DataDomain. Руководство по обновлению ОС для систем высокой доступности (HA)
Сводка: Обзор процесса модернизации Data Domain Operation System (DDOS) на устройствах Data Domain «Highly Available» (DDHA).
Инструкции
Плановое обслуживание системы HA
Для сокращения плановых простоев при обслуживании в архитектуру HA включена накопительная модернизация системы. Накопительная модернизация может в первую очередь модернизировать резервный узел, а затем использовать ожидаемое переключение HA при отказе для перемещения служб с активного узла на резервный узел. И наконец, ранее активные узлы модернизируются и присоединяются к кластеру HA в качестве резервного узла. Все эти процессы выполняются с помощью одной команды.
Альтернативный подход к модернизации вручную носит название «локальная модернизация». Сначала вручную модернизируется резервный узел, а затем вручную модернизируется активный узел. И наконец, резервный узел присоединяется к кластеру HA. Локальную модернизацию можно выполнить как для регулярного обновления, так и для устранения неполадок.
Все операции обновления системы на активном узле, требующие преобразования данных, могут не запускаться, пока обе системы не будут модернизированы до одного уровня и состояние высокой доступности не будет полностью восстановлено.
Перед выполнением этой процедуры необходимо ознакомиться с этой статьей базы знаний:
PowerProtect Data Domain. Предварительная проверка модернизации DDHA
DDOS 5.7 и более поздних версий поддерживает два вида методов модернизации систем HA.
-
Накопительная модернизация — автоматическая модернизация обоих узлов HA с помощью одной команды. После модернизации служба перемещается на другой узел.
-
Локальная модернизация — модернизация узлов HA вручную по одному. После модернизации служба сохраняется на том же узле.
Подготовьте систему к модернизации.
-
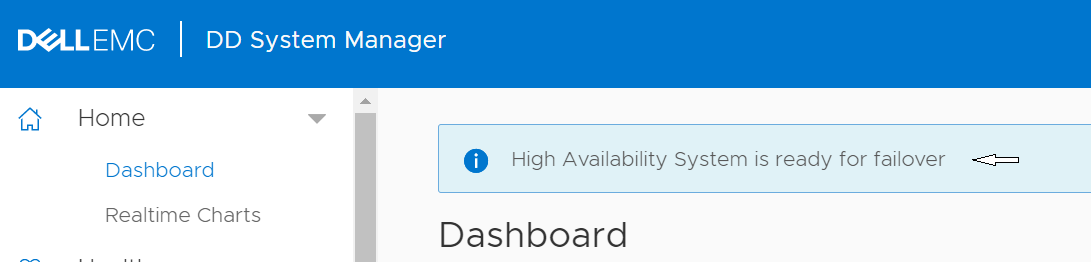
Убедитесь, что система HA находится в состоянии «highly available».
Графический интерфейс пользователя для входа -> Главная -> Панель управления
- Файл DDOS RPM должен быть размещен на активном узле; модернизация должна начинаться с этого узла.
Графический интерфейс пользователя для входа -> Главная -> Панель управления

- Загрузите файл RPM на активный узел.
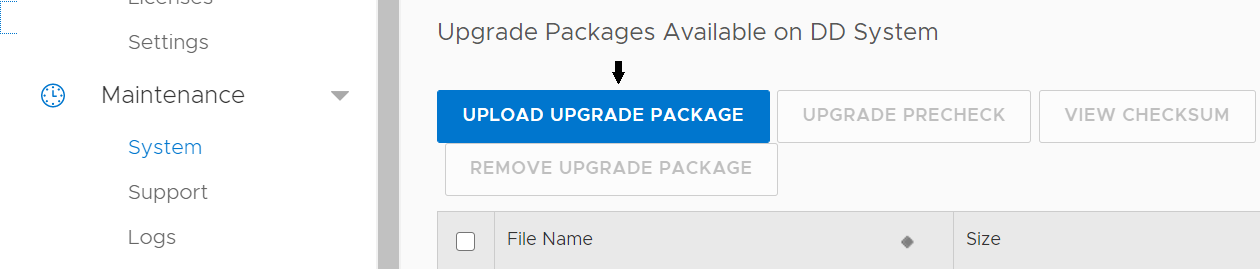 ЗАГРУЗИТЬ ПАКЕТ МОДЕРНИЗАЦИИПосле загрузки в списке появится файл RPM.
ЗАГРУЗИТЬ ПАКЕТ МОДЕРНИЗАЦИИПосле загрузки в списке появится файл RPM.
- Выполните предварительную проверку на активном узле. При возникновении какой-либо ошибки модернизация должна быть прервана.

Также выключите очистку, перемещение данных и репликацию файлов перед началом модернизации (шаг #6), чтобы эти задания не приводили к увеличению времени завершения работы DDFS во время обновления. Сокращение времени завершения работы DDFS поможет свести к минимуму воздействие на клиентов. Эти рабочие нагрузки не влияют на операции резервного копирования и восстановления на стороне клиента.
В зависимости от потребностей эти службы можно возобновить после завершения модернизации с помощью соответствующих команд включения. Дополнительные сведения см. в руководстве по администрированию.
Существуют и другие выполняемые вручную проверки и команды, описанные в руководстве по администрированию, которые не являются строго необходимыми для системы HA. В качестве теста для систем с одним узлом в настоящее время рекомендуется выполнить подготовку к перезагрузке. Она не требуется для систем HA, так как приведенный ниже шаг 5 («Переключение HA при отказе») предусматривает автоматическую перезагрузку в процессе переключения при отказе.
- Опционально. Перед выполнением последовательного обновления рекомендуется дважды вручную выполнить отработку отказа высокой доступности на активном узле. Целью является проверка функциональности переключения при отказе. Обратите внимание: эта операция приведет к перезагрузке активного узла.
Сначала подготовьтесь к переключению на резервный ресурс, выполнив очистку, перемещение данных и репликацию. Чтобы узнать, как это сделать с помощью графического интерфейса пользователя, см. руководство по администрированию. Эти службы не влияют на рабочие нагрузки резервного копирования и восстановления на стороне клиента. Затем перейдите к выполнению «ha failover».

(когда состояние системы HA снова станет «высокодоступной», выполните второе «отработка отказа ha» и подождите, пока оба узла не перейдут в режим онлайн)
После аварийного переключения HA остановленные службы можно возобновить с помощью соответствующих команд включения. Дополнительные сведения см. в руководстве по администрированию.
Указанные выше тесты переключения при отказе являются опциональными; можно не проводить их непосредственно перед модернизацией. Тесты переключения при отказе можно выполнить до модернизации (например, за две недели), чтобы при последующей модернизации можно было сократить период обслуживания. Время простоя службы DDFS для каждого переключения при отказе составляет около 10 минут (точное время зависит от версий DDOS и некоторых других факторов). Версия DDOS 7.4 и более поздние позволяют все больше сокращать простои с каждым выпуском, поскольку программное обеспечение DDOS продолжает улучшаться.
- Если предварительная проверка завершена без каких-либо проблем, перейдите к выполнению накопительной модернизации на активном узле.

- Дождитесь завершения накопительной модернизации. Перед этим не запускайте операцию переключения HA на резервный ресурс.
Доступность DDFS во время выполнения указанной выше команды.
-
Сначала резервный узел модернизируется и перезагружается до новой версии. Это занимает от 20 до 30 минут в зависимости от различных факторов. В течение этого периода служба DDFS включена и работает на активном узле без снижения производительности
-
После применения новой версии DDOS система переключает службу DDFS на модернизированный резервный узел. Это занимает примерно 10 минут (точное время зависит от различных факторов).
-
Одним из важных факторов является модернизация микропрограммы дисковой полки (DAE). В зависимости от количества настроенных DAE время простоя может увеличиться примерно на 20 минут. См. статью базы знаний «Data Domain. Накопительная модернизация HA может завершиться сбоем при модернизации микропрограммы внешнего шасси». Эта статья поможет определить, требуется ли модернизация микропрограммы DAE. Обратите внимание: в DDOS 7.5 и более поздних версий предусмотрено улучшение для включения микропрограммы DAE с целью онлайн-модернизации, что позволяет устранить эту проблему.
-
Можно обратиться в службу поддержки Dell, чтобы обсудить факторы, которые могут повлиять на время модернизации. В зависимости от ОС клиента, приложения и протокола взаимодействия между клиентом и системой HA в некоторых случаях пользователю может потребоваться вручную возобновить рабочие нагрузки клиента сразу после переключения при отказе. Например, если время переключения при отказе превышает 10 минут при взаимодействии с клиентами DDBoost, у клиента истекает время ожидания и пользователю необходимо вручную возобновить рабочие нагрузки. Но обычно клиентам доступны настройки, позволяющие устанавливать значения времени ожидания и количество попыток.
-
Обратите внимание: служба DDFS не работает в течение периода переключения при отказе. Благодаря просмотру выходных данных команды «filesys status» на модернизированном узле можно узнать, возобновлена ли работа службы DDFS. В DDOS 7.4 и более поздних версий, как ожидается, простои будут все больше сокращаться благодаря улучшениям в коде DDOS.
После переключения при отказе будет модернизирован ранее активный узел. После применения модернизации он перезагрузится до новой версии, а затем присоединится к кластеру HA в качестве резервного узла. Этот процесс не влияет на работу службы DDFS, так как она уже была возобновлена выше.
Проверка:
- После завершения последовательной модернизации необходимо войти в графический интерфейс пользователя через IP-адрес предрезервного узла, в данном случае это узел 1.

- Проверьте, нет ли непредвиденных оповещений.
- На этом этапе накопительная модернизация успешно завершена.
Накопительная модернизация с помощью CLI
Подготовьте систему к модернизации.
- Убедитесь, что система HA находится в состоянии «highly available».
#ha status
HA System name: HA-system
HA System status: highly available <-
Node Name Node id Role HA State
----------------------------- ------- ------- --------
Node0 0 active online
Node1 1 standby online
----------------------------- ------- ------- --------
- Файл DDOS RPM должен быть размещен на активном узле; модернизация должна начинаться с этого узла.
#ha status
HA System name: HA-system
HA System status: highly available
Node Name Node id Role HA State
----------------------------- ------- ------- --------
Node0 0 active online Node0 is active node
Node1 1 standby online
----------------------------- ------- ------- --------
- Загрузите файл RPM на активный узел.
Client-server # scp <rpm file> sysadmin@HA-system.active_node:/ddr/var/releases/
Password: (customer defined it.)
(From client server, target path is “/ddr/var/releases”)
You might need the -O option to get scp to work
Active-node # system package list
File Size (KiB) Type Class Name Version ------------------ ---------- ------ ---------- ----- ------- x.x.x.x-12345.rpm 2927007.3 System Production DD OS x.x.x.x ------------------ ---------- ------ ---------- ----- -------
- Выполните предварительную проверку на активном узле. При возникновении какой-либо ошибки модернизация должна быть прервана.
Active-node # system upgrade precheck <rpm file>
Upgrade precheck in progress:
Node 0: phase 1/1 (Precheck 100%) , Node 1: phase 1/1 (Precheck 100%)
Upgrade precheck found no issues.
Кроме того, перед началом модернизации (шаг 6) завершите работу GC и перемещение и репликацию данных, чтобы эти задания не увеличили время завершения работы DDFS во время модернизации. Сокращение времени завершения работы DDFS поможет свести к минимуму воздействие на клиентов. Эти рабочие нагрузки не влияют на операции резервного копирования и восстановления на стороне клиента. В зависимости от потребностей эти службы можно возобновить после завершения модернизации с помощью соответствующих команд включения. Дополнительные сведения см. в руководстве по администрированию. Active-node # filesys clean stop Active-node # cloud clean stop Active-node # replication disable all
Обратите внимание: существует несколько команд «watch» для проверки выполнения указанных выше операций.
Active-node # filesys clean watch
Active-node # cloud clean watch
Существуют и другие выполняемые вручную проверки и команды, описанные в руководстве по администрированию, которые не являются строго необходимыми для системы HA. В качестве теста для систем с одним узлом в настоящее время рекомендуется выполнить подготовку к перезагрузке. Она не требуется для систем HA, так как приведенный ниже шаг 5 («Переключение HA при отказе») предусматривает автоматическую перезагрузку в процессе переключения при отказе.
- Опционально. Перед выполнением последовательного обновления рекомендуется дважды вручную выполнить отработку отказа высокой доступности на активном узле. Целью является проверка функциональности переключения при отказе. Обратите внимание: эта операция приведет к перезагрузке активного узла.
Во-первых, подготовьтесь к переключению при отказе. Для этого завершите работу GC и перемещение и репликацию данных. Эти службы не влияют на рабочие нагрузки резервного копирования и восстановления на стороне клиента. Затем выполните «ha failover».
Для этого используются следующие команды:
Active-node # filesys clean stop
Active-node # cloud clean stop
Active-node # replication disable all
Обратите внимание: существует несколько команд «watch» для проверки выполнения указанных выше операций.
Active-node # filesys clean watch
Active-node # cloud clean watch
Затем выполните команду переключения на резервный ресурс:
Active-node # ha failoverThis operation will initiate a failover from this node. The local node will reboot.
Do you want to proceed? (yes|no) [no]: yes
Failover operation initiated. Run 'ha status' to monitor the status
(Когда система HA вновь перейдет в состояние «highly available», выполните вторую операцию «ha failover» и подождите, пока оба узла не перейдут в режим онлайн.)
После аварийного переключения HA остановленные службы можно возобновить с помощью соответствующих команд включения. Дополнительные сведения см. в руководстве по администрированию.
Указанные выше тесты переключения при отказе являются опциональными; можно не проводить их непосредственно перед модернизацией. Тесты переключения при отказе можно выполнить до модернизации (например, за две недели), чтобы при последующей модернизации можно было сократить период обслуживания. Время простоя службы DDFS для каждого переключения при отказе составляет около 10 минут (точное время зависит от версий DDOS и некоторых других факторов). Версия DDOS 7.4 и более поздние позволяют все больше сокращать простои с каждым выпуском, поскольку программное обеспечение DDOS продолжает улучшаться.
- Если предварительная проверка завершена без каких-либо проблем, перейдите к выполнению накопительной модернизации на активном узле.
Active-node # system upgrade start <rpm file> Команда «system upgrade» модернизирует ОС Data Domain. Во время модернизации доступ к файлам прерывается.
После модернизации система автоматически перезагрузится.
Are you sure? (yes|no) [no]: yes ok, proceeding. Upgrade in progress: Node Severity Issue Solution ---- -------- ------------------------------ -------- 0 WARNING 1 component precheck script(s) failed to complete 0 INFO Upgrade time est: 60 mins 1 WARNING 1 component precheck script(s) failed to complete 1 INFO Upgrade time est: 80 mins ---- -------- ------------------------------ -------- Node 0: phase 2/4 (Install 0%) , Node 1: phase 1/4 (Precheck 100%) Upgrade phase status legend: DU : Data Upgrade FO : Failover .. PC : Peer Confirmation VA : Volume Assembly Node 0: phase 3/4 (Reboot 0%) , Node 1: phase 4/4 (Finalize 5%) FO Upgrade has started. System will reboot.
Доступность DDFS во время выполнения указанной выше команды.
-
Сначала резервный узел модернизируется и перезагружается до новой версии. Это занимает от 20 до 30 минут в зависимости от различных факторов. Служба DDFS работает на активном узле в течение этого периода без ухудшения производительности.
-
После применения новой версии DDOS система переключает службу DDFS на модернизированный резервный узел. Это занимает примерно 10 минут (точное время зависит от различных факторов).
-
Одним из важных факторов является обновление микропрограммы дисковой полки (DAE). В зависимости от количества настроенных DAE время простоя может увеличиться примерно на 20 минут. См. статью базы знаний «Data Domain. Накопительная модернизация HA может завершиться сбоем при модернизации микропрограммы внешнего шасси». Эта статья поможет определить, требуется ли модернизация микропрограммы DAE. Обратите внимание: в DDOS 7.5 и более поздних версий предусмотрено улучшение для включения микропрограммы DAE с целью онлайн-модернизации, что позволяет устранить эту проблему.
-
Можно обратиться в службу поддержки Dell, чтобы обсудить факторы, которые могут повлиять на время модернизации. В зависимости от ОС клиента, приложения и протокола взаимодействия между клиентом и системой HA в некоторых случаях пользователю может потребоваться вручную возобновить рабочие нагрузки клиента сразу после переключения при отказе. Например, если время переключения при отказе превышает 10 минут при взаимодействии с клиентами DDBoost, у клиента истекает время ожидания и пользователю необходимо вручную возобновить рабочие нагрузки. Но обычно клиентам доступны настройки, позволяющие устанавливать значения времени ожидания и количество попыток.
-
-
После переключения при отказе будет модернизирован ранее активный узел. После применения модернизации он перезагрузится до новой версии, а затем присоединится к кластеру HA в качестве резервного узла. Этот процесс не влияет на работу службы DDFS, так как она уже была возобновлена выше.
- После того как резервный узел (node1) перезагрузится и станет доступен, можно войти в резервный узел для отслеживания состояния/хода выполнения модернизации.
Node1 # system upgrade status
Current Upgrade Status: DD OS upgrade In Progress
Node 0: phase 3/4 (Reboot 0%)
Node 1: phase 4/4 (Finalize 100%) waiting for peer confirmation
- Дождитесь завершения накопительной модернизации. Перед этим не запускайте операцию переключения HA на резервный ресурс.
Node1 # system upgrade status
Current Upgrade Status: DD OS upgrade Succeeded
End time: 20xx.xx.xx:xx:xx
- Проверьте состояние HA. Оба узла должны находиться в режиме онлайн, система HA должна быть в состоянии «highly available».
Node1 # ha status detailed
HA System name: HA-system
HA System Status: highly available
Interconnect Status: ok
Primary Heartbeat Status: ok
External LAN Heartbeat Status: ok
Hardware compatibility check: ok
Software Version Check: ok
Node Node1:
Role: active
HA State: online
Node Health: ok
Node Node0:
Role: standby
HA State: online
Node Health: ok
Mirroring Status:
Component Name Status
-------------- ------
nvram ok
registry ok
sms ok
ddboost ok
cifs ok
-------------- ------
Проверка:
- Убедитесь, что оба узла имеют одинаковую версию DDOS.
Node1 # system show version
Data Domain OS x.x.x.x-12345
Node0 # system show version
Data Domain OS x.x.x.x-12345
- Проверьте, нет ли непредвиденных оповещений.
Node1 # alert show current
Node0 # alert show current
- На этом этапе накопительная модернизация успешно завершена.
Примечание. При возникновении каких-либо проблем с обновлением обратитесь в службу поддержки Data Domain для получения дальнейших инструкций.
ЛОКАЛЬНОЕ ОБНОВЛЕНИЕ для пары DDHA:
Локальная модернизация в целом выполняется следующим образом.
Подготовьте систему к модернизации.
- Проверьте состояние системы HA. Даже если ее состояние ухудшилось, в этой ситуации может быть полезной локальная модернизация.
#ha status HA System name: HA-system HA System status: highly available <- Node Name Node id Role HA State ----------------------------- ------- ------- -------- Node0 0 active online Node1 1 standby online ----------------------------- ------- ------- --------
- Файл DDOS RPM должен быть размещен на обоих узлах; модернизация должна начинаться с резервного узла.
#ha status
HA System name: HA-system
HA System status: highly available
Node Name Node id Role HA State
----------------------------- ------- ------- --------
Node0 0 active online
Node1 1 standby online <- Node1 is standby node
----------------------------- ------- ------- --------
- Загрузите файл RPM на оба узла.
Client-server # scp <rpm file> sysadmin@HA- system.active_node:/ddr/var/releases/
Client-server # scp <rpm file> sysadmin@HA-system.standby_node:/ddr/var/releases/
Password: (customer defined it.)
You might need the -O option to get scp to work(From client server, target path is “/ddr/var/releases”)
Active-node # system package list File Size (KiB) Type Class Name Version ------------------ ---------- ------ ---------- ----- ------- x.x.x.x-12345.rpm 2927007.3 System Production DD OS x.x.x.x ------------------ ---------- ------ ---------- ----- ------ Standby-node # system package list File Size (KiB) Type Class Name Version ------------------ ---------- ------ ---------- ----- ------- x.x.x.x-12345.rpm 2927007.3 System Production DD OS x.x.x.x ------------------ ---------- ------ ---------- ----- ------
- Выполните предварительную проверку на активном узле, если HA находится в состоянии «highly available». При возникновении какой-либо ошибки модернизация должна быть прервана.
Active-node # system upgrade precheck <rpm file>
Upgrade precheck in progress: Node 0: phase 1/1 (Precheck 100%) , Node 1: phase 1/1 (Precheck 100%) Upgrade precheck found no issues.
If HA status is "degraded", need do precheck on both nodes.
Active-node # system upgrade precheck <rpm file> local
Upgrade precheck in progress:
Node 0: phase 1/1 (Precheck 100%)
Upgrade precheck found no issues.
Standby-node # system upgrade precheck <rpm file> local
Upgrade precheck in progress:
Node 1: phase 1/1 (Precheck 100%)
Upgrade precheck found no issues.
- Переведите резервный узел в автономный режим.
Standby-node # ha offline
This operation will cause the ha system to no longer be highly available.
Do you want to proceed? (yes|no) [no]: yes
Standby node is now offline.
(ПРИМЕЧАНИЕ. Если операция в автономном режиме завершилась сбоем или состояние высокой доступности ухудшилось, продолжите локальное обновление, так как последующие действия могут привести к сбоям.)
- Убедитесь, что резервный узел находится в автономном режиме.
Standby-node # ha status
HA System name: HA-system
HA System status: degraded
Node Name Node id Role HA State
----------------------------- ------- ------- --------
Node1 1 standby offline
Node0 0 active degraded
----------------------------- ------- ------- --------
- Выполните модернизацию на резервном узле. Эта операция вызовет перезагрузку резервного узла.
The 'system upgrade' command upgrades the Data Domain OS. File access
is interrupted during the upgrade. The system reboots automatically
after the upgrade.
Are you sure? (yes|no) [no]: yes
ok, proceeding.
The 'local' flag is highly disruptive to HA systems and should be used only as a repair operation.
Are you sure? (yes|no) [no]: yes
ok, proceeding.
Upgrade in progress:
Node 1: phase 3/4 (Reboot 0%)
Upgrade has started. System will reboot.
- Резервный узел перезагрузится до новой версии DDOS, но останется в автономном режиме.
- Проверьте состояние модернизации системы. Для завершения модернизации ОС может потребоваться более 30 минут.
Standby-node # system upgrade status
Current Upgrade Status: DD OS upgrade Succeeded
End time: 20xx.xx.xx:xx:xx
- Проверьте состояние системы HA. Резервный узел (в нашем случае это узел 1) должен находиться в автономном режиме, система HA должна находиться в состоянии «degraded».
Standby-node # ha status
HA System name: HA-system
HA System status: degraded
Node Name Node id Role HA State
----------------------------- ------- ------- --------
Node1 1 standby offline
Node0 0 active degraded
----------------------------- ------- ------- --------
- Выполните локальную модернизацию на активном узле. Эта операция приведет к перезагрузке активного узла.
Active-node # system upgrade start <rpm file> local
The 'system upgrade' command upgrades the Data Domain OS. File access
is interrupted during the upgrade. The system reboots automatically
after the upgrade.
Are you sure? (yes|no) [no]: yes
ok, proceeding.
The 'local' flag is highly disruptive to HA systems and should be used only as a repair operation.
Are you sure? (yes|no) [no]: yes
ok, proceeding.
Upgrade in progress:
Node Severity Issue Solution
---- -------- ------------------------------ --------
0 WARNING 1 component precheck
script(s) failed to complete
0 INFO Upgrade time est: 60 mins
---- -------- ------------------------------ --------
Node 0: phase 3/4 (Reboot 0%)
Upgrade has started. System will reboot.
- Проверьте состояние модернизации системы. Для завершения модернизации ОС может потребоваться более 30 минут.
Active-node # system upgrade status
Current Upgrade Status: DD OS upgrade Succeeded
End time: 20xx.xx.xx:xx:xx
- После завершения модернизации активного узла система HA по-прежнему будет находиться в состоянии «degraded». Выполните следующую команду, чтобы перевести резервный узел в режим онлайн. Команда перезагрузит резервный узел.
Standby-node # ha online The operation will reboot this node. Do you want to proceed? (yes|no) [no]: yes Broadcast message from root (Wed Oct 14 22:38:53 2020): The system is going down for reboot NOW! **** Error communicating with management service.(ПРИМЕЧАНИЕ. Если команда «ha offline» не выполнялась на предыдущих шагах, игнорируйте этот шаг.)
- Резервный узел перезагрузится и снова присоединится к кластеру. После этого система HA вновь перейдет в состояние «highly available».
Active-node # ha status detailed
HA System name: Ha-system
HA System Status: highly available
Interconnect Status: ok
Primary Heartbeat Status: ok
External LAN Heartbeat Status: ok
Hardware compatibility check: ok
Software Version Check: ok
Node node0:
Role: active
HA State: online
Node Health: ok
Node node1:
Role: standby
HA State: online
Node Health: ok
Mirroring Status:
Component Name Status
-------------- ------
nvram ok
registry ok
sms ok
ddboost ok
cifs ok
-------------- ------
Проверка:
- Убедитесь, что оба узла имеют одинаковую версию DDOS.
Node1 # system show version
Data Domain OS x.x.x.x-12345
Node0 # system show version
Data Domain OS x.x.x.x-12345
- Проверьте, нет ли непредвиденных оповещений.
Node1 # alert show current
Node0 # alert show current
- На этом этапе накопительная модернизация успешно завершена.
Дополнительная информация
Накопительная модернизация
-
Обратите внимание: во время модернизации выполняется одно переключение при отказе, поэтому роли будут меняться.
-
Информация о модернизации по-прежнему хранится в infra.log, но ha.log может содержать дополнительную информацию.
-
Ход модернизации можно отслеживать с помощью системного средства наблюдения.
Локальная модернизация узла
-
Локальная модернизация узла не выполняет переключение HA при отказе.
-
В результате будет иметь место длительный период простоя, пока активный узел выполняет модернизацию/перезагрузку/действия по модернизации после перезагрузки, что с высокой вероятностью приведет к истечению времени ожидания и сбою резервного копирования/восстановления. Требуется выделить временной промежуток на обслуживание для локальной модернизации.
-
Даже если система HA находится в состоянии «degraded», локальная модернизация может быть продолжена.
-
По какой-то причине накопительная модернизация может завершиться непредвиденным сбоем. В этой ситуации локальная модернизация может рассматриваться в качестве метода исправления.