VxBlock: Postup restartování propojení topologie Fabric USS
Shrnutí: Tento článek znalostní databáze vysvětluje vzorový postup restartování dvojice propojení UCS Fabric-Interconnect.
Tento článek se vztahuje na
Tento článek se nevztahuje na
Tento článek není vázán na žádný konkrétní produkt.
V tomto článku nejsou uvedeny všechny verze produktu.
Pokyny
Cíle
Tento článek znalostní databáze vysvětluje vzorový postup restartování dvojice propojení UCS Fabric-Interconnect.Fakty
Všechny verze UCSMŘešení
1. Zkontrolujte, zda se nevyskytují nějaké aktivní chyby.Pokud se vyskytnou nějaké aktivní chyby, měli byste je před pokračováním odstranit.
Pokud potřebujete pomoc s odstraněním závady nebo musíte zkontrolovat, zda chyba může ovlivnit restart
FI 2. IP adresa
přes SSH na UCSM3. V § 3 Zkontrolujte stav clusteru.
Všimněte si primárních a podřízených finančních nástrojů.
Ověřte, že jsou aktivní služby správy.
Potvrďte, že je HA READY.
# zobrazí rozšířený stav clusteru.
Cluster Id: 0xa0acfe0f61511e7-0xaa158c604fde2e01
Odpověď: UP, PRIMÁRNÍ
B: UP, PODŘÍZENÝ
A: stav memb UP, stav zájemce PRIMÁRNÍ, stav služeb pro správu: UP
B: stav memb UP, stav zájemce SUBORDINATE, stav služeb pro správu: Stav prezenčního signálu UP
PRIMARY_OK
INTERNÍ SÍŤOVÁ ROZHRANÍ:
eth1, UP
eth2, UP
HAREADY
4. Ověřte datovou cestu pro technologii Fibre Channel (režim koncového hostitele) pro obě FI.
# connect nxos {a | b}
# show npv flogi-table
# exit
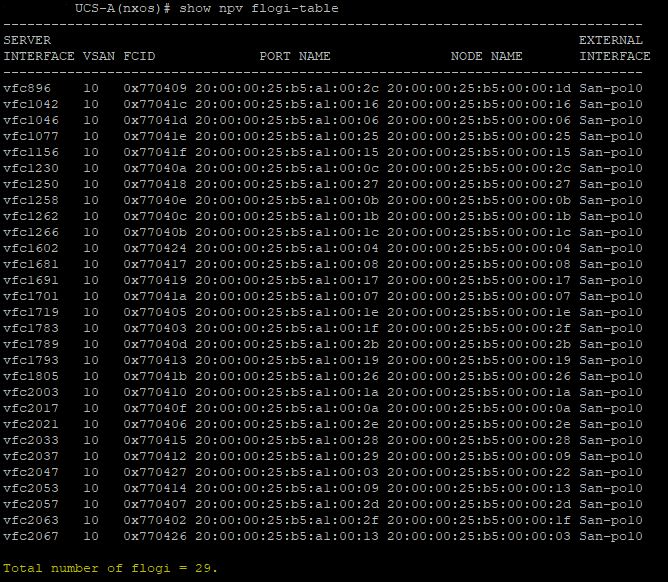
Zaznamenejte si celkový počet flogů pro oba FI. Čísla by se měla shodovat.
5. V § 5 Ověřte datové cesty sítě Ethernet pro obě FI.
# connect nxos {a | b}
# show int br | grep -v down | wc -l
# exit
Tento příkaz vrátí počet aktivních ethernetových rozhraní. Zaznamenejte si toto číslo pro každý FI. Nemusí se shodovat.
6. V § 6 Restartujte podřízený FI.
Připojte se k lokální správě podřízené FI a restartujte ji
# connect local-mgmt {a | b}
# reboot
Před restartováním vytvořte zálohu konfigurace.
Chcete přesto restartovat? (ano/ne): ano
7. Sledujte podřízenou FI.
Restartování obvykle trvá 10 až 20 minut. Sledujte spuštěním:
# show cluster extended-state
Níže je uveden stav clusteru, zatímco FI-B se stále restartuje.
A: UP, PRIMÁRNÍ
B: DOWN, NEPOUŽITELNÉ
A: stav memb NAHORU, stav zájemce PRIMÁRNÍ, stav služeb pro správu: UP
B: stav memb DOWN, stav zájemce NEAPPLICABLE , stav služeb mgmt: Stav prezenčního signálu DOWN
SECONDARY_FAILED
INTERNÍ SÍŤOVÁ ROZHRANÍ:
eth1, UP
eth2, UP
HA NOT READY
Propojení peer Fabric je mimo provoz.
Po dokončení restartování se zobrazí obě FI a zobrazí se možnost HA READY jako v kroku 3.
Až se znovu zobrazí funkce HA, příkaz READY se přesune ke kroku 8.
8. V § 8 Ověřte datové cesty FC a Ethernet pro podřízenou FI.
Opakujte kroky 4 a 5 pro podřízený FI, abyste ověřili, že se datové cesty FC a Ethernet zálohují a hlásí stejný počet flogis a ethernetových rozhraní jako dříve.
9. V § 9 Převzetí při selhání FI
Prohoďte stav FI a nastavte podřízeného, který byl restartován, jako nového primárního.
Primary-FI # connect local-mgmt
Primary-FI # cluster lead {a | b}
10 Znovu se připojte k uživatelskému rozhraní a rozhraní příkazového řádku.
Služby správy se restartují na novém primárním FI a aktuální relace uživatelského rozhraní a rozhraní příkazového řádku se odpojí.
Dokončení převzetí služeb při selhání trvá několik minut.
11 Opakujte kroky 6-8 pro nového podřízeného FI.
Restartujte podřízeného a sledujte nadcházející cluster a opětovné vytvoření datových cest.
Další informace
| Systém VCE | Vblock Series 500, Vblock Series 300, Vblock Series 1000, Vblock Series 700, VxBlock |
| Komponentní | UCS |
Dotčené produkty
VxBlock and Vblock SystemsVlastnosti článku
Číslo článku: 000205766
Typ článku: How To
Poslední úprava: 19 lis 2025
Verze: 3
Najděte odpovědi na své otázky od ostatních uživatelů společnosti Dell
Služby podpory
Zkontrolujte, zda se na vaše zařízení vztahují služby podpory.