PowerEdge:適用於 HPC BeeGFS 高效能儲存的 Dell Ready Solutions
Summary: 適用於 HPC BeeGFS 高效能儲存的 Dell Ready Solutions
Instructions
由 Dell HPC 與 AI 創新實驗室的 Nirmala Sundararajan 於 2019 年 11 月撰寫的文章
目錄
簡介
Dell HPC 團隊隆重宣佈推出「適用於 HPC BeeGFS 儲存裝置的 Dell EMC Ready Solutions」,這是 HPC 儲存產品系列的最新項目。此解決方案使用 R740xd 伺服器,每個伺服器搭載 24 個 Intel P4600 1.6TB NVMe、混合用途 Express Flash 磁碟機和兩個 Mellanox ConnectX-5 InfiniBand EDR 配接卡。在這樣的 24 個 NVMe 磁碟機組態中,12x NVMe SSD 連接至 PCIe 交換器,且每個交換器均使用 x16 PCIe 延伸卡連接至一個 CPU。此外,每個 IB 介面都連接至一個 CPU。這種將每個 CPU 連接至一個 InfiniBand 配接卡並處理 12 個 NVMe SSD 的均衡組態,可確保處理器在處理往返 NVMe 磁碟機的 I/O 要求時,能擁有最高的效能。
該解決方案的重點是高性能 I/O,它被設計為高速暫存解決方案。解決方案的核心是使用高速 NVMe SSD,從區塊層 級解決排程器和佇列的瓶頸 ,提供高頻寬和低延遲。BeeGFS 檔案系統也支援高彙總 I/O 輸送量。
解決方案參考架構
圖 1 顯示解決方案的參考架構。管理伺服器僅會使用乙太網路連接至中繼資料和儲存伺服器。每個中繼資料和儲存伺服器都有兩個 InfiniBand 連結,並透過乙太網路連線至私有網路。用戶端只有一個 InfiniBand 連結,並通過乙太網連接到專用介面。
圖 1: 適用於 HPC BeeGFS 儲存裝置的 Dell Ready Solutions - 參考架構
硬體與軟體組態
表 1 和 2 分別說明管理伺服器和中繼資料/儲存伺服器的硬體規格。表 3 說明解決方案使用的軟體版本。
| 表 1 PowerEdge R640 組態 (管理伺服器) | |
|---|---|
| 伺服器 | Dell PowerEdge R640 |
| 處理器 | 2 個 Intel Xeon Gold 5218 2.3 GHz,16 核心 |
| 記憶體 | 12 條 8GB DDR4 2666MT/s DIMMs - 96GB |
| 本機磁碟 | 6 個 300GB 15K RPM SAS 2.5 吋 HDD |
| RAID 控制器 | PERC H740P 整合式 RAID 控制器 |
| 頻外管理 | iDRAC9 Enterprise 與 Lifecycle Controller |
| 電源供應器 | 雙 1100W 電源供應單元 |
| BIOS 版本 | 2.2.11 |
| 作業系統 | CentOS™ 7.6 |
| 核心版本 | 3.10.0-957.27.2.el7.x86_64 |
| 表 2 PowerEdge R740xd 組態 (中繼資料與儲存伺服器) | |
|---|---|
| 伺服器 | Dell EMC PowerEdge R740xd |
| 處理器 | 2 個 Intel Xeon Platinum 8268 CPU @ 2.90GHz,24 核心 |
| 記憶體 | 12 條 32GB DDR4 2933MT/s DIMMs - 384GB |
| BOSS 介面卡 | 2 個 240GB M.2 SATA SSD,採用 RAID 1,用於作業系統 |
| 本機磁碟機 | 24 個 Dell Express Flash NVMe P4600 1.6TB 2.5 吋 U.2 |
| Mellanox EDR 介面卡 | 2 張 Mellanox ConnectX-5 EDR 介面卡 (插槽 1 與 8) |
| 頻外管理 | iDRAC9 Enterprise 與 Lifecycle Controller |
| 電源供應器 | 雙 2000W 電源供應單元 |
| 表 3 軟體組態 (中繼資料和儲存伺服器) | |
|---|---|
| BIOS | 2.2.11 |
| CPLD | 1.1.3 |
| 作業系統 | CentOS™ 7.6 |
| 核心版本 | 3.10.0-957.el7.x86_64 |
| iDRAC | 3.34.34.34 |
| 系統管理工具 | OpenManage Server Administrator 9.3.0-3407_A00 |
| Mellanox OFED | 4.5-1.0.1.0 |
| NVMe SSD | QDV1DP13 |
| *Intel ® 資料中心工具 | 3.0.19 |
| BeeGFS | 7.1.3 |
| Grafana | 6.3.2 |
| InfluxDB | 1.7.7 |
| IOzone 效能指標 | 3.487 |
解決方案組態詳細資料
BeeGFS 架構包含四個主要服務:
- 管理服務
- 中繼資料服務
- 儲存服務
- 用戶端服務
除了用戶端服務為核心模組外,管理、中繼資料和儲存服務均為使用者空間程序。圖 2 說明適用於 HPC BeeGFS 儲存裝置的 Dell EMC Ready Solutions 參考架構如何對應到 BeeGFS 檔案系統的一般架構。
圖 2: 在搭載 NVMe SSD 之 PowerEdge R740xd 上的 BeeGFS 檔案系統
管理服務
每個 BeeGFS 檔案系統或命名空間僅有一項管理服務。管理服務是必須設定的第一項服務,因為在我們設定所有其他服務時,都需要向管理服務註冊。使用 PowerEdge R640 作為管理伺服器。除了代管管理服務 (beegfs-mgmtd.service) 之外,還會代管監控服務 (beegfs-mon.service),該服務會使用時間系列資料庫 InfluxDB,從系統收集統計資料並提供給使用者。為了視覺化資料,beegfs-mon 提供開箱即可使用的預先定義 Grafana 窗格。管理伺服器具有設定為 RAID 10 的 6 個 300GB HDD,可用於作業系統和 InfluxDB。
中繼資料服務
中繼資料服務是一種擴充服務,也就是說,BeeGFS 檔案系統中可能有許多中繼資料服務。但是,每個中繼資料服務都僅有一個儲存中繼資料的中繼資料目標。在中繼資料目標上,BeeGFS 會針對每個使用者建立的檔案建立一個中繼資料檔案。BeeGFS 中繼資料會以每個目錄的方式分配。中繼資料服務會為用戶端提供資料等量分割資訊,且與檔案開啟/關閉之間的資料存取無關。
PowerEdge R740xd 搭載 24 個 Intel P4600 1.6TB NVMe 磁碟機,用於儲存中繼資料。由於 BeeGFS 中繼資料的儲存容量需求極小,因此沒有使用專用的中繼資料伺服器,而是將 NUMA 區域 0 上的 12 個磁碟機用於代管 中繼資料Targets (MDT),而 NUMA 區域主機 S儲存 Targets (ST) 上的其餘 12 個磁碟機則
使用。圖 3 顯示了元數據伺服器。位於黃色矩形中的 12 個磁碟機是 NUMA 區域 0 中的 MDT,而位於綠色矩形中的 12 個磁碟機則是 NUMA 區域 1 中的 ST。此組態不僅可避免 NUMA 問題,還能提供足夠的中繼資料儲存空間,以視需求擴充容量和效能。
圖 3: 中繼資料伺服器
圖 4 顯示中繼資料伺服器的 RAID 組態。圖片中強調了在中繼資料伺服器中 NUMA 區域 0 中的磁碟機代管 MDT,而 NUMA 區域 1 中的磁碟機則代管儲存資料,而儲存伺服器則在兩個 NUMA 區域中代管 ST。

圖 4: 中繼資料伺服器
中磁碟機的設定 用於中繼資料的 12 個磁碟機是配置為 6 個包含兩個磁碟機的 RAID 1 磁碟群組,每個磁碟機都可作為 MDT。有六個元數據服務正在運行,每個服務處理一個 MDT。其餘 12 個儲存磁碟機設定為 3 個各包含四個磁碟機的 RAID 0 磁碟群組。NUMA 1 區有三個儲存服務,為每個 ST 提供一個服務。因此,共同代管中繼資料和儲存目標的伺服器有 6 個 MDT 和 3 個 ST。它也執行六個中繼資料服務和三個儲存服務。每個 MDT 都是以 RAID 1 組態為基礎的 ext4 檔案系統。ST 是以設定為 RAID 0 的 XFS 檔案系統為基礎。
儲存服務
與中繼資料服務相同,儲存服務也是一種擴充服務。BeeGFS 檔案系統中可能有許多儲存服務的例項。不過這與中繼資料服務不同,每個儲存服務都可能有數個儲存目標。存儲服務存儲條帶化用戶文件內容,也稱為數據塊檔。
圖 5 顯示用作儲存伺服器的 5 部 PowerEdge R740xd 伺服器。
圖 5: 專用儲存伺服器
每個儲存伺服器都配置有 6 個 RAID 0 組,每個組為四個驅動器,因此每個伺服器託管 6 個 ST (每個 NUMA 區域 3 個),如圖 6 所示,如下所示: 圖 6: 儲存伺服器
圖 6: 儲存伺服器
中的磁碟機組態 基本參考架構組態總共擁有 6 個 MDT 和 33 個 ST。擁有五個專用儲存伺服器,可提供 211 TB 的原始容量和 190TiB 的可用容量。預估可用容量 TiB = 磁碟機數量 x 每個磁碟機的容量 TB x 0.99 (檔案系統遇存量) x (10^12/2^40)。這是理想的中範圍暫存解決方案,具備足夠的中繼資料儲存空間,可隨著容量需求增加而新增更多儲存伺服器。
基於下列因素,為儲存目標選擇 RAID 0 組態,而不是 RAID 10 組態。
- 寫入效能使用 dd 命令測量,透過建立區塊大小為 1MB 的 10GB 檔案,以及直接的資料 I/O。在 RAID 0 裝置上,每個裝置的平均寫入效能約為 5.1 GB/秒,而在 RAID 10 裝置上,每個裝置的平均寫入效能為 3.4GB/秒。
- StorageBench 效能指標測試顯示,RAID 0 組態的最大輸送量為 5.5 GB/秒,而 RAID 10 組態則為 3.4 GB/秒。這些結果與使用 dd 命令取得的結果類似。
- RAID 10 能提供 50% 的磁碟容量使用率,而寫入效能將降低約 50%。透過 RAID 10 進行儲存冗餘十分昂貴。
- NVMe 磁碟機價格昂貴,並可在 RAID 0 組態中提供最佳加速效果
用戶端服務
BeeGFS 用戶端模組必須載入至所有必須存取 BeeGFS 檔案系統的主機。載入 beegfs-client 時,它會掛接在/etc/beegfs/beegfs-mounts.conf 檔案中定義的檔案系統,而非根據 /etc/fstab 的常用方法。採用此方法會啟動 beegfs-client,與任何透過服務啟動指令檔啟動的其他 Linux 服務相同。這還會使 BeeGFS 用戶端模組在系統更新後自動重新編譯。
載入用戶端模組後,它會掛接 在 beegfs-mounts.conf 中定義的檔案系統。可以在同一用戶端上掛接多個 beegfs 例項,如下所示:
$ cat /etc/beegfs/beegfs-mounts.conf /mnt/beegfs-medium /etc/beegfs/beegfs-client-medium.conf /mnt/beegfs-small /etc/beegfs/beegfs-client-small.conf
上述範例顯示在同一用戶端上安裝兩種不同的檔案系統。為了進行這項測試,我們使用 32 個 C6420 節點作為用戶端。
R740xd,24 個 NVMe 磁碟機,CPU 對應詳細資料
在 PowerEdge R740xd 伺服器的 24 個 NVMe 組態中,有兩張 x16 NVMe 橋接卡,為背板面上的 PCIe 交換器提供資料,分散傳輸至前方的磁碟機 (磁碟機為 x4),如下圖 7 所示:
圖 7: 搭載 24 個 NVMe 的 R740xd CPU 對應詳細資料
在非一致記憶體存取 (Non-Uniform Memory Access,NUMA) 中,系統記憶體會分為稱作「節點」的區域,分派至 CPU 或插槽。存取 CPU 本機記憶體時,速度比連接至系統上的遠端 CPU 記憶體更快。當執行緒在相同的 NUMA 節點上存取記憶體時,執行緒應用程式通常可發揮最佳效能。NUMA 遺失對效能的影響相當顯著,通常會從 10% 或更高的效能影響開始。為改善效能,服務已設定為使用特定的 NUMA 區域,以避免使用不必要的 UPI 跨插槽連結,從而減少延遲。每個 NUMA 區域會處理 12 個磁碟機,並使用伺服器上兩個 InfiniBand EDR 介面的其中一個。這樣的 NUMA 分隔是透過手動設定 NUMA 平衡達成,建立自訂的系統單位檔案,以及設定多重主目錄。因此會停用自動 NUMA 平衡,如下所示:
# cat /proc/sys/kernel/numa_balancing 0
圖 8 顯示試驗平台,強調顯示 InfiniBand 至 NUMA 區域的連線。每個伺服器都有兩個 IP 連結,通過 NUMA 0 區域的流量由介面 IB0 處理,而通過 NUMA 1 區域的流量則由介面 IB1 處理。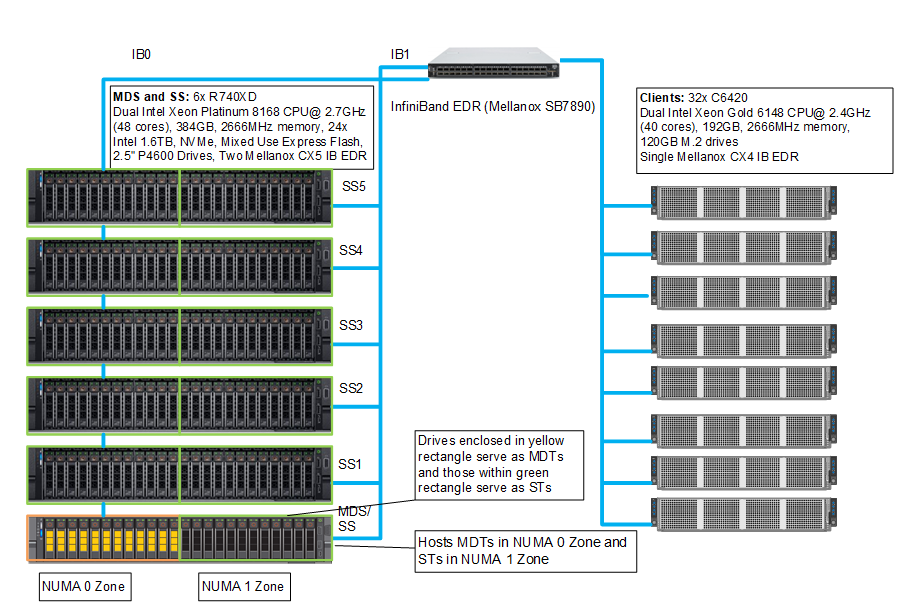
圖 8: 試驗平台組態
效能特性
本節提供效能評估,協助說明適用於 HPC BeeGFS 高效能儲存的 Dell EMC 就緒解決方案特性。如需進一步的詳細資料和更新,請查看將於之後發佈的白皮書。系統效能是使用 IOzone 效能指標進行評估。此解決方案經過了循序讀取和寫入輸送量,以及隨機讀取和寫入 IOPS 的測試。表 4 說明在進行本部落格中的效能研究時,作為 BeeGFS 用戶端的 C6420 伺服器組態。
| 表 4 用戶端組態 | |
|---|---|
| 用戶端 | 32 個 Dell PowerEdge C6420 運算節點 |
| BIOS | 2.2.9 |
| 處理器 | 2 個 Intel Xeon Gold 6148 CPU @ 2.40GHz,每顆處理器 20 個核心 |
| 記憶體 | 12 條 16GB DDR4 2666 MT/s DIMMs - 192GB |
| BOSS 介面卡 | 2 個 120GB M.2 開機磁碟機,採用 RAID 1,用於作業系統 |
| 作業系統 | Red Hat Enterprise Linux Server 7.6 版 |
| 核心版本 | 3.10.0-957.el7.x86_64 |
| 互聯 | 1 個 Mellanox ConnectX-4 EDR 介面卡 |
| OFED 版本 | 4.5-1.0.1.0 |
循序寫入和讀取 N-N
為了評估循序讀取和寫入效能,我們使用了循序讀取和寫入模式的 IOzone 效能指標。這些測試是從單線程開始,以 2 的次方增加,最多 1024 個線程,對多線程計數進行。在每個執行緒計數中,會產生相同的檔案數量,因為此測試會在每個執行緒針對一個檔案,或是 N 用戶端對 N 個檔案 (N-N) 的方式運作。此程序會以循環制或週期式的方式分佈在 32 個實體用戶端節點中,因此要求會平均分佈,並實現負載平衡。選取的彙總檔案大小為 8TB,在任何指定的測試中,此檔案會平均分配給執行緒。選擇的彙總檔案大小足以將來自伺服器和 BeeGFS 用戶端的快取影響降至最低。以寫入然後讀取 (-i 0, -i 1) 的合併模式執行 IOzone,使其可協調作業之間的邊界。在此測試和結果中,我們每次執行都使用 1MB 的記錄大小。用於執行順序 N-N 測試的命令如下:
循序寫入和讀取:
iozone -i 0 -i 1 -c -e -w -r 1m -I -s $Size -t $Thread -+n -+m /path/to/threadlist
執行以下命令,在每次迭代和讀寫測試之間清除或清理用戶端節點間的作業系統快取:
# sync && echo 3 > /proc/sys/vm/drop_caches
Beegfs 的預設 stripe 計數為 4。不過,您可以根據每個目錄的需求設定每個檔案的區塊大小和目標數目。在所有這些測試中,我們將 BeeGFS stripe 大小選擇為 2MB,而 stripe 計數則選擇為 3,因為我們每個 NUMA 區域有三個目標,如下所示:
$ beegfs-ctl --getentryinfo --mount=/mnt/beegfs /mnt/beegfs/benchmark --verbose EntryID: 0-5D9BA1BC-1 ParentID: root Metadata node: node001-numa0-4 [ID: 4] Stripe pattern details: + Type: RAID0 + Chunksize: 2M + Number of storage targets: desired: 3 + Storage Pool: 1 (Default) Inode hash path: 7/5E/0-5D9BA1BC-1
透明巨大頁面 (transparent huge page) 已停用,並為中繼資料和儲存伺服器設定下列調整選項:
vm.dirty_background_ratio = 5 vm.dirty_ratio = 20 vm.min_free_kbytes = 262144 vm.vfs_cache_pressure = 50 vm.zone_reclaim_mode = 2 kernel.numa_balancing = 0
除了上述內容外,還使用下列 BeeGFS 調整選項:
tuneTargetChooser在中繼資料組態檔案中將參數設定為「循環制」tuneNumWorkers中繼資料的參數設定為 24,儲存的參數設定為 32connMaxInternodeNum中繼資料的參數設定為 32,儲存的參數設定為 12,用戶端的參數設定為 24

圖 9: 循序 IOzone 8TB 彙總檔案大小。
在圖 9 中,我們發現尖峰讀取效能為 1024 個執行緒時的 132 GB/秒,尖峰寫入為 256 個執行緒時的 121 GB/秒。每個磁碟機可提供 3.2 GB/秒的尖峰讀取效能和 1.3 GB/秒的尖峰寫入效能,使理論上的尖峰讀取效能為 422 GB/秒,寫入則為 172 GB/秒。不過在這裡,網路是限制了效能的因素。在設定中,我們總共有 11 個儲存伺服器的 InfiniBand EDR 連結。每個連結都可提供 12.4 GB/秒的理論尖峰效能,總共應可提供 136.4 GB/秒的理論尖峰效能。所達到的尖峰讀取和寫入效能,分別是理論尖峰效能的 97% 和 89%。
觀察到的單一執行緒寫入效能為約 3 GB/秒,讀取效能則為約 3 GB/秒。我們觀察到寫入效能以線性增加,在 256 個執行緒時達到尖峰,然後開始減少。使用較低的執行緒計數時,讀取和寫入效能相同。因為在八個執行緒之前,我們有 8 個用戶端在 24 個目標寫入 8 個檔案,這表示並未充分運用所有儲存裝置目標。系統中有 33 個儲存目標,因此至少需要 11 個執行緒,才能完全使用所有伺服器。讀取效能會隨著並行執行緒的數量增加而持續增加,我們在 512 和 1024 個執行緒上觀察到幾乎相同的效能。
我們也觀察到,在執行緒計數從 16 到 128 之間時,讀取效能會低於寫入效能,然後讀取效能就會開始提高。這是因為 PCIe 讀取作業是非張貼作業,需要同時取得要求和完成通知,PCIe 寫入作業卻是一種自主導引 (fire and forget) 的作業。當交易層封包移交給資料連結層後,作業即完成。寫入作業是一種「張貼」作業,僅包含要求。
讀取的輸送量通常低於寫入輸送量,因為在處理相同資料量時,讀取需要兩次交易,而寫入僅需要一次。PCI Express 使用分割交易模式進行讀取。讀取交易包含下列步驟:
- 要求者傳送記憶體讀取要求 (MRR)。
- 完成者傳送 MRR 的確認。
- 完成者傳回完成通知與資料。
讀取傳輸量取決於發出讀取要求的時間,以及完成者傳回資料之間的延遲。但是,當應用程式發出可彌補此延遲的大量讀取要求時,便可最大化輸送量。這也是為什麼讀取效能會在 16 個執行緒到 128 個執行緒之間低於寫入效能,並在要求增加後輸送量也隨之增加。當要求者等待完成通知,再發出後續請求時,會測量到較低的輸送量。當發出多個要求,便可在第一次資料傳回後進行延遲分攤,便可實現較高的輸送量。
隨機寫入和讀取 N-N
為了評估隨機 IO 效能,我們使用了隨機模式的 IOzone。測試從 4 個執行緒到最多 1024 個執行緒,計算執行緒總數。我們使用直接 IO 選項 (-I) 執行 IOzone,讓所有作業都略過緩衝快取,並直接前往磁碟。使用的 BeeGFS stripe 計數為 3,區塊大小為 2MB。在 IOzone 使用 4KiB 要求大小。效能以每秒 I/O 作業 (IOPS) 計算。在 BeeGFS 伺服器和 BeeGFS 用戶端運行間會清理作業系統快取。用於執行隨機寫入和讀取的命令如下:
隨機讀取和寫入:
iozone -i 2 -w -c -O -I -r 4K -s $Size -t $Thread -+n -+m /path/to/threadlist

圖 10: 使用 IOzone 和 8 TB 彙總檔案大小隨機讀取和寫入效能。
隨機寫入在 512 個線程時達到 ~360 萬 IOPS 的峰值,隨機讀取在 1024 個線程時達到 ~350 萬 IOPS 的峰值,如圖 10 所示。當 IO 要求的數量提高時,觀察到的寫入和讀取效能也都更高。這是因為 NVMe 標準最多可支援 64K I/O 佇列,每個佇列最多可支援 64K 個命令。這樣的大型 NVMe 佇列集區,可提供更高層級的 I/O 平行處理,因此我們觀察到超過 300 萬的 IOPS。
結論和未來工作
此部落格宣佈推出 Dell EMC 高效能 BeeGFS 儲存解決方案,並強調其效能特性。解決方案的尖峰循序讀取與寫入效能分別為約 132 GB/秒和 ~121 GB/秒,隨機寫入尖峰效能為約 360 萬 IOPS,隨機讀取效能則為約 350 萬 IOPS。
此部落格是「BeeGFS 儲存解決方案」的一部分,其設計著重於高效能的暫存空間。請持續關注部落格系列的第 2 部分,其中將說明如何藉由增加伺服器數量來擴充解決方案,以提升效能和容量。本部落格系列的第 3 部分將討論 BeeGFS 的其他功能,並重點介紹如何使用 BeeGFS 的內建儲存目標效能指標「StorageBench」。
作為後續步驟的一部分,我們將在稍後發佈一份白皮書,其中包含元數據性能和 N 個線程到一個檔 IOR 性能,以及有關設計注意事項、調整和配置的其他詳細資訊。
參考資料
[1] BeeGFS 說明文件: https://www.beegfs.io/wiki/
[2] 如何在相同的子網路上連接兩個界面: https://access.redhat.com/solutions/30564