Dell EMC Ready Solution for HPC PixStor Storage: nível de NVMe
Summary: Blog sobre um componente da solução de armazenamento para HPC que inclui informações sobre arquitetura e avaliação de desempenho.
Symptoms
Blog sobre um componente da solução de armazenamento para HPC que inclui informações sobre arquitetura e avaliação de desempenho.
Resolution
Dell EMC Ready Solution for HPC PixStor Storage
Nível de NVMe
Sumário
Desempenho sequencial do IOzone de N clients para N arquivos
Desempenho sequencial do IOR de N clients para um arquivo
Desempenho de blocos pequenos aleatórios do IOzone de N clients para N arquivos
Desempenho de metadados com MDtest usando arquivos de 4 KiB
Introdução
Os ambientes de HPC atuais aumentaram as demandas por armazenamento de velocidade extremamente alta. Além disso, com o número maior de núcleos nas CPUs, as redes mais rápidas e a memória maior, o armazenamento estava se tornando o gargalo de muitas cargas de trabalho. Esses requisitos de HPC de alta demanda geralmente são atendidos por File systems paralelos (PFS), que concedem acesso simultâneo a um único arquivo ou um conjunto de arquivos de vários nós, distribuindo dados de maneira muito eficiente e segura para várias LUNs entre vários servidores. Esses file systems normalmente são baseados em mídia rotacional para proporcionar a maior capacidade pelo menor custo. No entanto, cada vez mais, a velocidade e a latência da mídia rotacional não conseguem acompanhar as demandas de muitas cargas de trabalho de HPC modernas, exigindo o uso de tecnologia flash na forma de buffers de burst, níveis mais rápidos ou, até mesmo, áreas temporárias muito rápidas, locais ou distribuídas. A DellEMC Ready Solution for HPC PixStor Storage usa nós NVMe como o componente para atender a essas novas demandas de largura de banda alta, além de ser flexível, dimensionável, eficiente e confiável.
Arquitetura da solução
Esta publicação do blog faz parte de uma série para as soluções de File system paralelo (PFS) voltadas para ambientes de HPC, principalmente para a DellEMC Ready Solution for HPC PixStor Storage, em que os servidores DellEMC PowerEdge R640 com unidades NVMe são usados como um nível baseado em flash rápido.
A solução PixStor PFS inclui o File system paralelo geral (GPFS) amplamente difundido, também conhecido como Spectrum Scale. A ArcaStream também inclui muitos outros componentes de software para oferecer lógica analítica avançada, administração e monitoramento simplificados, pesquisa eficiente de arquivos, recursos avançados de gateway e muito mais.
Os nós NVMe apresentados nesta publicação proporcionam um nível baseado em flash de desempenho elevado para a solução PixStor. É possível fazer o scale-out do desempenho e da capacidade desse nível de NVMe por meio de nós NVMe adicionais. A maior capacidade é oferecida ao selecionar os dispositivos NVMe adequados compatíveis com o PowerEdge R640.
A Figura 1 apresenta a arquitetura de referência — uma solução com quatro nós NVMe que usa o módulo de metadados de alta demanda — que lida com todos os metadados na configuração testada. O motivo para isso é que, atualmente, esses nós NVMe eram usados como destinos de armazenamento somente de dados. No entanto, também é possível usar nós NVMe para armazenar dados e metadados ou, até mesmo, como uma alternativa flash mais rápida ao módulo de metadados de alta demanda, caso demandas extremas de metadados exijam isso. Essas configurações dos nós NVMe não foram testadas como parte deste trabalho, mas serão testadas no futuro.
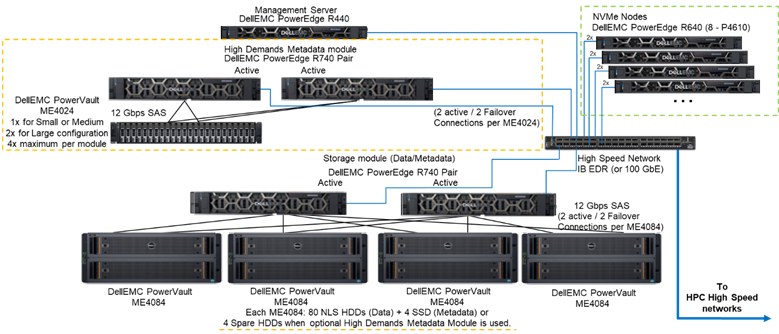
Figura 1 Arquitetura de referência
Componentes da solução
Esta solução utiliza as mais recentes CPUs escaláveis Intel Xeon de 2a geração, conhecidas como CPUs Cascade Lake, e a RAM mais rápida disponível (2.933 MT/s), exceto nos nós de gerenciamento para manter o custo-benefício deles. Além disso, a solução foi atualizada para a versão mais recente da PixStor (5.1.3.1) que oferece suporte a RHEL 7.7 e OFED 5.0, que serão as versões de software compatíveis no momento do lançamento.
Cada nó NVMe tem oito dispositivos Dell P4610 configurados como oito dispositivos RAID 10 em um par de servidores, que usam uma solução NVMe over Fabrics para permitir redundância de dados não apenas no nível dos dispositivos, mas também no nível do servidor. Além disso, quando dados entram ou saem de um desses dispositivos RAID10, todas as 16 unidades de ambos os servidores são usadas, o que aumenta a largura de banda do acesso a todas as unidades. Portanto, a única restrição para esses componentes é que eles devem ser vendidos e usados em pares. É possível usar as unidades NVMe compatíveis com o PowerEdge R640 nesta solução; no entanto, o P4610 tem uma largura de banda sequencial de 3.200 MB/s para leituras e gravações, além de altas especificações de IOPS aleatórias, que são recursos úteis ao tentar dimensionar e estimar o número de pares necessários para atender aos requisitos desse nível de flash.
Cada servidor R640 tem dois HCAs Mellanox ConnectX-6 de porta única com suporte a VPI e taxa HDR100 que são usados como conexões IB EDR de 100 Gb. No entanto, os nós NVMe estão prontos para oferecer suporte a velocidades HDR100 quando usados com cabos e switches HDR. O teste do padrão HDR100 nesses nós é adiado como parte da atualização do HDR100 para toda a solução PixStor. As duas interfaces CX6 são usadas para sincronizar dados do RAID 10 (NVMe over Fabrics) e como a conectividade do file system. Além disso, elas oferecem redundância de hardware no adaptador, na porta e no cabo. Para redundância no nível do switch, são necessários adaptadores VPI CX6 de porta dupla, que precisam ser adquiridos como componentes S&P.
Para caracterizar o desempenho dos nós NVMe com base no sistema representado na Figura 1, apenas o módulo de metadados de alta demanda e os nós NVMe foram usados.
A Tabela 1 apresenta a lista dos principais componentes da solução. Da lista de unidades compatíveis com o ME4024, SSDs de 960 Gb foram usadas para as operações de metadados e para a caracterização de desempenho. Unidades mais rápidas podem oferecer IOPS aleatórias melhores e aprimorar as operações de criação/remoção de metadados. Todos os dispositivos NVMe compatíveis com o PowerEdge R640 serão compatíveis com os nós NVMe.
Tabela 1 Componentes que serão usados no momento do lançamento e no ambiente de teste
|
No lançamento |
||
|
Conectividade interna |
Dell Networking S3048-ON Gigabit Ethernet |
|
|
Subsistema de armazenamento de dados |
1 a 4 Dell EMC PowerVault ME4084 1 a 4 Dell EMC PowerVault ME484 (um por ME4084) |
|
|
Subsistema opcional de armazenamento de metadados de alta demanda |
1 a 2 Dell EMC PowerVault ME4024 (4 ME4024, se necessário, somente configuração grande) |
|
|
Controladores RAID de armazenamento |
SAS de 12 Gbps |
|
|
Processador |
Nós NVMe |
2 processadores Intel Xeon Gold 6230 2,1 G, 20C/40T |
|
Metadados de alta demanda |
||
|
Nó de armazenamento |
||
|
Nó de gerenciamento |
2 processadores Intel Xeon Gold 5220 2,2 G, 18C/36T |
|
|
Memória |
Nós NVMe |
12x RDIMMs de 16 GiB 2933 MT/s (192 GiB) |
|
Metadados de alta demanda |
||
|
Nó de armazenamento |
||
|
Nó de gerenciamento |
12 DIMMs de 16 GB, 2666 MT/s (192 GiB) |
|
|
Sistema operacional |
CentOS 7.7 |
|
|
Versão do kernel |
3.10.0-1062.12.1.el7.x86_64 |
|
|
Software PixStor |
5.1.3.1 |
|
|
Software do file system |
Spectrum Scale (GPFS) 5.0.4-3 com NVMesh 2.0.1 |
|
|
Conectividade de rede de alto desempenho |
Nós NVMe: 2 ConnectX-6 InfiniBand usando EDR/100 GbE |
|
|
Switch de alto desempenho |
2 Mellanox SB7800 |
|
|
Versão do OFED |
Mellanox OFED 5.0-2.1.8.0 |
|
|
Discos locais (SO e análise/monitoramento) |
Todos os servidores, exceto os listados Nós NVMe 3 SSDs SAS3 de 480 GB (RAID1 + HS) para o SO 3 SSDs SAS3 de 480 GB (RAID1 + HS) para o SO Controlador RAID PERC H730P Controlador RAID PERC H740P Nó de gerenciamento 3 SSDs SAS3 de 480 GB (RAID1 + HS) para o SO com controlador RAID PERC H740P |
|
|
Gerenciamento de sistemas |
iDRAC 9 Enterprise + DellEMC OpenManage |
|
Caracterização de desempenho
Para caracterizar esse novo componente da Ready Solution, foram usadas as seguintes referências de desempenho:
· IOzone sequencial de N para N
· IOR sequencial de N para 1
· IOzone aleatório
· MDtest
Em todas as referências de desempenho listadas acima, o ambiente de teste tinha os clients conforme descrito na Tabela 2 abaixo. Como o número de nós de computação disponíveis para testes era de apenas 16, quando um número maior de threads era necessário, esses threads eram distribuídos igualmente nos nós de computação (ou seja, 32 threads = 2 threads por nó, 64 threads = 4 threads por nó, 128 threads = 8 threads por nó, 256 threads = 16 threads por nó, 512 threads = 32 threads por nó, 1.024 threads = 64 threads por nó). A intenção era simular um número maior de clients simultâneos com o número limitado de nós de computação disponíveis. Como algumas referências de desempenho oferecem suporte a muitos threads, utilizou-se um valor máximo de até 1.024 (especificado para cada teste), evitando a alternância excessiva de contexto e outros efeitos colaterais relacionados que afetam os resultados de desempenho.
Tabela 2 Ambiente de teste de clients
|
Número de nós de client |
16 |
|
Nó de client |
C6320 |
|
Processadores por nó de client |
2 Intel(R) Xeon(R) Gold E5-2697v4 com 18 núcleos a 2,30 GHz |
|
Memória por nó de client |
8x RDIMMs de 16 GiB 2400 MT/s (128 GiB) |
|
BIOS |
2.8.0 |
|
Kernel do SO |
3.10.0-957.10.1 |
|
Software do file system |
Spectrum Scale (GPFS) 5.0.4-3 com NVMesh 2.0.1 |
Desempenho sequencial do IOzone N clients para N arquivos
O desempenho sequencial de N clients para N arquivos foi medido com o IOzone versão 3.487. Os testes executados variaram de thread único até 1.024 threads em incrementos de potências de dois.
Os efeitos do armazenamento em cache sobre os servidores foram minimizados pela configuração do pool de páginas do GPFS ajustável para 16 GiB e pelo uso de arquivos com mais do que o dobro desse tamanho. É importante observar que, para o GPFS, essa opção define a quantidade máxima de memória usada para armazenamento em cache de dados, independentemente da quantidade de RAM instalada e livre. Além disso, é importante observar que, embora nas soluções anteriores de HPC da Dell EMC, o tamanho do bloco para grandes transferências sequenciais seja de 1 MiB, o GPFS foi formatado com 8 blocos MiB e, portanto, esse valor é usado na referência de desempenho para obter o desempenho ideal. Isso pode parecer muito grande e, aparentemente, desperdiçar muito espaço, mas o GPFS usa a alocação de sub-bloco para evitar essa situação. Na configuração atual, cada bloco foi subdividido em 256 sub-blocos de 32 KiB cada.
Os seguintes comandos foram usados para executar a referência de desempenho para leituras e gravações, em que $Threads era a variável com o número de threads usados (1 a 1.024 incrementados em potências de dois), e threadlist era o arquivo que alocou cada thread em um nó diferente, fazendo rodízio para distribuí-los de modo homogêneo entre os 16 nós de computação.
Para evitar possíveis efeitos do cache de dados com base nos clients, o tamanho total de dados dos arquivos foi o dobro da quantidade total de RAM dos clients utilizados. Ou seja, como cada client tem 128 GiB de RAM, para contagens de threads iguais ou superiores a 16 threads, o tamanho do arquivo foi de 4.096 GiB dividido pelo número de threads (a variável $Size abaixo foi usada para gerenciar esse valor). Para os casos com menos de 16 threads (o que significa que cada thread estava em execução em um client diferente), o tamanho do arquivo foi fixado como o dobro da quantidade de memória por client, ou 256 GiB.
iozone -i0 -c -e -w -r 8M -s $ G -t $Threads -+n -+m ./threadlist
iozone -i1 -c -e -w -r 8M -s $ G -t $Threads -+n -+m ./threadlist
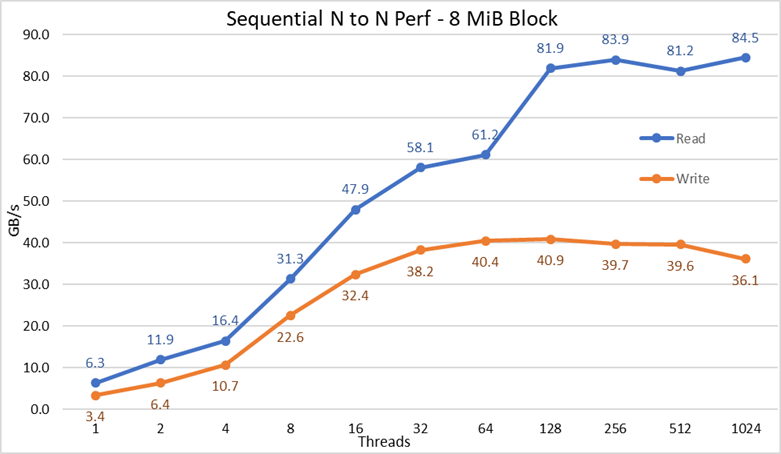
Figura 2 Desempenho sequencial de N para N
Com base nos resultados, nós podemos observar que o desempenho de gravação aumenta conforme o número de threads usados e, em seguida, atinge um platô de cerca de 64 threads para gravações e 128 threads para leituras. O desempenho de leitura também aumenta rapidamente de acordo com o número de threads e, depois, fica estável até que o número máximo de threads que o IOzone permite seja atingido e, portanto, o desempenho sequencial de arquivos grandes é estável mesmo para 1.024 clients simultâneos. O desempenho de gravação cai cerca de 10% quando o número de threads atinge 1.024. No entanto, como o cluster de client tem menos do que esse número de núcleos, não se sabe se a queda no desempenho se deve à troca e à sobrecarga semelhante não observada na mídia rotacional (pois a latência de NVMe é muito baixa em comparação com a mídia rotacional) ou se a sincronização de dados do RAID 10 está se tornando um gargalo. Mais clients são necessários para esclarecer esse ponto. Observou-se uma anomalia nas leituras com 64 threads, em que o desempenho não foi dimensionado na taxa observada para os pontos de dados anteriores e, no próximo ponto de dados, avança para um valor muito próximo ao do desempenho sustentado. Mais testes são necessários para encontrar o motivo dessa anomalia, mas isso está fora do escopo desta publicação.
O desempenho máximo de leitura foi inferior ao desempenho teórico dos dispositivos NVMe (cerca de 102 GB/s) ou ao desempenho dos links EDR, mesmo supondo-se que um link tenha sido usado principalmente para o tráfego de NVMe over Fabrics (4 EDR com BW de cerca de 96 GB/s).
No entanto, isso não é uma surpresa, pois a configuração de hardware não é equilibrada em relação aos dispositivos NVMe e aos HCAs IB de cada soquete de CPU. Um adaptador CX6 está na CPU1, enquanto a CPU2 tem todos os dispositivos NVMe e o segundo adaptador CX6. Qualquer tráfego de armazenamento que use o primeiro HCA deve usar as UPIs para acessar os dispositivos NVMe. Além disso, qualquer núcleo usado na CPU1 precisa acessar os dispositivos ou a memória atribuída à CPU2 para que a localidade dos dados seja afetada e os links de UPI sejam usados. Isso pode explicar a redução do desempenho máximo, em comparação com o desempenho máximo dos dispositivos NVMe ou com a velocidade de linha dos HCAs CX6. A alternativa para corrigir essa limitação é ter uma configuração de hardware equilibrada, o que implica reduzir a densidade pela metade usando um R740 com quatro slots x16 e empregar dois expansores PCIe x16 para distribuir igualmente os dispositivos NVMe em duas CPUs e ter um HCA CX6 em cada CPU.
Desempenho sequencial de IOR N clients para 1 arquivo
O desempenho sequencial dos N clients em um único arquivo compartilhado foi medido com a versão IOR 3.3.0, auxiliada pelo OpenMPI v4.0.1 para executar a referência de desempenho nos 16 nós de computação. Os testes executados variaram de thread único até 512 threads, pois não havia núcleos suficientes para 1.024 threads ou mais. Esses testes de referência de desempenho usaram 8 blocos MiB para obter o desempenho ideal. A seção anterior de teste de desempenho apresenta uma explicação mais completa sobre porque isso é importante.
Os efeitos do cache de dados foram minimizados ao definir o pool de páginas do GPFS como ajustável para 16 GiB e ao configurar o tamanho total do arquivo para o dobro da quantidade total de RAM dos clients usados. Ou seja, como cada client tem 128 GiB de RAM, para contagens de threads iguais ou superiores a 16 threads, o tamanho do arquivo foi de 4.096 GiB, e uma quantidade igual desse total foi dividida pelo número de threads (a variável $Size abaixo foi usada para gerenciar esse valor). Para os casos com menos de 16 threads (o que implica que cada thread estava em execução em um client diferente), o tamanho do arquivo foi o dobro da quantidade de memória por client usado, multiplicado pelo número de threads. Em outras palavras, cada thread precisou usar 256 GiB.
Os seguintes comandos foram usados para executar a referência de desempenho para leituras e gravações, em que $Threads foi a variável com o número de threads usados (1 a 1.024 incrementados em potências de dois), e my_hosts.$Threads é o arquivo correspondente que alocou cada thread em um nó diferente, fazendo rodízio para distribuí-los de modo homogêneo entre os 16 nós de computação.
mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads --mca btl_openib_allow_ib 1 --mca pml ^ucx --oversubscribe --prefix /mmfs1/perftest/ompi /mmfs1/perftest/lanl_ior/bin/ior -a POSIX -v -i 1 -d 3 -e -k -o /mmfs1/perftest/tst.file -w -s 1 -t 8m -b $ G
mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads --mca btl_openib_allow_ib 1 --mca pml ^ucx --oversubscribe --prefix /mmfs1/perftest/ompi /mmfs1/perftest/lanl_ior/bin/ior -a POSIX -v -i 1 -d 3 -e -k -o /mmfs1/perftest/tst.file -r -s 1 -t 8m -b $ G
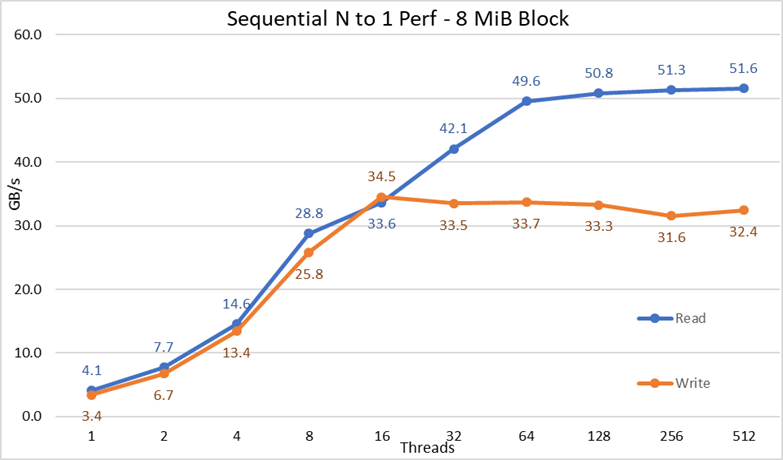
Figura 3 Desempenho sequencial de N para 1
Com base nos resultados, nós podemos observar que o desempenho de leitura e gravação é alto, independentemente da necessidade implícita de mecanismos de bloqueio, pois todos os threads acessam o mesmo arquivo. O desempenho aumenta muito rapidamente conforme o número de threads usados e, em seguida, atinge um platô relativamente estável para leituras e gravações até o número máximo de threads usados nesse teste. Observe que o desempenho máximo de leitura foi de 51,6 GB/s com 512 threads, mas o desempenho atingiu o platô com cerca de 64 threads. Da mesma forma, observe que o desempenho máximo de gravação de 34,5 GB/s foi alcançado com 16 threads e atingiu um platô que pode ser observado até o número máximo de threads usados.
Desempenho de blocos pequenos aleatórios do IOzone N clients para N arquivos
O desempenho aleatório de N clients para N arquivos foi medido com o IOzone versão 3.487. Os testes executados variaram de thread único até 1.024 threads em incrementos de potências de dois.
Os testes executados variaram de thread único até 512 threads, pois não havia núcleos de client suficientes para 1.024 threads. Cada thread estava usando um arquivo diferente e os threads foram atribuídos fazendo rodízio nos nós do client. Esses testes de referência de desempenho usaram blocos de 4 KiB para emular o tráfego de blocos pequenos e usar um tamanho da fila de 16. Os resultados da solução de grande porte e da expansão de capacidade foram comparados.
Novamente, os efeitos do armazenamento em cache foram minimizados ao definir o pool de páginas do GPFS como ajustável para 16 GiB e, para evitar quaisquer efeitos possíveis do cache de dados com base nos clients, o tamanho total de dados dos arquivos foi o dobro da quantidade total de RAM dos clients usados. Ou seja, como cada client tem 128 GiB de RAM, para contagens de threads iguais ou superiores a 16 threads, o tamanho do arquivo foi de 4.096 GiB dividido pelo número de threads (a variável $Size abaixo foi usada para gerenciar esse valor). Para os casos com menos de 16 threads (o que significa que cada thread estava em execução em um client diferente), o tamanho do arquivo foi fixado como o dobro da quantidade de memória por client, ou 256 GiB.
iozone -i0 -I -c -e -w -r 8M -s $ G -t $Threads -+n -+m ./nvme_threadlist <= Criar os arquivos sequencialmente
iozone -i2 -I -c -O -w -r 4k -s $ G -t $Threads -+n -+m ./nvme_threadlist <= Realizar as leituras e gravações aleatórias.
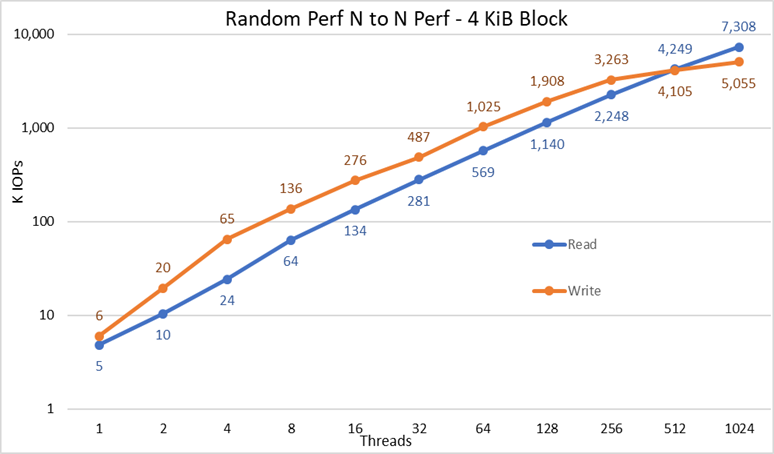
Figura 4 Desempenho aleatório de N para N
Com base nos resultados, nós podemos observar que o desempenho de gravação começa com um valor alto de 6 mil IOPS e aumenta constantemente até 1.024 threads, quando parece alcançar um platô com mais de 5 milhões de IOPS, se for possível usar mais threads. Por outro lado, o desempenho de leitura começa com um valor de 5 mil IOPS, aumenta estavelmente conforme o número de threads usados (lembre-se de que o número de threads é duplicado para cada ponto de dados) e atinge o desempenho máximo de 7,3 milhões de IOPS com 1.024 threads, sem sinal de atingir um platô. O uso de mais threads exigirá mais do que os 16 nós de computação para evitar a falta de recursos e trocas excessivas, que podem reduzir o desempenho aparente. Já os nós NVMe poderiam, de fato, manter o desempenho.
Desempenho de metadados com MDtest usando arquivos de 4 KiB
O desempenho dos metadados foi medido com o MDtest versão 3.3.0, auxiliado pelo OpenMPI v4.0.1 para executar a referência de desempenho nos 16 nós de computação. Os testes executados variaram de thread único para 512 threads. A referência de desempenho foi usada apenas para arquivos (sem metadados de diretórios), obtendo o número de criações, estatísticas, leituras e remoções que a solução pode processar, e os resultados foram comparados com a solução de grande porte.
O módulo opcional de metadados de alta demanda foi usado, mas com um só array ME4024, embora a configuração ampliada e testada neste trabalho tenha sido projetada para ter dois ME4024s. O motivo para usar esse módulo de metadados é que, atualmente, esses nós NVMe são usados como destinos de armazenamento apenas para dados. No entanto, é possível usar os nós para armazenar dados e metadados ou, até mesmo, como uma alternativa flash ao módulo de metadados de alta demanda, caso demandas extremas de metadados exijam isso. Essas configurações não foram testadas como parte deste trabalho.
Como o mesmo módulo de metadados de alta demanda foi usado na referência de desempenho anterior da solução DellEMC Ready Solution for HPC PixStor Storage, os resultados dos metadados serão muito semelhantes aos resultados da publicação anterior do blog. Por esse motivo, o estudo com arquivos vazios não foi realizado e, em vez disso, foram utilizados arquivos de 4 KiB. Como os arquivos de 4 KiB não cabem em um inode junto com as informações de metadados, os nós NVMe serão usados para armazenar dados de cada arquivo. Portanto, o MDtest pode dar uma ideia aproximada do desempenho de arquivos pequenos para leituras e o restante das operações de metadados.
O comando abaixo foi usado para executar a referência de desempenho, em que $Threads foi a variável com o número de threads usados (1 a 512 incrementados em potências de dois), e my_hosts.$Threads é o arquivo correspondente que alocou cada thread em um nó diferente, fazendo rodízio para distribuí-los de modo homogêneo entre os 16 nós de computação. Semelhante à referência de desempenho de E/S aleatória, o número máximo de threads foi limitado a 512, já que não há núcleos suficientes para 1.024 threads e a alternância do contexto afetaria os resultados, relatando um número menor do que o desempenho real da solução.
mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads --prefix /mmfs1/perftest/ompi --mca btl_openib_allow_ib 1 /mmfs1/perftest/lanl_ior/bin/mdtest -v -d /mmfs1/perftest/ -i 1 -b $Directories -z 1 -L -I 1024 -y -u -t -F -w 4K -e 4K
Como os resultados de desempenho podem ser afetados pelo número total de IOPS, pelo número de arquivos por diretório e pelo número de threads, decidiu-se manter fixo o número total de arquivos em 2 MiB (2^21 = 2.097.152), o número de arquivos por diretório em 1.024 e o número de diretórios variável de acordo com o número de threads alterados, conforme exibido na Tabela 3.
Tabela 3 Distribuição de arquivos em diretórios do MDtest
|
Número de threads |
Número de diretórios por thread |
Número total de arquivos |
|
1 |
2048 |
2.097.152 |
|
2 |
1024 |
2.097.152 |
|
4 |
512 |
2.097.152 |
|
8 |
256 |
2.097.152 |
|
16 |
128 |
2.097.152 |
|
32 |
64 |
2.097.152 |
|
64 |
32 |
2.097.152 |
|
128 |
16 |
2.097.152 |
|
256 |
8 |
2.097.152 |
|
512 |
4 |
2.097.152 |
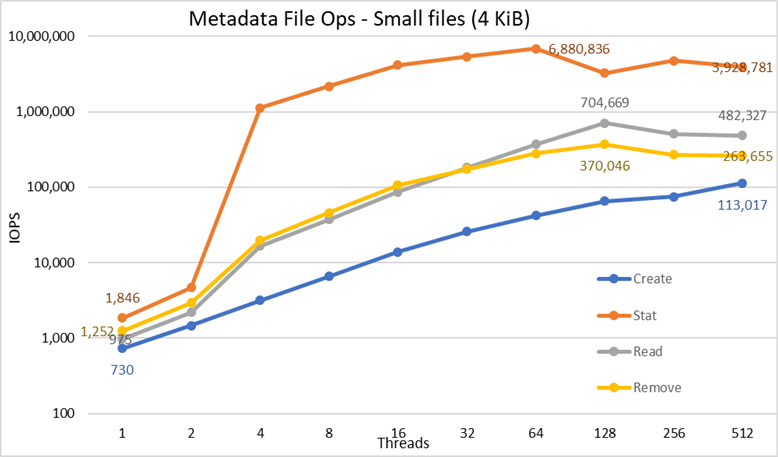
Figura 5 Desempenho dos metadados — arquivos de 4 KiB
Primeiro, observe que a escala escolhida foi logarítmica com base 10 para permitir operações de comparação que têm diferenças exponenciais; caso contrário, algumas das operações seriam semelhantes a uma linha plana próxima a 0 em uma escala linear. Um gráfico de logs com base 2 pode ser mais apropriado, já que o número de threads aumenta em potências de 2, mas o gráfico seria muito semelhante, e as pessoas tendem a lidar melhor com números com base em potências de 10 e a se lembrar deles.
O sistema obtém resultados muito bons, conforme relatado anteriormente, com operações de estatísticas atingindo o valor máximo em 64 threads com quase 6,9 milhões de operações por segundo (op/s) e, depois, sendo reduzidas com contagens maiores de threads, até atingir um platô. As operações de criação atingem o máximo de 113K op/s em 512 threads; portanto, espera-se que continuem aumentando se mais nós (e núcleos) de client forem usados. As operações de leitura e remoção atingiram o máximo em 128 threads, alcançando o pico em quase 705 mil op/s para leituras e 370 mil para remoções e, em seguida, atingiram um platô. As operações de estatísticas têm mais variabilidade mas, depois que atingem o valor máximo, o desempenho dessas operações não cai abaixo de 3,2 milhões op/s. A criação e a remoção ficam mais estáveis quando atingem um patamar e permanecem acima de 265K op/s para remoção e 113K op/s para criação. Por fim, as leituras atingem um platô com desempenho acima de 265 mil op/s.
Conclusões e trabalho futuro
Os nós NVMe são uma adição importante à solução de armazenamento para HPC, pois oferecem um nível de desempenho elevado com boa densidade, desempenho de acesso aleatório muito alto e desempenho sequencial superior. Além disso, é possível fazer scale-out linear da capacidade e do desempenho da solução, à medida que mais módulos de nós NVMe vão sendo adicionados. A Tabela 4 apresenta uma visão geral do desempenho dos nós NVMe. Espera-se que ele seja estável e que esses valores possam ser usados para estimar o desempenho para um número diferente de nós NVMe.
No entanto, lembre-se de que cada par de nós NVMe oferecerá metade de qualquer número exibido na Tabela 4.
Essa solução oferece aos clientes de HPC um file system paralelo muito confiável usado por muitos dos 500 principais clusters de HPC. Além disso, ela proporciona recursos excepcionais de pesquisa, monitoramento e gerenciamento avançados e gateways opcionais adicionais, que permitem o compartilhamento de arquivos por meio de protocolos padrão universais, como NFS, SMB, entre outros, para o máximo de clients necessários.
Tabela 4 Desempenho sustentado e máximo para dois pares de nós NVMe
|
|
Desempenho de pico |
Desempenho sustentado |
||
|
Gravação |
Read |
Gravação |
Read |
|
|
N clients sequenciais grandes para arquivos N |
40,9 GB/s |
84,5 GB/s |
40 GB/s |
81 GB/s |
|
N clients sequenciais grandes para um único arquivo compartilhado |
34,5 GB/s |
51,6 GB/s |
31,5 GB/s |
50 GB/s |
|
Blocos pequenos aleatórios de N clients para N arquivos |
5.06MIOPS |
7.31MIOPS |
5 MIOPS |
7,3 MIOPS |
|
Metadados — criação — arquivos de 4KiB |
113K IOps |
113K IOps |
||
|
Metadados — estatística — arquivos de 4KiB |
6.88M de IOps |
3.2M de IOps |
||
|
Metadados — leitura — arquivos de 4KiB |
705K IOps |
500K IOps |
||
|
Metadados — Remoção — arquivos de 4KiB |
370K IOps |
265K IOps |
||
Como os nós NVMe foram usados apenas para dados, possíveis trabalhos futuros podem incluir o uso deles para dados e metadados e ter um nível autossuficiente baseado em flash com melhor desempenho de metadados, devido à maior largura de banda e à menor latência dos dispositivos NVMe em comparação com as SSDs SAS3 conectadas aos controladores RAID. Como alternativa, se um cliente tiver demandas de metadados extremamente altas e precisar de uma solução mais densa do que a solução que o módulo de metadados de alta demanda pode oferecer, será possível usar alguns ou todos os dispositivos RAID 10 distribuídos para metadados da mesma forma que os dispositivos RAID 1 no ME4024s são usados atualmente.
Outra publicação que será feita no blog em breve caracterizará os nós do PixStor Gateway, que permitem conectar a solução PixStor a outras redes usando protocolos NFS ou SMB e fazer scale-out do desempenho. A solução também será atualizada para o HDR100 muito em breve, e outra publicação do blog deverá falar sobre esse assunto.