Řešení Dell EMC Ready pro úložiště HPC PixStor – Úroveň NVMe
Summary: Blog věnovaný komponentě HPC Storage Solution, včetně architektury spolu s hodnocením výkonu.
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Symptoms
Autor: Mario Gallegos z oddělení HPC and AI Innovation Lab, červen 2020
Blog věnovaný komponentě HPC Storage Solution, včetně architektury spolu s hodnocením výkonu.
Blog věnovaný komponentě HPC Storage Solution, včetně architektury spolu s hodnocením výkonu.
Resolution
Řešení Dell EMC Ready pro úložiště HPC PixStor
Vrstva NVMe
Obsah
Sekvenční výkon IOzone N klientů – N souborů
Sekvenční výkon IOR N klientů –1 soubor
Výkon náhodných malých bloků IOzone N klientů – N souborů
Výkon metadat s nástrojem MDtest pomocí 4KiB souborů
Úvod
Dnešní prostředí HPC kladou zvýšené nároky na velmi rychlé úložiště a s větším počtem procesorů, rychlejšími sítěmi a větší pamětí se úložiště stává kritickým bodem mnoha úloh. Tyto vysoké nároky prostředí HPC jsou obvykle kryty paralelními systémy souborů (PFS), které poskytují souběžný přístup k jednomu souboru nebo sadě souborů z více uzlů a velmi efektivně a bezpečně distribuují data do více jednotek LUN na několika serverech. Tyto systémy souborů jsou obvykle založené na rotujících discích, aby poskytovaly nejvyšší kapacitu při nejnižších nákladech. Rychlost a latence rotujících disků však stále častěji nedokážou držet krok s požadavky mnoha moderních úloh HPC a vyžadují použití technologie flash ve formě nárazových vyrovnávacích pamětí, rychlejších vrstev nebo dokonce velmi rychlých úložišť scratch, místních či distribuovaných. Řešení Dell EMC Ready Solution for HPC PixStor využívá uzly NVMe jako komponentu, která pokryje tyto nové požadavky na šířku pásma a je zároveň flexibilní, škálovatelná, efektivní a spolehlivá.
Architektura řešení
Tento blog je součástí seriálu věnovaného řešením PFS (Parallel File System) pro prostředí HPC, zejména řešení Dell EMC Ready Solution for HPC PixStor Storage, kde se servery Dell EMC PowerEdge R640 s disky NVMe používají jako rychlá vrstva založená na technologii flash.
Řešení PixStor PFS zahrnuje rozšířený systém General Parallel File System, známý také jako Spectrum Scale. ArcaStream také obsahuje mnoho dalších softwarových komponent, které poskytují pokročilou analytiku, zjednodušenou správu a monitorování, efektivní vyhledávání souborů, pokročilé možnosti brány a další.
Uzly NVMe prezentované v tomto blogu poskytují velmi výkonnou vrstvu založenou na paměti flash pro řešení PixStor. Výkon a kapacitu pro tuto vrstvu NVMe lze škálovat pomocí dalších uzlů NVMe. Vyšší kapacitu získáte výběrem vhodných zařízení NVMe podporovaných serverem PowerEdge R640.
Obrázek 1 znázorňuje referenční architekturu s řešením se 4 uzly NVMe s modulem metadat pro náročné operace, který zpracovává všechna metadata v testované konfiguraci. Důvodem je, že v současné době se tyto uzly NVMe používaly jako cíle úložiště pouze pro data. Uzly NVMe však lze také použít k ukládání dat a metadat, nebo dokonce jako rychlejší alternativu k modulu metadat pro náročné operace, pokud to vyžadují extrémní nároky na metadata. Tyto konfigurace pro uzly NVMe nebyly v rámci tohoto postupu testovány, ale budou testovány v budoucnu.
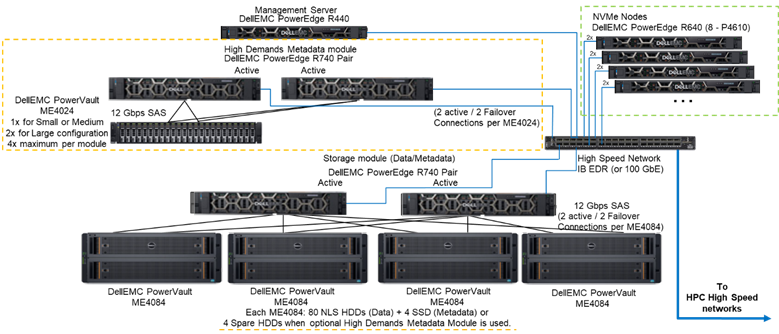
Obrázek 1 – Referenční architektura
Komponenty řešení
Toto řešení využívá nejnovější procesory Intel Xeon Scalable Xeon 2. generace neboli procesory Cascade Lake, a nejrychlejší dostupnou paměť RAM (2 933 MT/s), s výjimkou uzlů pro správu, aby byly nákladově efektivní. Kromě toho bylo řešení aktualizováno na nejnovější verzi PixStor (5.1.3.1), která podporuje verze RHEL 7.7 a OFED 5.0, což jsou podporované verze softwaru v době vydání.
Každý uzel NVMe má osm zařízení Dell P4610, která jsou nakonfigurována jako osm zařízení RAID 10 na dvojici serverů pomocí řešení NVMe over Fabric, což umožňuje redundanci dat nejen na úrovni zařízení, ale i na úrovni serverů. Kromě toho, když do jednoho z těchto zařízení RAID10 nebo z něj odchází jakákoli data, použije se všech 16 disků na obou serverech, čímž se zvýší šířka pásma přístupu ke všem diskům. Jediným omezením pro tyto komponenty je proto to, že se musí prodávat a používat v párech. V tomto řešení lze použít všechny disky NVMe podporované serverem PowerEdge R640, ale model P4610 má sekvenční šířku pásma 3 200 MB/s pro čtení i zápis a také vysoké náhodné specifikace IOPS, což jsou užitečné funkce při pokusu o odhad počtu párů potřebných ke splnění požadavků této vrstvy flash.
Každý server R640 má dvě zařízení HCA Mellanox ConnectX-6 Single Port VPI HDR100, které se používají jako připojení EDR 100 Gb IB. Uzly NVMe jsou však připraveny podporovat rychlosti HDR100 při použití s kabely a přepínači HDR. Testování HDR100 na těchto uzlech je odloženo jako součást aktualizace HDR100 pro celé řešení PixStor. Obě rozhraní CX6 se používají k synchronizaci dat pro pole RAID 10 (NVMe přes topologii Fabric) a jako připojení pro systém souborů. Kromě toho poskytují redundanci hardwaru v adaptéru, portu a kabelu. Pro redundanci na úrovni přepínačů jsou nutné dvouportové adaptéry CX6 VPI, ale je třeba je pořídit jako komponenty S&P.
K charakterizaci výkonu uzlů NVMe byl ze systému znázorněného na obrázku 1 použit pouze modul metadat pro náročné operace a uzly NVMe.
Tabulka 1 obsahuje seznam hlavních komponent řešení. Ze seznamu disků podporovaných ve skříni ME4024 byly 960GB disky SSD použity pro metadata a byly použity pro charakterizaci výkonu. Rychlejší disky mohou poskytovat lepší náhodné operace IOP a mohou zlepšit operace vytváření/odebírání metadat. Všechna zařízení NVMe podporovaná serverem PowerEdge R640 budou podporovaná pro uzly NVMe.
Tabulka 1: Komponenty použité v době vydání a komponenty použité v testbedu
|
V době vydání |
||
|
Interní konektivita |
Gigabitový ethernet Dell Networking S3048-ON |
|
|
Subsystém datového úložiště |
1x až 4x Dell EMC PowerVault ME4084 1x až 4x Dell EMC PowerVault ME484 (jeden na ME4084) |
|
|
Volitelný subsystém úložiště metadat pro vysoké nároky |
1x až 2x Dell EMC PowerVault ME4024 (v případě potřeby 4x ME4024, pouze velká konfigurace) |
|
|
Řadiče úložiště RAID |
12 Gb/s SAS |
|
|
Procesor |
Uzly NVMe |
2x Intel Xeon Gold 6230, 2,1 GHz, 20 jader / 40 vláken |
|
Metadata pro vysoké nároky |
||
|
Uzel úložiště |
||
|
Uzel pro správu |
2x Intel Xeon Gold 5220, 2,2 GHz, 18 jader / 36 vláken |
|
|
Paměť |
Uzly NVMe |
12x 16GiB modul RDIMM 2 933 MT/s (192 GiB) |
|
Metadata pro vysoké nároky |
||
|
Uzel úložiště |
||
|
Uzel pro správu |
12x 16GiB modul DIMM, 2 666 MT/s (192 GiB) |
|
|
Operační systém |
CentOS 7,7 |
|
|
Verze jádra |
3.10.0-1062.12.1.el7.x86_64 |
|
|
Software PixStor |
5.1.3.1 |
|
|
Software systému souborů |
Spectrum Scale (GPFS) 5.0.4-3 s verzí NVMesh 2.0.1 |
|
|
Vysoce výkonná síťová konektivita |
Uzly NVMe: 2x ConnectX-6 InfiniBand s využitím EDR/100 GbE |
|
|
Vysoce výkonný přepínač |
2x Mellanox SB7800 |
|
|
Verze systému OFED |
Mellanox OFED 5.0-2.1.8.0 |
|
|
Místní disky (OS a analýza/monitorování) |
Všechny servery kromě uvedených uzlů NVMe 3x 480GB disk SSD SAS3 (RAID1 + HS) pro operační systém3x 480GB disk SSD SAS3 (RAID1 + HS) pro operační systém Řadič PERC H730P RAID Řadič PERC H740P RAID Uzel pro správu 3x 480GB disk SSD SAS3 (RAID1 + HS) pro operační systém s řadičem RAID PERC H740P |
|
|
Správa systému |
iDRAC 9 Enterprise + Dell EMC OpenManage |
|
Charakteristika výkonu
K charakterizaci této nové komponenty Ready Solution byly použity následující srovnávací testy:
· Sekvenční test IOzone N–N
· Sekvenční test IOR N–1
· Náhodné IOzone
· MDtest
U všech výše uvedených srovnávacích testů měl testbed nastavené klienty jako v tabulce 2 níže. Jelikož pro testování bylo k dispozici pouze 16 výpočetních uzlů, při potřebě většího počtu vláken byla vlákna rovnoměrně distribuována na výpočetních uzlech (tj. 32 vláken = 2 vlákna na uzel, 64 vláken = 4 vlákna na uzel, 128 vláken = 8 vláken na uzel, 256 vláken = 16 vláken na uzel, 512 vláken = 32 vláken na uzel, 1 024 vláken = 64 vláken na uzel). Záměrem bylo simulovat větší počet souběžných klientů s omezeným počtem dostupných výpočetních uzlů. Vzhledem k tomu, že srovnávací testy podporují vysoký počet vláken, byla použita maximální hodnota 1 024 (pro každý test) a zároveň se zabránilo nadměrnému přepínání kontextu a dalším souvisejícím vedlejším účinkům, které by ovlivnily výsledky výkonu.
Tabulka 2: Testbed klientů
|
Počet klientských uzlů |
16 |
|
Uzel klienta |
C6320 |
|
Procesory na uzel klienta |
2x Intel(R) Xeon(R) Gold E5-2697v4, 18 jader při frekvenci 2,3 GHz |
|
Paměť na uzel klienta |
8x 16GiB modul RDIMM 2 400 MT/s (128 GiB) |
|
BIOS |
2.8.0 |
|
Jádro operačního systému |
3.10.0-957.10.1 |
|
Software systému souborů |
Spectrum Scale (GPFS) 5.0.4-3 s verzí NVMesh 2.0.1 |
Sekvenční výkon IOzone N klientů – N souborů
Sekvenční výkon N klientů – N souborů byl měřen pomocí Iozone verze 3.487. Provedené testy se pohybovaly v rozmezí 1–1024 v přírůstcích po mocnině 2.
Vliv ukládání do cache na servery byl minimalizován nastavením fondu stránek GPFS na 16 GiB a použitím souborů větších než dvojnásobek této velikosti. Je důležité zmínit, že u systému GPFS tato laditelná položka nastavuje maximální množství paměti použité pro ukládání dat do cache bez ohledu na množství nainstalované a volné paměti RAM. Důležité je také poznamenat, že zatímco v předchozích řešeních Dell EMC HPC je velikost bloku pro velké sekvenční přenosy 1 MiB, systém GPFS byl naformátován na 8MiB bloky, a proto je tato hodnota použita v benchmarku pro optimální výkon. Může se zdát, že to je příliš velké a zřejmě se tím příliš plýtvá místem, ale systém GPFS používá přidělování podbloků, aby této situaci zabránil. V současné konfiguraci byl každý blok rozdělen do 256 podbloků po 32 KiB.
K provedení srovnávacího testu pro zápis a čtení byly použity následující příkazy, kde $Threads byla proměnná s počtem použitých vláken (1 až 1024 s přírůstkem v mocninách dvou) a threadlist byl soubor, který přidělil každé vlákno na jiný uzel, přičemž použil kruhové dotazování k jejich rovnoměrnému rozložení mezi 16 výpočetních uzlů.
Aby se zabránilo možným účinkům ukládání dat do cache na straně klientů, byla celková velikost datových souborů dvojnásobkem celkové velikosti paměti RAM v použitých klientech. To znamená, že jelikož každý klient má 128 GiB RAM, pro počet vláken rovný nebo vyšší než 16 vláken byla velikost souboru 4 096 GiB děleno počtem vláken (k řízení této hodnoty byla použita proměnná $Size níže). V případech s méně než 16 vlákny (což znamená, že každé vlákno běželo na jiném klientovi) byla velikost souboru opravena na dvojnásobek velikosti paměti na klienta nebo 256 GiB.
iozone -i0 -c -e -w -r 8M -s $ G -t $Threads -+n -+m ./threadlist
iozone -i1 -c -e -w -r 8M -s $ G -t $Threads -+n -+m ./threadlist
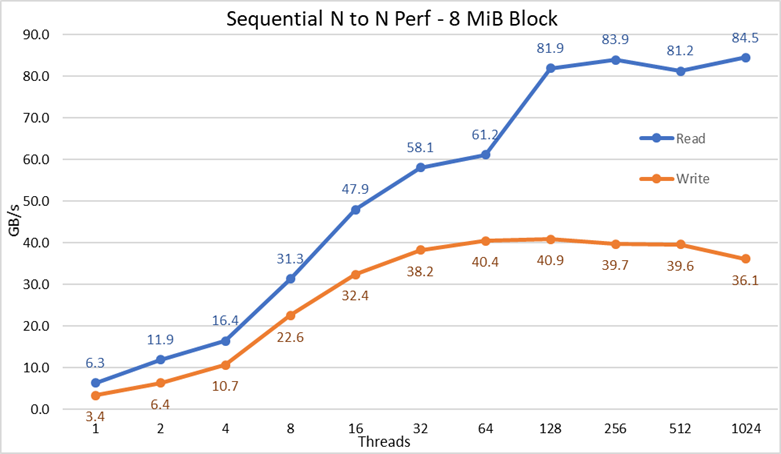
Obrázek 2: Sekvenční výkon N–N
Z výsledků můžeme pozorovat, že výkon zápisu stoupá s počtem použitých vláken a poté dosahuje stabilní hodnoty přibližně u 64 vláken pro zápis a 128 vláken pro čtení. Výkon čtení pak také rychle stoupá s počtem vláken a poté zůstává stabilní, dokud není dosaženo maximálního počtu vláken, který IOzone umožňuje, a proto je sekvenční výkon velkých souborů stabilní i pro 1 024 souběžných klientů. Výkon zápisu klesá asi o 10 % při 1 024 vláknech. Vzhledem k tomu, že cluster klientů má méně než tento počet jader, není jisté, zda je pokles výkonu způsoben výměnou a podobnou režií, která se u rotujících disků nevyskytuje (protože latence NVMe je ve srovnání s rotujícími disky velmi nízká), nebo zda se synchronizace dat RAID 10 stává úzkým hrdlem. K vyjasnění tohoto bodu je zapotřebí více klientů. U 64 vláken byla zaznamenána anomálie při čtení, kdy výkonnost nedosahovala úrovně pozorované u předchozích datových bodů a u následujícího datového bodu se posunula k hodnotě velmi blízké trvalé výkonnosti. K nalezení příčiny této anomálie je zapotřebí provést další testy, které však přesahují rámec tohoto blogu.
Maximální výkon čtení byl nižší než teoretický výkon zařízení NVMe (~102 GB/s) nebo výkon spojů EDR, i když předpokládáme, že jedno spojení bylo převážně používáno pro provoz NVMe přes strukturu (4x EDR BW ~96 GB/s).
To však není překvapivé, protože hardwarová konfigurace není vyvážená, pokud jde o zařízení NVMe a IB HCA pod každým socketem procesoru. Jeden adaptér CX6 je pod CPU1, zatímco CPU2 má všechna zařízení NVMe a druhé adaptéry CX6. Veškerý datový provoz úložiště využívající první HCA musí pro přístup k zařízením NVMe používat rozhraní UPI. Kromě toho musí každé jádro v CPU1 přistupovat k zařízením nebo paměti přiřazeným CPU2, což má negativní vliv na umístění dat, a proto se používají propojení UPI. To může vysvětlovat snížení maximálního výkonu ve srovnání s maximálním výkonem zařízení NVMe nebo rychlostí linky pro HCA CX6. Alternativou k odstranění tohoto omezení je vyvážená hardwarová konfigurace, která znamená snížení hustoty na polovinu pomocí R740 se čtyřmi sloty x16 a použití dvou expandérů PCIe x16 k rovnoměrnému rozložení zařízení NVMe na dva procesory a umístění jednoho HCA CX6 pod každý procesor.
Sekvenční výkon IOR N klientů –1 soubor
Sekvenční výkon N klientů na jeden sdílený soubor byl měřen pomocí IOR verze 3.3.0 s využitím OpenMPI verze 4.0.1 pro spuštění benchmarku na 16 výpočetních uzlech. Provedené testy se lišily od jednoho vlákna až po 512 vláken, protože nebyl dostatek jader pro 1 024 nebo více vláken. V tomto benchmarku byly pro optimální výkon použity bloky o velikosti 8 MiB. V předchozí části věnované testování výkonu je podrobněji vysvětleno, proč je to důležité.
Účinky ukládání dat do cache byly minimalizovány nastavením fondu stránek GPFS na 16 GiB a celková velikost souboru byla dvojnásobkem celkové velikosti RAM v použitých klientech. To znamená, že jelikož každý klient má 128 GiB RAM, pro počet vláken rovný nebo vyšší než 16 vláken byla velikost souboru 4 096 GiB a stejná částka z tohoto celkového množství byla rozdělena počtem vláken (k řízení této hodnoty byla použita proměnná $Size níže). V případech s méně než 16 vlákny (což znamená, že každé vlákno běželo na jiném klientovi) byla velikost souboru dvojnásobkem velikosti paměti na klienta násobené počtem vláken, nebo jinými slovy, každé vlákno mělo k dispozici 256 GiB.
Ke spuštění srovnávacího testu pro zápis a čtení byl použit následující příkaz, kde položka $Threads byla proměnná s počtem použitých vláken (1–1 024, rostoucí po mocnině 2) a položka my_hosts.$Threads byl odpovídající soubor, který přiděloval každé vlákno na jiný uzel, přičemž se použilo kruhové dotazování pro jejich homogenní rozložení mezi 16 výpočetních uzlů.
mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads --mca btl_openib_allow_ib 1 --mca pml ^ucx --oversubscribe --prefix /mmfs1/perftest/ompi /mmfs1/perftest/lanl_ior/bin/ior -a POSIX -v -i 1 -d 3 -e -k -o /mmfs1/perftest/tst.file -w -s 1 -t 8m -b $ G
mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads --mca btl_openib_allow_ib 1 --mca pml ^ucx --oversubscribe --prefix /mmfs1/perftest/ompi /mmfs1/perftest/lanl_ior/bin/ior -a POSIX -v -i 1 -d 3 -e -k -o /mmfs1/perftest/tst.file -r -s 1 -t 8m -b $ G
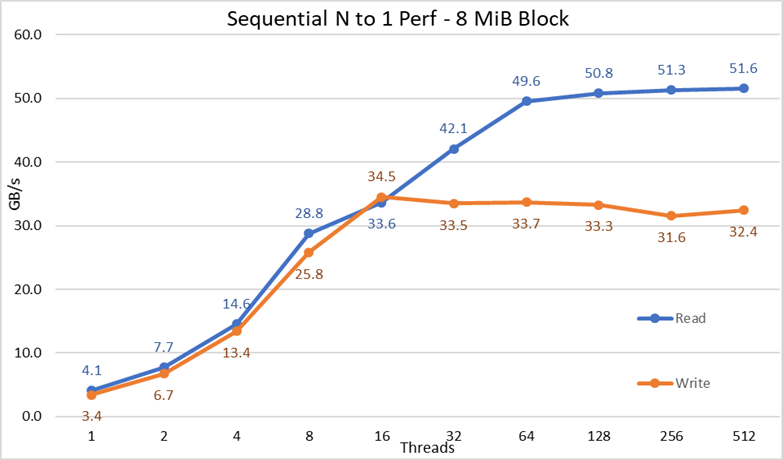
Obrázek 3: Sekvenční výkon N–1
Z výsledků můžeme pozorovat, že výkon čtení a zápisu je vysoký bez ohledu na implicitní potřebu uzamykacích mechanismů, protože všechna vlákna přistupují ke stejnému souboru. Výkon opět velmi rychle stoupá s počtem použitých vláken a poté se dostane do bodu, kde je poměrně stabilní pro čtení i zápis až do použití maximálního počtu vláken v tomto testu. Všimněte si, že maximální výkon čtení byl 51,6 GB/s při 512 vláknech, ale stabilní hodnoty ve výkonu je dosaženo na přibližně 64 vláknech. Podobně si všimněte, že maximálního výkonu zápisu 34,5 GB/s bylo dosaženo u 16 vláken a dosáhlo se stabilního bodu, který lze pozorovat až do maximálního počtu použitých vláken.
Výkon náhodných malých bloků IOzone N klientů – N souborů
Výkon náhodných N klientů–souborů N byl měřen pomocí IOzone verze 3.487. Provedené testy se pohybovaly v rozmezí 1–1024 v přírůstcích po mocnině 2.
Provedené testy se pohybovaly v rozmezí 1–512 vláken, protože pro 1 024 vláken nebyl dostatek klientských jader. Každé vlákno používalo jiný soubor a vlákna byla na přidělena na klientské uzly kruhovým dotazováním. V těchto benchmarcích byly použity bloky o velikosti 4 KiB pro emulaci přenosu malých bloků a hloubka fronty byla 16. Porovnávají se výsledky velkého řešení a rozšíření kapacity.
Účinky ukládání do cache byly opět minimalizovány nastavením fondu stránek GPFS na 16 GiB a aby se zabránilo možným účinkům ukládání dat do cache ze strany klientů, byla celková velikost dat souborů dvojnásobkem celkové velikosti paměti RAM v použitých klientech. To znamená, že jelikož každý klient má 128 GiB RAM, pro počet vláken rovný nebo vyšší než 16 vláken byla velikost souboru 4 096 GiB děleno počtem vláken (k řízení této hodnoty byla použita proměnná $Size níže). V případech s méně než 16 vlákny (což znamená, že každé vlákno běželo na jiném klientovi) byla velikost souboru opravena na dvojnásobek velikosti paměti na klienta nebo 256 GiB.
iozone -i0 -I -c -e -w -r 8M -s $ G -t $Threads -+n -+m ./nvme_threadlist <= Create the files sequentially
iozone -i2 -I -c -O -w -r 4k -s $ G -t $Threads -+n -+m ./nvme_threadlist <= Perform the random reads and writes.
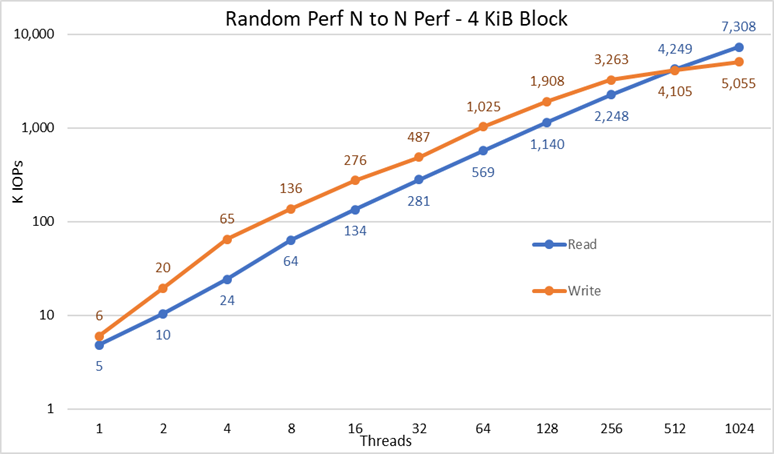
Obrázek 4: Výkon náhodných N–N
Z výsledků můžeme pozorovat, že výkon zápisu začíná na vysoké hodnotě 6 000 IOps a neustále stoupá až do 1 024 vláken, kde se zdá, že dosáhne stabilní hodnoty s více než 5 miliony IOPS, pokud by bylo možné použít více vláken. Naproti tomu výkon čtení začíná na hodnotě 5 000 IOPS a roste lineárně s počtem použitých vláken (mějte na paměti, že počet vláken je pro každý datový bod zdvojnásoben) a dosahuje maximálního výkonu 7,3 milionu IOPS při 1 024 vláknech, kde se zdá, že se blíží dosažení stabilní hodnoty. Použití více vláken bude vyžadovat více než 16 výpočetních uzlů, aby se zabránilo vyčerpání zdrojů a nadměrné výměně, které mohou snížit zdánlivý výkon, zatímco uzly NVMe by ve skutečnosti mohly výkon udržet.
Výkon metadat s nástrojem MDtest pomocí 4KiB souborů
Výkon metadat byl měřen pomocí MDtest verze 3.3.0 s využitím OpenMPI verze 4.0.1 pro spuštění benchmarku na 16 výpočetních uzlech. Provedené testy se pohybovaly v rozmezí 1–512 vláken. Srovnávací test byl použit pouze pro soubory (bez metadat adresářů), aby se zjistil počet vytvoření, statistik, čtení a odstranění, které řešení dokáže zpracovat, a výsledky byly porovnány s řešením pro velké velikosti.
Byl použit volitelný modul metadat pro vysoké nároky, ale s jedním polem ME4024, i když velká konfigurace testovaná v této práci byla určena pro dvě pole ME4024. Důvodem pro použití tohoto modulu metadat je to, že v současné době se tyto uzly NVMe používají pouze jako úložné cíle pro data. Uzly by však mohly být použity k ukládání dat a metadat, nebo dokonce jako alternativní paměť flash pro modul metadat s vysokými nároky, pokud to vyžadují extrémní nároky na metadata. Tyto konfigurace nebyly v rámci této práce testovány.
Vzhledem k tomu, že stejný modul metadat pro vysoké nároky byl použit pro předchozí srovnávací testy Dell EMC Ready Solution for HPC PixStor Storage, budou výsledky metadat velmi podobné výsledkům z předchozího blogu. Z tohoto důvodu nebyla provedena studie s prázdnými soubory, ale místo toho byly použity soubory o velikosti 4 KiB. Vzhledem k tomu, že soubory o velikosti 4 KiB se spolu s informacemi o metadatech nevejdou do uzlu inode, budou k ukládání dat pro každý soubor použity uzly NVMe. MDtest proto může poskytnout hrubou představu o výkonu malých souborů při čtení a ostatních operací s metadaty.
Ke spuštění benchmarku byl použit následující příkaz, kde položka $Threads byla proměnná s počtem použitých vláken (1–512, rostoucí po mocnině 2) a položka my_hosts.$Threads je odpovídající soubor, který přiděloval každé vlákno na jiný uzel, přičemž se použilo kruhové dotazování pro jejich homogenní rozložení mezi 16 výpočetních uzlů. Podobně jako u benchmarku náhodného IO byl maximální počet vláken omezen na 512, protože pro 1 024 vláken není k dispozici dostatek jader a přepínání kontextu by ovlivnilo výsledky a vykazovalo by nižší než skutečný výkon řešení.
mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads --prefix /mmfs1/perftest/ompi --mca btl_openib_allow_ib 1 /mmfs1/perftest/lanl_ior/bin/mdtest -v -d /mmfs1/perftest/ -i 1 -b $Directories -z 1 -L -I 1024 -y -u -t -F -w 4K -e 4K
Jelikož výsledky výkonu mohou být ovlivněny celkovým počtem IOPS, počtem souborů v adresáři a počtem vláken, bylo rozhodnuto, že celkový počet souborů bude pevně stanoven na 2 MiB souborů (2^21 = 2 097 152), počet souborů v adresáři byl pevně stanoven na 1 024 a počet adresářů se měnil se změnou počtu vláken, jak je uvedeno v tabulce 3.
Tabulka 3: Rozložení souborů v adresářích v nástroji MDtest
|
Počet vláken |
Počet adresářů na vlákno |
Celkový počet souborů |
|
1 |
2 048 |
2 097 152 |
|
2 |
1 024 |
2 097 152 |
|
4 |
512 |
2 097 152 |
|
8 |
256 |
2 097 152 |
|
16 |
128 |
2 097 152 |
|
32 |
64 |
2 097 152 |
|
64 |
32 |
2 097 152 |
|
128 |
16 |
2 097 152 |
|
256 |
8 |
2 097 152 |
|
512 |
4 |
2 097 152 |
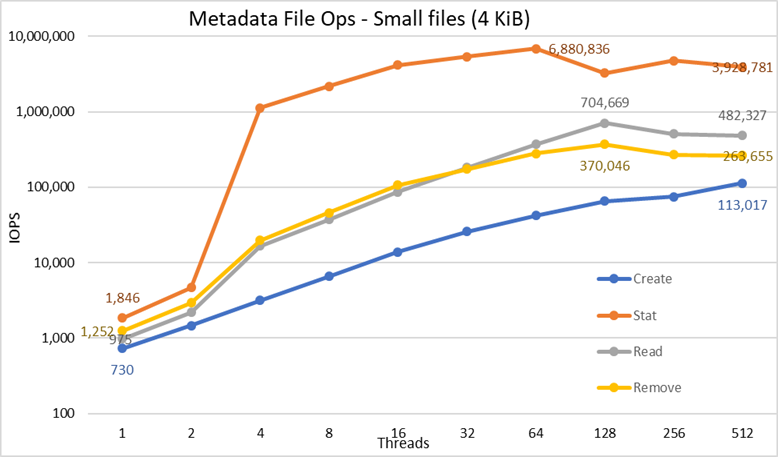
Obrázek 5: Výkon metadat – 4KiB soubory
Nejprve si všimněte, že byla zvolena logaritmická stupnice o základu 10, aby bylo možné porovnávat operace, které se liší o několik řádů, jinak by některé operace na lineární stupnici vypadaly jako plochá čára blízká 0. Logaritmický graf se základem 2 by mohl být vhodnější, protože počet vláken se zvyšuje v mocninách 2, ale graf by vypadal velmi podobně a lidé mají tendenci lépe si pamatovat čísla založená na mocninách 10 a pracovat s nimi.
Systém dosahuje velmi dobrých výsledků, jak bylo již dříve uvedeno, přičemž operace Stat dosahují maximální hodnoty při 64 vláknech s téměř 6,9 miliony operací za sekundu, a poté se při vyšším počtu vláken snižují a dosahují stabilní hodnoty. Operace Create dosahují maxima 113 tisíc operací za sekundu při 512 vláknech, takže se očekává, že budou dále stoupat, pokud bude použito více klientských uzlů (a jader). Operace čtení a odstraňování dosáhly svého maxima při 128 vláknech, kdy dosáhly vrcholu téměř 705 000 operací za sekundu pro operace Read a 370 000 operací za sekundu pro operace Remove, a poté dosáhly stabilní hodnoty. Operace Stat vykazují větší variabilitu, ale jakmile dosáhnou své maximální hodnoty, výkon neklesne pod 3,2 milionu op/s pro operace Stat. Operace Create a Removal jsou stabilnější, jakmile dosáhnou stabilní hodnoty a udržují se nad 265 000 op/s pro operace Removal a 113 000 op/s pro operace Create. A konečně, čtení dosáhnou stabilní hodnoty s výkonem nad 265 000 operací za sekundu.
Závěry a budoucí práce
Uzly NVMe jsou důležitým doplňkem úložného řešení HPC, protože poskytují velmi výkonnou vrstvu s dobrou hustotou, velmi vysokým výkonem při náhodném přístupu a velmi vysokým sekvenčním výkonem. Kapacita a výkon řešení se navíc lineárně škálují s tím, jak se přidávají další moduly uzlů NVMe. Přehled výkonu uzlů NVMe je uveden v tabulce 4; očekává se, že bude stabilní, a tyto hodnoty lze použít k odhadu výkonu pro různý počet uzlů NVMe.
Mějte však na paměti, že každá dvojice uzlů NVMe bude poskytovat polovinu jakéhokoli čísla uvedeného v tabulce 4.
Toto řešení poskytuje zákazníkům HPC velmi spolehlivý paralelní systém souborů, který využívá mnoho clusterů HPC z žebříčku Top 500. Kromě toho poskytuje výjimečné možnosti vyhledávání, pokročilé monitorování a správu a přidáním volitelných bran umožňuje sdílení souborů prostřednictvím běžných standardních protokolů, jako jsou NFS, SMB a další, pro libovolný počet klientů.
Tabulka 4 Špičkový a trvalý výkon pro 2 páry uzlů NVMe
|
|
Špičkový výkon |
Stálý výkon |
||
|
Zápis |
Čtení |
Zápis |
Čtení |
|
|
Velký sekvenční N klientů – N souborů |
40,9 GB/s |
84,5 GB/s |
40 GB/s |
81 GB/s |
|
Velký sekvenční N klientů – jeden sdílený soubor |
34,5 GB/s |
51,6 GB/s |
31,5 GB/s |
50 GB/s |
|
Náhodné malé bloky N klientů – N souborů |
5,06 milionu IOPS |
7,31 milionu IOPS |
5 milionů IOPS |
7,3 milionů IOPS |
|
4KiB soubory metadat – Create |
113 000 IOPS |
113 000 IOPS |
||
|
4KiB soubory metadat – Stat |
6,88 milionu IOPS |
3,2 mil. IOPS |
||
|
4KiB soubory metadat – Read |
705 000 IOPS |
500 000 IOPS |
||
|
4KiB soubory metadat – Remove |
370 000 IOPS |
265 000 IOPS |
||
Vzhledem k tomu, že uzly NVMe byly použity pouze pro data, možná může budoucí práce zahrnovat jejich použití pro data a metadata a mít samostatnou vrstvu založenou na paměti flash s lepším výkonem metadat díky vyšší šířce pásma a nižší latenci zařízení NVMe ve srovnání s disky SSD SAS3 za řadiči RAID. Případně, pokud má zákazník extrémně vysoké požadavky na metadata a požaduje řešení s vyšší hustotou, než jakou může poskytnout modul metadat pro vysoké nároky, lze některá nebo všechna distribuovaná zařízení RAID 10 použít pro metadata stejným způsobem, jakým se nyní používají zařízení RAID 1 ve skříni ME4024.
Další blog, který bude brzy vydán, bude charakterizovat uzly brány PixStor, které umožňují připojení řešení PixStor k jiným sítím pomocí protokolů NFS nebo SMB a mohou škálovat výkon. Řešení bude také velmi brzy aktualizováno na HDR100 a očekává se, že o této práci bude hovořit další blog.
Affected Products
High Performance Computing Solution ResourcesArticle Properties
Article Number: 000130558
Article Type: Solution
Last Modified: 21 Feb 2021
Version: 3
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.