VMware: vSAN 물리적 디스크 문제 해결 가이드
요약: 이 문서는 vSAN 클러스터의 물리적 디스크에 문제가 있는지 확인하는 데 도움이 되는 일반적인 문제 해결 가이드입니다.
이 문서는 다음에 적용됩니다.
이 문서는 다음에 적용되지 않습니다.
이 문서는 특정 제품과 관련이 없습니다.
모든 제품 버전이 이 문서에 나와 있는 것은 아닙니다.
지침
웹 UI에서 vSAN 물리적 디스크 상태 확인:
vCenter Server 웹 클라이언트에 연결하고 다음에서 디스크 상태를 확인합니다.
인벤토리 > 호스트 및 클러스터 > vSAN 클러스터 > 구성 vSAN > 디스크 관리 >
그림 1: vSAN 디스크 관리 보기
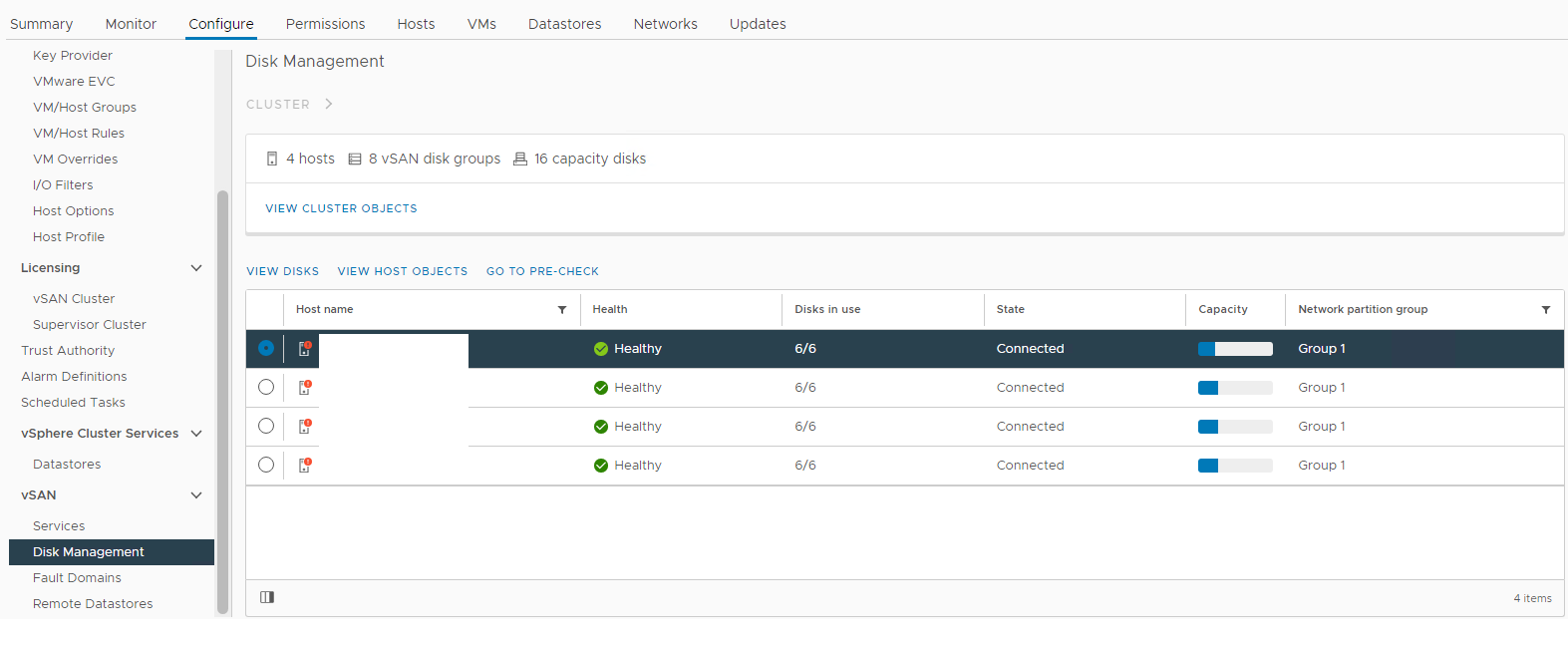
영향을 받는 호스트를 선택한 다음 디스크 보기 섹션을 확장합니다.
그림 2: vSAN 디스크 그룹 보기
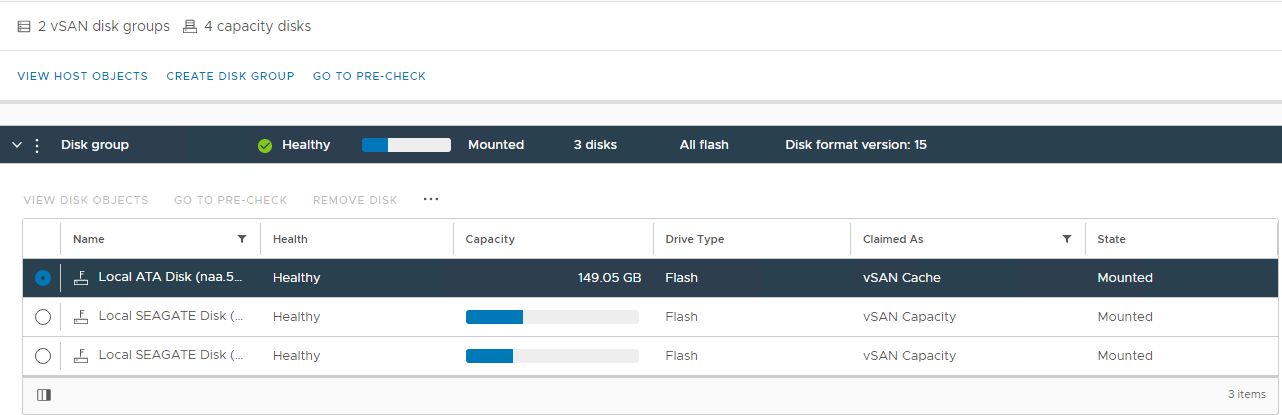
여기에서 디스크가 다음과 같이 감지되는지 확인할 수 있습니다.
비정상
마운트
해제됨 0 용량
영구 디스크 장애
디스크 다운
디스크 없음
또한 vSAN Skyline Health 섹션에서 트리거된 디스크 관련 경보를 확인합니다.
인벤토리 > 호스트 및 클러스터 > vSAN 클러스터 > 모니터 > vSAN > Skyline 상태 > 물리적 디스크
그림 3: Skyline 상태 보기
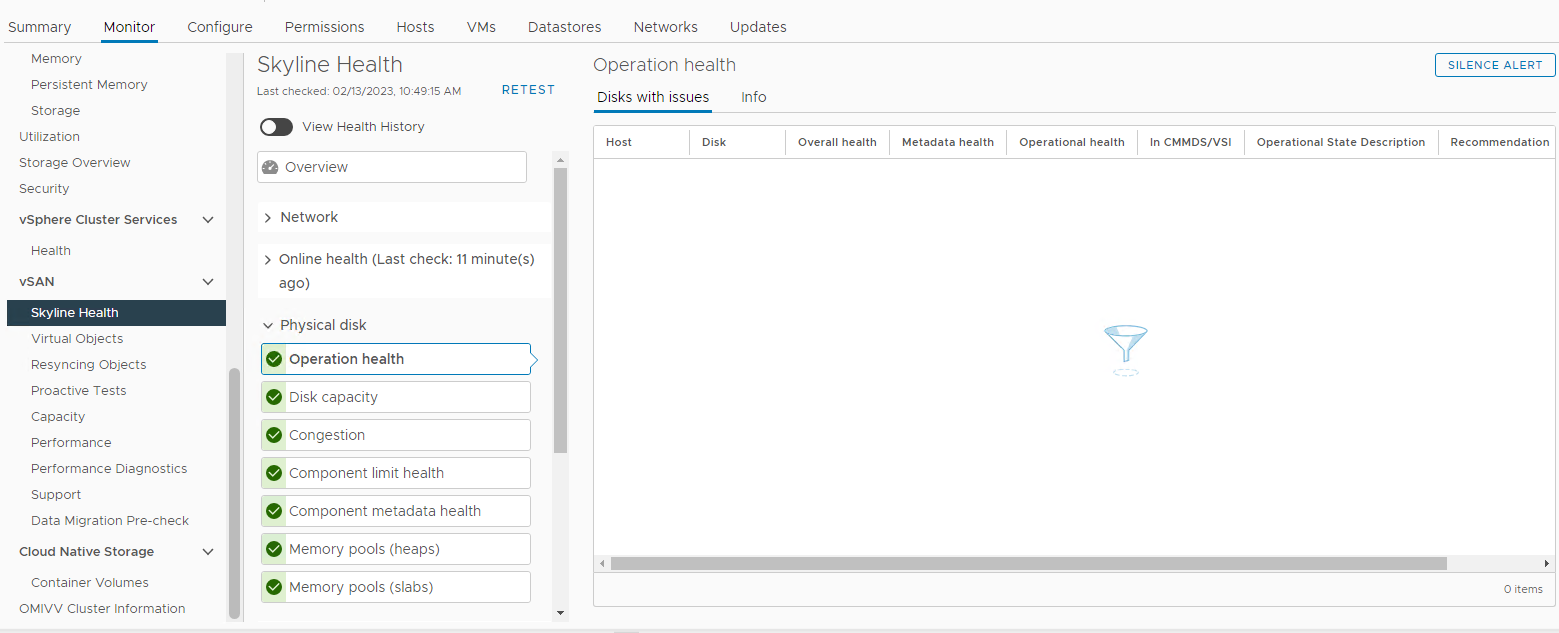
여기에서 다음 알람 중 하나가 트리거되었는지 확인할 수 있습니다.
Impending permanent disk failure, data is being evacuated (Health state - Yellow).
Impending permanent disk failure, data evacuation failed due to insufficient resources (Health state - Red).
Impending permanent disk failure, data evacuation failed due to inaccessible objects (Health state - Red).
Impending permanent disk failure, data evacuation completed (Health state - Yellow)
또한 영향을 받는 호스트의 스토리지 디바이스 목록에서 디스크 상태를 확인할 수 있습니다.
인벤토리 > 호스트 및 클러스터 > 영향을 받는 vSAN 클러스터 > vSAN ESXi 호스트 > 스토리지 > 스토리지 디바이스 >
구성 그림 4: Host Storage Devices 보기
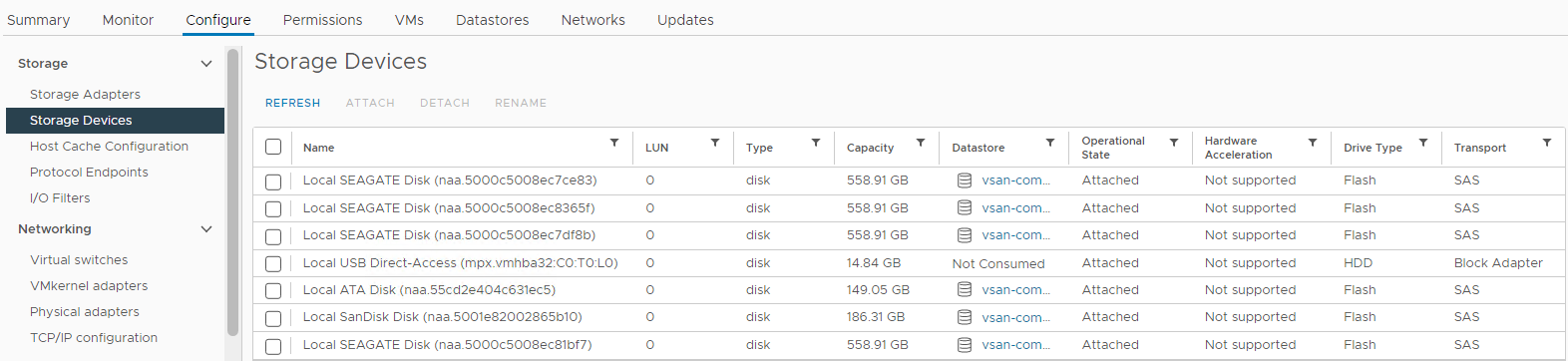
여기에서 디스크 상태가 다음과 같은지 확인할 수 있습니다.
0 용량
디스크 부재
디스크 마운트
해제됨 재동기화가 수행되는지 확인합니다.
인벤토리 > 호스트 및 클러스터 > vSAN 클러스터 > 모니터 > vSAN > 재동기화 오브젝트:
그림 5: 개체 보기 다시 동기화
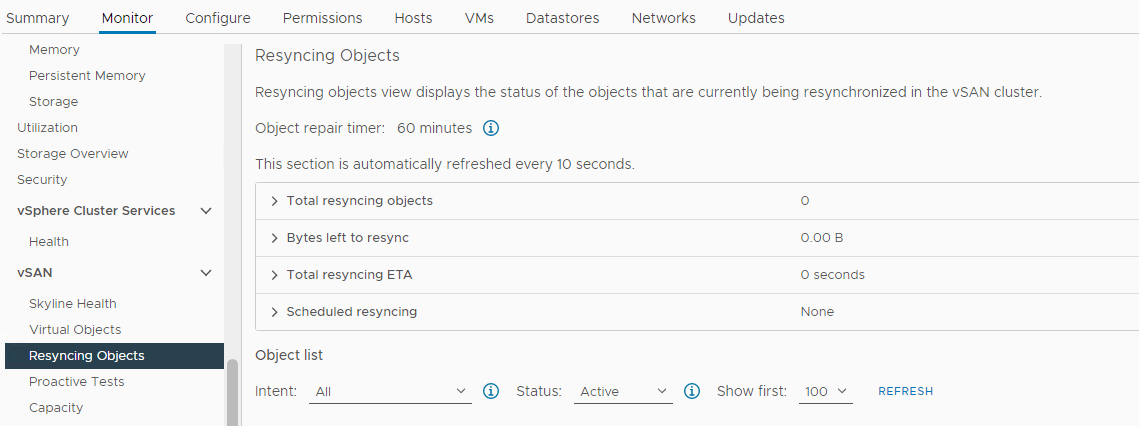
참고: 재동기화는 영향을 받는 디스크 또는 디스크 그룹에서 데이터가 제거되고 있음을 나타낼 수 있습니다. 영향을 받는 디스크를 제거 또는 교체할 준비가 되었는지 확인하려면 추가 조사가 필요합니다.
vSAN 오브젝트의 상태를 확인합니다.
인벤토리 > 호스트 및 클러스터 > vSAN 클러스터 > 모니터 > vSAN > Skyline 상태 > 데이터 > vSAN 오브젝트 상태
그림 6: vSAN 오브젝트 상태 보기
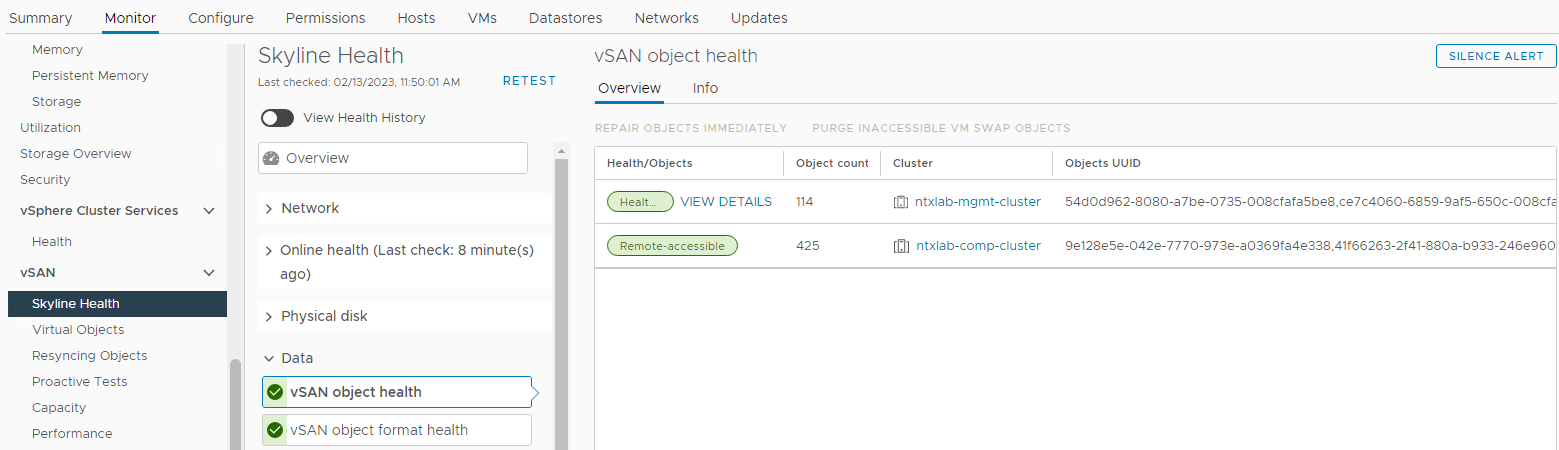
참고: 액세스할 수 없는 오브젝트가 없는지 확인하는 것이 중요합니다. 오브젝트에 액세스할 수 없다는 것은 "오브젝트의 모든 복제본이 누락됨"을 의미합니다. DL을 유발할 수 있는 디스크를 제거하거나 교체하는 경우.
다음 단계는 CLI를 통해 문제에 대한 자세한 정보를 수집하고 로그를 확인하는 것입니다.
CLI에서 vSAN 물리적 디스크 상태 확인:
SSH를 통해 영향을 받는 호스트에 연결하고 다음 명령을 실행합니다.
vdq -qH
를 확인하십시오 "IsPDL"(영구적 인 장치 손실) 매개 변수. 1과 같으면 디스크가 손실됩니다.
예:
DiskResults:
DiskResult[0]:
Name: naa.600508b1001c4b820b4d80f9f8acfa95
VSANUUID: 5294bbd8-67c4-c545-3952-7711e365f7fa
State: In-use for VSAN
ChecksumSupport: 0
Reason: Non-local disk
IsSSD?: 0
IsCapacityFlash?: 0
IsPDL?: 0
<<truncated>>
DiskResult[18]:
Name:
VSANUUID: 5227c17e-ec64-de76-c10e-c272102beba7
State: In-use for VSAN
ChecksumSupport: 0
Reason: None
IsSSD?: 0
IsCapacityFlash?: 0
IsPDL?: 1
vdq -iH
디스크 그룹에서 누락된 디스크가 있는지 확인합니다.
예:
Mappings: DiskMapping[0]: SSD: naa.58ce38ee2016ffe5 MD: naa.5002538a4819e3e0 DiskMapping[2]: SSD: naa.58ce38ee2016fe55 MD: naa.5002538a48199ca0 MD: naa.5002538a48199e20 MD: naa.5002538a48199e00
esxcli vsan storage list
에서 확인 "In CMMDS" 매개 변수. false이면 디스크와의 통신이 끊어집니다.
예:
Device: Unknown
Display Name: Unknown
Is SSD: false
VSAN UUID: 529cadbc-acd1-b588-8643-68336d5512d6
VSAN Disk Group UUID:
VSAN Disk Group Name:
Used by this host: false
In CMMDS: false
On-disk format version: <Unknown>
Deduplication: false
Compression: false
Checksum:
Checksum OK: false
Is Capacity Tier: false
for i in `esxcli storage core device list | grep ^naa` ; do echo $i; esxcli storage core device smart get -d $i; done.
smart get 명령을 사용하여 읽기/쓰기 오류를 확인합니다.
예:
naa.55cd2e404c1f35a1 Parameter Value Threshold Worst Raw -------------------------- ----- --------- ----- --- Health Status OK N/A N/A N/A Media Wearout Indicator 100 0 100 86 Read Error Count 130 39 130 133 Power-on Hours 100 0 100 110 Power Cycle Count 100 0 100 106 Drive Temperature 100 0 100 26 Uncorrectable Sector Count 100 0 100 0
naa.55cd2e404c1f35a5 Parameter Value Threshold Worst Raw -------------------------- ----- --------- ----- --- Health Status OK N/A N/A N/A Media Wearout Indicator 100 0 100 10 Read Error Count 130 39 130 53 Power-on Hours 100 0 100 110 Power Cycle Count 100 0 100 106 Drive Temperature 100 0 100 27 Uncorrectable Sector Count 100 0 100 0
esxcli vsan storage list | grep "VSAN Disk Group UUID:" | sort | uniq -c
사용 가능한 디스크 그룹을 확인합니다.
예:
2 VSAN Disk Group UUID: 5203424c-ee56-497d-75d1-fcf73ae997cb 2 VSAN Disk Group UUID: 52af8e5c-77d1-b552-3310-ec5fef09edf4
while true;do echo " ****************************************** "; echo "" > /tmp/resyncStats.txt ;cmmds-tool find -t DOM_OBJECT -f json |grep uuid |awk -F \" '{print $4}' |while read i;do pendingResync=$(cmmds-tool find -t DOM_OBJECT -f json -u $i|grep -o "\"bytesToSync\": [0-9]*,"|awk -F " |," '{sum+=$2} END{print sum / 1024 / 1024 / 1024;}');if [ ${#pendingResync} -ne 1 ]; then echo "$i: $pendingResync GiB";fi;done |tee -a /tmp/resyncStats.txt;total=$(cat /tmp/resyncStats.txt |awk '{sum+=$2} END{print sum}');echo "Total: $total GiB" |tee -aa /tmp/resyncStats.txt;total=$(cat /tmp/resyncStats.txt |grep Total);totalObj=$(cat /tmp/resyncStats.txt|grep -vE " 0 GiB|Total"|wc -l);echo "`date +%Y-%m-%dT%H:%M:%SZ` $total ($totalObj objects)" >> /tmp/totalHistory.txt; echo `date `; sleep 60; done
진행 중이거나 중단된 재동기화 작업이 있는지 확인합니다.
예:
Total: 0 GiB Mon Feb 13 17:32:06 UTC 2023
Ctrl+C를 눌러 명령을 중지합니다.
cmmds-tool find -f python | grep CONFIG_STATUS -B 4 -A 6 | grep 'uuid\|content' | grep -o 'state\\\":\ [0-9]*' | sort | uniq -c
구성 요소의 상태를 확인합니다.
Healthy -- state 7
Inaccessible -- state 13
Absent or Degraded -- state 15
예:
425 state\": 7
CLI를 통해 장애가 발생한 SSD 또는 하드 드라이브가 있는 위치를 식별하는 방법:
사용 가능한 모든 디바이스를 나열합니다.
esxcli storage core device list | grep "naa" | awk '{print $1}' | grep "naa"
예:
naa.5000c500852df8d3 naa.55cd2e404c1f35a1 naa.55cd2e404c1f35a5 naa.5000c500852dd5e7
목록에서 각 디스크 naa를 사용하여 위치를 확인합니다.
esxcli storage core device physical get -d
예:
esxcli storage core device physical get -d naa.5000c500852df8d3 esxcli storage core device physical get -d naa.55cd2e404c1f35a1 esxcli storage core device physical get -d naa.55cd2e404c1f35a5 esxcli storage core device physical get -d naa.5000c500852dd5e7 Physical Location: enclosure 65535 slot 0 Physical Location: enclosure 65535 slot 1 Physical Location: enclosure 65535 slot 2 Physical Location: enclosure 65535 slot 3
장치 이름이 누락된 경우 오류가 발생한 하드 드라이브 또는 SSD를 식별하는 방법:
장애가 발생한 디스크가 감지되지 않고 해당 naa를 사용하여 식별할 수 없을 수 있습니다. 이 시나리오에서는 모든 디스크를 찾아야 하며 물리적으로 위치하지 않은 디스크가 장애가 발생한 디스크입니다.
다음은 작업을 약간 더 빠르게 수행하는 데 사용할 수 있는 스크립트입니다.
echo "=============Physical disks placement=============="
echo ""
esxcli storage core device list | grep "naa" | awk '{print $1}' | grep "naa" | while read in; do
echo "$in"
esxcli storage core device physical get -d "$in"
sleep 1
echo "===================================================="
done
스토리지 관련 문제에 대한 vSAN 관련 로그:
/var/log/vmkernel.log
vSAN 디스크, vSAN 호스트 하트비트, PDL, SCSI 감지 코드 및 I/O 요청(읽기/쓰기), 클러스터 멤버십 정보에 대한 읽기 및 쓰기 문제.
예:
2021-06-22T12:02:08.408Z cpu30:1001397101)ScsiDeviceIO: PsaScsiDeviceTimeoutHandlerFn:12834: TaskMgmt op to cancel IO succeeded for device naa.55cd2e404b7736d0 and the IO did not complete. WorldId 0, Cmd 0x28, CmdSN = 0x428.Cancelling of IO will be 2021-06-22T12:02:08.408Z cpu30:1001397101)retried.
/var/log/vobd.log
디스크 상태, 영구 PDL(Device Lost Disk), 디스크 레이턴시에 대해 보고하고 호스트가 유지 보수 모드를 시작 및 종료하는 시점을 보고합니다.
예:
2022-05-31T11:42:46.065Z: [vSANCorrelator] 10605891965954us: [vob.vsan.lsom.devicerepair] vSAN device 521a74ce-c980-c16c-ff3d-38a036233daf is being repaired due to I/O failures, and will be out of service until the repair is complete. If the device is part of a dedup disk group, the entire disk group will be out of service until the repair is complete. 2022-05-31T11:42:46.065Z: [vSANCorrelator] 10606062774178us: [esx.problem.vob.vsan.lsom.devicerepair] Device 521a74ce-c980-c16c-ff3d-38a036233daf is in offline state and is getting repaired
/var/log/vsandevicemonitord.log
과도한 로그 정체 또는 I/O 지연 시간으로 인해 디스크가 비정상으로 표시되었는지 확인하는 데 도움이 됩니다.
예:
INFO vsandevicemonitord WARNING - WRITE Average Latency on VSAN device naa.50000xxxxxxxx has exceeded threshold value 2000000 us 2 times. INFO vsandevicemonitord Tier 2 (naa.50000xxxxxxxx) as unhealthy
해당 제품
PowerEdge C6420, PowerEdge C6520, PowerEdge C6525, PowerEdge C6615, PowerEdge C6620, PowerEdge M640 (for PE VRTX), PowerEdge R440, PowerEdge R450, PowerEdge R540, PowerEdge R550, PowerEdge R640, PowerEdge R6415, PowerEdge R650, PowerEdge R650xs
, PowerEdge R6515, PowerEdge R6525, PowerEdge R660, PowerEdge R660xs, PowerEdge R6615, PowerEdge R6625, PowerEdge R740, PowerEdge R740XD, PowerEdge R740XD2, PowerEdge R7415, PowerEdge R7425, PowerEdge R750, PowerEdge R750XA, PowerEdge R750xs, PowerEdge R7515, PowerEdge R7525, PowerEdge R760, PowerEdge R760XA, PowerEdge R760xd2, PowerEdge R760xs, PowerEdge R7615, PowerEdge R7625, PowerEdge R840, PowerEdge R860, PowerEdge R940, PowerEdge R940xa, PowerEdge R960, PowerEdge T430, PowerEdge T440, PowerEdge T550, PowerEdge T560, PowerEdge T630, PowerEdge T640, VMware ESXi 6.7.X, VMware ESXi 7.x, VMware ESXi 8.x, VMware VSAN, Dell EMC vSAN C6420 Ready Node, Dell EMC vSAN MX740c Ready Node, Dell EMC vSAN MX750c Ready Node, Dell vSAN Ready Node MX760c, Dell EMC vSAN R440 Ready Node, Dell EMC vSAN R640 Ready Node, Dell EMC vSAN R6415 Ready Node, Dell EMC vSAN R650 Ready Node, Dell EMC vSAN R6515 Ready Node, vSAN Ready Node R660, Dell vSAN R6615 Ready Node, Dell EMC vSAN R740 Ready Node, Dell EMC vSAN R740xd Ready Node, Dell EMC vSAN R750 Ready Node, Dell EMC vSAN R7515 Ready Node, Dell EMC vSAN R760 Ready Node, Dell vSAN R7615 Ready Node, Dell vSAN Ready Node R7625, Dell EMC vSAN R840 Ready Node, Dell EMC vSAN T350 Ready Node, VxRail 460 and 470 Nodes, VxRail D560, VxRail D560F, VxRail E460, VxRail E560, VxRail E560F, VxRail E560N, VxRail E660, VxRail E660F, VxRail E660N, VxRail E665, VxRail E665F, VxRail E665N, VxRail G560, VxRail G560F, VxRail P470, VxRail P570, VxRail P570F, VxRail P580N, VxRail P670F, VxRail P670N, VxRail P675F, VxRail P675N, VxRail S470, VxRail S570, VxRail S670, VxRail V470, VxRail V570, VxRail V570F, VXRAIL V670F, VxRail VD-4510C, VxRail VD-4520C, VxRail VE-660, VxRail VE-6615, VxRail VE-670, VxRail VP-760, VxRail VP-7625, VxRail VP-770
...
제품
VxRail, PowerEdge C6420, PowerEdge C6520, PowerEdge C6525, PowerEdge C6615, PowerEdge C6620, PowerEdge M640 (for PE VRTX), PowerEdge R440, PowerEdge R450, PowerEdge R540, PowerEdge R550, PowerEdge R640, PowerEdge R6415, PowerEdge R650
, PowerEdge R650xs, PowerEdge R6515, PowerEdge R6525, PowerEdge R660, PowerEdge R660xs, PowerEdge R6615, PowerEdge R6625, PowerEdge R740, PowerEdge R740XD, PowerEdge R740XD2, PowerEdge R7415, PowerEdge R7425, PowerEdge R750, PowerEdge R750XA, PowerEdge R750xs, PowerEdge R7515, PowerEdge R7525, PowerEdge R760, PowerEdge R760XA, PowerEdge R760xd2, PowerEdge R760xs, PowerEdge R7615, PowerEdge R7625, PowerEdge R840, PowerEdge R860, PowerEdge R940, PowerEdge R940xa, PowerEdge R960, PowerEdge T430, PowerEdge T440, PowerEdge T550, PowerEdge T560, PowerEdge T630, PowerEdge T640, Dell EMC vSAN C6420 Ready Node, Dell EMC vSAN MX740c Ready Node, Dell EMC vSAN MX750c Ready Node, Dell vSAN Ready Node MX760c, Dell EMC vSAN R440 Ready Node, Dell EMC vSAN R640 Ready Node, Dell EMC vSAN R6415 Ready Node, Dell EMC vSAN R650 Ready Node, Dell EMC vSAN R6515 Ready Node, vSAN Ready Node R660, Dell vSAN R6615 Ready Node, Dell EMC vSAN R740 Ready Node, Dell EMC vSAN R740xd Ready Node, Dell EMC vSAN R750 Ready Node, Dell EMC vSAN R7515 Ready Node, Dell EMC vSAN R760 Ready Node, Dell vSAN R7615 Ready Node, Dell vSAN Ready Node R7625, Dell EMC vSAN R840 Ready Node, Dell EMC vSAN T350 Ready Node
...
문서 속성
문서 번호: 000209262
문서 유형: How To
마지막 수정 시간: 29 5월 2026
버전: 7
다른 Dell 사용자에게 질문에 대한 답변 찾기
지원 서비스
디바이스에 지원 서비스가 적용되는지 확인하십시오.