Rozwiązanie Dell EMC Ready dla pamięci masowej HPC PixStor — warstwa NVMe
Summary: Blog dotyczący elementu rozwiązania HPC w zakresie pamięci masowej, w tym architektury i oceny wydajności.
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Symptoms
Autor: Mario Gallegos z HPC and AI Innovation Lab w czerwcu 2020 r.
Blog dotyczący elementu rozwiązania HPC w zakresie pamięci masowej, w tym architektury i oceny wydajności.
Blog dotyczący elementu rozwiązania HPC w zakresie pamięci masowej, w tym architektury i oceny wydajności.
Resolution
Rozwiązanie Dell EMC Ready dla pamięci masowej HPC PixStor
Warstwa NVMe
Spis treści
Wydajność sekwencyjna IOzone N klientów do N plików
Wydajność sekwencyjna IOR N klientów do 1 pliku
Losowe małe bloki — wydajność IOzone N klientów do N plików
Wydajność metadanych w teście MDtest przy użyciu plików 4 kB
Wprowadzenie
Dzisiejsze środowiska HPC wymagają coraz większej szybkości pamięci masowej, a ze względu na większą liczbę procesorów, szybsze sieci i większą ilość pamięci pamięć masowa stawała się wąskim gardłem w wielu obciążeniach roboczych. Te wysokie wymagania HPC są zwykle zaspokajane przez równoległe systemy plików (PFS), które zapewniają jednoczesny dostęp do pojedynczego pliku lub zestawu plików z wielu węzłów, bardzo wydajnie i bezpiecznie dystrybuując dane do wielu jednostek LUN na kilku serwerach. Te systemy plików są zwykle oparte na obracających się nośnikach, aby zapewnić największą pojemność przy najniższych kosztach. Jednak coraz częściej szybkość i opóźnienia obracających się nośników nie nadążają za wymaganiami wielu nowoczesnych obciążeń HPC, wymagających zastosowania technologii flash w postaci buforów burst, szybszych warstw, a nawet bardzo szybkiej przestrzeni roboczej, lokalnej lub rozproszonej. Rozwiązanie DellEMC Ready Solution dla pamięci masowej HPC PixStor wykorzystuje węzły NVMe jako elementy, które pozwalają sprostać nowym wymaganiom dotyczącym wysokiej przepustowości oraz zapewniają elastyczność, skalowalność, wydajność i niezawodność.
Architektura rozwiązania
Ten wpis na blogu należy do serii rozwiązań równoległego systemu plików (PFS) dla środowisk HPC, w szczególności dla rozwiązania DellEMC Ready Solution dla pamięci masowej HPC PixStor, w którym serwery DellEMC PowerEdge R640 z napędami NVMe są używane jako warstwa oparta na szybkiej pamięci flash.
Rozwiązanie PFS PixStor obejmuje szeroko rozpowszechniony system plików równoległych, znany również jako Skala spektrum. ArcaStream zawiera również wiele innych komponentów oprogramowania, które zapewniają zaawansowaną analitykę, uproszczoną administrację i monitorowanie, wydajne wyszukiwanie plików, zaawansowane możliwości bramki i nie tylko
Węzły NVMe przedstawione w tym wpisie na blogu zapewniają bardzo wydajną warstwę opartą na technologii flash dla rozwiązania PixStor. Wydajność i pojemność dla tej warstwy NVMe można skalować za pomocą dodatkowych węzłów NVMe. Pojemność zwiększa się poprzez wybór odpowiednich urządzeń NVMe obsługiwanych przez serwer PowerEdge R640.
Rysunek 1 przedstawia architekturę referencyjną rozwiązania z 4 węzłami NVMe korzystającymi z modułu metadanych o wysokim zapotrzebowaniu, który obsługuje wszystkie metadane w testowanej konfiguracji. Powodem jest fakt, że obecnie te węzły NVMe były używane jako cele pamięci masowej tylko dla danych. Jednak węzły NVMe mogą być również używane do przechowywania danych i metadanych, a nawet jako szybsza alternatywa flash dla modułu metadanych o wysokim zapotrzebowaniu, jeśli wymaga tego ekstremalne zapotrzebowanie na metadane. Te konfiguracje węzłów NVMe nie zostały przetestowane w ramach tych prac, ale zostaną przetestowane w przyszłości.
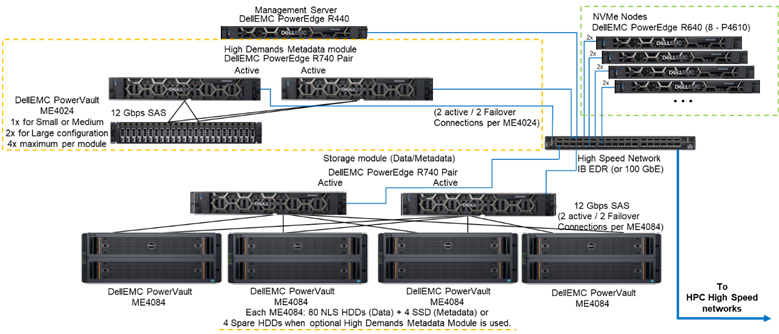
Rysunek 1. Architektura referencyjna
Elementy rozwiązania
To rozwiązanie wykorzystuje najnowsze skalowalne procesory Intel Xeon drugiej generacji, znane również jako procesory Cascade Lake, i najszybszą dostępną pamięć RAM (2933 MT/s), z wyjątkiem węzłów zarządzania, aby zapewnić opłacalność. Ponadto rozwiązanie zostało zaktualizowane do najnowszej wersji oprogramowania PixStor (5.1.3.1), która obsługuje systemy RHEL 7.7 i OFED 5.0, które będą obsługiwanymi wersjami oprogramowania w momencie wydania.
Każdy węzeł NVMe składa się z ośmiu urządzeń Dell P4610, które są skonfigurowane jako osiem urządzeń RAID 10 na parze serwerów, przy użyciu rozwiązania NVMe over Fabric, które zapewnia nadmiarowość danych nie tylko na poziomie urządzeń, ale i na poziomie serwera. Ponadto gdy jakiekolwiek dane trafiają lub wychodzą z jednego z urządzeń RAID10, używane są wszystkie 16 dysków na obu serwerach, co zwiększa przepustowość dostępu do wszystkich dysków. Dlatego jedynym ograniczeniem dla tych komponentów jest okoliczność, że muszą być sprzedawane i używane parami. W tym rozwiązaniu można używać wszystkich dysków NVMe obsługiwanych przez serwer PowerEdge R640, jednak P4610 charakteryzuje się przepustowością sekwencyjną 3200 MB/s zarówno dla odczytu, jak i zapisu, a także wysoką specyfikacją losowych operacji we/wy, co jest przydatną cechą przy próbie skalowania oszacowania liczby par potrzebnych do spełnienia wymagań tej warstwy flash.
Każdy serwer R640 ma dwa jednoportowe HCA Mellanox ConnectX-6 VPI HDR100, które są używane jako połączenia EDR 100 Gb IB. Węzły NVMe są jednak gotowe do obsługi prędkości HDR100, gdy są używane z kablami i przełącznikami HDR. Testowanie HDR100 na tych węzłach jest odroczone w ramach aktualizacji HDR100 dla całego rozwiązania PixStor. Oba interfejsy CX6 są używane do synchronizacji danych dla macierzy RAID 10 (NVMe over fabric) oraz jako łączność dla systemu plików. Ponadto zapewniają redundancję sprzętową na adapterze, porcie i kablu. Aby zapewnić nadmiarowość na poziomie przełącznika, wymagane są dwuportowe adaptery CX6 VPI, ale należy je zamówić jako komponenty oprogramowania i urządzeń peryferyjnych.
Aby scharakteryzować wydajność węzłów NVMe, z systemu przedstawionego na rysunku 1 użyto tylko modułu metadanych o wysokim zapotrzebowaniu i węzłów NVMe.
Tabela 1 zawiera listę głównych elementów rozwiązania. Z listy dysków obsługiwanych przez ME4024 dyski SSD o pojemności 960 GB były używane do metadanych i do charakteryzowania wydajności, a szybsze dyski mogą zapewnić lepsze losowe operacje we/wy i usprawnić operacje tworzenia/usuwania metadanych. Wszystkie urządzenia NVMe obsługiwane przez serwer PowerEdge R640 będą obsługiwane przez węzły NVMe.
Tabela 1. Komponenty używane w momencie premiery i te używane w środowisku testowym
|
W momencie wydania |
||
|
Połączenia wewnętrzne |
Dell Networking S3048-ON Gigabit Ethernet |
|
|
Podsystem w zakresie pamięci masowej |
1x do 4x Dell EMC PowerVault ME4084 1x do 4x Dell EMC PowerVault ME484 (jeden na ME4084) |
|
|
Opcjonalny podsystem przechowywania metadanych o wysokim zapotrzebowaniu |
1x do 2x Dell EMC PowerVault ME4024 (4x ME4024 w razie potrzeby, tylko duża konfiguracja) |
|
|
Kontrolery pamięci masowej RAID |
12 Gb/s SAS |
|
|
Procesor |
Węzły NVMe |
2x Intel Xeon Gold 6230 2.1G, 20C/40T |
|
Metadane o wysokim zapotrzebowaniu |
||
|
Węzeł pamięci masowej |
||
|
Węzeł zarządzania |
2x Intel Xeon Gold 5220 2.2G, 18C/36T |
|
|
Pamięć |
Węzły NVMe |
12 modułów 16 GB 2933 MT/s RDIMM (192 GB) |
|
Metadane o wysokim zapotrzebowaniu |
||
|
Węzeł pamięci masowej |
||
|
Węzeł zarządzania |
12 modułów 16 GB DIMM, 2666 MT/s (192 GB) |
|
|
System operacyjny |
CentOS 7.7 |
|
|
Wersja jądra |
3.10.0-1062.12.1.el7.x86_64 |
|
|
Oprogramowanie PixStor |
5.1.3.1 |
|
|
Oprogramowanie systemu plików |
Skala spektrum (GPFS) 5.0.4-3 z NVMesh 2.0.1 |
|
|
Wysokowydajna łączność sieciowa |
Węzły NVMe: 2 węzły ConnectX-6 InfiniBand korzystające z EDR/100 GbE |
|
|
Przełączniki o wysokiej wydajności |
2x Mellanox SB7800 |
|
|
Wersja OFED |
Mellanox OFED 5.0-2.1.8.0 |
|
|
Dyski lokalne (system operacyjny i analiza/monitorowanie) |
Wszystkie serwery z wyjątkiem wymienionych Węzły NVMe 3x 480 GB SSD SAS3 (RAID1 + HS) dla systemu operacyjnego 3x 480 GB SSD SAS3 (RAID1 + HS) dla systemu operacyjnego Kontroler macierzy RAID PERC H730P Kontroler macierzy RAID PERC H740P Węzeł zarządzania 3x 480 GB SSD SAS3 (RAID1 + HS) dla systemu operacyjnego z kontrolerem macierzy RAID PERC H740P |
|
|
Zarządzanie systemami |
iDRAC 9 Enterprise + DellEMC OpenManage |
|
Charakterystyka wydajności
Aby scharakteryzować ten nowy komponent Ready Solution, wykorzystano następujące testy porównawcze:
· IOzone N do N sekwencyjne
· IOR N do 1 sekwencyjne
· IOzone losowe
· MDtest
W przypadku wszystkich testów wymienionych powyżej stanowisko testowe posiadało klientów opisanych w Tabeli 2 poniżej. Ponieważ liczba węzłów obliczeniowych dostępnych do testów wynosiła tylko 16, gdy wymagana była większa liczba wątków, wątki te były równomiernie rozmieszczone na węzłach obliczeniowych (tj. 32 wątki = 2 wątki na węzeł, 64 wątki = 4 wątki na węzeł, 128 wątków = 8 wątków na węzeł, 256 wątków = 16 wątków na węzeł, 512 wątków = 32 wątki na węzeł, 1024 wątki = 64 wątki na węzeł). Celem było zasymulowanie większej liczby jednoczesnych klientów przy ograniczonej liczbie dostępnych węzłów obliczeniowych. Ponieważ niektóre testy porównawcze obsługują dużą liczbę wątków, zastosowano maksymalną wartość do 1024 (określoną dla każdego testu), jednocześnie unikając nadmiernego przełączania kontekstu i innych powiązanych efektów ubocznych wpływających na wyniki wydajności.
Tabela2. Stanowisko testowe klienta
|
Liczba węzłów klienta |
16 |
|
Węzeł klienta |
C6320 |
|
Procesory na węzeł klienta |
2x Intel(R) Xeon(R) Gold E5-2697v4 18 rdzeni przy 2,30 GHz |
|
Pamięć na węzeł klienta |
8 modułów 16 GB 2400 MT/s RDIMM (128 GB) |
|
BIOS |
2.8.0 |
|
Jądro OS |
3.10.0-957.10.1 |
|
Oprogramowanie systemu plików |
Skala spektrum (GPFS) 5.0.4-3 z NVMesh 2.0.1 |
Wydajność sekwencyjna IOzone N klientów do N plików
Wydajność sekwencyjnego połączenia N klientów z N plikami została zmierzona przy użyciu IOzone w wersji 3.487. Wykonane testy obejmowały od pojedynczego wątku do 1024 wątków zwiększanych w potęgach dwójki.
Efekty buforowania na serwerach zostały zminimalizowane poprzez ustawienie puli stron GPFS na 16 GB i używanie plików większych niż dwukrotność tego rozmiaru. Ważne jest, aby zauważyć, że w przypadku GPFS ten edytowalny parametr ustawia maksymalną ilość pamięci używanej do buforowania danych, niezależnie od ilości zainstalowanej i wolnej pamięci RAM. Należy również zauważyć, że podczas gdy w poprzednich rozwiązaniach DellEMC HPC rozmiar bloku dla dużych transferów sekwencyjnych wynosi 1 MB, GPFS został sformatowany z blokami 8 MB i dlatego ta wartość jest używana w teście porównawczym w celu uzyskania optymalnej wydajności. Może to wyglądać na zbyt duże i pozornie marnować zbyt dużo miejsca, ale GPFS używa alokacji podbloku, aby zapobiec takiej sytuacji. W obecnej konfiguracji każdy blok został podzielony na 256 podbloków po 32 KB każdy.
Poniższe polecenia zostały użyte do wykonania testu porównawczego dla zapisów i odczytów, gdzie $Threads było zmienną z liczbą używanych wątków (od 1 do 1024 zwiększanych w potęgach dwójki), a threadlist było plikiem, który przydzielał każdy wątek do innego węzła, używając round robin, aby rozłożyć je równomiernie na 16 węzłów obliczeniowych.
Aby uniknąć możliwych efektów buforowania danych z klientów, łączny rozmiar danych plików był dwukrotnie większy niż łączna ilość pamięci RAM używanych klientów. Oznacza to, że ponieważ każdy klient ma 128 GB pamięci RAM, dla liczby wątków równej lub większej niż 16 wątków rozmiar pliku wynosił 4096 GB podzielonych przez liczbę wątków (zmienna $Size poniżej została użyta do zarządzania tą wartością). W przypadku mniej niż 16 wątków (co oznacza, że każdy wątek był uruchomiony na innym kliencie) rozmiar pliku został ustalony na dwukrotnie większą ilość pamięci na klienta, czyli 256 GB.
iozone -i0 -c -e -w -r 8M -s $ G -t $Threads -+n -+m ./threadlist
iozone -i1 -c -e -w -r 8M -s $ G -t $Threads -+n -+m ./threadlist
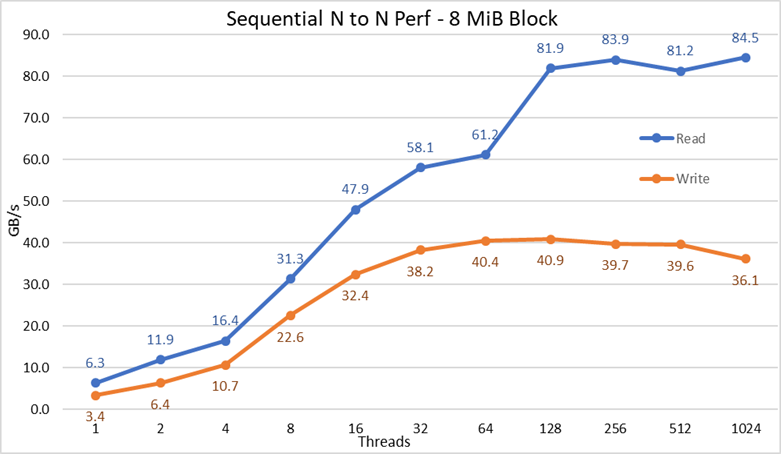
Rysunek 2. Wydajność sekwencyjna N do N
Na podstawie wyników możemy zaobserwować, że wydajność zapisu wzrasta wraz z liczbą używanych wątków, a następnie osiąga punkt wypłaszczenia na poziomie około 64 wątków dla zapisu i 128 wątków dla odczytów. Wydajność odczytu również szybko rośnie wraz z liczbą wątków, a następnie pozostaje stabilna do momentu osiągnięcia maksymalnej liczby wątków dozwolonej przez IOzone, a zatem wydajność sekwencyjna dużych plików jest stabilna nawet dla 1024 jednoczesnych klientów. Wydajność zapisu spada o około 10% przy 1024 wątkach. Ponieważ jednak klaster kliencki ma mniej rdzeni, nie ma pewności, czy spadek wydajności jest spowodowany wymianą i podobnym obciążeniem, którego nie obserwuje się w przypadku obracających się nośników (ponieważ opóźnienie NVMe jest bardzo niskie w porównaniu z obracającymi się nośnikami), czy też synchronizacja danych RAID 10 staje się wąskim gardłem. Potrzeba więcej klientów, aby wyjaśnić tę kwestię. Anomalię odczytów zaobserwowano w 64 wątkach, gdzie wydajność nie skalowała się z szybkością obserwowaną dla poprzednich punktów danych, a następnie w kolejnym punkcie danych przesuwała się do wartości bardzo zbliżonej do trwałej wydajności. Potrzebne są dalsze testy, aby znaleźć przyczynę takiej anomalii, ale wykracza to poza zakres tego wpisu.
Maksymalna wydajność odczytu dla odczytów była niższa od teoretycznej wydajności urządzeń NVMe (~102 GB/s) lub wydajności łączy EDR, nawet przy założeniu, że jedno łącze było najczęściej używane dla ruchu NVMe over fabric (4x EDR BW ~96 GB/s).
Nie jest to jednak niespodzianką, ponieważ konfiguracja sprzętowa nie jest zrównoważona w odniesieniu do urządzeń NVMe i IB HCA pod każdym gniazdem procesora. Jeden adapter CX6 znajduje się pod procesorem CPU1, podczas gdy procesor CPU2 ma wszystkie urządzenia NVMe i drugi adapter CX6. Wszelki ruch związany z pamięcią masową korzystający z pierwszego HCA musi korzystać z UPI, aby uzyskać dostęp do urządzeń NVMe. Ponadto każdy używany rdzeń procesora CPU1 musi mieć dostęp do urządzeń lub pamięci przypisanej do procesora 2, więc cierpi na tym lokalność danych i używane są łącza UPI. To może wyjaśniać redukcję maksymalnej wydajności w porównaniu z maksymalną wydajnością urządzeń NVMe lub prędkością łącza dla CX6 HCA. Alternatywą dla rozwiązania tego problemu jest zrównoważona konfiguracja sprzętowa, która oznacza zmniejszenie gęstości o połowę poprzez zastosowanie R740 z czterema gniazdami x16 i użyciem dwóch ekspanderów PCIe x16 w celu równomiernego rozmieszczenia urządzeń NVMe na dwóch procesorach oraz posiadanie jednego CX6 HCA pod każdym procesorem.
Wydajność sekwencyjna IOR N klientów do 1 pliku
Wydajność sekwencyjnego połączenia N klientów do pojedynczego współdzielonego pliku została zmierzona za pomocą IOR w wersji 3.3.0, wspomaganego przez OpenMPI v4.0.1 w celu uruchomienia benchmarku na 16 węzłach obliczeniowych. Wykonywane testy wahały się od jednego wątku do 512 wątków, ponieważ nie było wystarczającej liczby rdzeni dla 1024 lub więcej wątków. W tym teście porównawczym wykorzystano bloki 8 MB w celu uzyskania optymalnej wydajności. Poprzednia sekcja testu wydajności zawiera pełniejsze wyjaśnienie, dlaczego ma to znaczenie.
Efekty buforowania danych zostały zminimalizowane przez ustawienie puli stron GPFS na 16 GB, a całkowity rozmiar pliku był dwukrotnie większy niż całkowita ilość pamięci RAM w używanych klientach. Oznacza to, że ponieważ każdy klient ma 128 GB pamięci RAM, w przypadku liczby wątków równej lub większej niż 16 wątków rozmiar pliku wynosił 4096 GB, a taka sama część tej sumy została podzielona przez liczbę wątków (zmienna $Size poniżej została użyta do zarządzania tą wartością). W przypadkach z mniej niż 16 wątkami (co oznacza, że każdy wątek był uruchomiony na innym kliencie), rozmiar pliku był dwukrotnie większy niż ilość użytej pamięci na klienta razy liczba wątków, czyli innymi słowy, każdy wątek został poproszony o użycie 256 GB.
Poniższe polecenia zostały użyte do wykonania testu porównawczego dla zapisów i odczytów, gdzie $Threads było zmienną z liczbą używanych wątków (od 1 do 1024 zwiększanych w potęgach dwójki), a my_hosts.$Threads to odpowiedni plik, który przydzielał każdy wątek do innego węzła, używając round robin, aby rozłożyć je równomiernie na 16 węzłów obliczeniowych.
mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads --mca btl_openib_allow_ib 1 --mca pml ^ucx --oversubscribe --prefix /mmfs1/perftest/ompi /mmfs1/perftest/lanl_ior/bin/ior -a POSIX -v -i 1 -d 3 -e -k -o /mmfs1/perftest/tst.file -w -s 1 -t 8m -b $ G
mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads --mca btl_openib_allow_ib 1 --mca pml ^ucx --oversubscribe --prefix /mmfs1/perftest/ompi /mmfs1/perftest/lanl_ior/bin/ior -a POSIX -v -i 1 -d 3 -e -k -o /mmfs1/perftest/tst.file -r -s 1 -t 8m -b $ G
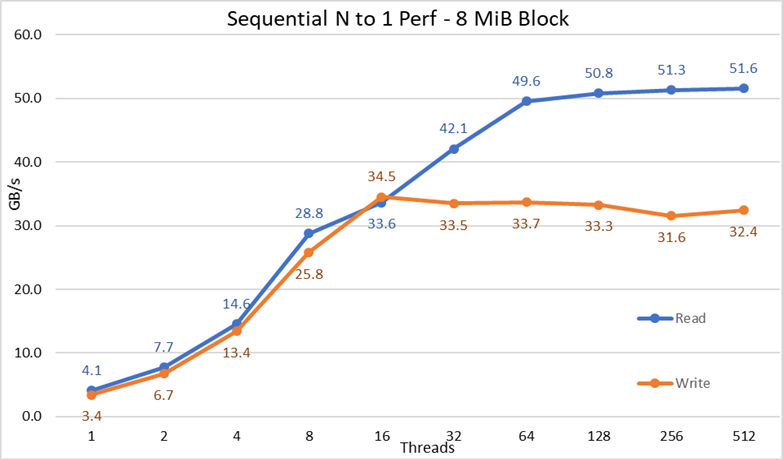
Rysunek 3. Wydajność sekwencyjna N do 1
Na podstawie wyników możemy zaobserwować, że wydajność odczytu i zapisu jest wysoka, niezależnie od ukrytej potrzeby mechanizmów blokujących, ponieważ wszystkie wątki mają dostęp do tego samego pliku. Wydajność ponownie rośnie bardzo szybko wraz z liczbą używanych wątków, a następnie osiąga punkt wypłaszczenia, który jest stosunkowo stabilny dla odczytów i zapisów aż do maksymalnej liczby wątków używanych w tym teście. Zwróć uwagę, że maksymalna wydajność odczytu wyniosła 51,6 GB/s przy 512 wątkach, ale punkt wypłaszczenia wydajności jest osiągany przy około 64 wątkach. Należy również zauważyć, że maksymalna wydajność zapisu 34,5 GB/s została osiągnięta przy 16 wątkach i osiągnęła punkt wypłaszczenia, który można zaobserwować aż do maksymalnej liczby używanych wątków.
Losowe małe bloki — wydajność IOzone N klientów do N plików
Wydajność losowego połączenia N klientów z N plikami została zmierzona przy użyciu IOzone w wersji 3.487. Wykonane testy obejmowały od pojedynczego wątku do 1024 wątków zwiększanych w potęgach dwójki.
Wykonywane testy wahały się od jednego wątku do 512 wątków, ponieważ nie było wystarczającej liczby rdzeni klienckich dla 1024 wątków. Każdy wątek korzystał z innego pliku, a wątki były przydzielane w systemie round robin na węzłach klienckich. W tym teście porównawczym wykorzystano bloki 4 kB do emulacji ruchu małych bloków i przy użyciu głębokości kolejki 16. Porównywane są wyniki zastosowania rozwiązania o dużych rozmiarach i zwiększenia pojemności.
Efekty buforowania zostały ponownie zminimalizowane poprzez ustawienie puli stron GPFS na 16 GB i aby uniknąć możliwych efektów buforowania danych z klientów, całkowity rozmiar danych plików był dwukrotnie większy niż całkowita ilość pamięci RAM w używanych klientach. Oznacza to, że ponieważ każdy klient ma 128 GB pamięci RAM, dla liczby wątków równej lub większej niż 16 wątków rozmiar pliku wynosił 4096 GB podzielonych przez liczbę wątków (zmienna $Size poniżej została użyta do zarządzania tą wartością). W przypadku mniej niż 16 wątków (co oznacza, że każdy wątek był uruchomiony na innym kliencie) rozmiar pliku został ustalony na dwukrotnie większą ilość pamięci na klienta, czyli 256 GB.
iozone -i0 -I -c -e -w -r 8M -s $ G -t $Threads -+n -+m ./nvme_threadlist <= Utwórz pliki sekwencyjnie
iozone -i2 -I -c -O -w -r 4k -s $ G -t $Threads -+n -+m ./nvme_threadlist <= Wykonaj losowe odczyty i zapisy.
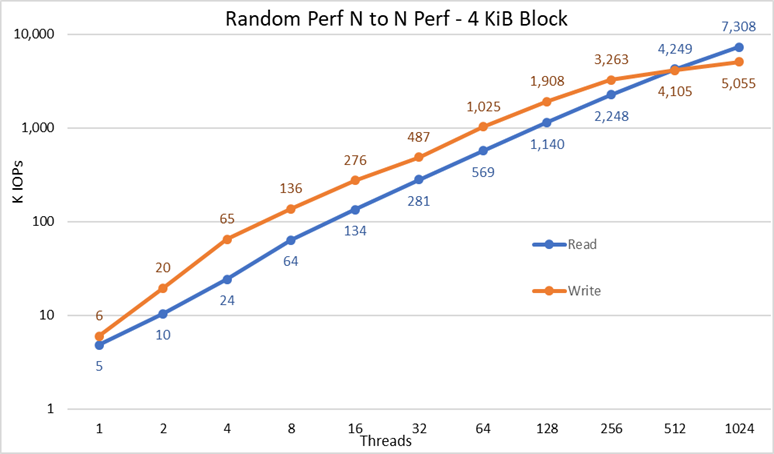
Rysunek 4. Wydajność losowa N do N
Na podstawie wyników możemy zaobserwować, że wydajność zapisu zaczyna się od wysokiej wartości 6 tys. operacji we/wy i stale rośnie do 1024 wątków, gdzie wydaje się, że osiąga punkt wypłaszczenia z ponad 5 mln operacji we/wy, jeśli można użyć więcej wątków. Z drugiej strony wydajność odczytu zaczyna się od 5 tys. operacji we/wy i wzrasta równomiernie wraz z liczbą używanych wątków (należy pamiętać, że liczba wątków jest podwajana dla każdego punktu danych) i osiąga maksymalną wydajność 7,3 mln operacji we/wy przy 1024 wątkach bez oznak osiągnięcia punktu wypłaszczenia. Korzystanie z większej liczby wątków będzie wymagało więcej niż 16 węzłów obliczeniowych, aby uniknąć głodu zasobów i nadmiernego zamieniania, które może obniżyć pozorną wydajność, podczas gdy węzły NVMe mogłyby w rzeczywistości utrzymać wydajność.
Wydajność metadanych w teście MDtest przy użyciu plików 4 kB
Wydajność metadanych została zmierzona za pomocą MDtest w wersji 3.3.0, wspomaganego przez OpenMPI v4.0.1 w celu uruchomienia benchmarku na 16 węzłach obliczeniowych. Wykonane testy obejmowały od pojedynczego wątku do 512 wątków. Test porównawczy został użyty tylko dla plików (bez metadanych katalogów), co pozwoliło uzyskać liczbę utworzeń, statystyk, odczytów i usunięć, które rozwiązanie może obsłużyć, a wyniki zostały porównane z rozwiązaniem o dużym rozmiarze.
Zastosowano opcjonalny moduł metadanych o wysokim zapotrzebowaniu, jednak w konfiguracji z jedną macierzą ME4024, choć duża konfiguracja testowana w tej pracy przewidywała dwie macierze ME4024. Powodem korzystania z tego modułu metadanych jest fakt, że obecnie te węzły NVMe są używane jako obiekty docelowe pamięci masowej tylko dla danych. Jednak węzły mogą być używane do przechowywania danych i metadanych, a nawet jako alternatywa flash dla modułu metadanych o wysokim zapotrzebowaniu, jeśli wymagają tego ekstremalne wymagania dotyczące metadanych. Konfiguracje te nie zostały przetestowane w ramach tych prac.
Ponieważ ten sam moduł metadanych o wysokim zapotrzebowaniu był używany do poprzednich testów porównawczych rozwiązania DellEMC Ready Solution dla rozwiązania pamięci masowej HPC PixStor, wyniki metadanych będą bardzo podobne w porównaniu z wynikami z poprzedniego wpisu. Z tego powodu nie przeprowadzono badania z pustymi plikami, a zamiast tego użyto plików 4 KB. Ponieważ pliki 4 KB nie mieszczą się w i-węźle wraz z informacjami o metadanych, węzły NVMe będą używane do przechowywania danych dla każdego pliku. W związku z tym MDtest może dać przybliżone wyobrażenie o wydajności małych plików dla odczytów i pozostałych operacji na metadanych.
Poniższe polecenie zostało użyte do wykonania testu porównawczego, gdzie $Threads było zmienną z liczbą używanych wątków (od 1 do 512 zwiększanych w potęgach dwójki), a my_hosts.$Threads to odpowiedni plik, który przydzielał każdy wątek do innego węzła, używając round robin, aby rozłożyć je równomiernie na 16 węzłów obliczeniowych. Podobnie jak w teście porównawczym losowych operacji IO, maksymalna liczba wątków została ograniczona do 512, ponieważ nie ma wystarczającej liczby rdzeni dla 1024 wątków, a przełączanie kontekstu wpłynęłoby na wyniki, zgłaszając liczbę niższą niż rzeczywista wydajność rozwiązania.
mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads --prefix /mmfs1/perftest/ompi --mca btl_openib_allow_ib 1 /mmfs1/perftest/lanl_ior/bin/mdtest -v -d /mmfs1/perftest/ -i 1 -b $Directories -z 1 -L -I 1024 -y -u -t -F -w 4K -e 4K
Ponieważ na wyniki wydajności może mieć wpływ całkowita liczba operacji we/wy, liczba plików na katalog i liczba wątków, zdecydowano się utrzymać całkowitą liczbę plików na stałym poziomie 2 MB (2^21 = 2097152), liczbę plików na katalog na stałym poziomie 1024, a liczba katalogów zmieniała się wraz ze zmianą liczby wątków, jak pokazano w Tabeli 3.
Tabela 3. Mdtest — rozkład plików w katalogach
|
Liczba wątków |
Liczba katalogów na wątek |
Łączna liczba plików |
|
1 |
2048 |
2 097 152 |
|
2 |
1024 |
2 097 152 |
|
4 |
512 |
2 097 152 |
|
8 |
256 |
2 097 152 |
|
16 |
128 |
2 097 152 |
|
32 |
64 |
2 097 152 |
|
64 |
32 |
2 097 152 |
|
128 |
16 |
2 097 152 |
|
256 |
8 |
2 097 152 |
|
512 |
4 |
2 097 152 |
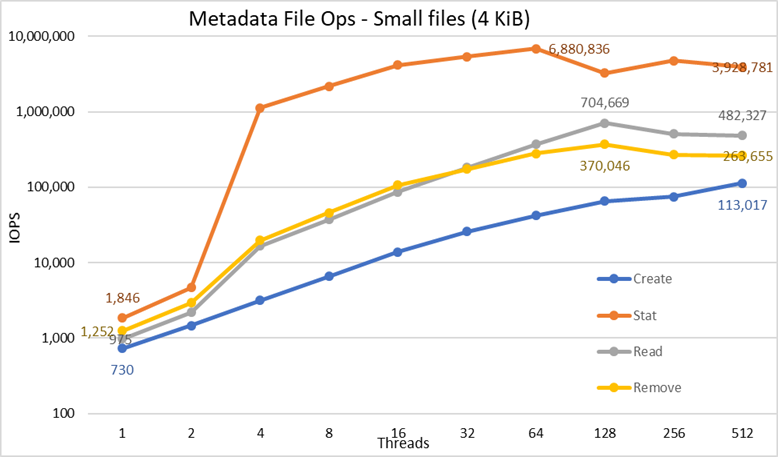
Rysunek 5. Wydajność metadanych — pliki 4 KB
Po pierwsze należy zauważyć, że wybrana skala była skalą logarytmiczną o podstawie 10, ponieważ umożliwiała porównywanie operacji, które różnią się o kilka rzędów wielkości; w przeciwnym razie niektóre operacje wyglądałyby jak płaska linia bliska 0 na skali liniowej. Wykres logarytmiczny o podstawie 2 mógłby być bardziej odpowiedni, ponieważ liczba wątków jest zwiększana w potęgach 2, ale wykres wyglądałby bardzo podobnie, a ludzie lepiej liczą i zapamiętują liczby oparte na potęgach 10.
System uzyskuje bardzo dobre wyniki, jak wcześniej informowano, przy czym operacje Stat osiągają szczytową wartość przy 64 wątkach przy prawie 6,9 mln operacji na sekundę, a następnie są zmniejszane w przypadku większej liczby wątków, osiągając punkt wypłaszczenia. Operacje Create osiągają maksymalną liczbę operacji na poziomie 113 tys./s przy 512 wątkach, dlatego oczekuje się, że będą nadal rosnąć, jeśli będzie używanych więcej węzłów klienckich (i rdzeni). Operacje Reads i Removes osiągnęły maksymalną liczbę 128 wątków, osiągając maksymalną wartość prawie 705 tys. operacji na sekundę dla Reads i 370 tys. operacji na sekundę dla Removes, a następnie osiągają punkt wypłaszczenia. Operacje Stat charakteryzują się większą zmiennością, ale po osiągnięciu wartości szczytowej wydajność nie spada poniżej 3,2 mln operacji na sekundę dla Stats. Operacje Create i Removal są bardziej stabilne, gdy osiągną punkt wypłaszczenia i utrzymują się powyżej 265 tys. operacji na sekundę dla Removal i 113 tys. operacji na sekundę dla Create. Wreszcie odczyty osiągają punkt wypłaszczenia z wydajnością powyżej 265 tys. operacji/s.
Wnioski i przyszłe prace
Węzły NVMe są ważnym dodatkiem do rozwiązania pamięci masowej HPC, ponieważ zapewniają bardzo wysoką wydajność z dobrą gęstością, bardzo wysoką wydajnością dostępu losowego i bardzo wysoką wydajnością sekwencyjną. Ponadto pojemność i wydajność rozwiązania skaluje się liniowo w miarę dodawania kolejnych modułów węzłów NVMe. Wydajność węzłów NVMe została przedstawiona w Tabeli 4. Powinna być stabilna, a wartości te można wykorzystać do oszacowania wydajności dla różnej liczby węzłów NVMe.
Należy jednak pamiętać, że każda para węzłów NVMe zapewni połowę dowolnej liczby przedstawionej w Tabeli 4.
Rozwiązanie to zapewnia klientom HPC bardzo niezawodny równoległy system plików wykorzystywany przez wiele klastrów HPC z listy Top 500. Ponadto zapewnia wyjątkowe możliwości wyszukiwania, zaawansowane monitorowanie i zarządzanie, a dodanie opcjonalnych bramek umożliwia udostępnianie plików za pośrednictwem wszechobecnych standardowych protokołów, takich jak NFS, SMB i innych, dowolnej liczbie klientów.
Tabela 4. Szczytowa i utrzymująca się wydajność dla 2 par węzłów NVMe
|
|
Szczytowa wydajność |
Utrzymująca się wydajność |
||
|
Zapis |
Odczyt |
Zapis |
Odczyt |
|
|
Duży sekwencyjny N klientów do N plików |
40,9 GB/s |
84,5 GB/s |
40 GB/s |
81 GB/s |
|
Duży sekwencyjny N klientów do jednego udostępnionego pliku |
34,5 GB/s |
51,6 GB/s |
31,5 GB/s |
50 GB/s |
|
Losowe małe bloki N klientów do N plików |
5.06MIOPS |
7.31MIOPS |
5 MIOPS |
7,3 MIOPS |
|
Metadane pliki 4 kB Create |
113 tys. IOPs |
113 tys. IOPs |
||
|
Metadane pliki 4 kB Stat |
6,88 mln IOPs |
3,2 mln IOPs |
||
|
Metadane pliki 4 kB Read |
705 tys. IOPs |
500 tys. IOPs |
||
|
Metadane pliki 4 kB Remove |
370 tys. IOPs |
265 tys. IOPs |
||
Ponieważ węzły NVMe były używane tylko do danych, ewentualne przyszłe prace mogą obejmować wykorzystanie ich do danych i metadanych oraz mieć niezależną warstwę opartą na pamięci flash z lepszą wydajnością metadanych ze względu na większą przepustowość i mniejsze opóźnienia urządzeń NVMe w porównaniu z dyskami SSD SAS3 znajdującymi się za kontrolerami RAID. Alternatywnie, jeśli klient ma bardzo wysokie wymagania dotyczące metadanych i potrzebuje rozwiązania bardziej zagęszczonego niż to, co może zapewnić moduł metadanych o wysokim zapotrzebowaniu, niektóre lub wszystkie urządzenia rozproszonej macierzy RAID 10 mogą być używane do metadanych w taki sam sposób, w jaki obecnie używane są urządzenia RAID 1 w ME4024.
Kolejny wpis na blogu, który zostanie opublikowany wkrótce, będzie zawierał opis węzłów PixStor Gateway, które umożliwiają podłączenie rozwiązania PixStor do innych sieci za pomocą protokołów NFS lub SMB i mogą skalować wydajność. Ponadto rozwiązanie wkrótce zostanie zaktualizowane do HDR100, a kolejny wpis na blogu poświęcony będzie tym pracom.
Affected Products
High Performance Computing Solution ResourcesArticle Properties
Article Number: 000130558
Article Type: Solution
Last Modified: 21 Feb 2021
Version: 3
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.