PowerScale, Isilon OneFS: Testování výkonu databáze HBase v řešení Isilon
Summary: Tento článek popisuje srovnávací testy výkonu v clusteru Isilon X410 pomocí sady Yahoo Cloud Serving Benchmarking (YCSB) a řešení Cloudera Data Hub (CDH) 5.10.
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Symptoms
Není vyžadováno
Cause
Není vyžadováno
Resolution
POZNÁMKA: Toto téma je součástí informačního centra Použití platformy Hadoop se systémem OneFS.
Úvod
Na clusteru Isilon X410 s využitím sady YCSB benchmarking suite a CDH 5.10 byla provedena řada výkonnostních benchmarkingových testů.
Testovací prostředí bylo nakonfigurováno s pěti uzly Isilon x410 se systémem OneFS v8.0.0.4 a novějším v8.0.1.1. Byly spuštěny srovnávací testy streamování systému souborů NFS (Network File System) Large Block. Očekávané teoretické agregované maximum pro testy bylo ~700 MB/s (3,5 GB/s) zápis a ~1 GB/s čtení (5 GB/s) na uzel.
(9) výpočetních uzlů jsou servery Dell PowerEdge FC630 se systémem CentOS verze 7.3.1611, každý konfigurovaný s procesorem 2x18C/36T-Intel Xeon® CPU E5-2697 v4 @ 2.30GHz s 512 GB paměti RAM. Místní úložiště je 2xSSD v poli RAID 1 formátované jako XFS pro operační systém i pro odkládání nebo nepotřebné soubory.
K dispozici byly také tři další servery Edge, které byly použity k řízení zatížení YCSB.
Backendová síť mezi výpočetními uzly a řešením Isilon je 10 Gb/s s nastavenými rámci typu Jumbo (MTU = 9162) pro síťové karty a porty přepínače.
Součásti konfigurace testu Hadoop (obrázek 1)
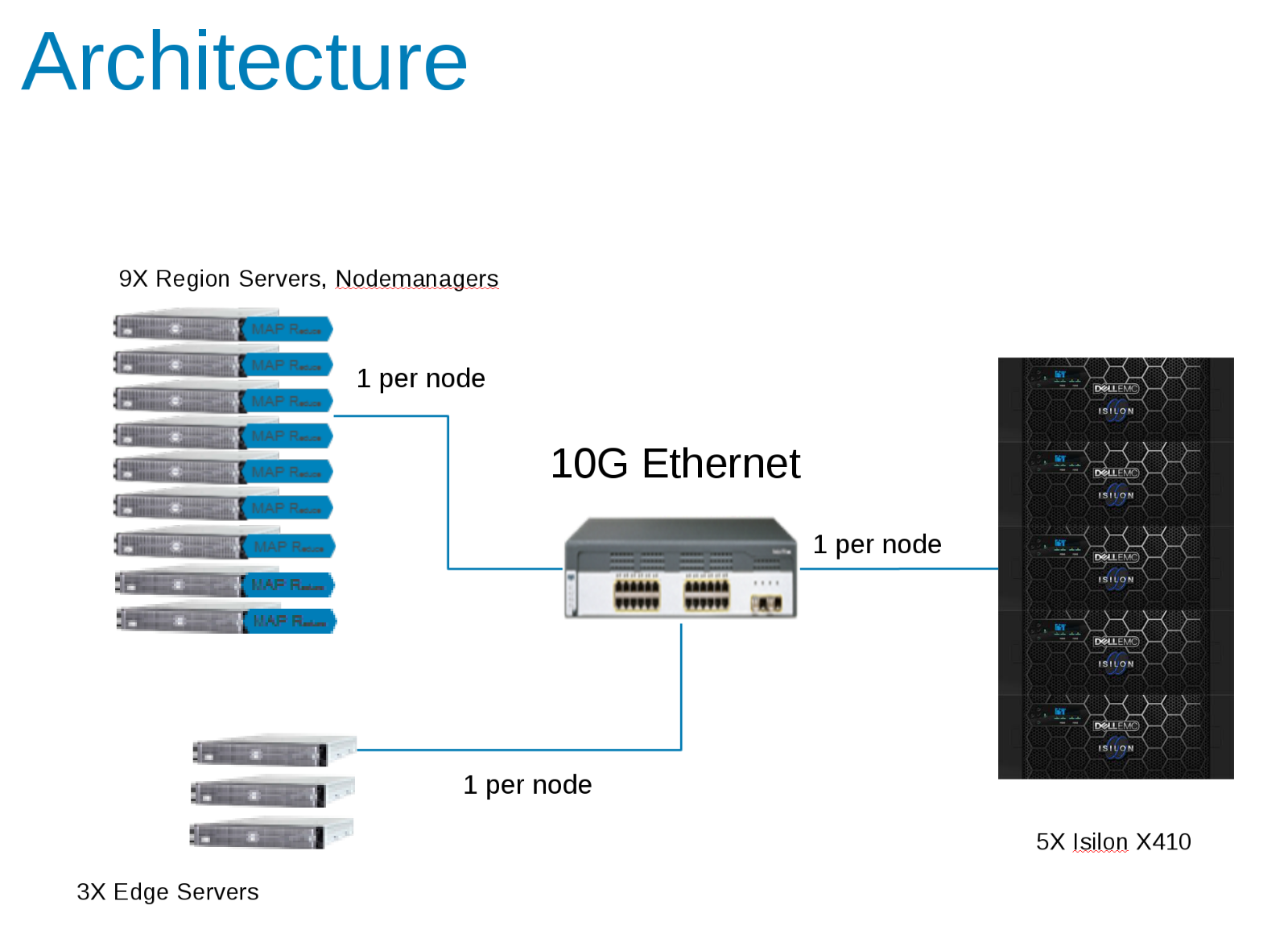
Funkce CDH 5.10 byla nakonfigurována pro spuštění v zóně přístupu v clusteru Isilon. Účty služeb byly vytvořeny u místního poskytovatele Isilon a místně v klientských souborech /etc/passwd. Všechny testy byly spuštěny pomocí základního testovacího klienta bez zvláštních oprávnění.
Statistiky řešení Isilon byly monitorovány pomocí nástroje IIQ i balíčku Grafana/Data Insights. Statistiky CDH byly sledovány pomocí Cloudera Manager a také pomocí Grafany.
Počáteční testování
První série testů měla určit relevantní parametry na straně HBASE, které ovlivnily celkový výstup. Nástroj YCSB byl použit ke generování zatížení pro HBA. Tento počáteční test byl spuštěn pomocí jednoho klienta (hraničního serveru) pomocí fáze načítání YCSB a 40 milionů řádků. Tato tabulka byla před každým spuštěním odstraněna.
ycsb load hbase10 -P workloads/workloada1 -p table='ycsb_40Mtable_nr' -p columnfamily=family -threads 256 -p recordcount=40000000
- hbase.regionserver.maxlogs – Maximální počet souborů protokolu WAL (Write-Ahead Log) – Tato hodnota vynásobená velikostí bloku HDFS (dfs.blocksize) je velikost hal, kterou je nutné přehrát při chybě serveru. Tato hodnota je nepřímo úměrná frekvenci vyprázdnění disku.
- hbase.wal.regiongrouping.numgroups – Při použití více HDFS WAL jako WALProvider se nastaví, kolik protokolů write-ahead-logs by měl každý RegionServer spustit. Výsledky ukazují počet kanálů HDFS. Zápisy pro danou oblast přecházejí pouze do jednoho kanálu, čímž se celkové zatížení regionserveru rozloží.
Propustnost v porovnání s počtem kanálů (obrázek 2)
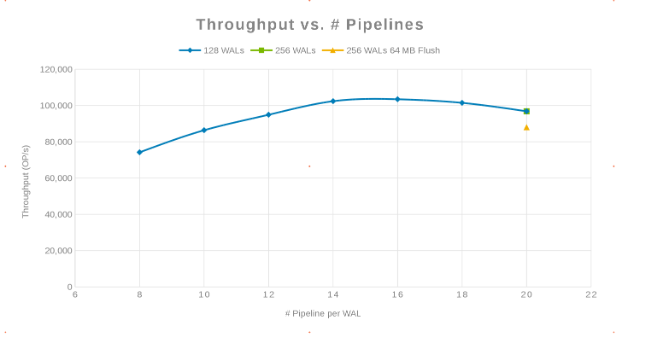
Latence v porovnání s počtem kanálů (obrázek 3)
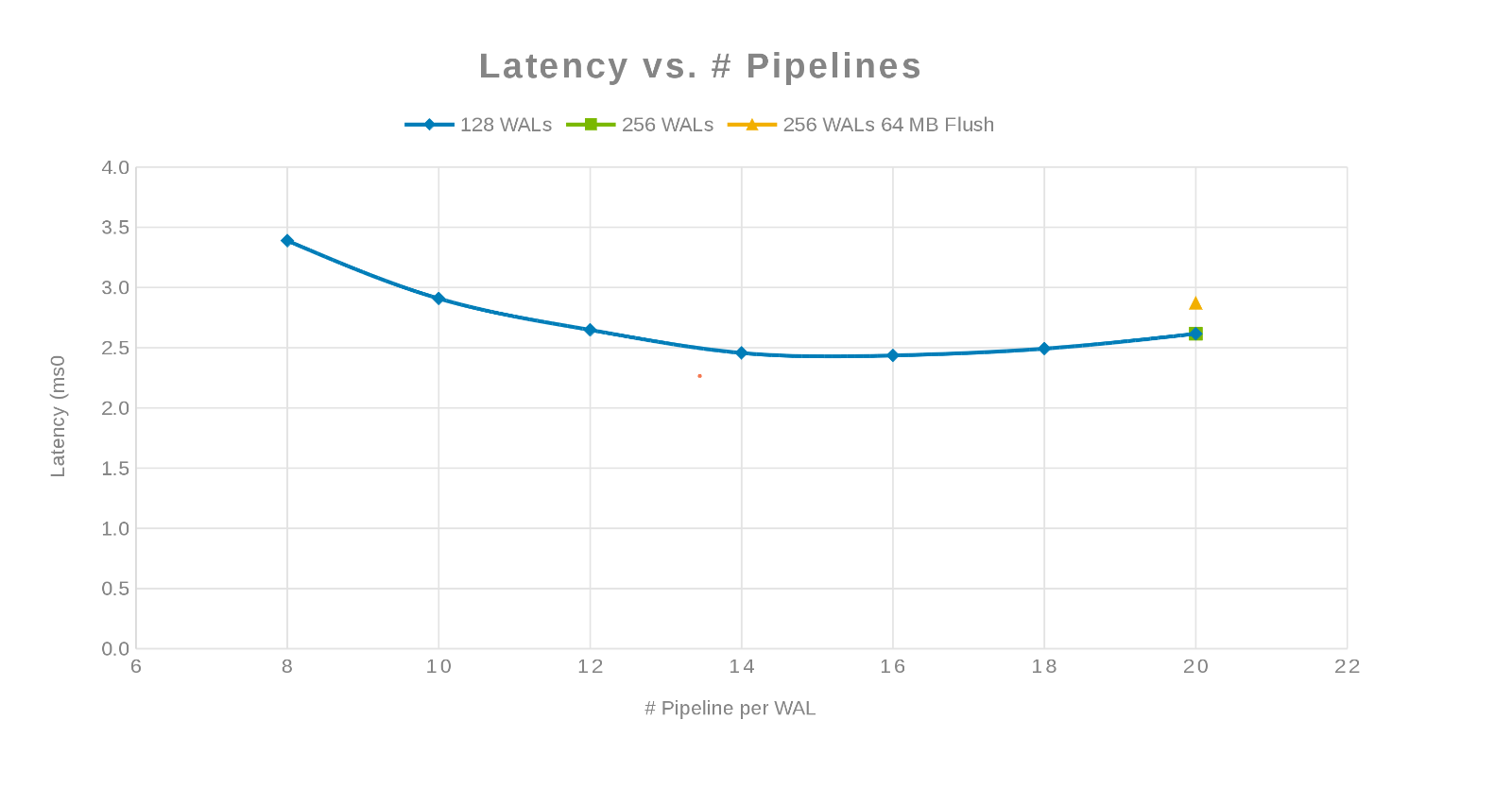
Filozofií zde bylo paralelizovat co nejvíce spisů. Zvýšení počtu WAL a následného počtu vláken (kanálu) na WAL toho dosáhne. Předchozí dva grafy ukazují, že pro dané číslo pro "maxlogy", 128 nebo 256, se nezobrazuje žádná skutečná změna. To znamená, že test ve skutečnosti nemá vliv na výsledky na straně klienta. Počet kanálů na soubor se lišil, což vykazovalo trend označující parametr, který je citlivý na paralelizaci. Další otázkou je, kde cluster Isilon "překáží" při vstupu a výstupu disku, síti, procesoru nebo systému OneFS. Chcete-li odpovědět na tuto otázku, podívejte se na statistickou zprávu Isilon.
Využití a zatížení sítě Isilon během testu (obrázek 4)
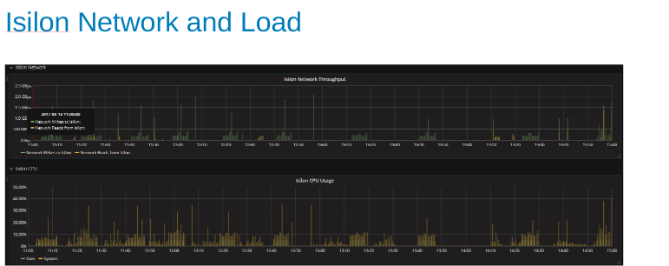
Grafy sítě a procesoru nám říkají, že cluster Isilon je nedostatečně využitý a má prostor pro další práci. Procesor by byl > 80 % a šířka pásma sítě by byla větší než 3 GB/s.
Grafy statistik protokolu HDFS a využití procesoru při zatížení protokolu HDFS (obrázek 5)
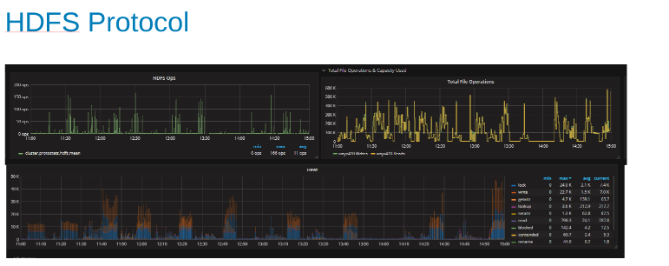
Tyto grafy ukazují statistiky protokolu HDFS a způsob, jakým systém OneFS překládá výstup. Operace HDFS jsou násobky velikosti dfs.blocksize, což je zde 256 MB. Zajímavé je, že graf "Heat" zobrazuje operace se soubory OneFS a zobrazuje korelaci zápisů a zámků. V tomto případě se HBase připojuje k přepínačům WAL, takže systém OneFS uzamkne soubor WAL pro každý připojený zápis. Což je to, co se očekává pro stabilní zápisy do clusterovaného systému souborů. Zdá se, že ty přispívají k limitujícímu faktoru v tomto souboru testů.
Aktualizace HBase
Tento další test spočíval v dalším experimentování, aby se zjistilo, co se děje ve velkém měřítku. Vytvoří se tabulka s 1 miliardou řádků, jejíž generování trvalo hodinu. Spustí se test YCSB, který aktualizuje 10 milionů řádků pomocí nastavení "workloada" (čtení/zápis 50/50). Tento test byl spuštěn na jednom klientovi. Test byl spuštěn v závislosti na počtu vláken YCSB, aby bylo možné generovat co největší propustnost. Také bylo provedeno určité ladění a systém OneFS byl upgradován na verzi 8.0.1.1, která obsahuje vylepšení výkonu služby datového uzlu. Následující graf ukazuje nárůst výkonu ve srovnání s předchozí sadou spuštění. Pro tato spuštění je hbase.regionserver.maxlogs nastavená na 256 a hbase.wal.regiongrouping.numgroups na 20.
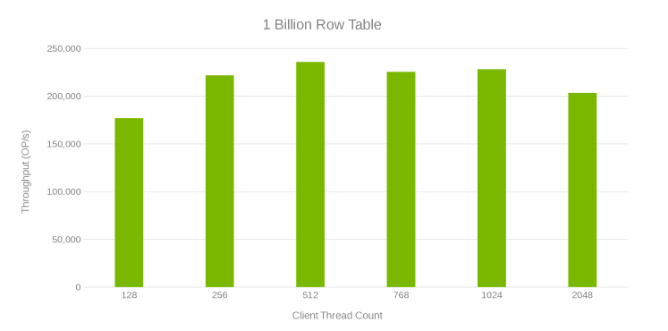
Propustnost a počet vláken při aktualizaci tabulky řádků s 1 miliardou (obrázek 6)
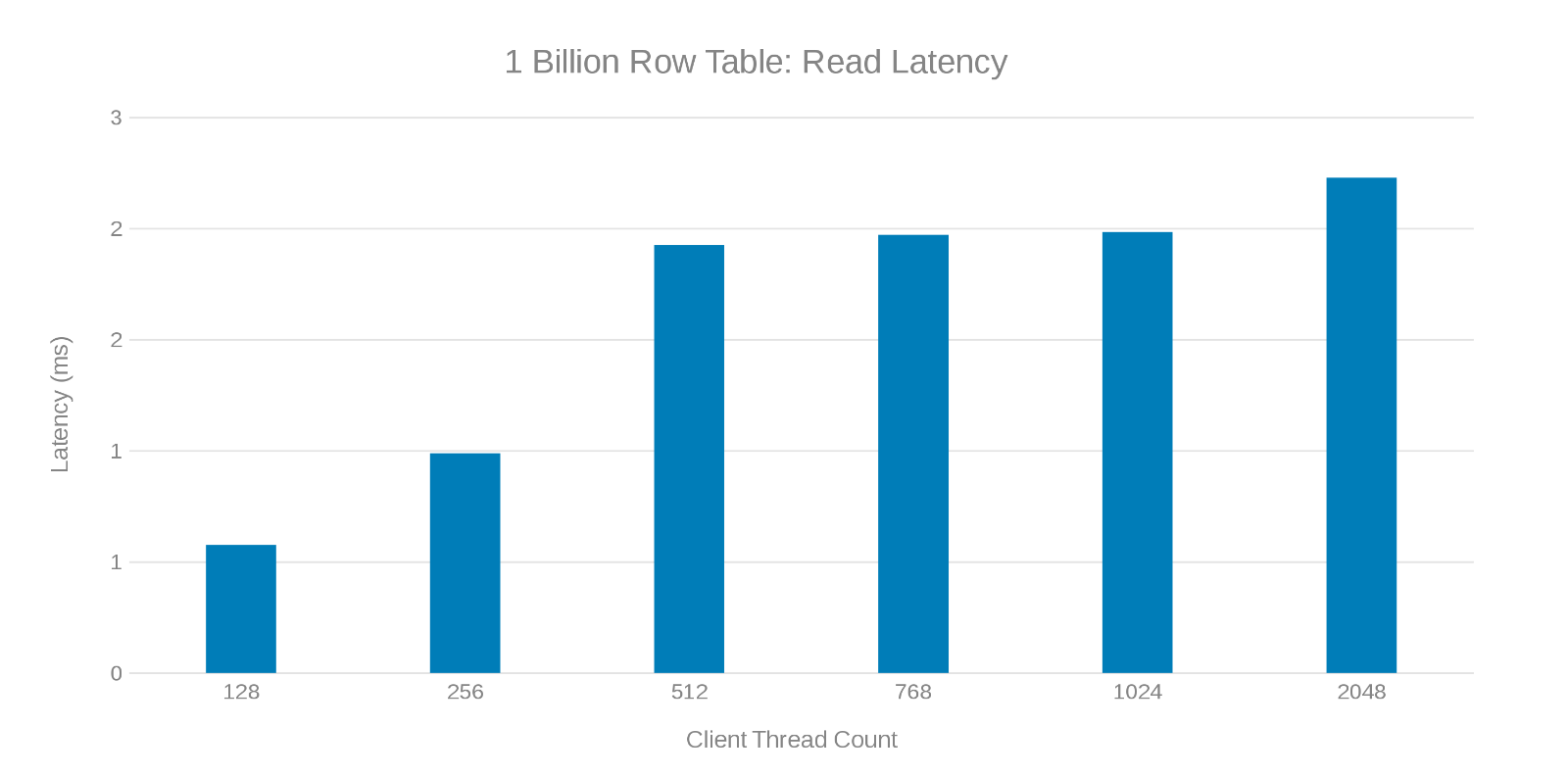
Latence čtení při aktualizaci tabulky řádků s 1 miliardou (obrázek 7)
Aktualizace latence při aktualizaci tabulky řádků s 1 miliardou (obrázek 8)
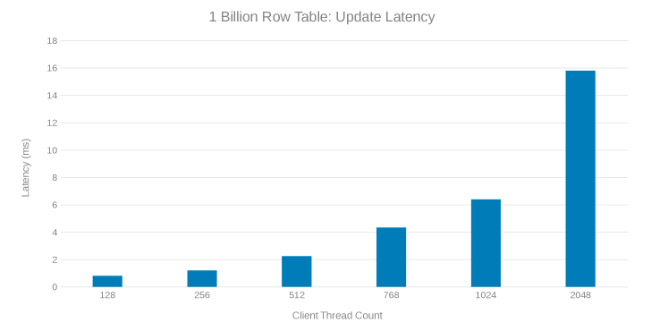
Kontrola těchto testovacích běhů ukazuje zřejmý pokles při vysokém počtu vláken, což může být problém Isilon nebo na straně klienta. Testování ukazuje a dosahuje 200 tisíc operací za sekundu při latenci < aktualizace 3 ms. Každý z testovacích běhů aktualizace byl rychlý a bylo možné jej spustit po sobě. Níže uvedený graf ukazuje rovnováhu, kterou uzly Isilon zajišťují při každém testovacím běhu.
Tepelný graf znázorňující zatížení jednotlivých uzlů v clusteru Isilon (obrázek 9)
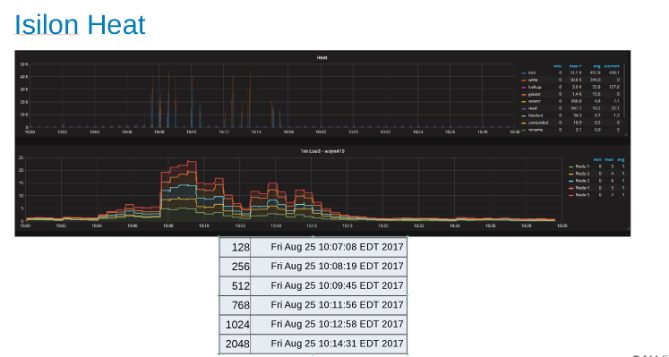
Tepelný graf ukazuje, že operace se soubory jsou zápisy a zámky, které odpovídají povaze připojení procesů WAL.
Škálování regionálního serveru
Dalším testem bylo zjistit, jak si uzly Isilon (pět uzlů) povedou proti různému počtu regionálních serverů. Stejný aktualizační skript spuštěný v předchozím testu byl spuštěn s tabulkou jedné miliardy řádků a aktualizací 10 milionů řádků pomocí workloada. Test používal jednoho klienta s vlákny YCSB nastavenými na 51. Stejné nastavení se použije pro maxlogy a kanály (256 a 20).
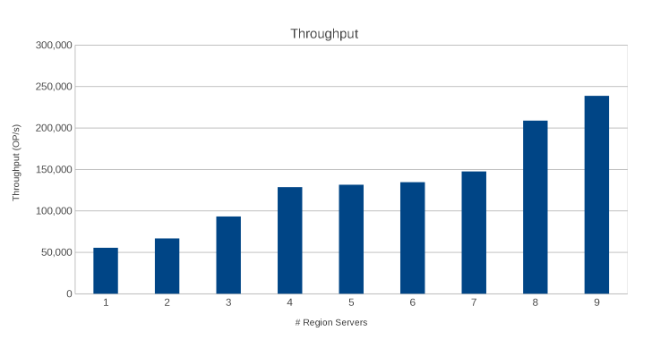
Propustnost mezi oblastními servery (obrázek 10)
Latence mezi oblastními servery (obrázek 11)
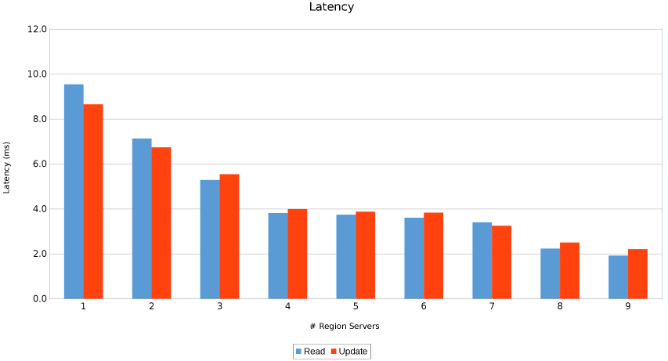
Výsledky jsou informativní, i když ne překvapivé. Škálovatelná povaha databáze HBase v kombinaci s horizontálně škálovatelnou povahou řešení Isilon ukázala, že více je lépe. Tento test se doporučuje, aby klienti běželi ve svých prostředích jako součást vlastního cvičení velikosti. Zde je devět serverů, které tlačí na pět uzlů Isilon, a vypadá to, že stále existuje prostor pro další, než dosáhnou bodu klesající návratnosti.
Více klientů
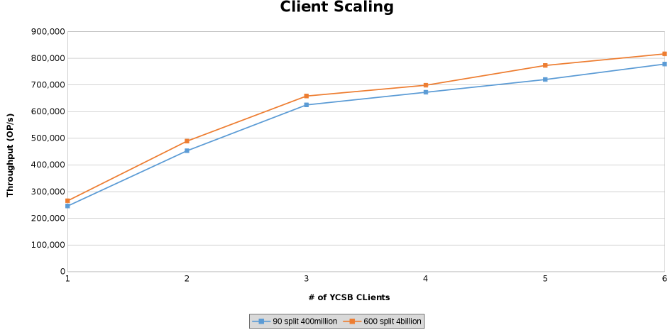
Poslední série testů sloužila k otestování limitů hardwarové konfigurace. To bylo provedeno za účelem stanovení horní hranice testovaných parametrů. V této sérii testů se ke spouštění klientů používají dva další servery. Kromě toho jsou z každého serveru spuštěni dva klienti YCSB, což umožňuje každému až šest klientů. Každý klient řídil 512 vláken, což vedlo k celkovému počtu 4096 vláken. Byly vytvořeny dvě různé tabulky. Jedna tabulka se 4 miliardami řádků rozdělená do 600 oblastí a druhá se 400 miliony řádků rozdělených do 90 oblastí.
Tím se znázorňuje propustnost operací při testování škálování klienta (obrázek 12) .
Měření latence čtení při testování škálování klienta (obrázek 13)
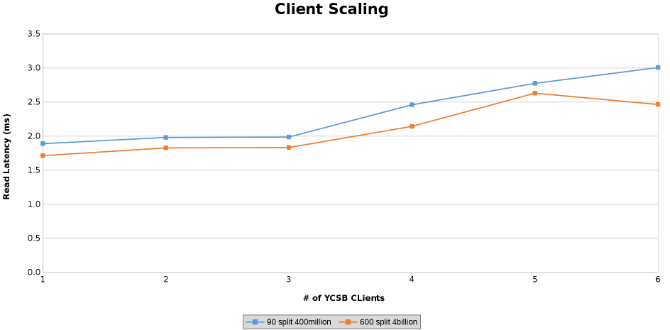
Měření latence aktualizace při testování škálování klienta (obrázek 14)
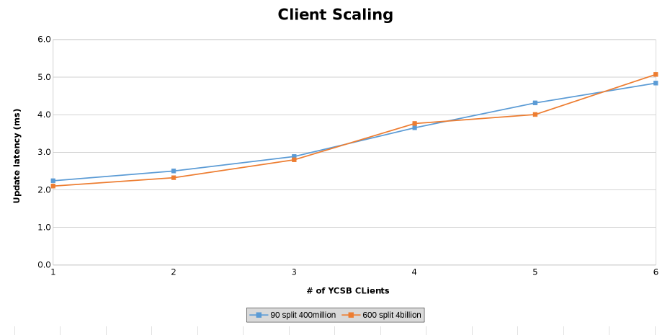
Níže uvedené grafy ukazují, že na velikosti tabulky v tomto testu příliš nezáleží. Teplotní grafy řešení Isilon opět ukazují, že v počtu operací se soubory je patrný několikaprocentní rozdíl. Většina rozdílů byla v souladu s rozdíly mezi tabulkou se čtyřmi miliardami řádků a tabulkou se 400 miliony řádků.
Porovnání tepla pracovního zatížení Isilon při aktualizaci tabulky se 400 miliony řádků v porovnání s tabulkou se 4 miliardami řádků (obrázek 15).
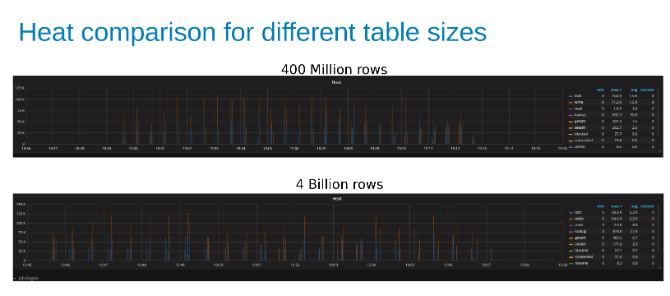
Závěr
HBase je dobrým kandidátem pro provoz v řešení Isilon, a to hlavně kvůli architekturám s horizontálním navýšením kapacity na více systémů. HBase provádí spoustu vlastního ukládání do mezipaměti a rozdělením tabulky napříč velkým počtem oblastí může HBase škálovat na více instancí s daty. Jinými slovy, odvádí dobrou práci, když se stará o své vlastní potřeby, a souborový systém je tu pro odolnost aplikací. Testování nedokázalo tlačit zátěž do bodu, kdy se věci rozbily. Pokud je adaptér HBA navržený pro 800 000 operací s latencí menší než 3 ms, tato architektura ho podporuje. HBase podporuje nesčetné množství úprav a vylepšení výkonu jak na straně klienta, tak na straně HBase samotné. Testování všech těchto úprav a úprav bylo nad rámec tohoto testu.Affected Products
Isilon, PowerScale OneFSArticle Properties
Article Number: 000128942
Article Type: Solution
Last Modified: 11 Mar 2026
Version: 7
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.