Dell Unity: Процесори зберігання відображаються як перезавантаження в інтерфейсі користувача, але не в CLI, і немає несправних світлодіодів (User Correctable)
Summary: У цій статті пояснюється, чому інтерфейс користувача Unisphere може відображати SP деградовані та перезавантаження, коли вони перебувають у нормальному режимі.
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Symptoms
Small Factor Pluggable (SFP) один раз відсутній у журналах, а згодом показує все добре.
Відомо, що SFP залишаються непоміченими, якщо на них трохи пилу або вони не повністю вставлені в порт
.Це поширений фактор погіршення продуктивності, оскільки викликає постійні відключення і може бути відповідальним як пристрій повільного розряду.
У інтерфейсі користувача Unisphere процесори зберігання відображаються як перезавантажені та в деградованому стані на 'SYSTEM' > , 'service' > 'Service Tasks'.
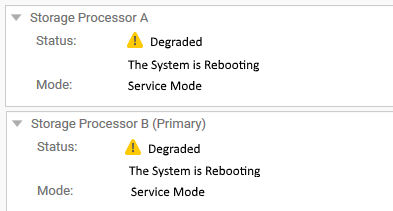
Однак у SSH-терміналі, що використовує CLI, обидва SP працюють у нормальному режимі.
Це вже спостерігалося у версії Unity OE 4.5.1.0.5.001.
Приклад:
service@CKMxxxxxxxx spa:~/user# svc_diag ======== Now executing basic state ======== * System Serial Number is: CKMxxxxxxx * System Model Number is: Unity 500 * System Friendly Host Name is: CKMxxxxxxxx * Current Software version: c4dev_PIE_3786R-4.5.1.0.5.001.1552025209-GNOSIS_RETAIL * Unisphere IP address(es): xx.xxx.xxx.xx xxxx::xxx:xxxx:xxxx:xxxx * SSH Enabled: true * FIPS mode: Disabled * Boot Mode: Normal Mode * Post Faults: 0x0000 * Backend Faults: 0x0000 * Boot Faults: 0x0000 * Rescue Reason: 0x0000 * Rescue reason for code 0x0000 - No faults detected. * SP Service Hint Code: <None>
Cause
Ця конкретна ситуація виникла під час встановлення нових модулів введення/виведення.
Комміт не було завершено через неоптимальний SFP, тому операції, пов'язані зі здоров'ям, тимчасово вимкнені (подібно до того, що відбувається під час оновлень).
Оскільки опитування здоров'я було вимкнене, система не змогла визначити правильний статус процесорів зберігання і повідомляла про попередній відомий статус «перезавантаження».
Щоб підтвердити, що це та сама проблема, перевірте наступні логи: /var/tmp/ptm/ptm.log/EMC/C4Core/log/c4_safe_ktrace.log
Це можна побачити в реальному часі, виконавши команди на SSH-терміналі або в журналах збору даних сервісу:
Команда/журнал #1:
Очікуваний результат:
cat /var/tmp/ptm/ptm.log
Очікуваний результат:
=====================================Tasks===================================== 10:56 [ 16/22 ] Core reboot sp if required (local) 10 minutes Start at: Thu May 23 10:56:19 2019 Complete at: Thu May 23 10:56:19 2019 =============================================================================== 10:56 [ 17/22 ] Core start c4 (local) 5 minutes Start at: Thu May 23 10:56:19 2019 Task Manager was terminated unexpectedly with signal <TERM> .... <there might be a few extra lines here > .... Previous failure detected. Not auto-restarting.
Команда/журнал #2:
І звертайте увагу на події, пов'язані з SFP або мезоніном.
Ми бачимо, що щось пішло не так під час встановлення нових модулів введення/виведення:
less /EMC/C4Core/log/c4_safe_ktrace.log
І звертайте увагу на події, пов'язані з SFP або мезоніном.
Ми бачимо, що щось пішло не так під час встановлення нових модулів введення/виведення:
c4_safe_ktrace INFO OBJ 3 RP:MEZZ(SP: 0, Slot: 0): fbe_base_env_send_resume_prom_read_async_cmd entry. c4_safe_ktrace INFO OBJ 3 RP:MEZZ(SP: 0, Slot: 0): Read async completed, workItem 0x7f2486432760, resumeStatus DEVICE_NOT_VALID_FOR_PLATFO c4_safe_ktrace INFO OBJ 3 100C0 : ModMgmt: CLEAR enclFaultLedReason Mezzanine RP Fault. <<<====== Fault detected in Root Port (RP) .......... c4_safe_ktrace INFO OBJ 3 100C0 : fbe_module_mgmt_check_module_state, SPB Mezzanine 0, state:ENABLED, substate:GOOD c4_safe_ktrace INFO OBJ 3 100C0 : fbe_module_mgmt_check_port_state Setting SPB Mezzanine 0, Port 0, state ENABLED, substate GOOD c4_safe_ktrace INFO OBJ 3 100C0 : fbe_module_mgmt_check_port_state Setting SPB Mezzanine 0, Port 1, state MISSING, substate MISS_SFP <<<=== SFP not detected c4_safe_ktrace INFO OBJ 3 100C0 : fbe_module_mgmt_check_port_state Setting SPB Mezzanine 0, Port 2, state ENABLED, substate GOOD c4_safe_ktrace INFO OBJ 3 100C0 : fbe_module_mgmt_check_port_state Setting SPB Mezzanine 0, Port 3, state ENABLED, substate GOOD c4_safe_ktrace INFO OBJ 3 100C0 : fbe_module_mgmt_check_port_state Setting SPB Mezzanine 0, Port 4, state ENABLED, substate GOOD c4_safe_ktrace INFO OBJ 3 100C0 : fbe_module_mgmt_check_port_state Setting SPB Mezzanine 0, Port 5, state ENABLED, substate GOOD
Resolution
Щоб вирішити цю проблему, повторно зафіксуйте I/O Modules, оскільки вони спочатку не спрацювали, використовуючи наведені нижче команди.
Примітка: Ці команди не потребують root, але потребують здорового масиву, тому перед запуском переконайтеся, що масив повністю працездатний, як такий:
Команда #1:
uemcli -no /sys/general healthcheck -output csv -detail
Приклади результатів:
#1 (НЕ оптимально) — не продовжувати до вирішення помилок).
"Error code" "Warning: One or more asynchronous replication sessions, or one or more NAS Server or file system synchronous replication sessions, exist. This could cause problems during upgrade. Pause the replication sessions on the production array prior to starting the upgrade and resume them after completing the upgrade. [Warning Code: platform::check_replication_health_4]" "Warning: One or more NAS servers may not be in a healthy state. You can continue with the upgrade, but it is recommended that you record the error code and contact your service provider. [Warning Code: dm::check_nas_servers_health_3]" Operation completed successfully.
Примітка: Там згадується «Upgrade», бо це команда, яка використовується перед виконанням Non-Disruptive Upgrades (NDU). Однак причина відображення цих повідомлень полягає в тому, що масив (обидва SP) потрібно перезавантажити.
Команда #2 також може вимагати перезавантаження, тому важливо, щоб ця перевірка здоров'я проходила без жодного [Error Code:].
[Попередження] можна ігнорувати, але Command #2 — це повідомлення
"Do you still want to continue," і ви можете ввести «так». Однак підтримка Dell рекомендує усунути всі попередження та помилки у Health Check перед тим, як продовжити далі.
Щоб перезавантажити процесор зберігання, будь ласка, дотримуйтесь кроків, викладених у KB Dell Unity: Як перезавантажити процесор зберігання (коригується користувачем)
#2 (Оптимально) - можеш перейти до Командування #2
"Error code" Operation completed successfully.
Команда #2:
svc_change_hw_config -e
Очікуваний результат:
service@CKMxxxxxxxx spa:~/user# svc_change_hw_config -e Checking if both SPs are in Normal mode...OK INFO: Beginning eSLIC or CNA Hardware Upgrade... WARNING: This operation will cause several reboots to occur on the Storage Processors. WARNING: Do NOT proceed further if the user is unaware of this downtime! ==============================System Information=============================== Task Manager Command: /opt/ptm/task_mgr.pl Starts at: Sat Oct 5 10:03:47 2019 Dual SP: Yes SP: b Platform: OBERON Original Primary: Yes Model: Unity xxx Serial Number: xxxxxxxxxxxxx Total number of attempts: 0 =============================================================================== ==========================Time Estimate for All Tasks========================== Task name [ 22 tasks in total ] Estimated Status Time(Minutes) 1 Slic wait for system ready slic (local) 3 2 Core run pre upgrade health checks (local) 2 3 ESLIC check eslic configuration (local) 1 4 Core enable auto start (local) 0 5 Core clear boot counters (local) 0 6 Core clear boot counters (remote) 0 7 Core force vdms off sp (remote) 2 8 ESLIC set esp boolean (remote) 1 9 Core disable quickboot (remote) 1 10 Core reboot peer sp if required (local) 10 11 Core start c4 (remote) 5 12 Core wait for system ready on peer 3 13 Core force vdms off sp (local) 2 14 ESLIC set esp boolean (local) 1 15 Core disable quickboot (local) 1 16 Core reboot sp if required (local) 10 17 Core start c4 (local) 5 18 Core wait for system ready (local) 3 19 ESLIC final configuration check (local) 1 20 Core clean up (local) 0 21 Core clean up peer (local) 0 22 Core disable auto start (local) 0 =============================================================================== =========================Estimated Time for Services ========================== Current Time: 10:03 Estimated Time when eSLIC will be complete: 10:52 =============================================================================== Do you wish to continue [ yes or no ]? >
Після того, як ви введете "yes" і натиснете клавішу "Return", ви повинні побачити наступний вихід:
=====================================Tasks===================================== 20:41 [ 17/22 ] Core start c4 (local) 5 minutes =============================================================================== 20:41 [ 18/22 ] Core wait for system ready (local) 3 minutes =============================================================================== 20:41 [ 19/22 ] ESLIC final configuration check (local) 30 seconds =============================================================================== 20:41 [ 20/22 ] Core clean up (local) 5 seconds =============================================================================== 20:41 [ 21/22 ] Core clean up peer (local) 5 seconds =============================================================================== 20:41 [ 22/22 ] Core disable auto start (local) 5 seconds =============================================================================== ===================================SUMMARY===================================== Status: Success Actual Time Spent: 16452 minutes Total Number of attempts: 1 Log File: /var/tmp/ptm/ptm.log =====================================END=======================================
Вони також увійшли в систему
/EMC/backend/log_shared/EMCSystemLogFile.log:
Platform_Basic 30018 [NOTICE] Audit: Service user executed the following service script command: svc_change_hw_config -e IOModule 30010 [INFO] User: Starting the hardware configuration commit operation Platform_Basic 30018 [NOTICE] Audit: Service user executed the following service script command: svc_dc -pbc udoctor IOModule 30014 [INFO] User: Completed task <17> of <22> (Restarting services) IOModule 30014 [INFO] User: Completed task <18> of <22> (Waiting for system ready state) IOModule 30014 [INFO] User: Completed task <19> of <22> (Checking if upgrade complete) IOModule 30014 [INFO] User: Completed task <20> of <22> (Cleaning up) IOModule 30014 [INFO] User: Completed task <21> of <22> (Cleaning up) IOModule 30014 [INFO] User: Completed task <22> of <22> (Disabling automatic restart) IOModule 30011 [NOTICE] User: The hardware configuration has been successfully committed Health 6044f [INFO] User: Storage Processor SP A is operating normally Health 6044f [INFO] User: Storage Processor SP B is operating normally
Після того, як наведений вище вихід буде відображено, оновіть інтерфейс користувача Unisphere і подивіться, чи статус повернувся до норми (очікувано).
Якщо ні, зверніться до технічної підтримки Dell і зверніться до цієї статті.
Примітка: Більше інформації про цю команду міститься в документі Dell EMC™ Unity Family Service Commands Technical Notes, за сторінкою https://www.dell.com/support/home/en-us
Additional Information
ПРИМІТКА: Також можлива несправна батарейка Coin Cell, що спричиняє проблему з хибнопозитивним SP перезавантаженням у інтерфейсі.
Див. KB 000069296 Dell Unity: Акумулятор монетної комірки на процесорі зберігання (Dell Correctable)
Affected Products
Dell Unity 300, Dell EMC Unity FamilyProducts
Dell EMC Unity 300F, Dell EMC Unity 350F, Dell EMC Unity 400, Dell EMC Unity 400F, Dell EMC Unity 450F, Dell EMC Unity 500, Dell EMC Unity 500F, Dell EMC Unity 550F, Dell EMC Unity 600, Dell EMC Unity 600F, Dell EMC Unity 650F
, Dell EMC Unity Family |Dell EMC Unity All Flash, Dell EMC Unity Family, Dell EMC Unity Hybrid
...
Article Properties
Article Number: 000056107
Article Type: Solution
Last Modified: 04 Dec 2025
Version: 6
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.