PowerEdge: Rozwiązania Dell Ready dla pamięci masowej HPC BeeGFS o dużej wydajności
Summary: Rozwiązania Dell Ready dla pamięci masowej HPC BeeGFS o dużej wydajności
Instructions
Artykuł napisany przez Nirmalę Sundararajan z laboratorium innowacji HPC i AI firmy Dell w listopadzie 2019 r.
Spis treści
- Wprowadzenie
- Architektura referencyjna rozwiązania
- Konfiguracja sprzętu i oprogramowania
- Szczegóły konfiguracji rozwiązania
- R740xd, 24 dyski NVMe, szczegóły dotyczące mapowania procesora
- Charakterystyka wydajności
- Wnioski i przyszłe prace
Wprowadzenie
Zespół Dell HPC z dumą informuje o wprowadzeniu na rynek "Dell EMC Ready Solutions for HPC BeeGFS Storage", najnowszego dodatku do portfolio pamięci masowych HPC. W tym rozwiązaniu wykorzystywane są serwery R740xd, z których każdy jest wyposażony w 24 dyski Mixed Use Express Flash Intel P4600 NVMe 1,6 TB i dwa adaptery Mellanox ConnectX-5 InfiniBand EDR. W konfiguracji z 24 dyskami NVMe 12 dysków SSD NVMe łączy się z przełącznikiem PCIe, a każdy przełącznik jest podłączony do jednego procesora za pomocą karty rozszerzenia PCIe x16. Co więcej, każdy interfejs IB jest podłączony do jednego procesora. Taka zrównoważona konfiguracja, w której każdy procesor jest podłączony do jednego adaptera InfiniBand i obsługuje 12 dysków SSD NVMe, zapewnia maksymalną wydajność, zapewniając, że procesory są w równym stopniu zajęte obsługą żądań we/wy do i z dysków NVMe.
Głównym celem rozwiązania jest wysoka wydajność we/wy i zostało ono zaprojektowane jako rozwiązanie do szybkiego zarysowania. Głównym elementem rozwiązania jest zastosowanie szybkich dysków SSD NVMe, które zapewniają wysoką przepustowość i niskie opóźnienia poprzez usunięcie programu planującego i wąskich gardeł kolejek z warstwy bloku. System plików BeeGFS obsługuje również wysoką łączną przepustowość modułu we/wy.
Architektura referencyjna rozwiązania
Rysunek 1 przedstawia architekturę referencyjną rozwiązania. Serwer zarządzający jest podłączony tylko za pomocą sieci Ethernet do metadanych i serwerów pamięci masowej. Każdy serwer metadanych i pamięci masowej ma dwa łącza InfiniBand i jest podłączony do sieci prywatnej za pośrednictwem sieci Ethernet. Klienci mają jedno łącze InfiniBand i są połączeni z interfejsem prywatnym za pośrednictwem sieci Ethernet.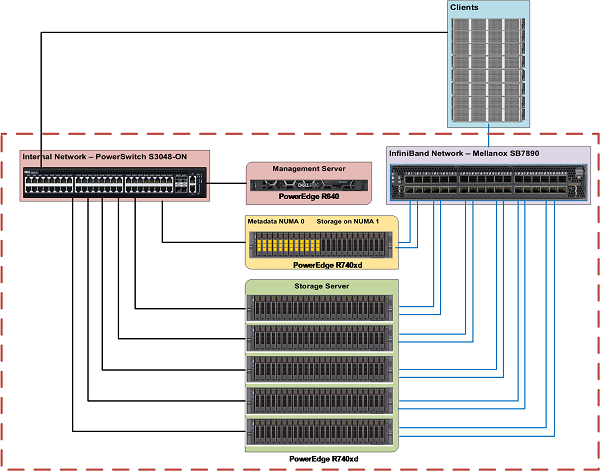
Rysunek 1: Gotowe rozwiązania Dell dla pamięci masowej HPC BeeGFS – Architektura referencyjna
Konfiguracja sprzętu i oprogramowania
W tabelach 1 i 2 przedstawiono odpowiednio specyfikacje sprzętu serwera zarządzania i metadanych/serwera pamięci masowej. Tabela 3 zawiera informacje o wersjach oprogramowania używanych w tym rozwiązaniu.
| Tabela 1 Konfiguracja serwera PowerEdge R640 (serwer zarządzający) | |
|---|---|
| Serwer | Dell PowerEdge R640 |
| Procesor | 2x Intel Xeon Gold 5218 2,3 GHz, 16 rdzeni |
| Pamięć | 12 modułów DIMM DDR4 2666 MT/s o pojemności 8 GB – 96 GB |
| Dyski lokalne | 6 dysków twardych SAS 2,5 cala o pojemności 300 GB i prędkości 15 tys. obr./min |
| Kontroler macierzy RAID | Zintegrowany kontroler macierzy RAID PERC H740P |
| Zarządzanie zewnątrz-pasmowe | iDRAC9 Enterprise z kontrolerem Lifecycle Controller |
| Zasilacze | Dwa zasilacze 1100 W |
| BIOS Version (Wersja systemu BIOS) | 2.2.11 |
| System operacyjny | CentOS™ 7.6 |
| Wersja jądra | 3.10.0-957.27.2.el7.x86_64 |
| Tabela 2 Konfiguracja serwera PowerEdge R740xd (metadane i serwery pamięci masowej) | |
|---|---|
| Serwer | Dell EMC PowerEdge R740xd |
| Procesor | 2 procesory Intel Xeon Platinum 8268, 2,90 GHz, 24 rdzenie |
| Pamięć | 12 modułów DIMM DDR4 2933 MT/s o pojemności 32 GB – 384 GB |
| Karta BOSS | 2 dyski SSD SATA M.2 SATA 240 GB w macierzy RAID 1 dla systemu operacyjnego |
| Dyski lokalne | 24 2,5-calowe dyski Dell Express Flash NVMe P4600 1,6 TB U.2 |
| Karta Mellanox EDR | 2x karta Mellanox ConnectX-5 EDR (gniazda 1 i 8) |
| Zarządzanie zewnątrz-pasmowe | iDRAC9 Enterprise z kontrolerem Lifecycle Controller |
| Zasilacze | Dwa zasilacze 2000 W |
| Tabela 3 Konfiguracja oprogramowania (metadane i serwery pamięci masowej) | |
|---|---|
| BIOS | 2.2.11 |
| CPLD | 1.1.3 |
| System operacyjny | CentOS™ 7.6 |
| Wersja jądra | 3.10.0-957.el7.x86_64 |
| iDRAC | 3.34.34.34 |
| Narzędzie do zarządzania systemami | OpenManage Server Administrator 9.3.0-3407_A00 |
| Mellanox OFED | 4.5-1.0.1.0 |
| Dyski SSD NVMe | QDV1DP13 |
| * Narzędzie Intel ® Data Center | 3.0.19 |
| BeeGFS | 7.1.3 |
| Grafana | 6.3.2 |
| InfluxDB | 1.7.7 |
| Test porównawczy IOzone | 3.487 |
Szczegóły konfiguracji rozwiązania
Architektura BeeGFS obejmuje cztery główne usługi:
- Usługa zarządzania
- Usługa metadanych
- Usługi w zakresie pamięci masowej
- Usługa w zakresie systemów klienckich
Z wyjątkiem usługi klienckiej, która jest modułem jądra, usługi zarządzania, metadanych i pamięci masowej to procesy przestrzeni użytkownika. Rysunek 2 przedstawia, w jaki sposób architektura referencyjna rozwiązań Dell EMC Ready Solutions for HPC BeeGFS Storage mapuje się do ogólnej architektury systemu plików BeeGFS.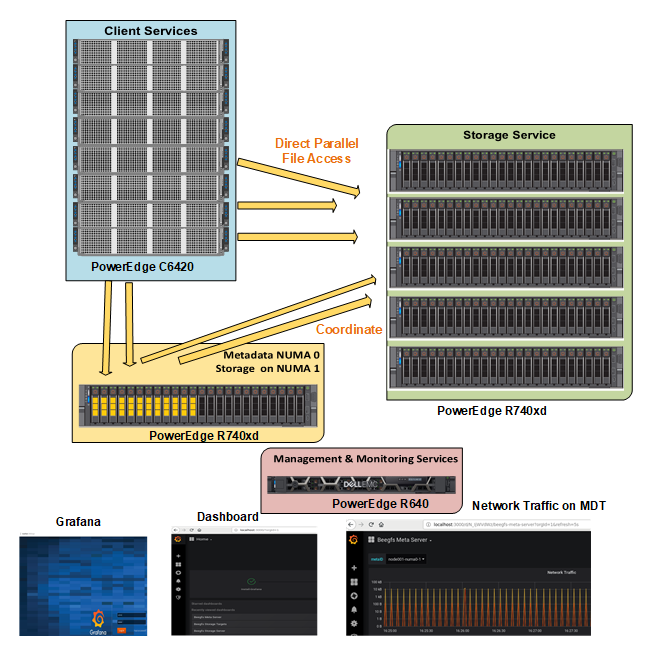
Rysunek 2. System plików BeeGFS na serwerze PowerEdge R740xd z dyskami SSD NVMe
Usługa zarządzania
Każdy system plików BeeGFS lub przestrzeń nazw ma tylko jedną usługę zarządzania. Usługa zarządzania jest pierwszą usługą, którą należy skonfigurować, ponieważ po skonfigurowaniu wszystkich innych usług muszą one zarejestrować się w usłudze zarządzania. Serwer zarządzania jest używany jako serwer zarządzający serwerem PowerEdge R640. Oprócz hostingu usługi zarządzania (beegfs-mgmtd.service), hostuje również usługę monitorowania (beegfs-mon.service), która gromadzi statystyki z systemu i dostarcza je użytkownikowi, korzystając z bazy danych z szeregów czasowych InfluxDB. W celu wizualizacji danych beegfs-mon zapewnia wstępnie zdefiniowane okienka Grafana, których można używać w konfiguracji fabrycznej. Serwer zarządzający wyposażony jest w 6 dysków twardych o pojemności 300 GB skonfigurowanych w macierzy RAID 10 dla systemu operacyjnego i InfluxDB.
Usługa metadanych
Usługa metadanych jest usługą skalowaną, co oznacza, że w systemie plików BeeGFS może znajdować się wiele usług metadanych. Jednak każda usługa metadanych ma dokładnie jeden klaster docelowy metadanych do przechowywania metadanych. W klastrze docelowym metadanych BeeGFS tworzy jeden plik metadanych na plik utworzony przez użytkownika. Metadane BeeGFS są rozproszone według katalogu. Usługa metadanych zapewnia informacje o przeplocie danych klientom i nie jest związana z dostępem do danych między otwarciem/zamknięciem pliku.
Dyski PowerEdge R740xd z 24 dyskami Intel P4600 1,6 TB NVMe służą do przechowywania metadanych. Ponieważ wymagania dotyczące pojemności pamięci masowej dla metadanych BeeGFS są bardzo małe, zamiast korzystać z dedykowanego serwera metadanych, tylko 12 dysków w strefie NUMA 0 zostało użytych do hostowania kart Meta-DataT(MDT), podczas gdy pozostałe 12 dysków w strefie NUMA hosta Sprzechowuje Targety (ST).
Rysunek 3 przedstawia serwer metadanych. 12 dysków zawartych w żółtym prostokącie do MTD w strefie NUMA 0, podczas gdy 12 dysków zawartych w zielonym prostokącie to ST w strefie NUMA 1. Taka konfiguracja nie tylko pozwala uniknąć problemów z NUMA, ale także zapewnia wystarczającą ilość pamięci masowej metadanych, aby w razie potrzeby ułatwić skalowanie pojemności i wydajności.
Rysunek 3: Serwer metadanych
Rysunek 4 przedstawia konfigurację macierzy RAID serwera metadanych. Rysunek przedstawia, w jaki sposób na serwerze metadanych dyski w strefie NUMA 0 hostują klastry MDT, a klastry w strefie NUMA 1 hostują dane pamięci masowej, podczas gdy serwery pamięci masowej hostują klastry ST w obu strefach NUMA.
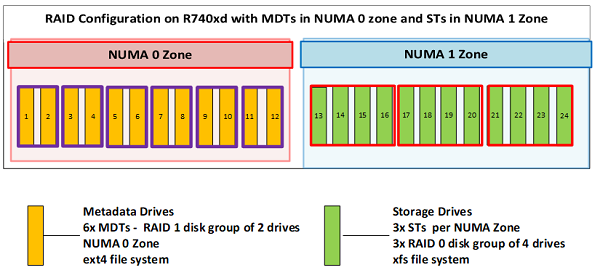
Rysunek 4: Konfiguracja dysków na serwerze
metadanych 12 dysków używanych jako metadane jest skonfigurowanych jako 6 grup dysków RAID 1 składających się z dwóch dysków, z których każdy służy jako MDT. Uruchomiono sześć usług metadanych, z których każda obsługuje jeden klaster MDT. Pozostałe 12 dysków skonfigurowano w 3 grupach dysków RAID 0, po 4 dyski każdy. W strefie NUMA 1 uruchomione są trzy usługi pamięci masowej, po jednej dla każdego klastra ST. W ten sposób serwer, który wspólnie obsługuje metadane i klastry docelowe pamięci masowej, wyposażony jest w 6 klastrów MDT i 3 klastry ST. Obsługuje również sześć usług metadanych i trzy usługi pamięci masowej. Każdy klaster MDT to system plików ext4 oparty na konfiguracji RAID 1. Klastry ST są oparte na systemie plików XFS skonfigurowanym w macierzy RAID 0.
Usługi w zakresie pamięci masowej
Podobnie jak usługa metadanych, usługa pamięci masowej jest również usługą skalowalną. W systemie plików BeeGFS może być wiele instancji usługi pamięci masowej. Jednak w przeciwieństwie do usługi metadanych może istnieć kilka klastrów docelowych pamięci masowej na usługę pamięci masowej. Usługa magazynu przechowuje rozłożoną zawartość plików użytkownika, nazywaną również plikami fragmentów danych.
Rysunek 5 przedstawia 5 serwerów PowerEdge R740xd używanych jako serwery pamięci masowej.
Rysunek 5: Dedykowane serwery
pamięci masowej Każdy serwer pamięci masowej jest skonfigurowany z 6 grupami RAID 0, każda składająca się z czterech dysków, hostując w ten sposób 6 ST na serwer (3 na strefę NUMA), jak pokazano na rysunku 6 poniżej: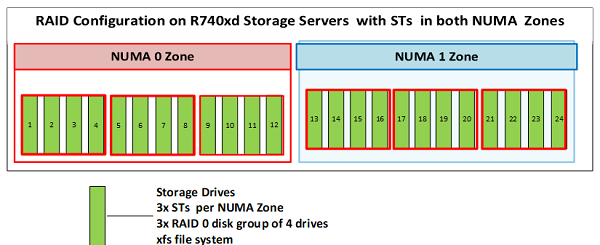 Rysunek 6: Konfiguracja dysków w serwerach
Rysunek 6: Konfiguracja dysków w serwerach
pamięci masowej Łącznie podstawowa konfiguracja architektury referencyjnej obsługuje 6 klastrów MDT i 33 klastry ST. Posiadanie pięciu dedykowanych serwerów pamięci masowej zapewnia 211 TB pojemności i 190 TiB pojemności użytecznej. Szacowana pojemność użyteczna w TiB = liczba dysków x pojemność na dysk w TB x 0,99 (zapas systemu plików) x (10^12/2^40). Byłoby to idealne rozwiązanie jako rozwiązanie umożliwiające zapis średniej klasy z wystarczającą ilością pamięci masowej metadanych, aby ułatwić dodanie większej liczby serwerów pamięci masowej w miarę wzrostu wymagań dotyczących pojemności.
W związku z następującymi czynnikami wybrano konfigurację macierzy RAID 0 dla celów pamięci masowej w konfiguracji macierzy RAID 10.
- Wydajność zapisu została zmierzona za pomocą polecenia dd poprzez utworzenie pliku 10 GB o rozmiarze bloku 1 MB i bezpośredniego modułu we/wy dla danych. W przypadku urządzeń RAID 0 średnia wartość to około 5,1 GB/s dla każdego urządzenia, podczas gdy w przypadku urządzeń RAID 10 średnia dla każdego urządzenia wynosiła 3,4 GB/s.
- Testy porównawcze StorageBench wykazały, że maksymalna przepustowość to 5,5 GB/s w konfiguracji macierzy RAID 0, podczas gdy w konfiguracji macierzy RAID 10 wynosi ona 3,4 GB/s. Wyniki te są podobne do wyników uzyskanych przy użyciu poleceń dd.
- Macierz RAID 10 zapewnia 50% wykorzystania pojemności dysku i podobne zmniejszenie wydajności zapisu o 50%. Użycie macierzy RAID 10 jest kosztownym sposobem na uzyskanie nadmiarowości pamięci masowej.
- Dyski NVMe są kosztowne i oferują szybkość, które najlepiej sprawdzają się w konfiguracji macierzy RAID 0
Usługa w zakresie systemów klienckich
Moduł klienta BeeGFS należy załadować na wszystkie hosty, które muszą uzyskać dostęp do systemu plików BeeGFS. Po załadowaniu klienta beegfs instaluje on systemy plików zdefiniowane wpliku/etc/beegfs/beegfs-mounts.conf zamiast typowego podejścia opartego na /etc/fstab. Przyjęcie tego podejścia powoduje uruchomienie klienta beegfs, podobnie jak innych usług Linux za pośrednictwem skryptu rozruchowego usługi. Umożliwia ono również automatyczną ponowną kompilację modułu klienta BeeGFS po aktualizacji systemu.
Po załadowaniu modułu klienta instaluje on systemy plików zdefiniowane w pliku beegfs-mounts.conf. Istnieje możliwość zainstalowania wielu instancji beegfs na tym samym kliencie, jak pokazano poniżej:
$ cat /etc/beegfs/beegfs-mounts.conf /mnt/beegfs-medium /etc/beegfs/beegfs-client-medium.conf /mnt/beegfs-small /etc/beegfs/beegfs-client-small.conf
Powyższy przykład pokazuje dwa różne systemy plików zainstalowane na tym samym kliencie. Do celów tych testów jako klientów użyto 32 węzły C6420.
R740xd, 24 dyski NVMe, szczegóły dotyczące mapowania procesora
W konfiguracji 24xNVMe serwera PowerEdge R740xd na płycie backplane znajdują się dwie karty Bridge X16 NVMe, które obsługują przełącznik PCIe, który wentyluje i zasila dyski (dyski z napędem x4) z przodu, jak pokazano na rysunku 7 poniżej:
Rysunek 7. Szczegóły dotyczące R740xd, 24x NVMe podczas mapowania procesora
W architekturze NUMA pamięć systemowa jest podzielona na strefy zwane węzłami, które są przydzielane do procesorów lub gniazd. Dostęp do pamięci, która jest lokalna dla procesora jest szybszy niż pamięć podłączona do zdalnych procesorów w systemie. Aplikacja wielowątkowa zazwyczaj działa najlepiej, gdy wątki mają dostęp do pamięci w tym samym węźle NUMA. Wpływ na wydajność spowodowany brakami ze strony NUMA jest znaczny, zwykle zaczyna się od 10% wydajności lub wyższej. W celu poprawy wydajności usługi są skonfigurowane do korzystania z określonych stref NUMA w celu uniknięcia niepotrzebnego korzystania z łączy krzyżowych UPI, co zmniejsza opóźnienia. Każda strefa NUMA obsługuje 12 dysków i korzysta z jednego z dwóch interfejsów EDR InfiniBand na serwerach. Tę separację NUMA uzyskuje się poprzez ręczne skonfigurowanie zbilansowania NUMA poprzez utworzenie niestandardowych plików jednostki systemd i skonfigurowanie multihostingu. Dlatego automatyczne zbilansowanie NUMA jest wyłączone, jak pokazano poniżej:
# cat /proc/sys/kernel/numa_balancing 0
Rysunek 8 przedstawia stanowisko testowe, w którym wyróżniono połączenia InfiniBand ze strefą NUMA. Każdy serwer ma dwa łącza IP, a ruch przez strefę NUMA 0 jest przekazywany przez interfejs IB0, podczas gdy ruch przez strefę NUMA 1 jest obsługiwany przez interfejs IB1.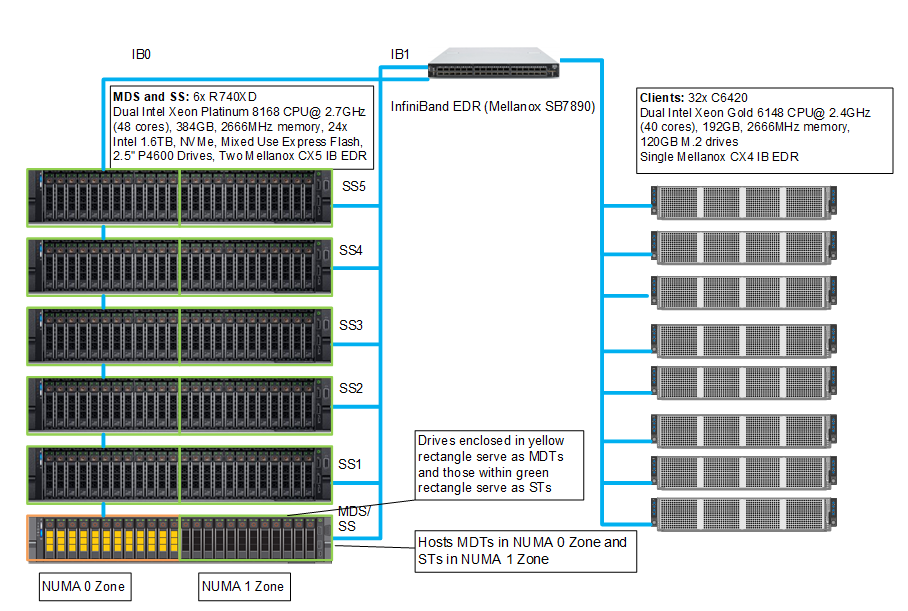
Rysunek 8: Konfiguracja stanowiska testowego
Charakterystyka wydajności
W tej sekcji przedstawiono ocenę wydajności, która pomaga scharakteryzować rozwiązanie Dell EMC Ready Solution dla rozwiązania pamięci masowej HPC BeeGFS o wysokiej wydajności. Aby uzyskać więcej informacji i aktualizacje, należy poszukać opracowania, które zostanie opublikowane później. Oceny wydajności systemu dokonano przy użyciu testu porównawczego IOzone. Rozwiązanie zostało przetestowane pod kątem sekwencyjnej przepustowości odczytu i zapisu oraz losowego odczytu i zapisu IOPS. Tabela 4 przedstawia konfigurację serwerów C6420, które były używane jako klienty BeeGFS w badaniach wydajności w tym blogu.
| Tabela 4 Konfiguracja klienta | |
|---|---|
| Klienty | 32 węzły obliczeniowe Dell PowerEdge C6420 |
| BIOS | 2.2.9 |
| Procesor | 2 procesory Intel Xeon Gold 6148, 2,40 GHz, 20 rdzeni na procesor |
| Pamięć | 12 modułów DIMM DDR4 2666 MT/s o pojemności 16 GB – 192 GB |
| Karta BOSS | 2 dyski rozruchowe M.2 120 GB w macierzy RAID 1 dla systemu operacyjnego |
| System operacyjny | Red Hat Enterprise Linux Server, wersja 7.6 |
| Wersja jądra | 3.10.0-957.el7.x86_64 |
| Połączenia | Karta 1x Mellanox ConnectX-4 EDR |
| Wersja OFED | 4.5-1.0.1.0 |
Sekwencyjne zapisy i odczyty N-N
Do oceny sekwencyjnego odczytu i zapisu użyto testu porównawczego IOzone w trybie sekwencyjnego odczytu i zapisu. Testy przeprowadzono na wielu wątkach, rozpoczynając od 1 wątku, a następnie zwiększając liczbę wątków dwukrotnie, aż do 1024. Przy każdej liczbie wątków wygenerowano taką samą liczbę plików, ponieważ ten test działa dla jednego pliku w wątku, lub przypadku klientów N do pliku N (N-N). Procesy były rozproszone między 32 fizycznymi węzłami klienta w formie algorytmu karuzelowego lub cyklicznego, tak aby żądania były równomiernie rozproszone i zapewniały równoważenie obciążenia. Wybrano łączny rozmiar pliku wynoszący 8 TB, który został równo podzielony pomiędzy liczbę wątków w danym teście. Łączny rozmiar pliku został wybrany na tyle duży, aby zminimalizować skutki buforowania z serwerów i klientów BeeGFS. IOzone został uruchomiony w połączonym trybie zapisu, a następnie odczytu (-i 0, -i 1), aby umożliwić koordynację granic między operacjami. W przypadku tych testów i wyników użyliśmy rozmiaru rekordu 1 MB przy każdym uruchomieniu. Polecenia używane do sekwencyjnych testów N-N podano poniżej:
Sekwencyjne zapisy i odczyty:
iozone -i 0 -i 1 -c -e -w -r 1m -I -s $Size -t $Thread -+n -+m /path/to/threadlist
Pamięci podręczne systemu operacyjnego zostały również porzucone lub wyczyszczone w węzłach klienta między iteracjami oraz między testami zapisu i odczytu poprzez uruchomienie polecenia:
# sync && echo 3 > /proc/sys/vm/drop_caches
Domyślna liczba przeplotów dla beegfs wynosi 4. Jednak rozmiar fragmentu i liczbę obiektów docelowych na plik można skonfigurować na podstawie każdego katalogu. W przypadku wszystkich tych testów wybrano rozmiar Stripe BeeGFS jako 2 MB, a liczbę przeplotów wybrano jako 3, ponieważ dla strefy NUMA wybrano trzy obiekty docelowe, jak pokazano poniżej:
$ beegfs-ctl --getentryinfo --mount=/mnt/beegfs /mnt/beegfs/benchmark --verbose EntryID: 0-5D9BA1BC-1 ParentID: root Metadata node: node001-numa0-4 [ID: 4] Stripe pattern details: + Type: RAID0 + Chunksize: 2M + Number of storage targets: desired: 3 + Storage Pool: 1 (Default) Inode hash path: 7/5E/0-5D9BA1BC-1
Transparentne ogromne strony zostały wyłączone, a na serwerach pamięci masowej i metadanych są dostępne następujące opcje dopasowywania:
vm.dirty_background_ratio = 5 vm.dirty_ratio = 20 vm.min_free_kbytes = 262144 vm.vfs_cache_pressure = 50 vm.zone_reclaim_mode = 2 kernel.numa_balancing = 0
Poza powyższymi, użyto następujących opcji dopasowywania BeeGFS:
tuneTargetChooserParametr ustawiono na "roundrobin" w pliku konfiguracyjnym metadanychtuneNumWorkersparametr został ustawiony na 24 dla metadanych i 32 dla pamięci masowejconnMaxInternodeNumparametr został ustawiony na 32 dla metadanych i 12 dla pamięci masowej oraz 24 dla klientów
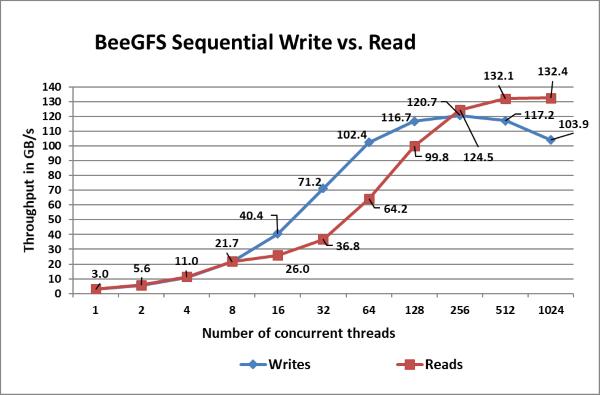
Rysunek 9: Sekwencyjny łączny rozmiar pliku IOzone 8 TB.
Na rysunku 9 widać, że najwyższa wydajność odczytu wynosi 132 GB/s przy 1024 wątkach, a zapis szczytowy wynosi 121 GB/s przy 256 wątkach. Każdy dysk może zapewnić maksymalną wydajność odczytu 3,2 GB/s i maksymalną wydajność zapisu 1,3 GB/s, co umożliwia teoretyczny szczytowy wzrost 422 GB/s do odczytu i 172 GB/s do zapisu. Jednak tutaj sieć jest czynnikiem ograniczającym. Mamy łącznie 11 łączy EDR InfiniBand dla serwerów pamięci masowej w konfiguracji. Każde łącze może zapewnić teoretyczną maksymalną wydajność 12,4 GB/s, co zapewnia teoretyczną maksymalną wydajność 136,4 GB/s. Maksymalna wydajność odczytu i zapisu to odpowiednio 97% i 89% teoretycznej najwyższej wydajności.
Wydajność zapisu jednego wątku wynosi ok. 3 GB/s i jest odczytywana przy ok. 3 GB/s. Zauważamy, że wydajność zapisu jest skalowana liniowo, osiąga maksymalną wartość 256 wątków, a następnie zaczyna zmniejszać się. Przy mniejszej liczbie wątków wydajność odczytu i zapisu jest taka sama. Ponieważ do ośmiu wątków mamy ośmiu klientów zapisujących osiem plików w 24 celach, co oznacza, że nie wszystkie obiekty docelowe pamięci masowej są w pełni wykorzystywane. Mamy 33 obiekty docelowe pamięci masowej w systemie i dlatego do pełnego wykorzystania wszystkich serwerów potrzebne jest co najmniej 11 wątków. Wydajność odczytu rejestruje stały wzrost liniowy wraz ze wzrostem liczby równoczesnych wątków i zauważamy prawie podobną wydajność w przypadku wątków 512 i 1024.
Zauważamy również, że wydajność odczytu jest niższa niż zapisy dla liczby wątków od 16 do 128, a następnie wydajność odczytu zaczyna się skalować. Dzieje się tak, ponieważ podczas gdy operacja odczytu PCIe jest operacją nieopublikowaną, wymagającą zarówno żądania, jak i ukończenia, operacja zapisu PCIe jest operacją „fire and forget”. Po przekazaniu pakietu warstwy transakcji warstwie danych do warstwy łącza danych operacja zostanie zakończona. Operacja zapisu jest operacją „opublikowaną”, która składa się wyłącznie z żądania.
Przepustowość odczytu jest zazwyczaj niższa niż przepustowość zapisu, ponieważ odczyty wymagają dwóch transakcji zamiast jednego zapisu dla takiej samej ilości danych. PcI Express używa modelu podzielonej transakcji do odczytu. Transakcja odczytu obejmuje następujące czynności:
- Moduł żądający wysyła żądanie odczytu pamięci (MRR).
- Moduł completer wysyła potwierdzenie do MRR.
- Moduł completer zwraca zakończenie z danymi.
Przepustowość odczytu zależy od opóźnienia między czasem wystawienia żądania odczytu a czasem, przez jaki moduł completer zwraca dane. Jeśli jednak aplikacja wydaje wystarczającą liczbę żądań odczytu, aby uwzględnić to opóźnienie, przepustowość jest zmaksymalizowana. Z tego powodu, mimo że wydajność odczytu jest mniejsza niż wydajność zapisu z 16 wątków do 128 wątków, mierzymy zwiększoną przepustowość po zwiększeniu liczby żądań. Niższa przepustowość jest mierzona, gdy moduł żądający czeka na zakończenie przed wystawieniem kolejnych żądań. W przypadku wystawienia wielu żądań w celu amortyzacji opóźnienia po powrocie pierwszych danych zarejestrowana jest większa przepustowość.
Losowe zapisy i odczyty N-N
Aby ocenić wydajność losowego we/wy, zastosowano IOzone w trybie losowym. Testy przeprowadzono na liczbie wątków od 4 wątków do 1024 wątków. Opcja Direct IO (-I) została użyta do uruchomienia IOzone, dzięki czemu wszystkie operacje pomijają buforową pamięć podręczną i trafiają bezpośrednio do dysku. Wykorzystano liczbę przeplotów BeeGFS 3 i rozmiar fragmentu 2 MB. Rozmiar żądania 4 KiB jest używany w IOzone. Wydajność jest mierzona w operacjach we/wy na sekundę (IOPS). Pamięci podręczne systemu operacyjnego zostały porzucone między uruchomieniami na serwerach BeeGFS i klientach BeeGFS. Poniższe polecenie służy do wykonywania losowych zapisów i odczytów:
Odczyty i zapisy losowe:
iozone -i 2 -w -c -O -I -r 4K -s $Size -t $Thread -+n -+m /path/to/threadlist
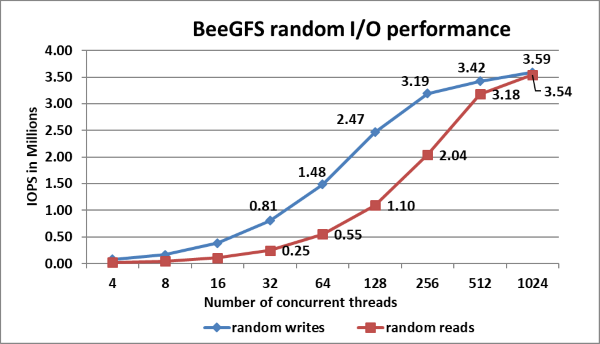
Rysunek 10. Wydajność odczytu i zapisu losowego przy użyciu IOzone z łącznym rozmiarem pliku 8 TB.
Jak pokazano na rysunku 10, szczytowa wartość zapisu losowego wynosi ~3,6 miliona operacji we/wy na sekundę przy 512 wątkach, a szczytowa liczba losowych odczytów wynosi ~3,5 miliona operacji we/wy na sekundę przy 1024 wątkach. Wydajność zapisu i odczytu wykazuje wyższą wydajność w przypadku większej liczby żądań we/wy. Dzieje się tak, ponieważ standard NVMe obsługuje kolejkę we/wy do 64K i do 64K poleceń na kolejkę. Ta duża pula kolejek NVMe zapewnia wyższy poziom równoległości we/wy, a zatem zauważamy, że IOPS przekracza 3 miliony.
Wnioski i przyszłe prace
Ten blog informuje o wprowadzeniu rozwiązania pamięci masowej Dell EMC High Performance BeeGFS i podkreśla jego charakterystykę wydajności. Rozwiązanie ma szczytową wydajność odczytu i zapisu (odpowiednio ok. 132 GB/s i ok. 121 GB/s), a zapis losowy osiąga wartość ok. 3,6 mln operacji we/wy i odczytów losowych wynosi ok. 3,5 mln IOPS.
Ten blog jest częścią pierwszej części „Rozwiązania pamięci masowej BeeGFS”, która została zaprojektowana z myślą o przestrzeni do zapisu z dużą wydajnością. Zapoznaj się z drugą częścią bloga, która opisuje, w jaki sposób można skalować rozwiązanie poprzez zwiększenie liczby serwerów w celu zwiększenia wydajności i pojemności. W części 3 bloga omówiono dodatkowe funkcje BeeGFS i zwrócono uwagę na zastosowanie "StorageBench", wbudowanego testu porównawczego docelowych pamięci masowej BeeGFS.
W ramach kolejnych kroków opublikujemy później opracowanie z wydajnością metadanych i wydajnością IOR wątków N do jednego pliku, a także z dodatkowymi szczegółami dotyczącymi zagadnień projektowych, dostrajania i konfiguracji.
Odniesienia
[1] Dokumentacja BeeGFS: https://www.beegfs.io/wiki/
[2] Jak podłączyć dwa interfejsy w tej samej podsieci: https://access.redhat.com/solutions/30564