Dell Unity: Storage-Prozessoren werden in der Benutzeroberfläche, aber nicht in der CLI als Neustart angezeigt und es liegen keine fehlerhaften LEDs vor (vom Nutzer korrigierbar).
Summary: In diesem Artikel wird erläutert, warum die Unisphere-Benutzeroberfläche die SPs möglicherweise heruntergestuft anzeigt und neu startet, wenn sie sich im Normalmodus befinden.
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Symptoms
Der SFP (Small Factor Pluggable) wird in Protokollen als einmal fehlend angezeigt und später als gut.
SFPs werden bekanntermaßen nicht erkannt, wenn sie ein wenig Staub aufweisen oder nicht vollständig in den Anschluss eingesetzt sind.
Dies ist ein häufiger Faktor für Leistungseinbußen, da es zu ständigen Verbindungsabbrüchen führt und sogar als langsames Entladungsgerät verantwortlich sein kann.
In der Unisphere-Benutzeroberfläche werden die Storage-Prozessoren als "Rebooting" und "Degraded State " unter "SYSTEM" > "Service" > und "Service Tasks" angezeigt.
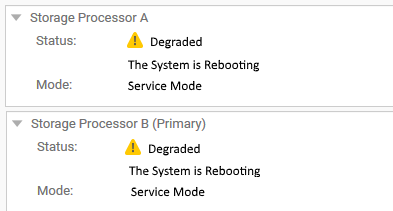
In einem SSH-Terminal, das die CLI verwendet, befinden sich jedoch beide SPs im Normalmodus.
Dies ist bisher in Unity OE-Version 4.5.1.0.5.001 der Fall.
Beispiel:
service@CKMxxxxxxxx spa:~/user# svc_diag ======== Now executing basic state ======== * System Serial Number is: CKMxxxxxxx * System Model Number is: Unity 500 * System Friendly Host Name is: CKMxxxxxxxx * Current Software version: c4dev_PIE_3786R-4.5.1.0.5.001.1552025209-GNOSIS_RETAIL * Unisphere IP address(es): xx.xxx.xxx.xx xxxx::xxx:xxxx:xxxx:xxxx * SSH Enabled: true * FIPS mode: Disabled * Boot Mode: Normal Mode * Post Faults: 0x0000 * Backend Faults: 0x0000 * Boot Faults: 0x0000 * Rescue Reason: 0x0000 * Rescue reason for code 0x0000 - No faults detected. * SP Service Hint Code: <None>
Cause
Diese besondere Situation trat bei der Installation neuer I/O-Module auf.
Der Commit wurde aufgrund eines nicht optimalen SFP nicht abgeschlossen, daher wurden integritätsbezogene Vorgänge vorübergehend deaktiviert (ähnlich wie bei Upgrades).
Da die Integritätsabfrage deaktiviert war, konnte das System den korrekten Status der Storage-Prozessoren nicht identifizieren und meldete den bekannten vorherigen Status "wird neu gestartet".
Um zu bestätigen, dass es sich um dasselbe Problem handelt, überprüfen Sie die folgenden Protokolle: /var/tmp/ptm/ptm.log/EMC/C4Core/log/c4_safe_ktrace.log
Dies kann live angezeigt werden, indem Sie die Befehle auf einem SSH-Terminal oder in den Protokollen der Triaged Service Data Collection ausführen:
Befehl/Protokoll #1:
Erwartete Ausgabe:
cat /var/tmp/ptm/ptm.log
Erwartete Ausgabe:
=====================================Tasks===================================== 10:56 [ 16/22 ] Core reboot sp if required (local) 10 minutes Start at: Thu May 23 10:56:19 2019 Complete at: Thu May 23 10:56:19 2019 =============================================================================== 10:56 [ 17/22 ] Core start c4 (local) 5 minutes Start at: Thu May 23 10:56:19 2019 Task Manager was terminated unexpectedly with signal <TERM> .... <there might be a few extra lines here > .... Previous failure detected. Not auto-restarting.
Befehl/Protokoll #2:
Und suchen Sie nach SFP- oder Mezzanine-bezogenen Ereignissen.
Wir können sehen, dass bei der Installation der neuen I/O-Module etwas schief gelaufen ist:
less /EMC/C4Core/log/c4_safe_ktrace.log
Und suchen Sie nach SFP- oder Mezzanine-bezogenen Ereignissen.
Wir können sehen, dass bei der Installation der neuen I/O-Module etwas schief gelaufen ist:
c4_safe_ktrace INFO OBJ 3 RP:MEZZ(SP: 0, Slot: 0): fbe_base_env_send_resume_prom_read_async_cmd entry. c4_safe_ktrace INFO OBJ 3 RP:MEZZ(SP: 0, Slot: 0): Read async completed, workItem 0x7f2486432760, resumeStatus DEVICE_NOT_VALID_FOR_PLATFO c4_safe_ktrace INFO OBJ 3 100C0 : ModMgmt: CLEAR enclFaultLedReason Mezzanine RP Fault. <<<====== Fault detected in Root Port (RP) .......... c4_safe_ktrace INFO OBJ 3 100C0 : fbe_module_mgmt_check_module_state, SPB Mezzanine 0, state:ENABLED, substate:GOOD c4_safe_ktrace INFO OBJ 3 100C0 : fbe_module_mgmt_check_port_state Setting SPB Mezzanine 0, Port 0, state ENABLED, substate GOOD c4_safe_ktrace INFO OBJ 3 100C0 : fbe_module_mgmt_check_port_state Setting SPB Mezzanine 0, Port 1, state MISSING, substate MISS_SFP <<<=== SFP not detected c4_safe_ktrace INFO OBJ 3 100C0 : fbe_module_mgmt_check_port_state Setting SPB Mezzanine 0, Port 2, state ENABLED, substate GOOD c4_safe_ktrace INFO OBJ 3 100C0 : fbe_module_mgmt_check_port_state Setting SPB Mezzanine 0, Port 3, state ENABLED, substate GOOD c4_safe_ktrace INFO OBJ 3 100C0 : fbe_module_mgmt_check_port_state Setting SPB Mezzanine 0, Port 4, state ENABLED, substate GOOD c4_safe_ktrace INFO OBJ 3 100C0 : fbe_module_mgmt_check_port_state Setting SPB Mezzanine 0, Port 5, state ENABLED, substate GOOD
Resolution
Um dieses Problem zu beheben, führen Sie mit den unten aufgeführten Befehlen ein erneutes Committening der I/O-Module durch, da sie anfänglich fehlgeschlagen sind.
Anmerkung: Diese Befehle erfordern kein root, aber ein fehlerfreies Array, also bestätigen Sie vor der Ausführung, dass Ihr Array voll funktionsfähig ist:
Befehl #1:
uemcli -no /sys/general healthcheck -output csv -detail
Beispielausgaben:
#1 (NICHT optimal) - fahren Sie nicht fort, bevor Sie die angezeigten Fehler behoben haben).
"Error code" "Warning: One or more asynchronous replication sessions, or one or more NAS Server or file system synchronous replication sessions, exist. This could cause problems during upgrade. Pause the replication sessions on the production array prior to starting the upgrade and resume them after completing the upgrade. [Warning Code: platform::check_replication_health_4]" "Warning: One or more NAS servers may not be in a healthy state. You can continue with the upgrade, but it is recommended that you record the error code and contact your service provider. [Warning Code: dm::check_nas_servers_health_3]" Operation completed successfully.
Hinweis: "Upgrade" wird erwähnt, da dies der Befehl ist, der vor der Durchführung unterbrechungsfreier Upgrades (Non-Disruptive Upgrades, NDU) verwendet wird. Diese Meldungen werden jedoch angezeigt, weil das Array (beide SPs) neu gestartet werden müssen.
Befehl #2 erfordert möglicherweise auch einen Neustart. Aus diesem Grund ist es wichtig, dass diese Integritätsprüfung ohne [Fehlercode:] verläuft.
[Warnungen] können ignoriert werden, aber die Eingabeaufforderung von Befehl #2 ist die Meldung
"Do you still want to continue," und Sie können "Ja" eingeben. Der Dell Support empfiehlt jedoch, alle Warnungen und Fehler im Health Check zu beheben, bevor Sie fortfahren.
Um einen Storage-Prozessor neu zu starten, befolgen Sie bitte die Schritte, die im Wissensdatenbankartikel Dell Unity beschrieben sind: Anleitung zum Neustarten eines Storage-Prozessors (von NutzerInnen korrigierbar)
#2 (Optimal) - Sie können zu Befehl #2 gehen
"Error code" Operation completed successfully.
Befehl #2:
svc_change_hw_config -e
Erwartete Ausgabe:
service@CKMxxxxxxxx spa:~/user# svc_change_hw_config -e Checking if both SPs are in Normal mode...OK INFO: Beginning eSLIC or CNA Hardware Upgrade... WARNING: This operation will cause several reboots to occur on the Storage Processors. WARNING: Do NOT proceed further if the user is unaware of this downtime! ==============================System Information=============================== Task Manager Command: /opt/ptm/task_mgr.pl Starts at: Sat Oct 5 10:03:47 2019 Dual SP: Yes SP: b Platform: OBERON Original Primary: Yes Model: Unity xxx Serial Number: xxxxxxxxxxxxx Total number of attempts: 0 =============================================================================== ==========================Time Estimate for All Tasks========================== Task name [ 22 tasks in total ] Estimated Status Time(Minutes) 1 Slic wait for system ready slic (local) 3 2 Core run pre upgrade health checks (local) 2 3 ESLIC check eslic configuration (local) 1 4 Core enable auto start (local) 0 5 Core clear boot counters (local) 0 6 Core clear boot counters (remote) 0 7 Core force vdms off sp (remote) 2 8 ESLIC set esp boolean (remote) 1 9 Core disable quickboot (remote) 1 10 Core reboot peer sp if required (local) 10 11 Core start c4 (remote) 5 12 Core wait for system ready on peer 3 13 Core force vdms off sp (local) 2 14 ESLIC set esp boolean (local) 1 15 Core disable quickboot (local) 1 16 Core reboot sp if required (local) 10 17 Core start c4 (local) 5 18 Core wait for system ready (local) 3 19 ESLIC final configuration check (local) 1 20 Core clean up (local) 0 21 Core clean up peer (local) 0 22 Core disable auto start (local) 0 =============================================================================== =========================Estimated Time for Services ========================== Current Time: 10:03 Estimated Time when eSLIC will be complete: 10:52 =============================================================================== Do you wish to continue [ yes or no ]? >
Nachdem Sie "yes" eingegeben und die Eingabetaste gedrückt haben, sollte die folgende Ausgabe angezeigt werden:
=====================================Tasks===================================== 20:41 [ 17/22 ] Core start c4 (local) 5 minutes =============================================================================== 20:41 [ 18/22 ] Core wait for system ready (local) 3 minutes =============================================================================== 20:41 [ 19/22 ] ESLIC final configuration check (local) 30 seconds =============================================================================== 20:41 [ 20/22 ] Core clean up (local) 5 seconds =============================================================================== 20:41 [ 21/22 ] Core clean up peer (local) 5 seconds =============================================================================== 20:41 [ 22/22 ] Core disable auto start (local) 5 seconds =============================================================================== ===================================SUMMARY===================================== Status: Success Actual Time Spent: 16452 minutes Total Number of attempts: 1 Log File: /var/tmp/ptm/ptm.log =====================================END=======================================
Diese sind ebenfalls eingeloggt
/EMC/backend/log_shared/EMCSystemLogFile.logaus:
Platform_Basic 30018 [NOTICE] Audit: Service user executed the following service script command: svc_change_hw_config -e IOModule 30010 [INFO] User: Starting the hardware configuration commit operation Platform_Basic 30018 [NOTICE] Audit: Service user executed the following service script command: svc_dc -pbc udoctor IOModule 30014 [INFO] User: Completed task <17> of <22> (Restarting services) IOModule 30014 [INFO] User: Completed task <18> of <22> (Waiting for system ready state) IOModule 30014 [INFO] User: Completed task <19> of <22> (Checking if upgrade complete) IOModule 30014 [INFO] User: Completed task <20> of <22> (Cleaning up) IOModule 30014 [INFO] User: Completed task <21> of <22> (Cleaning up) IOModule 30014 [INFO] User: Completed task <22> of <22> (Disabling automatic restart) IOModule 30011 [NOTICE] User: The hardware configuration has been successfully committed Health 6044f [INFO] User: Storage Processor SP A is operating normally Health 6044f [INFO] User: Storage Processor SP B is operating normally
Nachdem die obige Ausgabe angezeigt wurde, aktualisieren Sie die Unisphere-Benutzeroberfläche und prüfen Sie, ob sich der Status wieder in den Normalzustand geändert hat (erwartet).
Wenn nicht, wenden Sie sich an den technischen Support von Dell und verweisen Sie auf diesen Artikel.
Hinweis: Weitere Informationen zu diesem Befehl finden Sie im Dokument Dell EMC Unity™ Family Service Commands Technical Notes, unter https://www.dell.com/support/home/en-us
Additional Information
HINWEIS: Es gibt auch eine möglicherweise beschädigte Knopfzellenbatterie, die ein falsch positives Problem beim Neustart des SP in der Benutzeroberfläche verursacht.
Siehe KB 000069296 Dell Unity: Knopfzellenbatterie auf dem Storage-Prozessor (von Dell korrigierbar)
Affected Products
Dell Unity 300, Dell EMC Unity FamilyProducts
Dell EMC Unity 300F, Dell EMC Unity 350F, Dell EMC Unity 400, Dell EMC Unity 400F, Dell EMC Unity 450F, Dell EMC Unity 500, Dell EMC Unity 500F, Dell EMC Unity 550F, Dell EMC Unity 600, Dell EMC Unity 600F, Dell EMC Unity 650F
, Dell EMC Unity Family |Dell EMC Unity All Flash, Dell EMC Unity Family, Dell EMC Unity Hybrid
...
Article Properties
Article Number: 000056107
Article Type: Solution
Last Modified: 04 Dec 2025
Version: 6
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.