PowerScale, Isilon OneFS: Prueba de rendimiento de HBase en Isilon (en inglés)
Summary: En este artículo, se ilustran las pruebas de análisis comparativo de rendimiento en un clúster de Isilon X410 mediante el conjunto de Yahoo Cloud Serving Benchmarking (YCSB) y Cloudera Data Hub (CDH) 5.10. ...
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Symptoms
No se requiere
Cause
No se requiere
Resolution
NOTA: Este tema forma parte del Centro de información Uso de Hadoop con OneFS.
Introducción
Se realizó una serie de pruebas comparativas de rendimiento en un clúster Isilon X410 con el conjunto de pruebas comparativas YCSB y CDH 5.10.
El entorno de pruebas de laboratorio se configuró con cinco nodos Isilon x410 que ejecutan OneFS v8.0.0.4 y versiones posteriores v8.0.1.1. Se ejecutaron parámetros de referencia de streaming de bloques grandes de Network File System (NFS). El máximo agregado teórico esperado para las pruebas fue de ~700 MB/s (3,5 GB/s) de escrituras y ~1 GB/s de lecturas (5 GB/s) por nodo.
Los (9) nodos de computación son servidores Dell PowerEdge FC630 que ejecutan CentOS v7.3.1611, cada uno configurado con 2 CPU Intel Xeon® E5-2697 @ 2697 v4 @ 2.30GHz con 512 GB de RAM. El almacenamiento local es 2 SSD en RAID 1 formateado como XFS tanto para el sistema operativo como para los archivos de espacio temporal o derrame.
También había tres servidores edge adicionales que se utilizaron para impulsar la carga de YCSB.
La red de back-end entre los nodos de computación e Isilon es de 10 Gbps con tramas jumbo configuradas (MTU=9162) para las NIC y los puertos del switch.
Los componentes de la configuración de prueba de Hadoop (Figura 1)
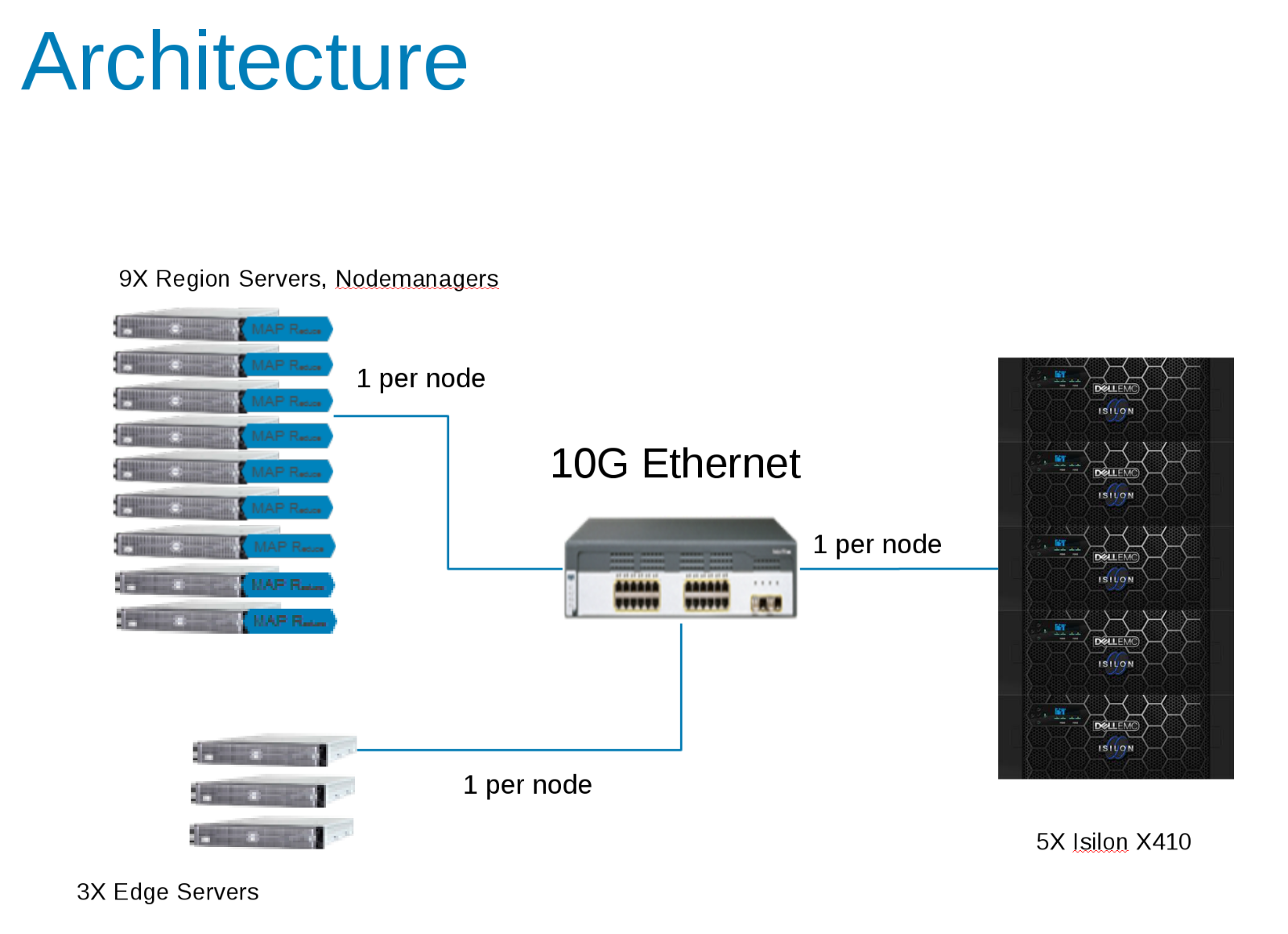
CDH 5.10 se configuró para ejecutarse en una zona de acceso en el clúster de Isilon. Las cuentas de servicio se crearon en el proveedor local de Isilon y localmente en los archivos /etc/passwd del cliente. Todas las pruebas se ejecutaron con un cliente de prueba básico sin privilegios especiales.
Las estadísticas de Isilon se monitorearon con IIQ y el paquete de Grafana/Data Insights. Las estadísticas de CDH se monitorearon con Cloudera Manager y también con Grafana.
Pruebas iniciales
La primera serie de pruebas consistió en determinar los parámetros relevantes en el lado de HBASE que afectaban a la producción global. Se utilizó la herramienta YCSB para generar la carga para HBASE. Esta prueba inicial se ejecutó con un solo cliente (servidor perimetral) utilizando la fase de "carga" de YCSB y 40 millones de filas. Esta tabla se eliminó antes de cada ejecución.
ycsb load hbase10 -P workloads/workloada1 -p table='ycsb_40Mtable_nr' -p columnfamily=family -threads 256 -p recordcount=40000000
- hbase.regionserver.maxlogs : número máximo de archivos de registro de escritura anticipada (WAL): este valor multiplicado por el tamaño de bloque de HDFS (dfs.blocksize) es el tamaño de la WAL que se debe reproducir cuando se bloquea un servidor. Este valor es inversamente proporcional a la frecuencia de los vaciados del disco.
- hbase.wal.regiongrouping.numgroups : cuando se utilizan varios WAL de HDFS como WALProvider, se establece la cantidad de registros de escritura anticipada que debe ejecutar cada RegionServer. Los resultados muestran la cantidad de pipelines de HDFS. Las escrituras de una región determinada solo van a una única canalización y distribuyen la carga total de RegionServer.
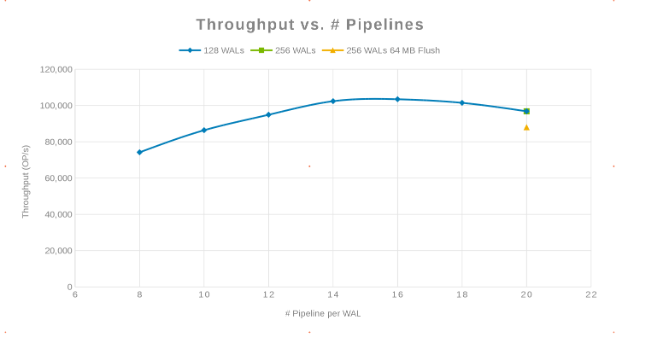
Rendimiento en comparación con el número de canalizaciones (Figura 2)
Latencia comparada con el número de pipelines (Figura 3)
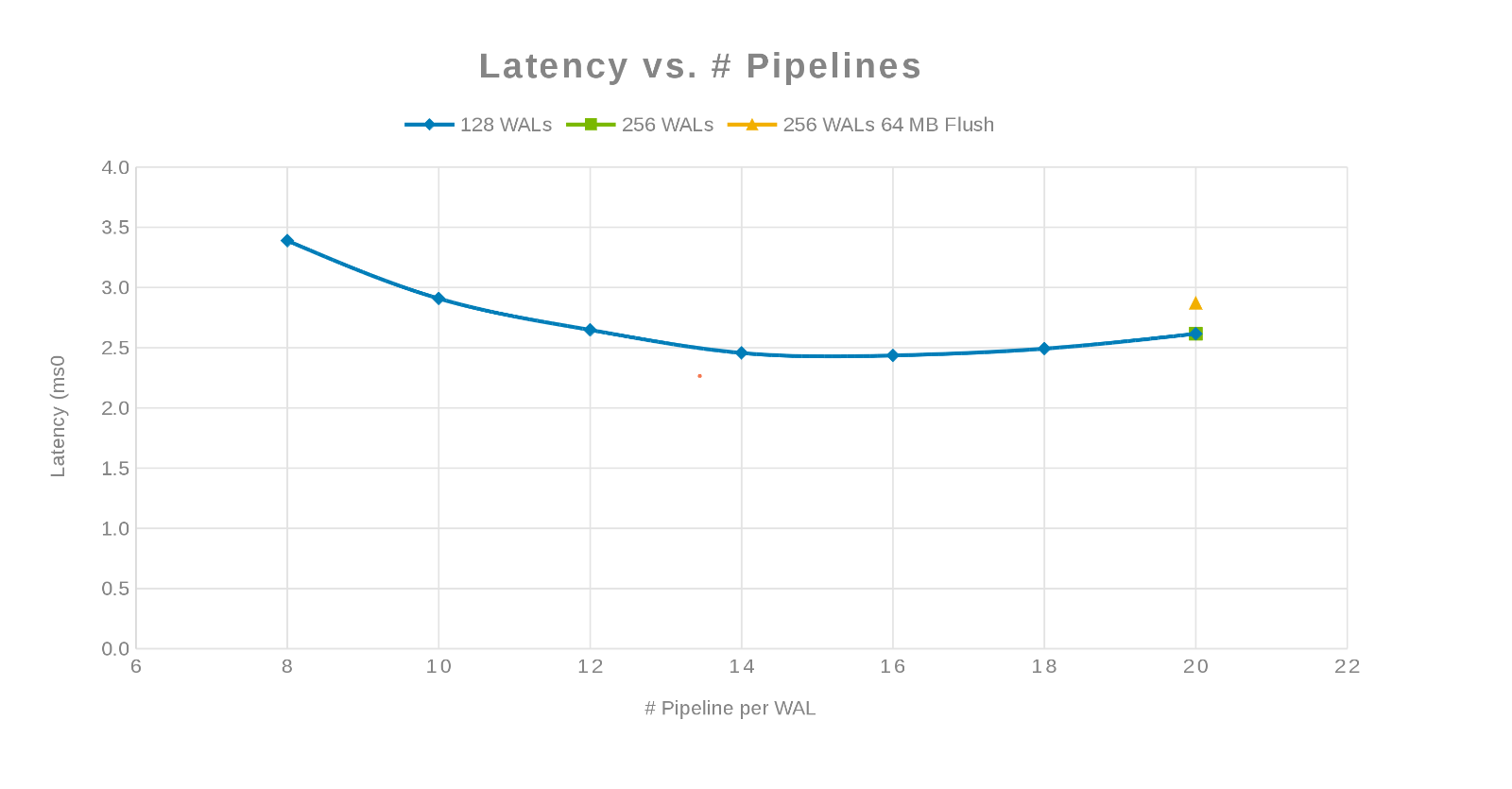
La filosofía aquí era paralelizar tantas escrituras como fuera posible. Esto se logra con el aumento de la cantidad de WAL y, luego, la cantidad de subprocesos (pipeline) por WAL. Los dos gráficos anteriores muestran que para un número dado de 'maxlogs', 128 o 256, no se muestra ningún cambio real. Esto indica que la prueba no afecta realmente los resultados del lado del cliente. El número de "pipelines" por archivo varió, lo que mostró una tendencia que indica el parámetro que es sensible a la paralelización. La siguiente pregunta es dónde se interpone el clúster Isilon, ya sea con I/O de disco, red, CPU o OneFS. Para responder esta pregunta, consulte el informe de estadísticas de Isilon.
La utilización de la red Isilon y la carga durante la prueba (Figura 4)
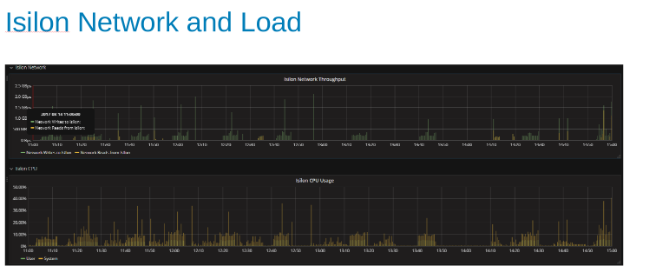
Los gráficos de red y CPU nos indican que el clúster Isilon está infrautilizado y tiene espacio para más trabajo. La CPU sería > del 80 % y el ancho de banda de red sería superior a 3 GB/s.
Gráficos de las estadísticas del protocolo HDFS y la utilización de CPU mientras se encuentra bajo la carga del protocolo HDFS (Figura 5)
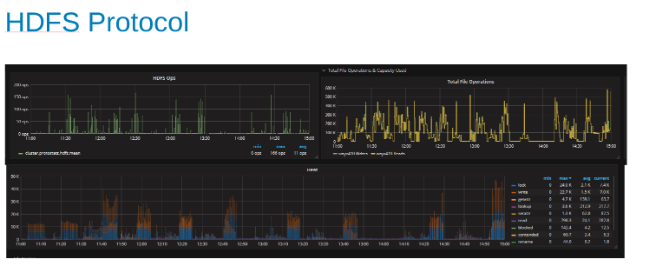
Estos gráficos muestran las estadísticas del protocolo HDFS y la manera en que OneFS traduce la salida. Las operaciones de HDFS son múltiplos de dfs.blocksize, que es de 256 MB aquí. Lo interesante aquí es que el gráfico "Heat" muestra las operaciones de archivos de OneFS y se muestra la correlación de escrituras y bloqueos. En este caso, HBase realiza anexos a los WAL, de modo que OneFS bloquea el archivo WAL para cada escritura que se anexa. Que es lo que se espera para las escrituras estables en un sistema de archivos en clúster. Estos parecen estar contribuyendo al factor limitante en este conjunto de pruebas.
Actualizaciones de HBase
La siguiente prueba consistió en hacer más experimentos para encontrar lo que sucede a escala. Se crea una tabla de mil millones de filas que tardó una hora en generarse. Se ejecuta una prueba de YCSB que actualizó 10 millones de filas con la configuración de "workloada" (50/50 de lectura/escritura). Esta prueba se ejecutó en un solo cliente. La prueba se ejecutó en función de la cantidad de subprocesos YCSB para que se pueda generar el mayor rendimiento. Además, se aplicaron algunos ajustes y OneFS se actualizó a la versión 8.0.1.1, que tiene ajustes de rendimiento para el servicio de nodo de datos. En el siguiente gráfico se muestra el aumento en el rendimiento en comparación con el conjunto anterior de ejecuciones. Para estas ejecuciones, hbase.regionserver.maxlogs se establece en 256 y hbase.wal.regiongrouping.numgroups en 20.
Rendimiento y conteo de subprocesos durante la actualización de la tabla de 1 mil millones de filas (Figura 6)
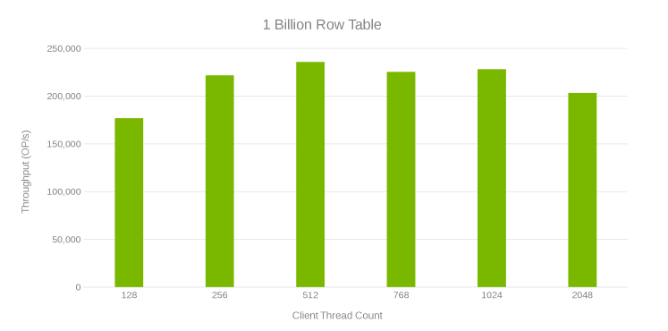
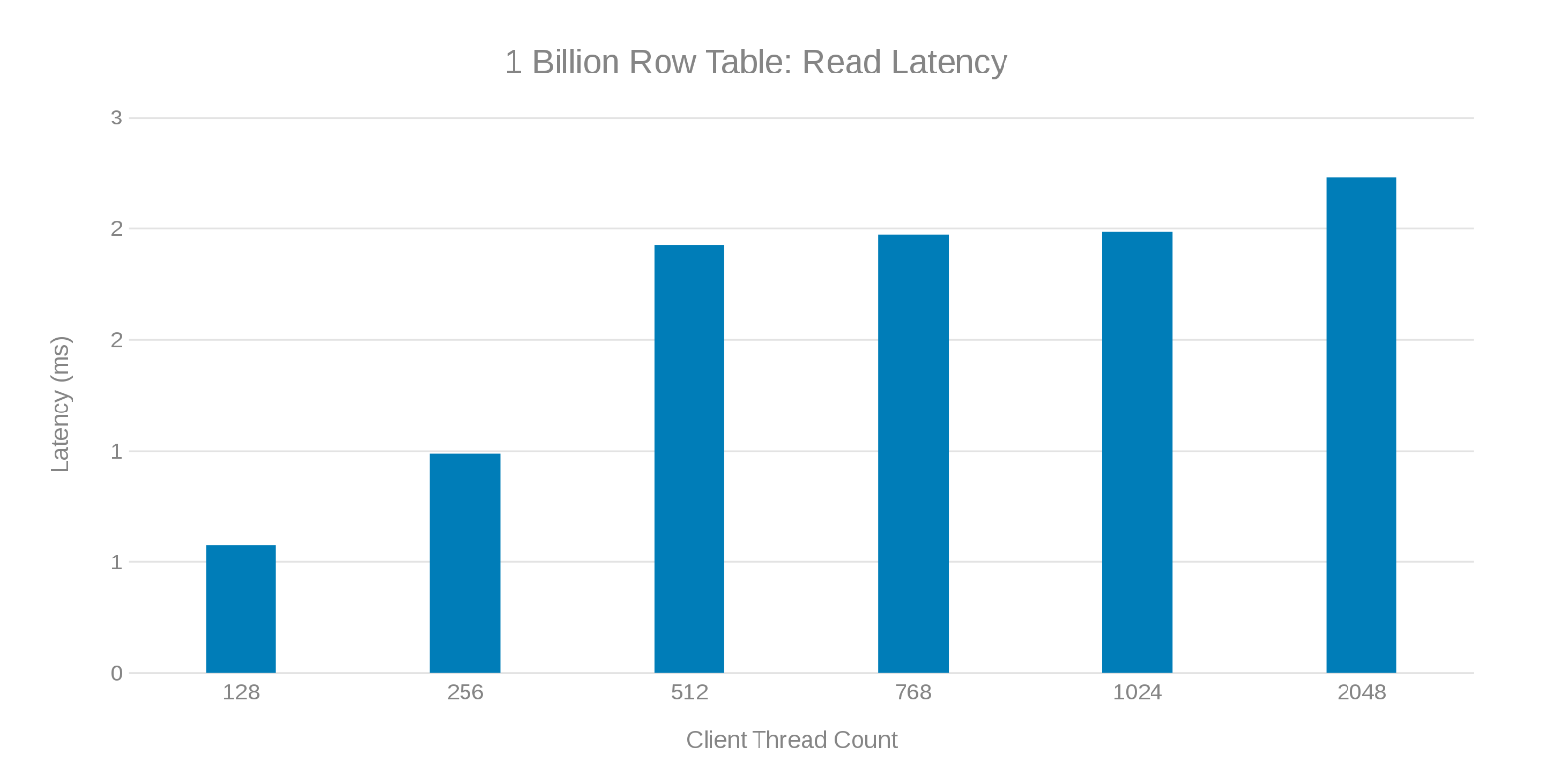
Latencia de lectura durante la actualización de la tabla de 1 mil millones de filas (Figura 7)
Actualizar latencia durante la actualización de la tabla de 1 mil millones de filas (Figura 8)
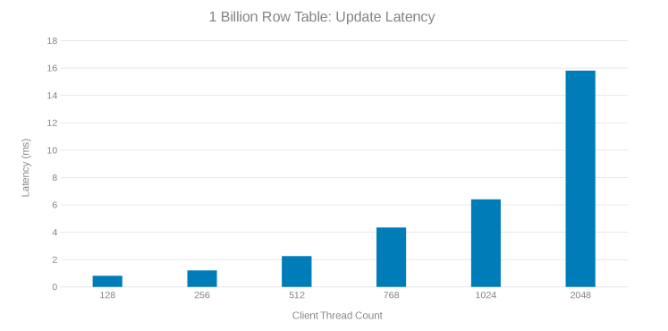
La revisión de estas ejecuciones de prueba muestra una disminución aparente en un conteo alto de subprocesos que puede ser un problema de Isilon o del lado del cliente. Las pruebas muestran e impresionan 200 000 operaciones por segundo a una latencia de actualización de < 3 ms. Cada una de las ejecuciones de prueba de actualización fue rápida y se pudo ejecutar consecutivamente. El siguiente gráfico muestra un equilibrio uniforme entre los nodos Isilon para cada ejecución de prueba.
Gráfico de calor que indica la carga de trabajo en cada nodo del clúster de Isilon (Figura 9)
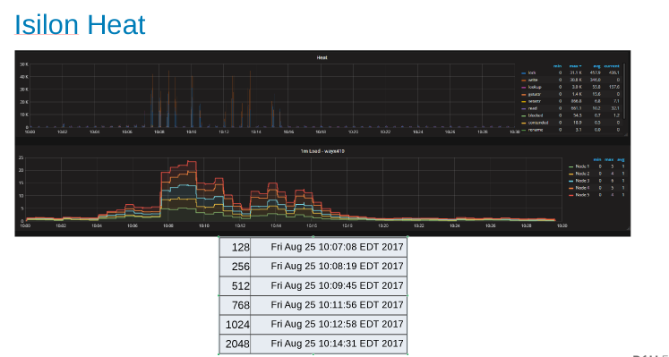
En el gráfico Heat, se muestra que las operaciones de archivos son escrituras y bloqueos correspondientes a la naturaleza anexada de los procesos WAL.
Escalamiento del servidor de la región
La siguiente prueba consistió en determinar cómo les iría a los nodos Isilon (cinco nodos) frente a una cantidad diferente de servidores regionales. El mismo script de actualización ejecutado en la prueba anterior se ejecutó con una tabla de mil millones de filas y una actualización de 10 millones de filas con "workloada". En la prueba, se utilizó un solo cliente con subprocesos YCSB configurados en 51. Se aplica la misma configuración para maxlogs y pipelines (256 y 20 respectivamente).
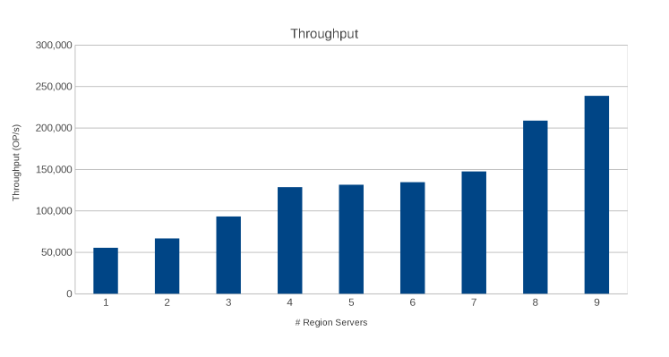
Rendimiento en toda la región Servidores (Figura 10)
Latencia entre servidores regionales (Figura 11)
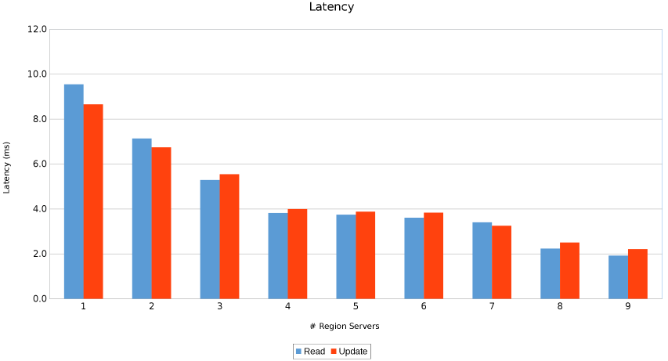
Los resultados son informativos, aunque no sorprendentes. La naturaleza de escalamiento horizontal de HBase combinada con la naturaleza de escalamiento horizontal de Isilon indica que más es mejor. Se recomienda que los clientes ejecuten esta prueba en sus entornos como parte de su propio ejercicio de dimensionamiento. Aquí hay nueve servidores que impulsan cinco nodos Isilon y parece que todavía hay espacio para más antes de llegar al punto de rendimientos decrecientes.
Más clientes
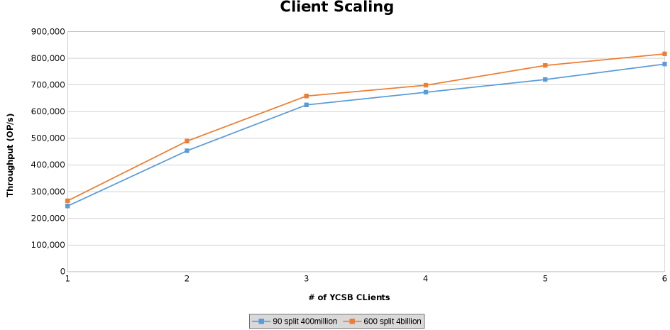
La última serie de pruebas sirvió para probar los límites de la configuración de hardware. Esto se hizo para determinar el límite superior de los parámetros que se estaban probando. En esta serie de pruebas, se utilizan dos servidores adicionales desde los cuales ejecutar clientes. Además, se ejecutan dos clientes YCSB desde cada servidor, lo que permitía hasta seis clientes cada uno. Cada cliente controló 512 subprocesos, lo que dio como resultado 4096 subprocesos en total. Se crearon dos tablas diferentes. Una tabla con 4000 millones de filas dividida en 600 regiones y otra con 400 millones de filas divididas en 90 regiones.
Esto grafica el rendimiento de las operaciones durante las pruebas de escalamiento de clientes (Figura 12).
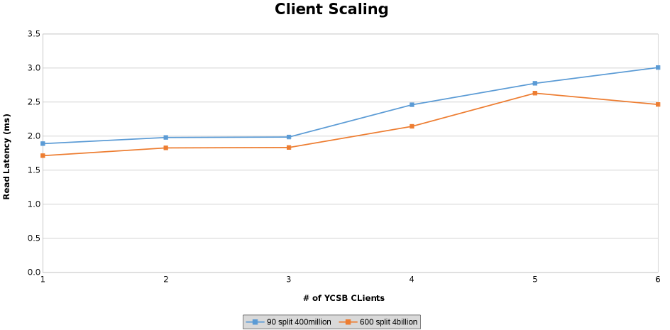
Medición de la latencia de lectura durante las pruebas de escalamiento de clientes (Figura 13)
Medición de la latencia de actualización durante las pruebas de escalamiento de clientes (Figura 14)
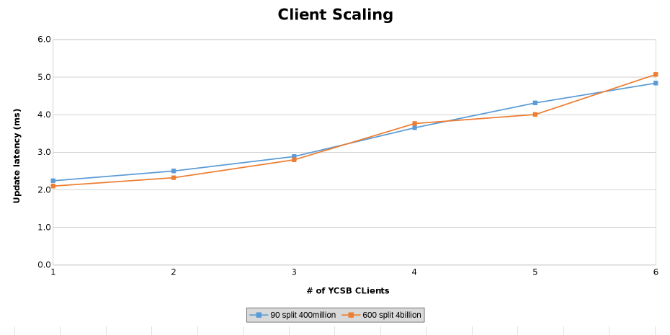
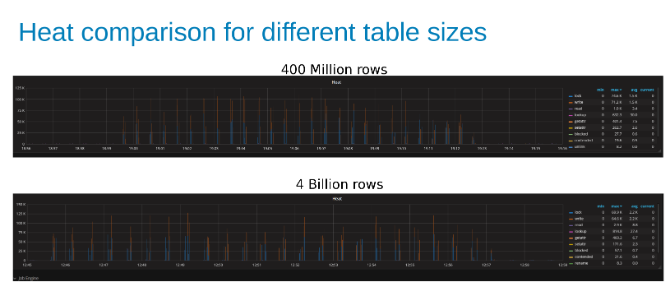
Los siguientes gráficos muestran que el tamaño de la tabla importa poco en esta prueba. Los gráficos de Isilon Heat vuelven a mostrar que hay una pequeña diferencia porcentual en la cantidad de operaciones de archivos. La mayoría de las diferencias estaban en línea con las diferencias de una tabla de cuatro mil millones de filas con una tabla de 400 millones de filas.
Comparación del calor de la carga de trabajo de Isilon durante la actualización de una tabla de 400 millones de filas en comparación con una tabla de 4 mil millones de filas (Figura 15).
Conclusión
HBase es un buen candidato para ejecutarse en Isilon, principalmente debido a las arquitecturas de escalamiento horizontal a horizontal. HBase realiza gran parte de su propio almacenamiento en caché y, al dividir la tabla en un buen número de regiones, HBase puede escalar horizontalmente con los datos. En otras palabras, hace un buen trabajo al ocuparse de sus propias necesidades, y el sistema de archivos está ahí para la resiliencia de las aplicaciones. Las pruebas no pudieron empujar la carga hasta el punto de romper cosas. Si HBase está diseñado para 800 000 operaciones con menos de 3 ms de latencia, esta arquitectura lo admite. HBase es compatible con una gran cantidad de ajustes y modificaciones de rendimiento tanto para el lado del cliente como para el propio HBase. La prueba de todos esos ajustes y retoques estaba más allá del alcance de esta prueba.Affected Products
Isilon, PowerScale OneFSArticle Properties
Article Number: 000128942
Article Type: Solution
Last Modified: 11 Mar 2026
Version: 7
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.