VMware: Guía de solución de problemas de discos físicos de vSAN
Resumen: Esta es una guía general de solución de problemas para ayudar a identificar si hay un problema con un disco físico en los clústeres de vSAN.
Instrucciones
Comprobación del estado del disco físico de vSAN desde la interfaz de usuario web:
Conéctese a vCenter Server Web Client y compruebe el estado del disco desde las siguientes ubicaciones:
Inventario > Host y clústeres Clúster de > vSAN Configurar >> la administración de discos de vSAN >Imagen 1: vista
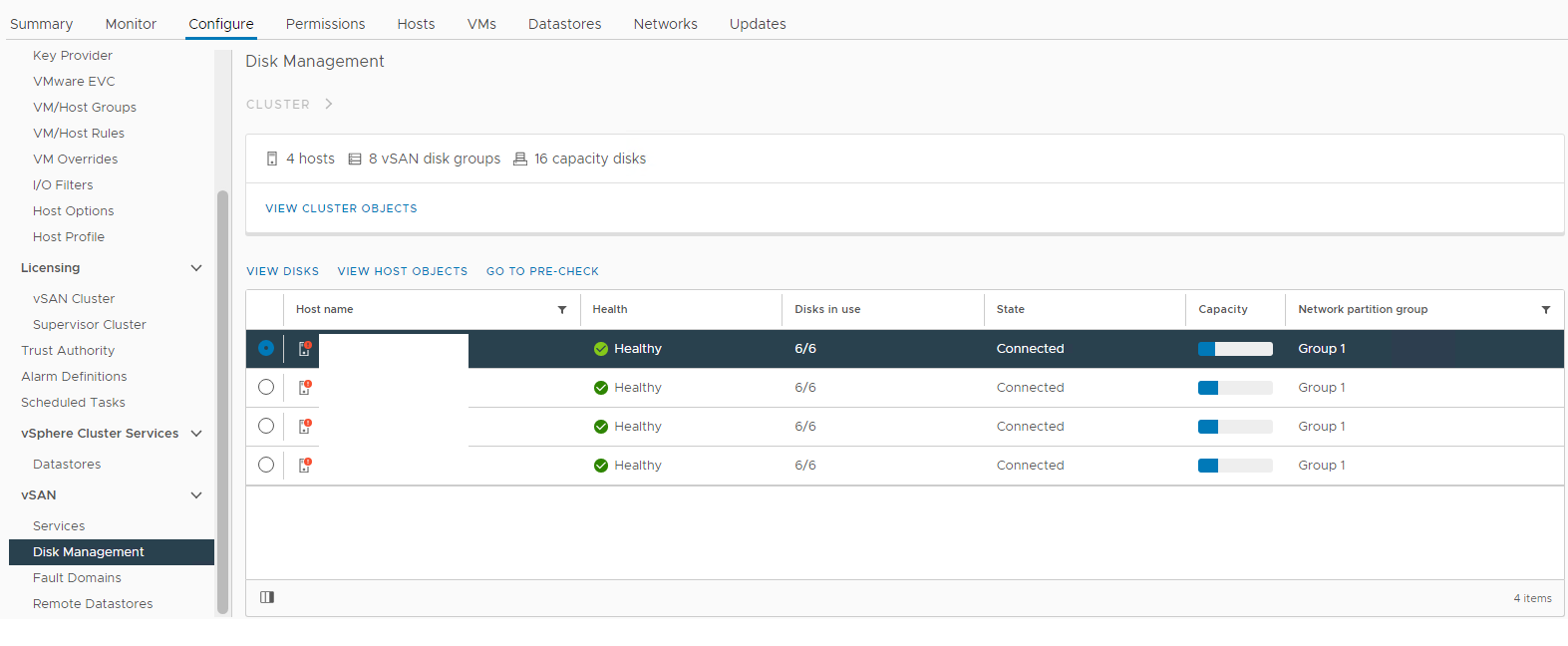
de administración de discos de vSAN Seleccione el host afectado y, a continuación, expanda la sección Ver disco:
Imagen 2: Vista
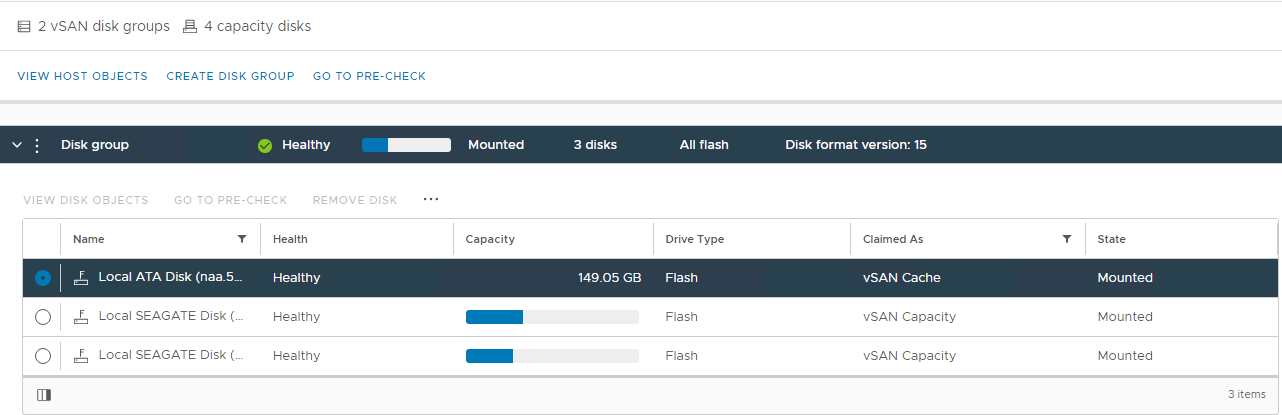 de grupo de discos de vSAN Aquí puede verificar si un disco se detecta como:
de grupo de discos de vSAN Aquí puede verificar si un disco se detecta como:
En mal estado
desmontado
0 capacidad
falla
de disco permanente disco inactivo
disco ausente
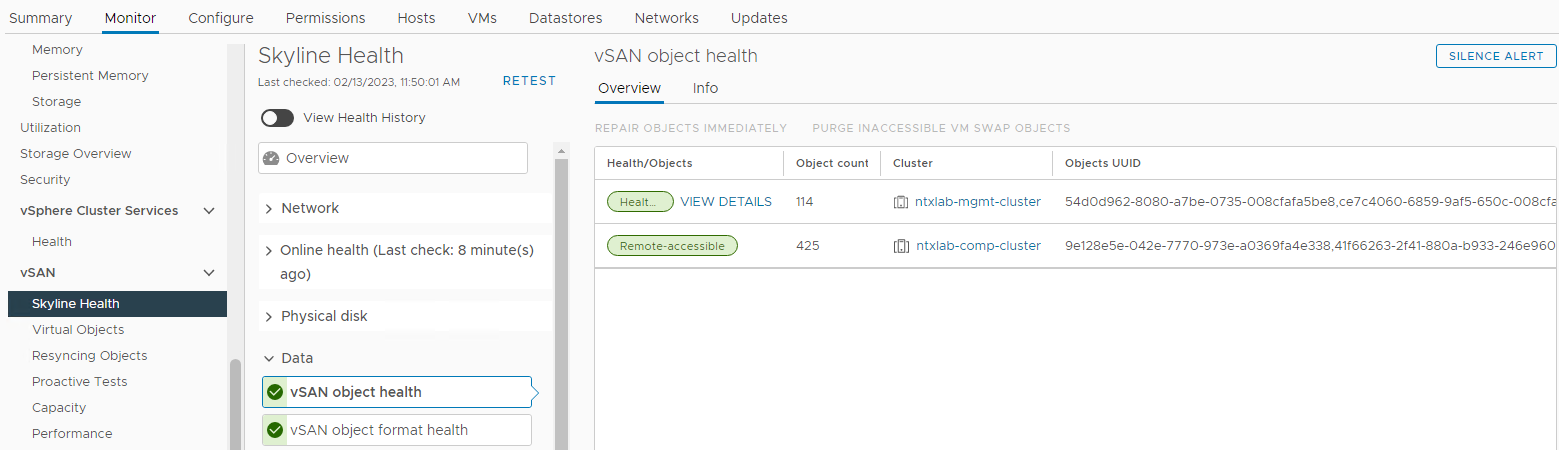
Además, compruebe si hay alarmas relacionadas con el disco activadas desde la sección vSAN Skyline Health:
Inventario > Host y clústeres Monitor de clústeres >> de vSAN Estado > de vSAN > Skyline Disco >
físico Imagen 3: Vista
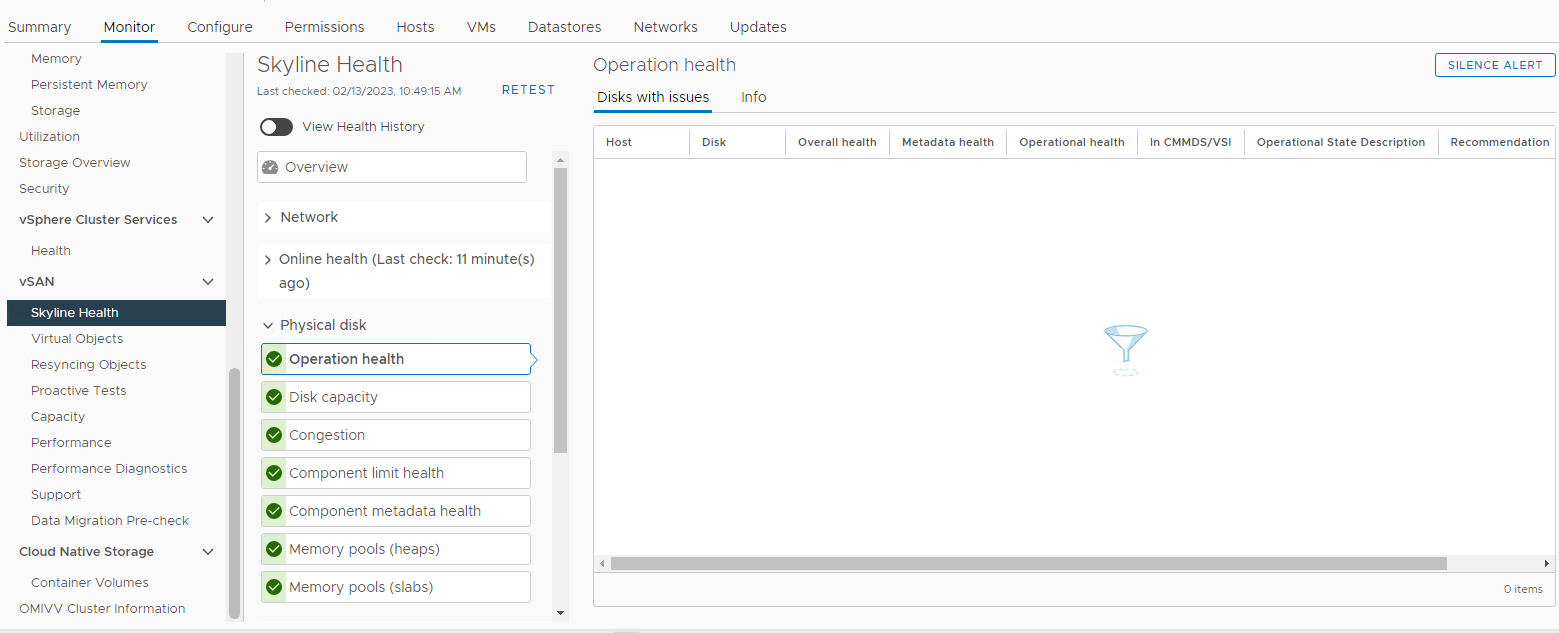
Skyline Health Aquí puede verificar si se activa alguna de las siguientes alarmas:
Impending permanent disk failure, data is being evacuated (Health state - Yellow).
Impending permanent disk failure, data evacuation failed due to insufficient resources (Health state - Red).
Impending permanent disk failure, data evacuation failed due to inaccessible objects (Health state - Red).
Impending permanent disk failure, data evacuation completed (Health state - Yellow)
Además, puede comprobar el estado del disco desde la lista Dispositivos de almacenamiento del host afectado:
Inventario > Host y clústeres Clúster > de > vSAN afectado Host > ESXi de vSAN Configurar > dispositivos de almacenamiento >Imagen 4:
Vista Host Storage Devices
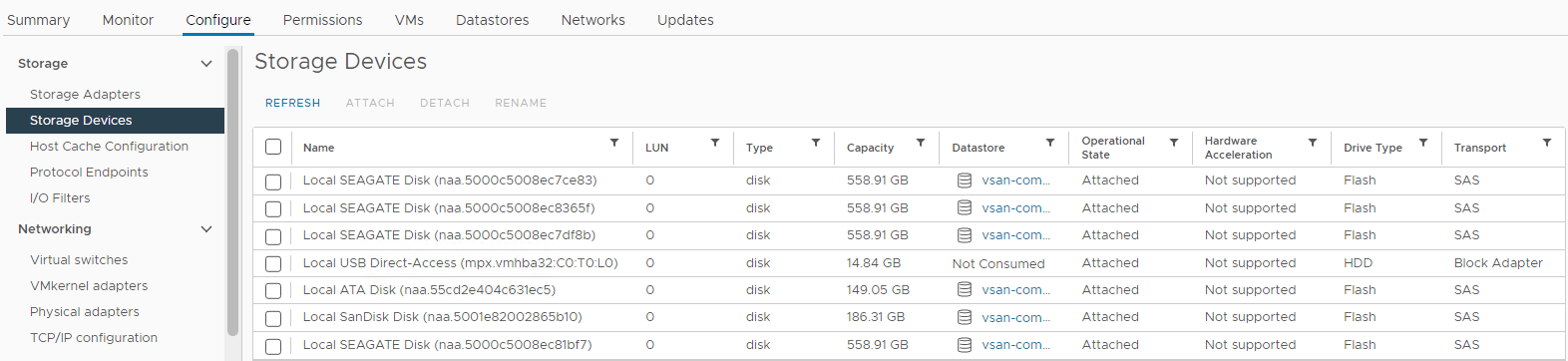
Aquí puede verificar si el estado de un disco es:
Disco de capacidad
0 Disco ausente
Desmontado
Verifique si se está produciendo una resincronización:
Inventario > Host y clústeres > vSAN Cluster > Monitor > vSAN > Resincronización de objetos:
Imagen 5: Vista Resincronización de objetos
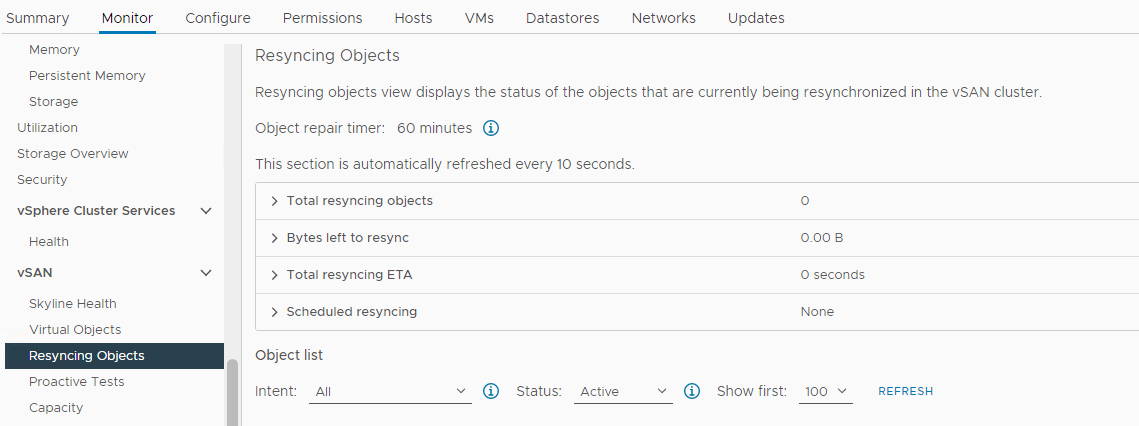
Verifique el estado de los objetos de vSAN:
Inventario > Host y clústeres Monitor de clústeres >> de vSAN Datos > de estado de vSAN > Skyline Estado >> del
objeto de vSAN Imagen 6: vista del estado del objeto de vSAN
El siguiente paso es recopilar más información sobre el problema a través de la CLI y comprobar los registros:
Comprobación del estado del disco físico de vSAN desde la CLI:
Conectarse a través de SSH al host afectado y ejecutar los siguientes comandos:
vdq -qH
Compruebe en la "IsPDL" (pérdida permanente del dispositivo). Si es igual a 1, se pierde el disco.
Ejemplo:
DiskResults:
DiskResult[0]:
Name: naa.600508b1001c4b820b4d80f9f8acfa95
VSANUUID: 5294bbd8-67c4-c545-3952-7711e365f7fa
State: In-use for VSAN
ChecksumSupport: 0
Reason: Non-local disk
IsSSD?: 0
IsCapacityFlash?: 0
IsPDL?: 0
<<truncated>>
DiskResult[18]:
Name:
VSANUUID: 5227c17e-ec64-de76-c10e-c272102beba7
State: In-use for VSAN
ChecksumSupport: 0
Reason: None
IsSSD?: 0
IsCapacityFlash?: 0
IsPDL?: 1
vdq -iH
Compruebe si falta un disco del grupo de discos.
Ejemplo:
Mappings: DiskMapping[0]: SSD: naa.58ce38ee2016ffe5 MD: naa.5002538a4819e3e0 DiskMapping[2]: SSD: naa.58ce38ee2016fe55 MD: naa.5002538a48199ca0 MD: naa.5002538a48199e20 MD: naa.5002538a48199e00
esxcli vsan storage list
Verifique en el "In CMMDS" parámetro. Si es falso, se pierde la comunicación con el disco.
Ejemplo:
Device: Unknown
Display Name: Unknown
Is SSD: false
VSAN UUID: 529cadbc-acd1-b588-8643-68336d5512d6
VSAN Disk Group UUID:
VSAN Disk Group Name:
Used by this host: false
In CMMDS: false
On-disk format version: <Unknown>
Deduplication: false
Compression: false
Checksum:
Checksum OK: false
Is Capacity Tier: false
for i in `esxcli storage core device list | grep ^naa` ; do echo $i; esxcli storage core device smart get -d $i; done.
Compruebe si hay errores de lectura/escritura con el comando "get inteligente".
Ejemplo:
naa.55cd2e404c1f35a1 Parameter Value Threshold Worst Raw -------------------------- ----- --------- ----- --- Health Status OK N/A N/A N/A Media Wearout Indicator 100 0 100 86 Read Error Count 130 39 130 133 Power-on Hours 100 0 100 110 Power Cycle Count 100 0 100 106 Drive Temperature 100 0 100 26 Uncorrectable Sector Count 100 0 100 0
naa.55cd2e404c1f35a5 Parameter Value Threshold Worst Raw -------------------------- ----- --------- ----- --- Health Status OK N/A N/A N/A Media Wearout Indicator 100 0 100 10 Read Error Count 130 39 130 53 Power-on Hours 100 0 100 110 Power Cycle Count 100 0 100 106 Drive Temperature 100 0 100 27 Uncorrectable Sector Count 100 0 100 0
esxcli vsan storage list | grep "VSAN Disk Group UUID:" | sort | uniq -c
Compruebe si hay grupos de discos disponibles.
Ejemplo:
2 VSAN Disk Group UUID: 5203424c-ee56-497d-75d1-fcf73ae997cb 2 VSAN Disk Group UUID: 52af8e5c-77d1-b552-3310-ec5fef09edf4
while true;do echo " ****************************************** "; echo "" > /tmp/resyncStats.txt ;cmmds-tool find -t DOM_OBJECT -f json |grep uuid |awk -F \" '{print $4}' |while read i;do pendingResync=$(cmmds-tool find -t DOM_OBJECT -f json -u $i|grep -o "\"bytesToSync\": [0-9]*,"|awk -F " |," '{sum+=$2} END{print sum / 1024 / 1024 / 1024;}');if [ ${#pendingResync} -ne 1 ]; then echo "$i: $pendingResync GiB";fi;done |tee -a /tmp/resyncStats.txt;total=$(cat /tmp/resyncStats.txt |awk '{sum+=$2} END{print sum}');echo "Total: $total GiB" |tee -aa /tmp/resyncStats.txt;total=$(cat /tmp/resyncStats.txt |grep Total);totalObj=$(cat /tmp/resyncStats.txt|grep -vE " 0 GiB|Total"|wc -l);echo "`date +%Y-%m-%dT%H:%M:%SZ` $total ($totalObj objects)" >> /tmp/totalHistory.txt; echo `date `; sleep 60; done
Compruebe si hay operaciones de resincronización en curso o bloqueadas.
Ejemplo:
Total: 0 GiB Mon Feb 13 17:32:06 UTC 2023
Presione Ctrl+C para detener el comando.
cmmds-tool find -f python | grep CONFIG_STATUS -B 4 -A 6 | grep 'uuid\|content' | grep -o 'state\\\":\ [0-9]*' | sort | uniq -c
Compruebe el estado de los componentes.
Healthy -- state 7
Inaccessible -- state 13
Absent or Degraded -- state 15
Ejemplo:
425 state\": 7
Cómo identificar dónde se encuentra la SSD o el DISCO DURO fallidos en la CLI:
Enumere todos los dispositivos disponibles:
esxcli storage core device list | grep "naa" | awk '{print $1}' | grep "naa"
Ejemplo:
naa.5000c500852df8d3 naa.55cd2e404c1f35a1 naa.55cd2e404c1f35a5 naa.5000c500852dd5e7
Compruebe la ubicación utilizando cada disco naa de la lista:
esxcli storage core device physical get -d
Ejemplo:
esxcli storage core device physical get -d naa.5000c500852df8d3 esxcli storage core device physical get -d naa.55cd2e404c1f35a1 esxcli storage core device physical get -d naa.55cd2e404c1f35a5 esxcli storage core device physical get -d naa.5000c500852dd5e7 Physical Location: enclosure 65535 slot 0 Physical Location: enclosure 65535 slot 1 Physical Location: enclosure 65535 slot 2 Physical Location: enclosure 65535 slot 3
Cómo identificar el DISCO DURO o SSD fallido si falta el nombre del dispositivo:
Es posible que el disco fallido no se detecte y no se pueda identificar mediante el nro de NAA correspondiente. En este escenario, es necesario localizar todos los discos, y el que no está localizado físicamente sería el que falló.
Este es un script que se puede utilizar para realizar la tarea un poco más rápido:
echo "=============Physical disks placement=============="
echo ""
esxcli storage core device list | grep "naa" | awk '{print $1}' | grep "naa" | while read in; do
echo "$in"
esxcli storage core device physical get -d "$in"
sleep 1
echo "===================================================="
done
Registros relevantes de vSAN para problemas relacionados con el almacenamiento:
/var/log/vmkernel.log
Problemas de lectura y escritura en discos de vSAN, latidos del host de vSAN, PDL, códigos de detección de SCSI y solicitudes de I/O (lecturas/escrituras), e información de membresía del clúster.
Ejemplo:
2021-06-22T12:02:08.408Z cpu30:1001397101)ScsiDeviceIO: PsaScsiDeviceTimeoutHandlerFn:12834: TaskMgmt op to cancel IO succeeded for device naa.55cd2e404b7736d0 and the IO did not complete. WorldId 0, Cmd 0x28, CmdSN = 0x428.Cancelling of IO will be 2021-06-22T12:02:08.408Z cpu30:1001397101)retried.
/var/log/vobd.log
Informa sobre el estado de los discos, los discos perdidos permanentes de dispositivos (PDL) y la latencia de discos, e informa sobre cuándo un host entra y sale del modo de mantenimiento.
Ejemplo:
2022-05-31T11:42:46.065Z: [vSANCorrelator] 10605891965954us: [vob.vsan.lsom.devicerepair] vSAN device 521a74ce-c980-c16c-ff3d-38a036233daf is being repaired due to I/O failures, and will be out of service until the repair is complete. If the device is part of a dedup disk group, the entire disk group will be out of service until the repair is complete. 2022-05-31T11:42:46.065Z: [vSANCorrelator] 10606062774178us: [esx.problem.vob.vsan.lsom.devicerepair] Device 521a74ce-c980-c16c-ff3d-38a036233daf is in offline state and is getting repaired
/var/log/vsandevicemonitord.log
Lo ayuda a determinar si el disco se marcó como en mal estado debido a una congestión excesiva de registros o latencias de I/O.
Ejemplo:
INFO vsandevicemonitord WARNING - WRITE Average Latency on VSAN device naa.50000xxxxxxxx has exceeded threshold value 2000000 us 2 times. INFO vsandevicemonitord Tier 2 (naa.50000xxxxxxxx) as unhealthy
Información adicional
Consulte este video:
VMware: Guía de solución de problemas de discos físicos de vSAN
Duración: 00:10:19 (hh:mm:ss)
Cuando está disponible, se puede elegir la configuración de idioma de los subtítulos cerrados (subtítulos) mediante el ícono CC en este reproductor de video.
También puede ver este video en YouTube.