PowerScale, Isilon OneFS: Teste de desempenho do HBase no Isilon
Summary: Este artigo ilustra os testes comparativos de desempenho em um cluster do Isilon X410 usando a suíte Yahoo Cloud Serving Benchmarking (YCSB) e o Cloudera Data Hub (CDH) 5.10.
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Symptoms
Não obrigatório
Cause
Não obrigatório
Resolution
Nota: Este tópico faz parte do Hub de informações usando o Hadoop com o OneFS.
Introdução
Uma série de testes comparativos de desempenho foi realizada em um cluster Isilon X410 usando o conjunto de benchmarking YCSB e o CDH 5.10.
O ambiente de teste de laboratório foi configurado com cinco nós do Isilon x410 executando o OneFS v8.0.0.4 e versões posteriores v8.0.1.1. As referências de desempenho de streaming de grandes blocos do NFS (Network File System, sistema de arquivos de rede) foram executadas. O máximo teórico agregado esperado para os testes foi de ~700 MB/s (3,5 GB/s) gravações e ~1 GB/s leituras (5 GB/s) por nó.
Os (9) nós de computação são servidores Dell PowerEdge FC630 executando o CentOS v7.3.1611, cada configurado com 2x18C/36T-Intel Xeon® CPU E5-2697 v4 @ 2,30GHz com 512 GB de RAM. O armazenamento local é 2xSSD no RAID 1 formatado como XFS para o sistema operacional e espaço de rascunho ou arquivos de derramamento.
Também havia três servidores de borda adicionais que foram usados para impulsionar a carga do YCSB.
A rede de back-end entre os nós de computação e o Isilon é de 10 Gbps com jumbo frames definidos (MTU = 9162) para as NICs e as portas do switch.
Os componentes da configuração de teste do Hadoop (Figura 1)
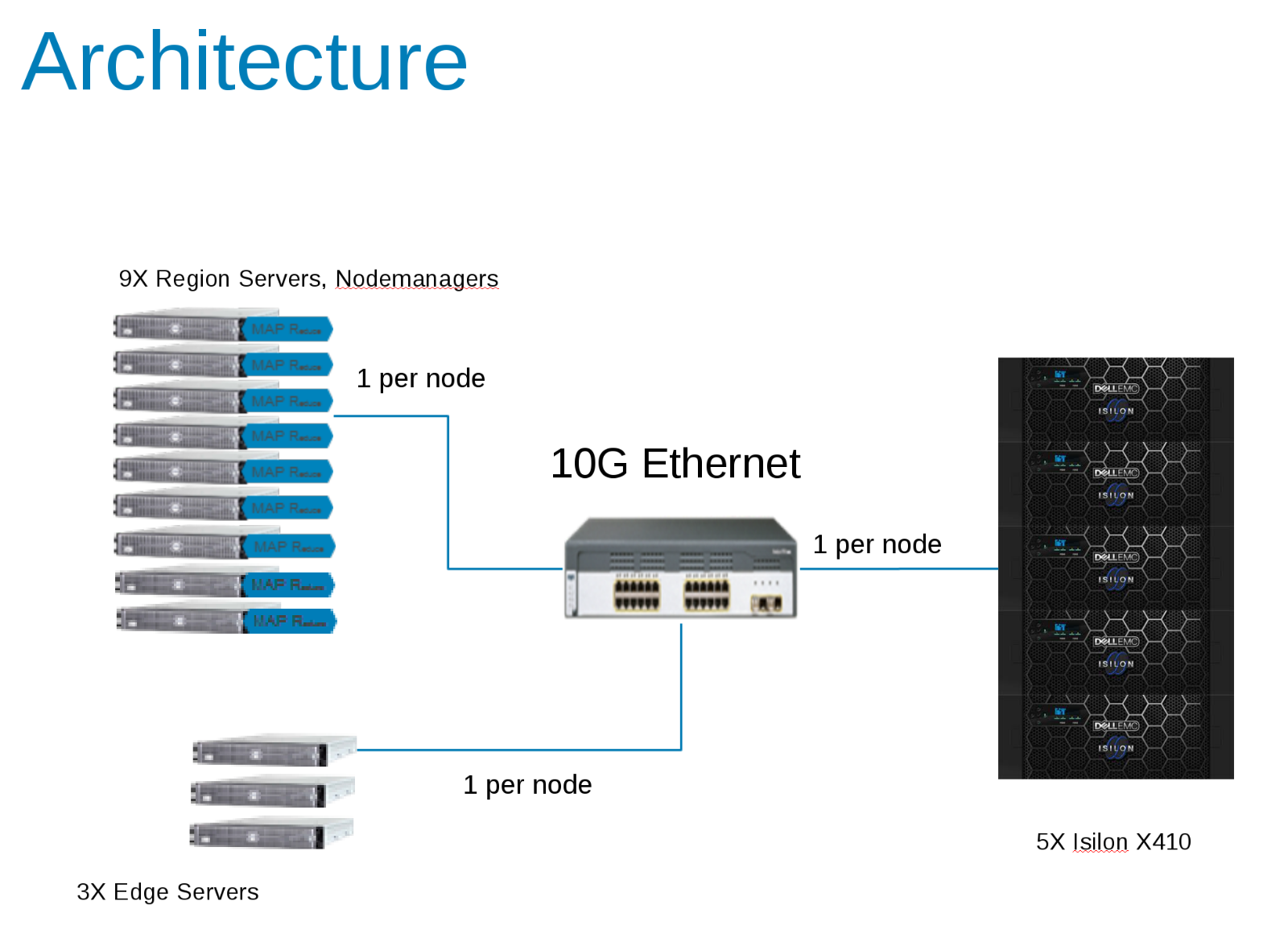
O CDH 5.10 foi configurado para ser executado em uma zona de acesso no cluster do Isilon. As contas de serviço foram criadas no provedor local do Isilon e localmente nos arquivos /etc/passwd do client. Todos os testes foram executados usando um cliente de teste básico sem privilégios especiais.
As estatísticas do Isilon foram monitoradas com o pacote IIQ e Grafana/Data Insights. As estatísticas de CDH foram monitoradas com o Cloudera Manager e também com a Grafana.
Testes iniciais
A primeira série de testes foi para determinar os parâmetros relevantes no lado do HBASE que afetaram a saída geral. A ferramenta YCSB foi utilizada para gerar a carga para o HBASE. Esse teste inicial foi executado usando um único client (servidor de borda) usando a fase de "carga" do YCSB e 40 milhões de linhas. Essa tabela foi excluída antes de cada execução.
ycsb load hbase10 -P workloads/workloada1 -p table='ycsb_40Mtable_nr' -p columnfamily=family -threads 256 -p recordcount=40000000
- hbase.regionserver.maxlogs — número máximo de arquivos de registro de gravação antecipada (WAL) — esse valor multiplicado pelo tamanho do bloco do HDFS (dfs.blocksize) é o tamanho do WAL que deve ser reproduzido quando um servidor trava. Esse valor é inversamente proporcional à frequência de flushes no disco.
- hbase.wal.regiongrouping.numgroups - Ao usar vários WAL do HDFS como WALProvider, isso define quantos logs de gravação antecipada cada RegionServer deve executar. Os resultados mostram o número de pipelines do HDFS. As gravações para uma determinada Região vão apenas para um único pipeline, espalhando a carga total do RegionServer.
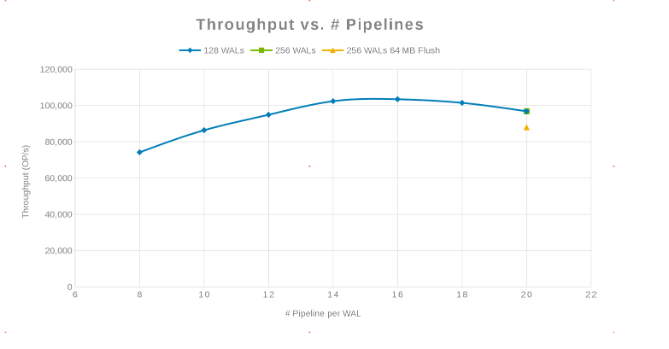
Throughput em comparação com o número de pipelines (Figura 2)
Latência em comparação com o número de pipelines (Figura 3)
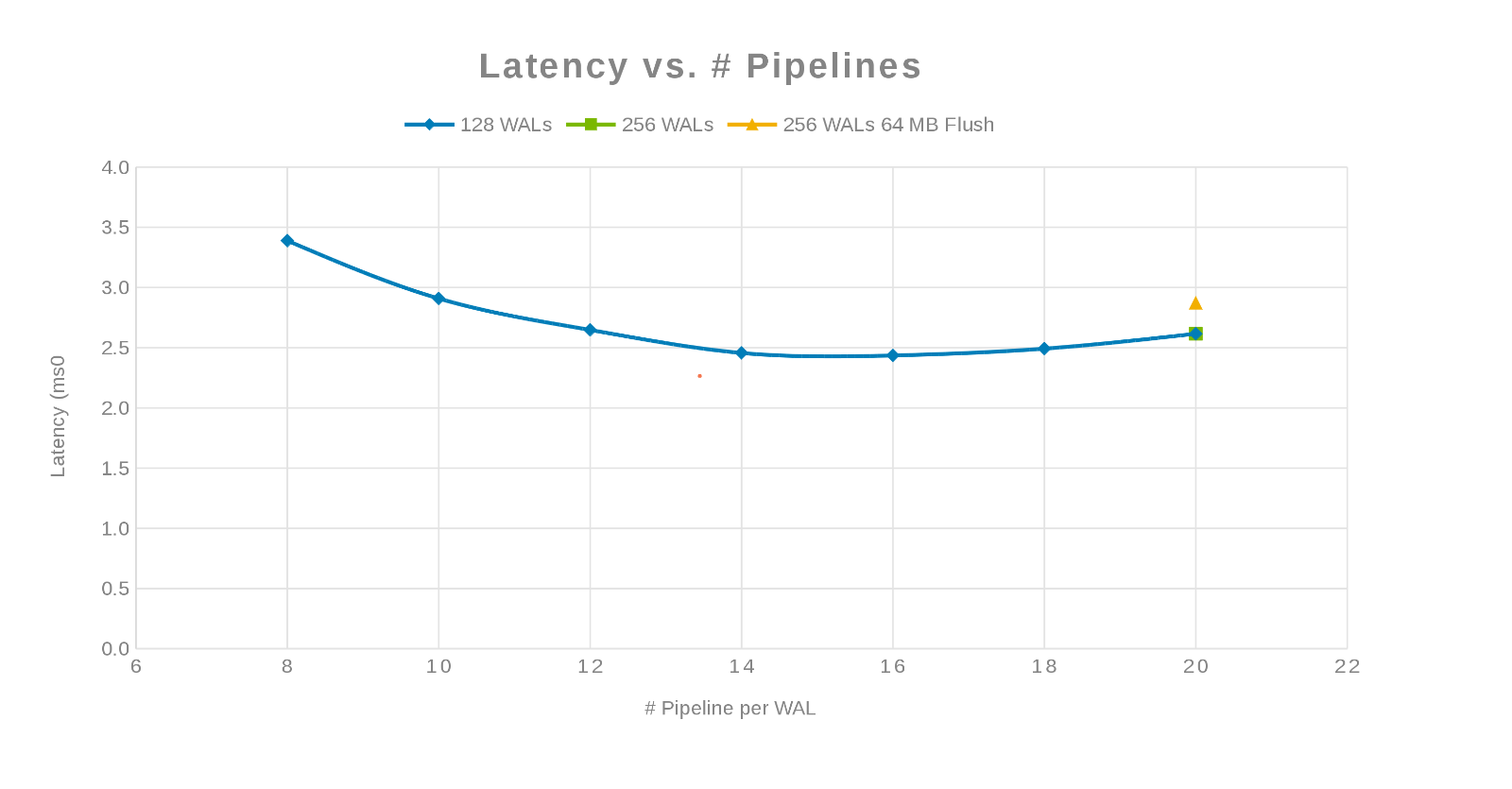
A filosofia aqui era paralelizar o maior número possível de escritos. Aumentar o número de WALs e, em seguida, o número de threads (pipeline) por WAL faz isso. Os dois gráficos anteriores mostram que, para um determinado número para 'maxlogs', 128 ou 256, nenhuma mudança real é mostrada. Isso indica que o teste não está realmente afetando os resultados do lado do client. O número de 'pipelines' por arquivo variou, o que mostrou uma tendência que indica o parâmetro que é sensível à paralelização. A próxima pergunta é: onde o cluster do Isilon "atrapalha" com E/S de disco, rede, CPU ou OneFS? Para responder a essa pergunta, consulte o relatório de estatísticas do Isilon.
A utilização da rede do Isilon e a carga durante o teste (Figura 4)
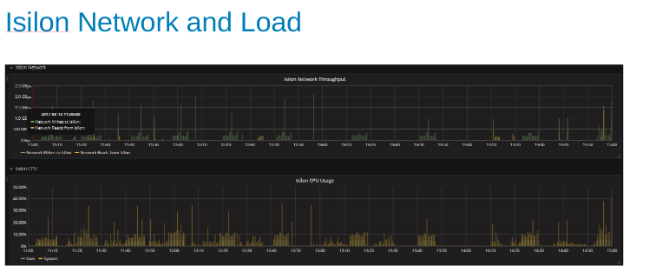
Os gráficos de rede e CPU nos dizem que o cluster do Isilon é subutilizado e tem espaço para mais trabalho. A CPU seria > de 80% e a largura de banda da rede seria superior a 3 GB/s.
Gráficos da estatística do protocolo HDFS e da utilização da CPU durante a carga do protocolo HDFS (Figura 5)
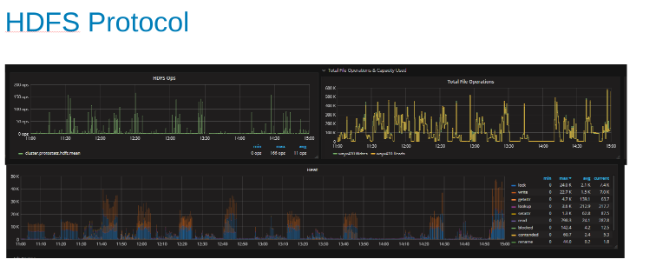
Esses gráficos mostram as estatísticas do protocolo HDFS e como o OneFS converte o resultado. As operações do HDFS são múltiplos de dfs.blocksize, que aqui é de 256 MB. O interessante aqui é que o gráfico "Calor" mostra as operações de arquivo do OneFS e a correlação de gravações e bloqueios é mostrada. Nesse caso, o HBase está fazendo acréscimos aos WALs para que o OneFS bloqueie o arquivo do WAL para cada gravação acrescentada. Que é o que é esperado para gravações estáveis em um sistema de arquivos em cluster. Estes parecem estar contribuindo para o fator limitante nesse conjunto de testes.
Atualizações do HBase
Este próximo teste foi fazer mais experimentos para encontrar o que acontece em escala. É criada uma tabela de 1 bilhão de linhas que levou uma hora para ser gerada. É executado um teste YCSB que atualizou 10 milhões de linhas usando as configurações de "workloada" (leitura/gravação 50/50). Esse teste foi executado em um único client. O teste foi executado como uma função do número de threads YCSB para que a taxa de transferência máxima possa ser gerada. Além disso, alguns ajustes foram aplicados e o OneFS recebeu upgrade para a versão v8.0.1.1, que tem ajustes de desempenho para o serviço de nó de dados. O gráfico a seguir mostra o aumento no desempenho em comparação com o conjunto anterior de execuções. Para essas execuções, hbase.regionserver.maxlogs é definido como 256 e hbase.wal.regiongrouping.numgroups como 20.
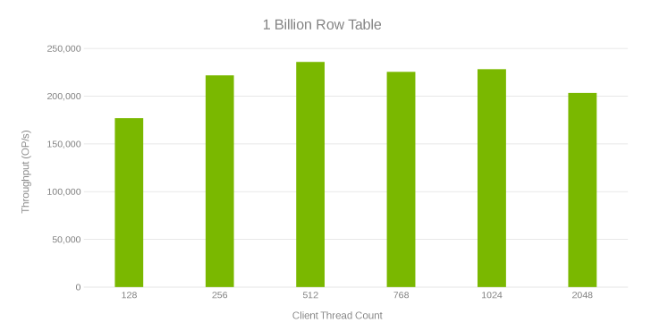
Throughput e contagem de threads durante a atualização da tabela de 1 bilhão de linhas (Figura 6)
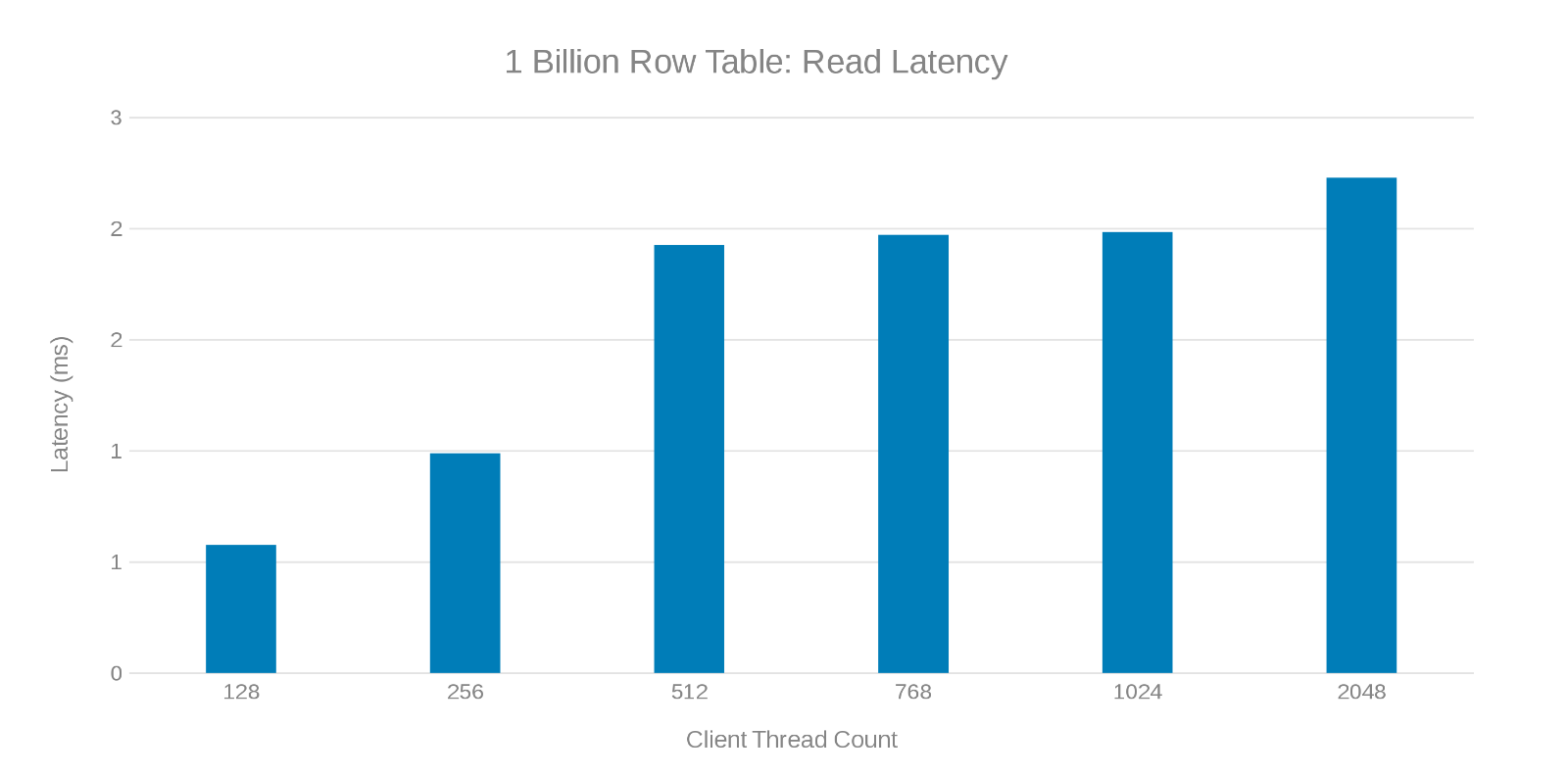
Latência de leitura ao atualizar a tabela de 1 bilhão de linhas (Figura 7)
Latência de atualização ao atualizar a tabela de 1 bilhão de linhas (Figura 8)
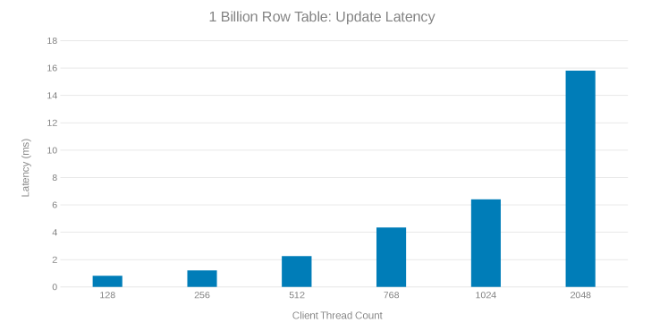
A análise dessas execuções de teste mostra uma queda aparente em alta contagem de threads, o que pode ser um problema do Isilon ou do lado do client. Os testes mostram e impressionam 200 mil operações por segundo com uma latência de atualização de < 3 ms. Cada uma das execuções de teste de atualização foi rápida e pôde ser executada consecutivamente. O gráfico a seguir mostra um equilíbrio uniforme entre os nós do Isilon para cada execução de teste.
Gráfico de calor indicando a carga de trabalho em cada nó do cluster do Isilon (Figura 9)
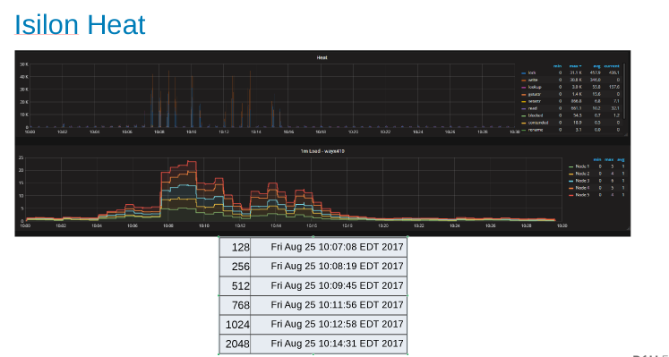
O gráfico de calor mostra que as operações de arquivo são gravações e bloqueios correspondentes à natureza de acréscimo dos processos do WAL.
Dimensionamento do servidor da região
O próximo teste foi determinar como os nós do Isilon (cinco nós) se sairiam em relação a um número diferente de servidores da região. O mesmo script de atualização executado no teste anterior foi executado envolvendo uma tabela de um bilhão de linhas e uma atualização de 10 milhões de linhas usando "workloada". O teste usou um único client com threads YCSB definidos como 51. A mesma configuração para maxlogs e pipelines é aplicada (256 e 20, respectivamente).
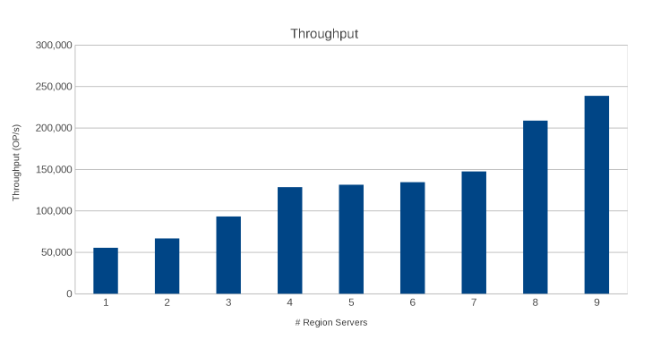
Throughput nos servidores regionais (Figura 10)
Latência entre servidores regionais (Figura 11)
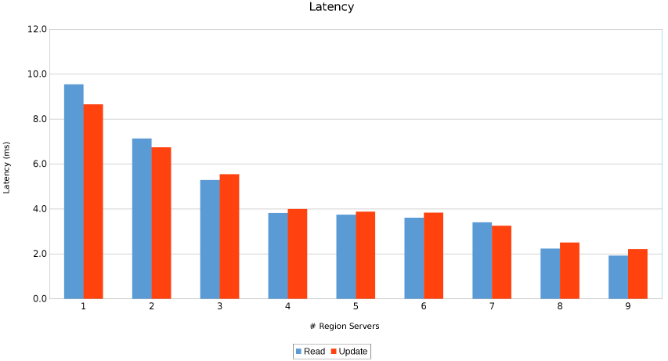
Os resultados são informativos, embora não surpreendentes. A natureza scale-out do HBase combinada com a natureza scale-out do Isilon indicaram que quanto mais, melhor. Esse teste é recomendado para que os clientes sejam executados em seus ambientes como parte de seu próprio exercício de dimensionamento. Aqui, há nove servidores enviando cinco nós do Isilon, e parece que ainda há espaço para mais antes de chegar ao ponto de diminuir os retornos.
Mais clientes
A última série de testes serviu para testar os limites da configuração de hardware. Isso foi feito para determinar o limite superior dos parâmetros que estão sendo testados. Nessa série de testes, dois servidores adicionais são usados para executar clients a partir do. Além disso, dois clients YCSB são executados de cada servidor, permitindo até seis clients cada. Cada client gerou 512 threads, resultando em 4.096 threads no geral. Duas tabelas diferentes foram criadas. Uma tabela com 4 bilhões de linhas divididas em 600 regiões e outra com 400 milhões de linhas divididas em 90 regiões.
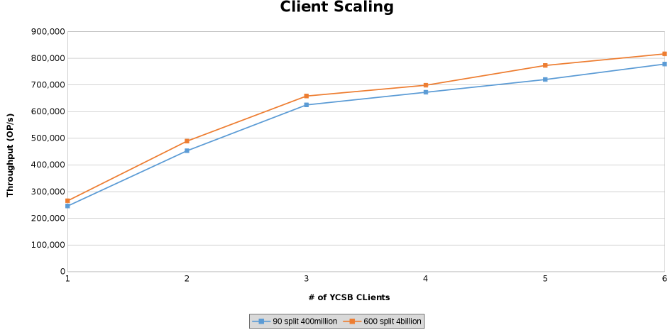
Isso representa graficamente o throughput das operações durante o teste do dimensionamento do client (Figura 12).
Medição da latência de leitura ao testar o dimensionamento do client (Figura 13)
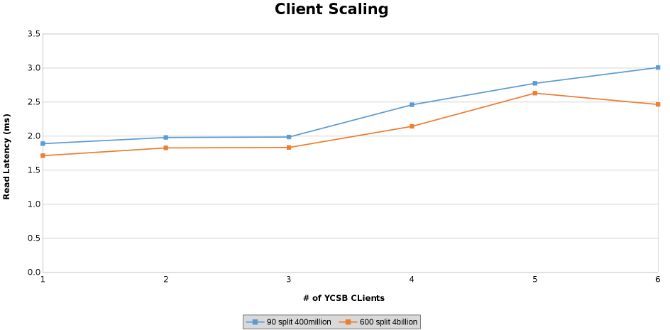
Medição da latência de atualização ao testar o dimensionamento do client (Figura 14)
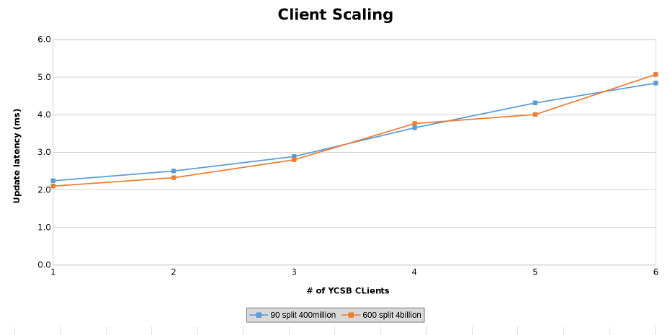
Os gráficos abaixo mostram que o tamanho da tabela pouco importa neste teste. Os gráficos de calor do Isilon novamente mostram que há algumas diferenças percentuais no número de operações de arquivo. A maioria das diferenças estava em linha com as diferenças de uma tabela de quatro bilhões de linhas para uma tabela de 400 milhões de linhas.
Comparação do aquecimento da carga de trabalho do Isilon ao atualizar uma tabela de 400 milhões de linhas em comparação com uma tabela de 4 bilhões de linhas (Figura 15).
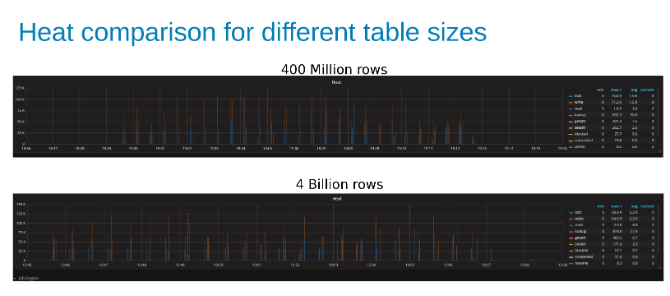
Conclusão
O HBase é um bom candidato para execução no Isilon, principalmente por causa das arquiteturas scale-out para scale-out. O HBase faz muito de seu próprio armazenamento em cache e, dividindo a tabela em um bom número de regiões, o HBase pode fazer scale-out com os dados. Em outras palavras, ele faz um bom trabalho ao cuidar de suas próprias necessidades, e o sistema de arquivos está lá para resiliência de aplicativos. Os testes não foram capazes de empurrar a carga ao ponto de quebrar as coisas. Se o HBase for projetado para 800.000 operações com menos de 3 ms de latência, essa arquitetura dará suporte a ele. O HBase dá suporte a inúmeros ajustes e ajustes de desempenho para o lado do cliente e o próprio HBase. O teste de todos esses ajustes e ajustes estava além do escopo deste teste.Affected Products
Isilon, PowerScale OneFSArticle Properties
Article Number: 000128942
Article Type: Solution
Last Modified: 11 Mar 2026
Version: 7
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.