 |
2,097,152 |
|
16 |
128 |
2,097,152 |
|
32 |
64 |
2,097,152 |
|
64 |
32 |
2,097,152 |
|
128 |
16 |
2,097,152 |
|
256 |
8 |
2,097,152 |
|
512 |
4 |
2,097,152 |
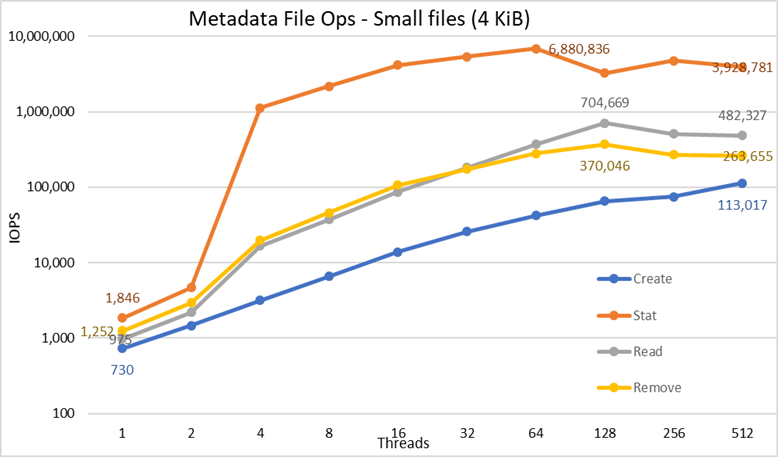
Afbeelding 5 Metadataprestaties – 4 KiB-bestanden
Merk eerst op dat de gekozen schaal logaritmisch was met grondtal 10, om bewerkingen te kunnen vergelijken die verschillen hebben met verschillende ordes van grootte; Anders zouden sommige bewerkingen eruitzien als een vlakke lijn in de buurt van 0 op een lineaire schaal. Een loggrafiek met grondtal 2 zou geschikter kunnen zijn, omdat het aantal threads wordt verhoogd in machten van 2, maar de grafiek zou erg op elkaar lijken en mensen hebben de neiging om betere getallen te hanteren en te onthouden op basis van machten van 10.
Het systeem behaalt zeer goede resultaten, zoals eerder gemeld, met Stat-bewerkingen die de piekwaarde bereiken bij 64 threads met bijna 6,9 miljoen op/s en vervolgens worden verlaagd voor een hoger aantal threads dat een plateau bereikt. Creatiebewerkingen bereiken het maximum van 113K op/s bij 512 threads, en zullen naar verwachting blijven toenemen als er meer clientknooppunten (en cores) worden gebruikt. Lees- en verwijderingsbewerkingen bereikten hun maximum bij 128 threads, met een piek van bijna 705.000 bewerkingen voor leesbewerkingen en 370.000 bewerkingen voor verwijderingen, waarna ze een plateau bereikten. Stat-bewerkingen hebben meer variabiliteit, maar zodra ze hun piekwaarde hebben bereikt, dalen de prestaties niet onder de 3,2 miljoen op/s voor statistieken. Maken en Verwijderen zijn stabieler zodra ze een plateau hebben bereikt en blijven boven de 265K op/s voor Verwijdering en 113K op/s voor Maken. Ten slotte bereiken leesbewerkingen een plateau met prestaties van meer dan 265K op/s.
Conclusies en toekomstig werk
De NVMe-knooppunten zijn een belangrijke aanvulling op de HPC-storageoplossing omdat ze een zeer krachtige laag bieden, met een goede dichtheid, zeer hoge random-access-prestaties en zeer hoge sequentiële prestaties. Bovendien schaalt de oplossing lineair op in capaciteit en prestaties naarmate er meer NVMe-knooppuntmodules worden toegevoegd. De prestaties van de NVMe-knooppunten kunnen worden overzien in Tabel 4, zijn naar verwachting stabiel en deze waarden kunnen worden gebruikt om de prestaties voor een ander aantal NVMe-knooppunten te schatten.
Houd er echter rekening mee dat elk paar NVMe-knooppunten de helft biedt van elk getal dat in tabel 4 wordt weergegeven.
Deze oplossing biedt HPC-klanten een zeer betrouwbaar parallel bestandssysteem dat door veel Top 500 HPC-clusters wordt gebruikt. Daarnaast biedt het uitzonderlijke zoekmogelijkheden, geavanceerde bewaking en beheer, en het toevoegen van optionele gateways maakt het delen van bestanden mogelijk via alomtegenwoordige standaardprotocollen zoals NFS, SMB en andere naar zoveel clients als nodig is.
Tabel 4 piek- en aanhoudende prestaties voor 2 paren NVMe-knooppunten
|
|
Topprestaties |
Aanhoudende prestaties |
||
|
Schrijven |
Lezen |
Schrijven |
Lezen |
|
|
Grote sequentiële N-clients naar N-bestanden |
40,9 GB/s |
84,5 GB/s |
40 GB/s |
81 GB/s |
|
Grote sequentiële N-clients naar één gedeeld bestand |
34,5 GB/s |
51,6 GB/s |
31,5 GB/s |
50 GB/s |
|
Willekeurige kleine blokken N clients naar N bestanden |
5.06MIOPS |
7,31 MIOPS |
5 MIOPS |
7.3 MIOPS |
|
Metadata 4KiB-bestanden maken |
113K IOps |
113K IOps |
||
|
Metadata Stat 4KiB-bestanden |
6,88 miljoen IOps |
3,2 miljoen IOps |
||
|
Metagegevens 4KiB-bestanden lezen |
705K IOps |
500 K IOps |
||
|
Metadata 4KiB-bestanden verwijderen |
370K IOps |
265K IOps |
||
Aangezien NVMe-knooppunten alleen voor data werden gebruikt, kan mogelijk toekomstig werk bestaan uit het gebruik ervan voor data en metadata en een op zichzelf staande flash-gebaseerde laag met betere metadataprestaties vanwege de hogere bandbreedte en lagere latentie van NVMe-apparaten in vergelijking met SAS3 SSD's achter RAID-controllers. Als een klant extreem hoge eisen stelt aan metadata en een oplossing nodig heeft die compacter is dan wat de veeleisende metadatamodule kan bieden, kunnen sommige of alle gedistribueerde RAID 10-apparaten worden gebruikt voor metadata op dezelfde manier als RAID 1-apparaten op de ME4024's nu worden gebruikt.
Een andere blog die binnenkort wordt uitgebracht, zal de PixStor Gateway-knooppunten karakteriseren, waarmee de PixStor-oplossing kan worden verbonden met andere netwerken met behulp van NFS- of SMB-protocollen en de prestaties kunnen worden opgeschaald. Ook zal de oplossing zeer binnenkort worden geüpdatet naar HDR100, en een andere blog zal naar verwachting over dat werk praten.