PowerEdge: AMD Rome - 아키텍처 및 초기 HPC 성능
요약: 오늘날 HPC 분야에서는 AMD의 최신 세대 EPYC 프로세서인 Rome 코드명이 소개되고 있습니다.
이 문서는 다음에 적용됩니다.
이 문서는 다음에 적용되지 않습니다.
이 문서는 특정 제품과 관련이 없습니다.
모든 제품 버전이 이 문서에 나와 있는 것은 아닙니다.
지침
Garima Kochhar, Deepthi Cherlopalle, Joshua Weage에 관한 자세한 내용을 참조하십시오. HPC 및 AI Innovation Lab, 2019년 10월
오늘날 HPC 세계에서 AMD의 최신 세대 EPYC 프로세서인 Rome은 별도의 소개가 필요하지 않습니다. 지난 몇 달 동안 HPC 및 AI Innovation Lab
에서 Rome 기반 시스템을 평가해 왔으며, Dell Technologies는 이 프로세서 아키텍처를 지원하는 서버를 최근에 발표했습니다
. Rome Series의 첫 번째 블로그에서는 Rome 프로세서 아키텍처에 대해 설명하고 HPC 성능을 위해 이를 튜닝하는 방법과 초기 마이크로 벤치마크 성능을 소개합니다. 후속 블로그에서는 CFD, CAE, 분자 역학, 기상 시뮬레이션 및 기타 애플리케이션의 분야에서의 애플리케이션 성능에 대해 설명합니다.
아키텍처
Rome은 AMD의 2세대 EPYC CPU로, 1세대 Naples의 후속 제품입니다.
HPC에 유리한 Naples와 Rome 간 가장 큰 아키텍처 차이 중 하나는 Rome에 새롭게 도입된 I/O 다이입니다. Rome에서 각 프로세서는 그림 1과 같이 최대 9개의 칩렛으로 구성된 멀티칩 패키지입니다. 중앙에 위치한 14nm I/O 다이 하나가 모든 I/O 및 메모리 기능을 담당합니다. 여기에는 메모리 컨트롤러, 소켓 내부의 Infinity Fabric 링크, 소켓 간 연결, PCI-e 등이 포함됩니다. 소켓당 8개의 메모리 컨트롤러가 있으며, 이는 DDR4 3,200MT/s로 동작하는 8개 메모리 채널을 지원합니다. 단일 소켓 서버는 최대 130개의 PCIe Gen4 레인을 지원할 수 있습니다. 듀얼 소켓 시스템은 최대 160개의 PCIe Gen4 레인을 지원할 수 있습니다.
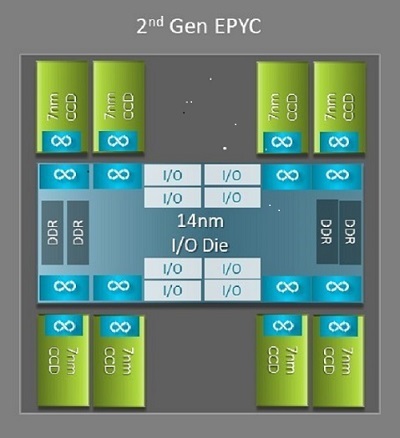
(그림 1 중앙 I/O 다이 1개와 최대 8코어 다이가 포함된 Rome 멀티칩 패키지)
중앙 I/O 다이 주변에는 최대 8개의 7nm 코어 칩렛이 있습니다. 코어 칩렛을 Core Cache Die 또는 CCD라고 합니다. 각 CCD에는 Zen2 마이크로아키텍처, L2 캐시 및 32MB L3 캐시를 기반으로 하는 CPU 코어가 있습니다. CCD 자체에는 2개의 CCX(Core Cache Complex)가 있으며, 각 CCX에는 최대 4개의 코어와 16MB의 L3 캐시가 있습니다. 그림 2는 CCX를 보여줍니다.

(그림 2 4개의 코어와 공유 16MB L3 캐시가 있는 CCX)
Rome CPU 모델마다 코어 수는 다르지만
모두 하나의 중앙 I/O 다이가 있습니다.
최상단에는 64코어 CPU 모델이 있습니다(예: EPYC 7702). Lstopo 출력은 이 프로세서가 소켓당 16개의 CCX를 가지고 있음을 보여줍니다. 그림 3 및 4와 같이 각 CCX에는 4개의 코어가 있으므로 소켓당 64개의 코어가 생성됩니다. CCX당 16MB L3, 즉 CCD당 32MB L3은 이 프로세서에 256MB L3 캐시를 제공합니다. 그러나 Rome의 총 L3 캐시는 모든 코어에서 공유되지 않습니다. 각 CCX의 16MB L3 캐시는 독립적이며 그림 2와 같이 CCX의 코어에서만 공유됩니다.
EPYC 7402와 같은 24코어 CPU에는 128MB L3 캐시가 있습니다. 그림 3 및 4의 Lstopo 출력은 이 모델이 CCX당 3개의 코어와 소켓당 8개의 CCX를 가지고 있음을 보여줍니다.


(그림 3 & 4: 64코어 및 24코어 CPU용 Lstopo 출력)
CCD의 개수와 관계없이, 각 Rome 프로세서는 논리적으로 4개의 쿼드런트로 구분되며, CCD는 가능한 한 균등하게 각 쿼드런트에 분산되고, 각 쿼드런트에는 두 개의 메모리 채널이 있습니다. 중앙 I/O 다이는 소켓의 4개 쿼드런트를 논리적으로 지원하는 구조로 볼 수 있습니다.
Rome 아키텍처 기반의 BIOS 옵션
Rome의 중앙 I/O 다이는 Naples 대비 측정된 메모리 레이턴시를 개선하는 데 도움이 됩니다. 또한 CPU를 단일 NUMA 도메인으로 구성하여 소켓의 모든 코어에 대해 균일한 메모리 액세스를 수행할 수 있습니다. 이는 아래에 설명되어 있습니다.
Rome 프로세서의 4개 논리적 쿼드런트는 CPU를 서로 다른 NUMA 도메인으로 분할할 수 있게 합니다. 이 설정을 소켓당 NUMA 또는 NPS라고합니다.
- NPS1은 Rome CPU가 단일 NUMA 도메인임을 의미하며, 소켓 내 모든 코어와 메모리가 이 하나의 NUMA 도메인에 속합니다. 메모리는 8개의 메모리 채널에 걸쳐 인터리빙됩니다. 소켓의 모든 PCIe 디바이스는 이 단일 NUMA 도메인에 속합니다.
- NPS2는 CPU를 2개의 NUMA 도메인으로 분할하며, 각 NUMA 영역에는 소켓에 있는 코어와 메모리 채널의 절반이 있습니다. 메모리는 각 NUMA 도메인의 4개 메모리 채널에 걸쳐 인터리빙됩니다.
- NPS4는 CPU를 4개의 NUMA 도메인으로 파티셔닝합니다. 여기서 각 쿼드런트는 하나의 NUMA 도메인이며, 메모리는 각 쿼드런트 내 2개의 메모리 채널에 걸쳐 인터리빙됩니다. PCIe 디바이스는 해당 디바이스의 PCIe 루트가 I/O 다이의 어느 쿼드런트에 위치하는지에 따라 소켓의 4개 NUMA 도메인 중 하나에 속하게 됩니다.
- 모든 CPU가 모든 NPS 설정을 지원할 수 있는 것은 아닙니다.
가능한 경우, HPC에서는 NPS4 사용을 권장합니다. NPS4는 가장 높은 메모리 대역폭과 가장 낮은 메모리 레이턴시를 제공할 것으로 예상되며, 당사의 애플리케이션은 대체로 NUMA를 인식하도록 설계되어 있기 때문입니다. NPS4를 사용할 수 없는 경우 CPU 모델에서 지원하는 가장 높은 NPS(NPS2 또는 NPS1)를 사용하는 것이 좋습니다.
Rome 기반 플랫폼에서 다양한 NUMA 옵션을 제공함에 따라, PowerEdge BIOS는 MADT 열거에서 두 가지 코어 열거 방법을 지원합니다. 선형 열거 방식은 코어를 순서대로 번호를 매기며, 하나의 CCX, CCD, 소켓을 채운 뒤 다음 소켓으로 넘어갑니다. 32c CPU에서 코어 0~31은 첫 번째 소켓에, 코어 32~63은 두 번째 소켓에 있습니다. 라운드 로빈 열거 방식은 NUMA 영역 전반에 걸쳐 코어에 번호를 부여합니다. 이 경우 짝수 번호의 코어는 첫 번째 소켓에, 홀수 번호의 코어는 두 번째 소켓에 있습니다. 단순성을 위해 HPC에 선형 열거를 사용하는 것이 좋습니다. NPS4에 구성된 듀얼 소켓 64c 서버의 선형 코어 열거 예는 그림 5를 참조하십시오. 그림에서 4개의 코어가 있는 각 박스는 CCX이고, 8개의 연속된 코어가 있는 각 세트는 CCD입니다.
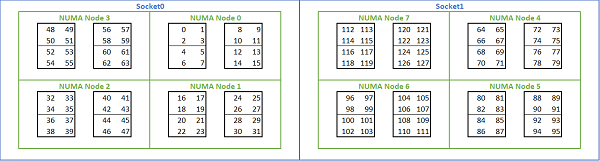
(그림 5 듀얼 소켓 시스템의 선형 코어 열거, 소켓당 64c, 8개의 CCD CPU 모델의 NPS4 구성)
Rome에 특화된 BIOS 옵션 중 하나는 기본 I/O 디바이스입니다. 이는 InfiniBand 대역폭과 메시지 속도를 튜닝하는 중요한 요소입니다. 이를 통해 플랫폼은 하나의 I/O 디바이스에 대한 트래픽의 우선순위를 지정할 수 있습니다. 이 옵션은 단일 소켓 및 듀얼 소켓 Rome 플랫폼에서 사용할 수 있으며, 모든 CPU 코어가 활성 상태일 때 전체 메시지 속도를 달성하려면 BIOS 메뉴에서 플랫폼의 InfiniBand 디바이스를 기본 디바이스로 선택해야 합니다.
Naples와 마찬가지로 Rome 역시 하이퍼스레딩 또는 논리 프로세서를 지원합니다. HPC의 경우 이 기능을 비활성화된 상태로 두지만 일부 애플리케이션은 논리 프로세서를 활성화하면 이점을 얻을 수 있습니다. 분자 역학 응용 연구에 대한 후속 블로그를 찾아보십시오.
Naples와 마찬가지로 Rome도 CCX를 NUMA 도메인으로 허용합니다. 이 옵션은 각 CCX를 NUMA 노드로 노출합니다. CPU당 16개의 CCX가 있는 듀얼 소켓 시스템에서는 이 설정을 통해 32개의 NUMA 도메인이 노출됩니다. 이 예에서 각 소켓에는 8개의 CCD, 즉 16 CCX가 있습니다. 각 CCX를 개별 NUMA 도메인으로 활성화할 수 있으며, 소켓당 16개의 NUMA 노드, 듀얼 소켓 시스템에서는 총 32개의 NUMA 노드를 제공합니다. HPC 환경에서는 CCX를 NUMA 도메인으로 설정하는 옵션을 기본값인 비활성화 상태로 두는 것을 권장합니다. 이 옵션을 활성화하면 가상화 환경에 도움이 됩니다.
Naples와 마찬가지로 Rome은 시스템을 Performance Determinism 또는 Power Determinism 모드로 설정할 수 있습니다. Performance Determinism 모드에서는 시스템이 CPU 모델에 맞는 예상 주파수로 동작하여, 여러 서버 간의 변동성을 줄여줍니다. Power Determinism에서 시스템은 CPU 모델의 사용 가능한 최대 TDP에서 작동합니다. 이로 인해 제조 프로세스의 부품 간 편차가 증폭되어 일부 서버는 다른 서버보다 속도가 빨라집니다. 모든 서버는 CPU의 최대 정격 전력을 소비하므로 소비 전력이 결정적이지만 여러 서버에서 성능 차이가 어느 정도 발생할 수 있습니다.
PowerEdge 플랫폼에서 예상할 수 있듯이 BIOS에는 System Profile이라는 메타 옵션이 있습니다. 성능 최적화 시스템 프로파일을 선택하면 터보 부스트 모드가 활성화되고 C-상태가 비활성화되며, Determinism 슬라이더가 Power Determinism으로 설정되어 성능 최적화가 이루어집니다.
성능 결과 - STREAM, HPL, InfiniBand 마이크로벤치마크
많은 독자들이 바로 이 섹션으로 넘어왔을 수 있으므로 바로 살펴보겠습니다.
HPC 및 AI Innovation Lab에서는 Minerva라는 64서버 Rome 기반 클러스터를 구축했습니다. Minerva 클러스터 외에도 평가할 수 있는 몇 가지 다른 Rome CPU 샘플이 있습니다. 테스트베드는 표 1과 표 2에 설명되어 있습니다.
(표 1 본 연구에서 평가한 Rome CPU 모델)
| CPU | 소켓당 코어 수 | Config | 기본 클록 | TDP |
|---|---|---|---|---|
| 7702 | 64c | CCX당 4c | 2.0GHz | 200W |
| 7502 | 32c | CCX당 4c | 2.5GHz | 180W |
| 7452 | 32c | CCX당 4c | 2.35GHz | 155W |
| 7402 | 24c | CCX당 3c | 2.8GHz | 180W |
(표 2 테스트베드)
| 구성 요소 | 세부 정보 |
|---|---|
| 서버 | PowerEdge C6525 |
| 프로세서 | 표 1 듀얼 소켓 |
| 메모리 | 256GB, 16x16GB 3200MT/s DDR4 |
| 상호 연결 | ConnectX-6 Mellanox Infini 밴드 HDR100 |
| 운영 체제 | Red Hat Enterprise Linux 7.6 |
| 커널 | 3.10.0.957.27.2.e17.x86_64 |
| 디스크 | 240GB SATA SSD M.2 모듈 |
STREAM
Rome의 메모리 대역폭 테스트는 그림 6에 나와 있습니다. 이러한 테스트는 NPS4 모드에서 실행되었습니다. 표 1에 나열된 4개의 CPU 모델을 통해 서버의 모든 코어를 사용할 때 PowerEdge C6525의 이중 소켓 메모리 대역폭을 ~270-300GB/s로 측정했습니다. CCX당 하나의 코어만 사용하는 경우 시스템 메모리 대역폭은 모든 코어에서 측정한 것보다 약 9~17% 더 높습니다.
대부분의 HPC 워크로드는 시스템의 모든 코어를 완전히 활용하거나, HPC 센터에서는 각 서버에서 여러 작업을 동시에 실행하는 고처리량 모드로 운영됩니다. 따라서 전체 코어 메모리 대역폭은 시스템의 코어당 메모리 대역폭 및 메모리 대역폭 기능을 보다 정확하게 나타냅니다.
그림 6은 또한 소켓당 8개의 메모리 채널을 지원하지만 2667MT/s로 실행되는 이전 세대 EPYC Naples 플랫폼에서 측정한 메모리 대역폭을 보여줍니다. Rome 플랫폼은 Naples보다 5~19% 더 나은 총 메모리 대역폭을 제공하며, 이는 주로 더 빠른 3200MT/s 메모리 덕분입니다. 소켓당 64c를 사용하더라도 Rome 시스템은 코어당 2GB/s 이상을 제공할 수 있습니다.
참고: 동일하게 구성된 여러 Rome 기반 서버에서 STREAM Triad 결과에 5~10%의 성능 편차가 측정되었으며, 아래의 결과는 해당 범위의 상위 수준으로 간주해야 합니다.
서로 다른 NPS 구성을 비교한 결과, 그림 7과 같이 NPS1과 비교하여 NPS4에서 메모리 대역폭이 최대 13% 더 높게 측정되었습니다.

(그림 6 듀얼 소켓 NPS4 STREAM Triad 메모리 대역폭)

(그림 7 NPS1 대 NPS2 대 NPS 4 메모리 대역폭)
InfiniBand 대역폭 및 메시지 속도
그림 8은 단방향 및 양방향 테스트를 위한 싱글 코어 InfiniBand 대역폭을 보여줍니다. 테스트베드는 100Gbps에서 실행되는 HDR100을 사용했으며 그래프는 이러한 테스트에 대한 예상 회선 속도 성능을 보여줍니다.
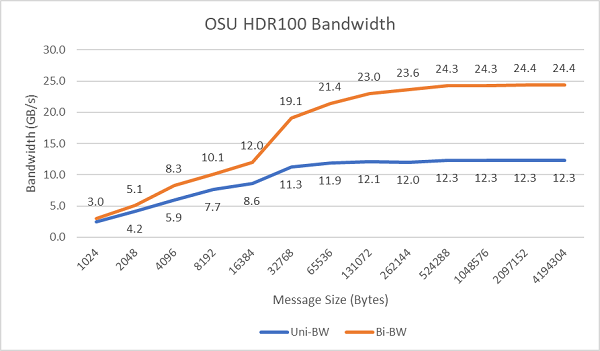
그림 8 InfiniBand 대역폭(싱글 코어)

그림 9 InfiniBand 메시지 속도(모든 코어)
테스트 대상인 두 서버에서 소켓 내 모든 코어를 사용하여 메시지 전송 속도 테스트를 진행했습니다. BIOS에서 Preferred I/O가 활성화되고 ConnectX-6 HDR100 어댑터가 기본 디바이스로 구성된 경우 그림 9와 같이 기본 I/O가 활성화되지 않은 경우보다 모든 코어 메시지 속도가 더 높습니다. 이는 HPC 및 특히 다중 노드 애플리케이션 확장성을 튜닝할 때 이 BIOS 옵션의 중요성을 보여줍니다.
HPL
Rome 마이크로아키텍처는 사이클당 16 DP FLOP을 처리할 수 있으며, 이는 사이클당 8FLOP을 처리했던 Naples의 두 배에 해당합니다. 이로써 Rome은 Naples보다 이론적 최대 FLOPS가 4배 높습니다. 이는 부동소수점 연산 성능 향상으로 인한 2배 증가와, 코어 수가 두 배(64코어 및 32코어 비교)로 늘어난 데 따른 2배 증가의 결과입니다. 그림 10은 테스트한 4개의 Rome CPU 모델에 대한 측정된 HPL 결과와 Naples 기반 시스템의 이전 결과를 보여줍니다. Rome HPL 효율성은 그래프의 막대 위에 있는 백분율 값으로 표시되며 TDP CPU 모델이 낮은 경우 더 높습니다.
테스트는 전원 결정 모드에서 실행되었으며, 동일하게 구성된 64개의 서버에서 약 5%의 성능 델타가 측정되었습니다. 따라서 결과는 해당 성능 대역에 있습니다.

(그림 10 NPS4의 단일 서버 HPL)
다음 다중 노드 HPL 테스트가 수행되었고 그 결과는 그림 11에 나타나 있습니다. EPYC 7452의 HPL 효율성은 64노드 규모에서 90% 이상으로 유지되지만, 효율성이 102%에서 97%로 떨어지고 다시 99%까지 떨어지는 경우 추가 평가가 필요합니다.

(그림 11 멀티 노드 HPL, HDR100 InfiniBand 기반 듀얼 소켓 EPYC 7452)
요약 및 향후 내용:
Rome에 기반을 둔 서버에 대한 초기 성능 연구는 첫 번째 HPC 벤치마크 세트에 대해 예상되는 성능을 보여줍니다. BIOS 튜닝은 최상의 성능을 위해 구성할 때 중요하며, 튜닝 옵션은 공장에서 구성하거나 Dell EMC 시스템 관리 유틸리티를 사용하여 설정할 수 있는 BIOS HPC 워크로드 프로파일에서 사용할 수 있습니다.
HPC 및 AI Innovation Lab에는 새로운 64서버 Rome 기반 PowerEdge 클러스터 Minerva가 있습니다. 이 공간에서 새로운 Minerva 클러스터에 대한 애플리케이션 성능 연구를 설명하는 후속 블로그를 확인해 보십시오.
해당 제품
Mellanox Family of Adapters, PowerEdge C6525, PowerEdge C6615, PowerEdge R6515, PowerEdge R6525, PowerEdge R6615, PowerEdge R6625, PowerEdge R6715, PowerEdge R6725, PowerEdge R7515, PowerEdge R7525, PowerEdge R7615, PowerEdge R7625, PowerEdge R7715
, PowerEdge R7725, PowerEdge R7725xd
...
문서 속성
문서 번호: 000137696
문서 유형: How To
마지막 수정 시간: 16 10월 2025
버전: 11
다른 Dell 사용자에게 질문에 대한 답변 찾기
지원 서비스
디바이스에 지원 서비스가 적용되는지 확인하십시오.