Dell Unity: Procesory pamięci masowej są wyświetlane jako uruchamiające się ponownie w interfejsie użytkownika, ale nie w interfejsie CLI i bez wadliwych diod LED (możliwość naprawienia przez użytkownika)
Summary: W tym artykule wyjaśniono, dlaczego interfejs użytkownika Unisphere może wyświetlać SP w pogorszonym stanie i uruchamiać się ponownie w trybie normalnym.
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Symptoms
Small Factor Pluggable (SFP) pojawia się jeden raz jako brakujący w dziennikach, a później pokazuje się jako dobry.
Wiadomo, że moduły SFP pozostają niewykryte, jeśli mają trochę kurzu lub nie są całkowicie włożone do portu.
Jest to częsty czynnik pogorszenia wydajności, ponieważ powoduje ciągłe rozłączenia, a nawet może być odpowiedzialny za urządzenie o powolnym opróżnianiu.
W interfejsie użytkownika Unisphere procesory pamięci masowej są wyświetlane jako uruchamiane ponownie i w stanie zdegradowanym w folderze "SYSTEM > ", "Service > ", "Service Tasks".
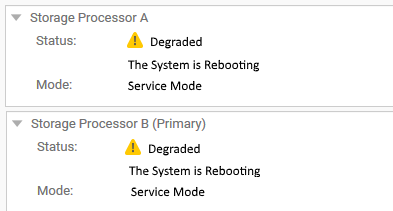
Jednak w terminalu SSH korzystającym z interfejsu wiersza poleceń oba SP działają w trybie normalnym.
Do tej pory było to widoczne w Unity OE w wersji 4.5.1.0.5.001.
Przykład:
service@CKMxxxxxxxx spa:~/user# svc_diag ======== Now executing basic state ======== * System Serial Number is: CKMxxxxxxx * System Model Number is: Unity 500 * System Friendly Host Name is: CKMxxxxxxxx * Current Software version: c4dev_PIE_3786R-4.5.1.0.5.001.1552025209-GNOSIS_RETAIL * Unisphere IP address(es): xx.xxx.xxx.xx xxxx::xxx:xxxx:xxxx:xxxx * SSH Enabled: true * FIPS mode: Disabled * Boot Mode: Normal Mode * Post Faults: 0x0000 * Backend Faults: 0x0000 * Boot Faults: 0x0000 * Rescue Reason: 0x0000 * Rescue reason for code 0x0000 - No faults detected. * SP Service Hint Code: <None>
Cause
Ta szczególna sytuacja miała miejsce podczas instalowania nowych modułów we/wy.
Zatwierdzenie nie zostało ukończone z powodu nieoptymalnego SFP, dlatego operacje związane z kondycją zostały tymczasowo wyłączone (podobnie jak podczas uaktualniania).
Ponieważ ankieta kondycji była wyłączona, system nie mógł zidentyfikować prawidłowego stanu procesorów pamięci masowej i zgłosił poprzedni znany stan "ponownego uruchomienia".
Aby potwierdzić, że występuje ten sam problem, sprawdź następujące dzienniki: /var/tmp/ptm/ptm.log/EMC/C4Core/log/c4_safe_ktrace.log
Można to zobaczyć na żywo, uruchamiając polecenia w terminalu SSH lub w dziennikach gromadzenia danych usługi Triaged Service:
Polecenie/log #1:
Oczekiwany wynik:
cat /var/tmp/ptm/ptm.log
Oczekiwany wynik:
=====================================Tasks===================================== 10:56 [ 16/22 ] Core reboot sp if required (local) 10 minutes Start at: Thu May 23 10:56:19 2019 Complete at: Thu May 23 10:56:19 2019 =============================================================================== 10:56 [ 17/22 ] Core start c4 (local) 5 minutes Start at: Thu May 23 10:56:19 2019 Task Manager was terminated unexpectedly with signal <TERM> .... <there might be a few extra lines here > .... Previous failure detected. Not auto-restarting.
Polecenie/log #2:
I szukaj wydarzeń związanych z SFP lub Mezzanine.
Widać, że coś poszło nie tak podczas instalowania nowych modułów we/wy:
less /EMC/C4Core/log/c4_safe_ktrace.log
I szukaj wydarzeń związanych z SFP lub Mezzanine.
Widać, że coś poszło nie tak podczas instalowania nowych modułów we/wy:
c4_safe_ktrace INFO OBJ 3 RP:MEZZ(SP: 0, Slot: 0): fbe_base_env_send_resume_prom_read_async_cmd entry. c4_safe_ktrace INFO OBJ 3 RP:MEZZ(SP: 0, Slot: 0): Read async completed, workItem 0x7f2486432760, resumeStatus DEVICE_NOT_VALID_FOR_PLATFO c4_safe_ktrace INFO OBJ 3 100C0 : ModMgmt: CLEAR enclFaultLedReason Mezzanine RP Fault. <<<====== Fault detected in Root Port (RP) .......... c4_safe_ktrace INFO OBJ 3 100C0 : fbe_module_mgmt_check_module_state, SPB Mezzanine 0, state:ENABLED, substate:GOOD c4_safe_ktrace INFO OBJ 3 100C0 : fbe_module_mgmt_check_port_state Setting SPB Mezzanine 0, Port 0, state ENABLED, substate GOOD c4_safe_ktrace INFO OBJ 3 100C0 : fbe_module_mgmt_check_port_state Setting SPB Mezzanine 0, Port 1, state MISSING, substate MISS_SFP <<<=== SFP not detected c4_safe_ktrace INFO OBJ 3 100C0 : fbe_module_mgmt_check_port_state Setting SPB Mezzanine 0, Port 2, state ENABLED, substate GOOD c4_safe_ktrace INFO OBJ 3 100C0 : fbe_module_mgmt_check_port_state Setting SPB Mezzanine 0, Port 3, state ENABLED, substate GOOD c4_safe_ktrace INFO OBJ 3 100C0 : fbe_module_mgmt_check_port_state Setting SPB Mezzanine 0, Port 4, state ENABLED, substate GOOD c4_safe_ktrace INFO OBJ 3 100C0 : fbe_module_mgmt_check_port_state Setting SPB Mezzanine 0, Port 5, state ENABLED, substate GOOD
Resolution
Aby rozwiązać ten problem, należy ponownie zatwierdzić moduły we/wy, ponieważ początkowo nie powiodły się, używając poleceń wymienionych poniżej.
Nuta: Te polecenia nie wymagają katalogu root, ale wymagają sprawnego systemu macierzy, dlatego przed uruchomieniem należy upewnić się, że macierz jest w pełni sprawna:
Polecenie #1:
uemcli -no /sys/general healthcheck -output csv -detail
Przykładowe wyniki:
#1 (NIE jest optymalne) - nie kontynuuj przed rozwiązaniem wyświetlanych błędów).
"Error code" "Warning: One or more asynchronous replication sessions, or one or more NAS Server or file system synchronous replication sessions, exist. This could cause problems during upgrade. Pause the replication sessions on the production array prior to starting the upgrade and resume them after completing the upgrade. [Warning Code: platform::check_replication_health_4]" "Warning: One or more NAS servers may not be in a healthy state. You can continue with the upgrade, but it is recommended that you record the error code and contact your service provider. [Warning Code: dm::check_nas_servers_health_3]" Operation completed successfully.
Uwaga: Wspomina o "Upgrade", ponieważ jest to polecenie używane przed wykonaniem aktualizacji niezakłócających pracy (NDU). Przyczyną wyświetlenia tych komunikatów jest konieczność ponownego uruchomienia
macierzy (oba SP).Polecenie #2 może również wymagać ponownego uruchomienia komputera, dlatego ważne jest, aby kontrola poprawności działania przebiegała bez żadnego [kodu błędu:].
[Ostrzeżenia] można zignorować, ale komunikatem jest polecenie #2
"Do you still want to continue," i możesz wpisać "yes". Dział pomocy technicznej firmy Dell zaleca jednak usunięcie wszystkich ostrzeżeń i błędów opisanych w programie Health Check przed kontynuowaniem procesu.
Aby ponownie uruchomić procesor pamięci masowej, wykonaj czynności opisane w artykule bazy wiedzy Dell Unity: Jak ponownie uruchomić procesor pamięci masowej (możliwość naprawienia przez użytkownika)
#2 (Optymalne) - możesz przejść do Polecenia #2
"Error code" Operation completed successfully.
Polecenie #2:
svc_change_hw_config -e
Oczekiwany wynik:
service@CKMxxxxxxxx spa:~/user# svc_change_hw_config -e Checking if both SPs are in Normal mode...OK INFO: Beginning eSLIC or CNA Hardware Upgrade... WARNING: This operation will cause several reboots to occur on the Storage Processors. WARNING: Do NOT proceed further if the user is unaware of this downtime! ==============================System Information=============================== Task Manager Command: /opt/ptm/task_mgr.pl Starts at: Sat Oct 5 10:03:47 2019 Dual SP: Yes SP: b Platform: OBERON Original Primary: Yes Model: Unity xxx Serial Number: xxxxxxxxxxxxx Total number of attempts: 0 =============================================================================== ==========================Time Estimate for All Tasks========================== Task name [ 22 tasks in total ] Estimated Status Time(Minutes) 1 Slic wait for system ready slic (local) 3 2 Core run pre upgrade health checks (local) 2 3 ESLIC check eslic configuration (local) 1 4 Core enable auto start (local) 0 5 Core clear boot counters (local) 0 6 Core clear boot counters (remote) 0 7 Core force vdms off sp (remote) 2 8 ESLIC set esp boolean (remote) 1 9 Core disable quickboot (remote) 1 10 Core reboot peer sp if required (local) 10 11 Core start c4 (remote) 5 12 Core wait for system ready on peer 3 13 Core force vdms off sp (local) 2 14 ESLIC set esp boolean (local) 1 15 Core disable quickboot (local) 1 16 Core reboot sp if required (local) 10 17 Core start c4 (local) 5 18 Core wait for system ready (local) 3 19 ESLIC final configuration check (local) 1 20 Core clean up (local) 0 21 Core clean up peer (local) 0 22 Core disable auto start (local) 0 =============================================================================== =========================Estimated Time for Services ========================== Current Time: 10:03 Estimated Time when eSLIC will be complete: 10:52 =============================================================================== Do you wish to continue [ yes or no ]? >
Po wpisaniu "yes" i naciśnięciu "Return" powinny pojawić się poniższe dane wyjściowe:
=====================================Tasks===================================== 20:41 [ 17/22 ] Core start c4 (local) 5 minutes =============================================================================== 20:41 [ 18/22 ] Core wait for system ready (local) 3 minutes =============================================================================== 20:41 [ 19/22 ] ESLIC final configuration check (local) 30 seconds =============================================================================== 20:41 [ 20/22 ] Core clean up (local) 5 seconds =============================================================================== 20:41 [ 21/22 ] Core clean up peer (local) 5 seconds =============================================================================== 20:41 [ 22/22 ] Core disable auto start (local) 5 seconds =============================================================================== ===================================SUMMARY===================================== Status: Success Actual Time Spent: 16452 minutes Total Number of attempts: 1 Log File: /var/tmp/ptm/ptm.log =====================================END=======================================
Są one również zalogowane
/EMC/backend/log_shared/EMCSystemLogFile.log:
Platform_Basic 30018 [NOTICE] Audit: Service user executed the following service script command: svc_change_hw_config -e IOModule 30010 [INFO] User: Starting the hardware configuration commit operation Platform_Basic 30018 [NOTICE] Audit: Service user executed the following service script command: svc_dc -pbc udoctor IOModule 30014 [INFO] User: Completed task <17> of <22> (Restarting services) IOModule 30014 [INFO] User: Completed task <18> of <22> (Waiting for system ready state) IOModule 30014 [INFO] User: Completed task <19> of <22> (Checking if upgrade complete) IOModule 30014 [INFO] User: Completed task <20> of <22> (Cleaning up) IOModule 30014 [INFO] User: Completed task <21> of <22> (Cleaning up) IOModule 30014 [INFO] User: Completed task <22> of <22> (Disabling automatic restart) IOModule 30011 [NOTICE] User: The hardware configuration has been successfully committed Health 6044f [INFO] User: Storage Processor SP A is operating normally Health 6044f [INFO] User: Storage Processor SP B is operating normally
Po wyświetleniu powyższych danych odśwież interfejs użytkownika Unisphere i sprawdź, czy stan zmienił się z powrotem na normalny (oczekiwany).
Jeśli nie, skontaktuj się z działem pomocy technicznej firmy Dell i powołaj się na ten artykuł.
Uwaga: Więcej informacji na temat tego polecenia znajduje się w dokumencie Uwagi techniczne dotyczące poleceń rodziny Dell EMC Unity™ na stronie https://www.dell.com/support/home/en-us
Additional Information
UWAGA: Uszkodzona bateria pastylkowa może również powodować fałszywie dodatni problem z ponownym uruchomieniem SP w interfejsie użytkownika.
Zapoznaj się z artykułem bazy wiedzy 000069296 temat Dell Unity: Bateria pastylkowa procesora pamięci masowej (z możliwością naprawienia przez firmę Dell)
Affected Products
Dell Unity 300, Dell EMC Unity FamilyProducts
Dell EMC Unity 300F, Dell EMC Unity 350F, Dell EMC Unity 400, Dell EMC Unity 400F, Dell EMC Unity 450F, Dell EMC Unity 500, Dell EMC Unity 500F, Dell EMC Unity 550F, Dell EMC Unity 600, Dell EMC Unity 600F, Dell EMC Unity 650F
, Dell EMC Unity Family |Dell EMC Unity All Flash, Dell EMC Unity Family, Dell EMC Unity Hybrid
...
Article Properties
Article Number: 000056107
Article Type: Solution
Last Modified: 04 Dec 2025
Version: 6
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.