VMware:vSAN物理ディスク トラブルシューティング ガイド
Summary: これは、vSANクラスター内の物理ディスクに問題があるかどうかを特定するのに役立つ一般的なトラブルシューティング ガイドです。
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Instructions
Web UIからのvSAN物理ディスク ステータスの確認:
vCenter Server Web Clientに接続し、次からディスク ステータスを確認します。
インベントリー>vSANクラスター>ホストとクラスター > vSANの構成>>ディスク管理
図1:vSANディスク管理ビュー
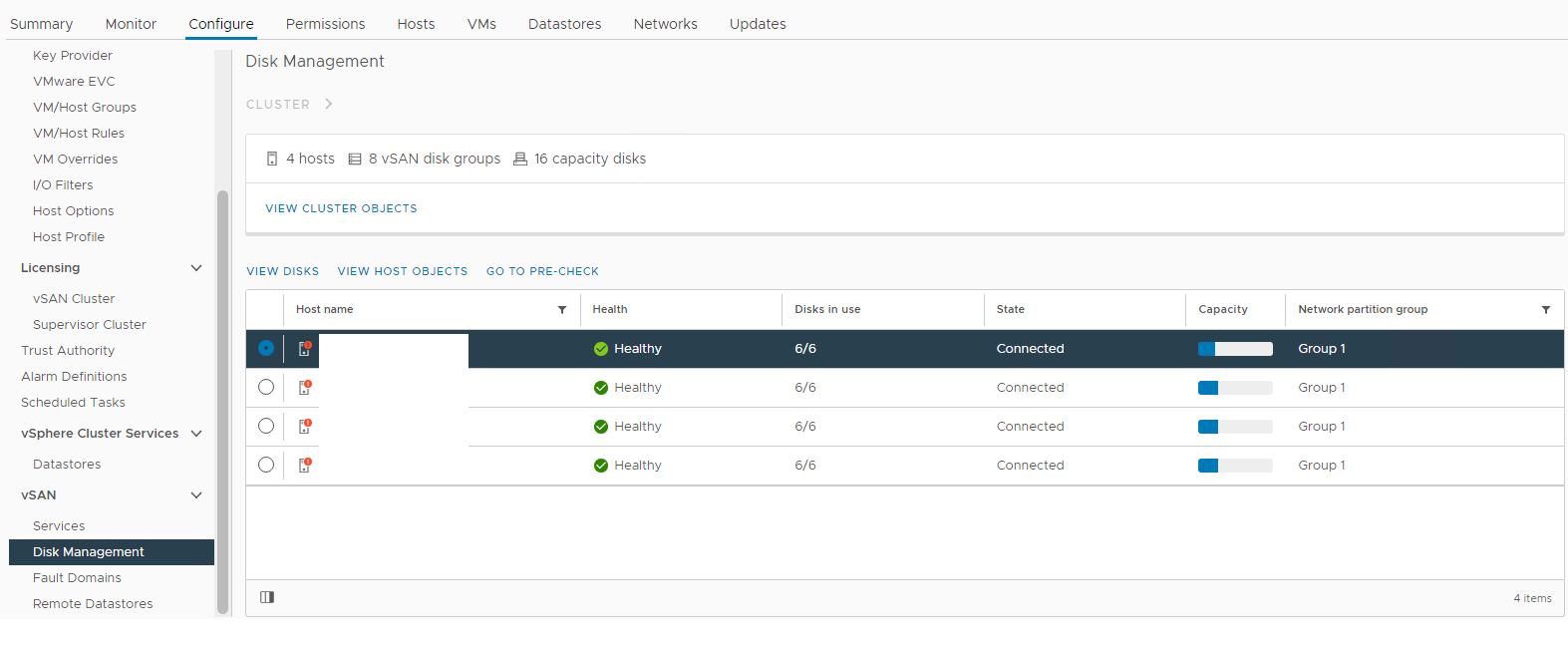
影響を受けるホストを選択し、[ディスクの表示]セクションを展開します。
図2:vSANディスク グループ ビュー
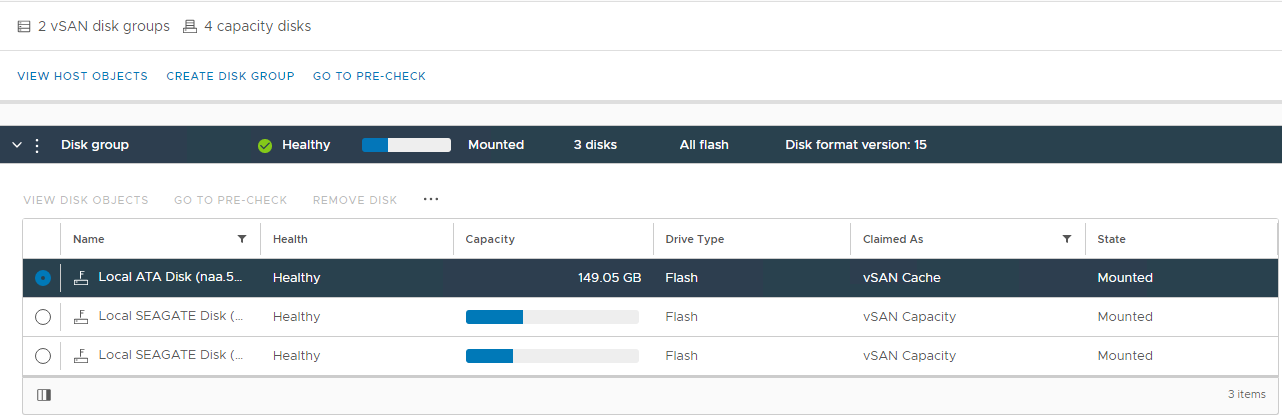
ここでは、ディスクが次のように検出されているかどうかを確認できます。
異常
アンマウント
0 容量
永続的なディスク障害
ディスク ダウン
ディスクがありません
また、vSAN Skyline の [健全性] セクションからトリガーされたディスク関連のアラームを確認します。
インベントリー>vSANクラスター>ホストとクラスター > vSAN>スカイラインの正常性>物理ディスク>監視
画像3: スカイラインの健全性ビュー
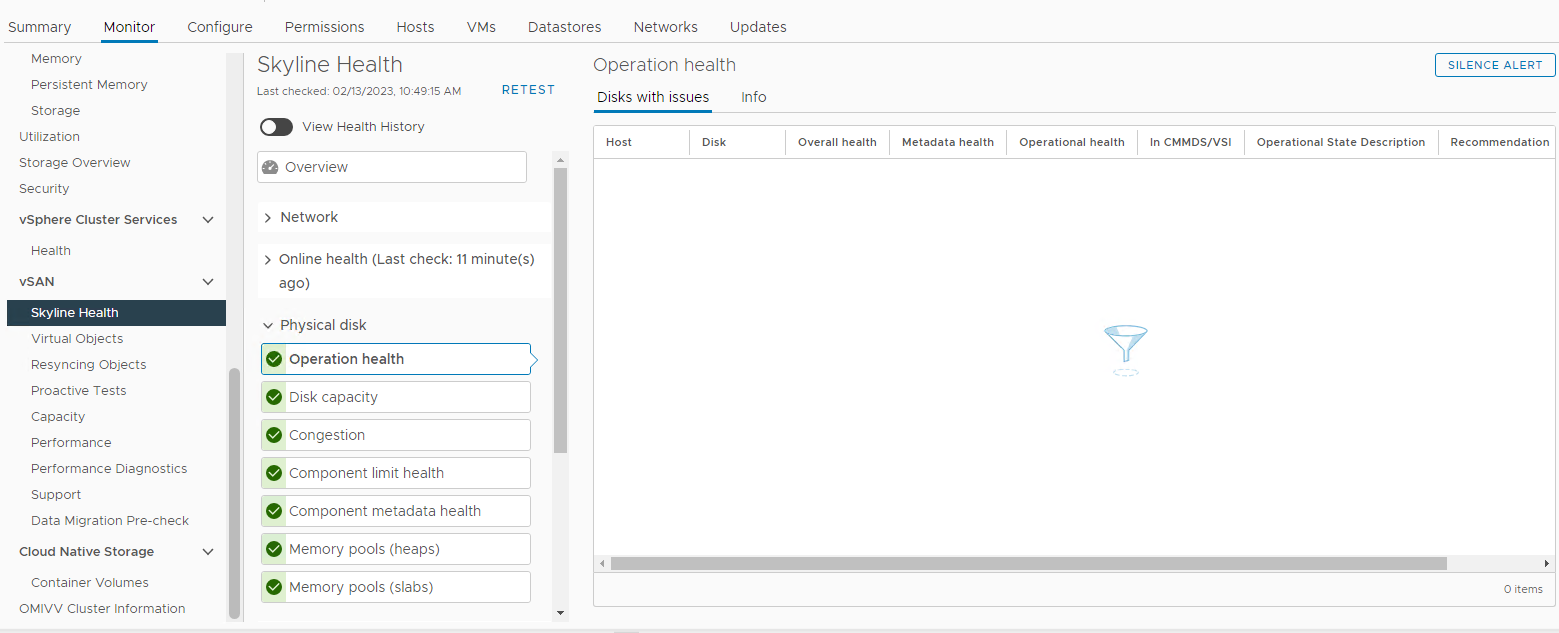
ここでは、次のアラームのいずれかがトリガーされているかどうかを確認できます。
Impending permanent disk failure, data is being evacuated (Health state - Yellow).
Impending permanent disk failure, data evacuation failed due to insufficient resources (Health state - Red).
Impending permanent disk failure, data evacuation failed due to inaccessible objects (Health state - Red).
Impending permanent disk failure, data evacuation completed (Health state - Yellow)
また、影響を受けるホストの[Storage Devices]リストからディスク ステータスを確認することもできます。
インベントリー>vSANクラスター>ホストとクラスター>影響を受けるvSAN ESXiホスト>>ストレージ>ストレージ デバイスを構成します
図4: ホスト ストレージ デバイス ビュー
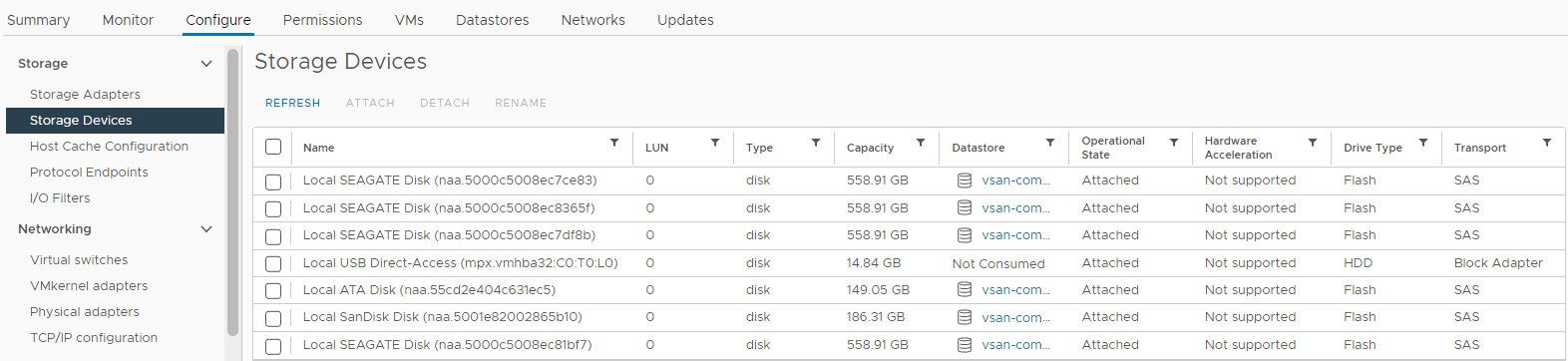
ここでは、ディスク ステータスが次のとおりかどうかを確認できます。
0 Capacity
Disk Absent
Disk Unmounted
再同期が発生しているかどうかを確認します。
インベントリー>vSANクラスター>ホストとクラスター > vSANモニター>vSAN>の再同期中:
図5: [Resyncing Objects]ビュー
![[Resyncing Objects]ビュー](https://supportkb.dell.com/img/ka0Do000000deuNIAQ/ka0Do000000deuNIAQ_ja_5.jpeg)
注:再同期は、影響を受けるディスクまたはディスク グループからデータが退避中であることを示している可能性があります。影響を受けたディスクを取り外しまたは交換する準備ができているかどうかを判断するには、さらに調査する必要があります。
vSANオブジェクトのステータスを確認します。
インベントリー>vSANクラスター > モニター>ホストおよびクラスター > vSAN>スカイラインの稼働状態>データ > vSANオブジェクトの稼働状態
図6:vSANオブジェクトの稼働状態ビュー
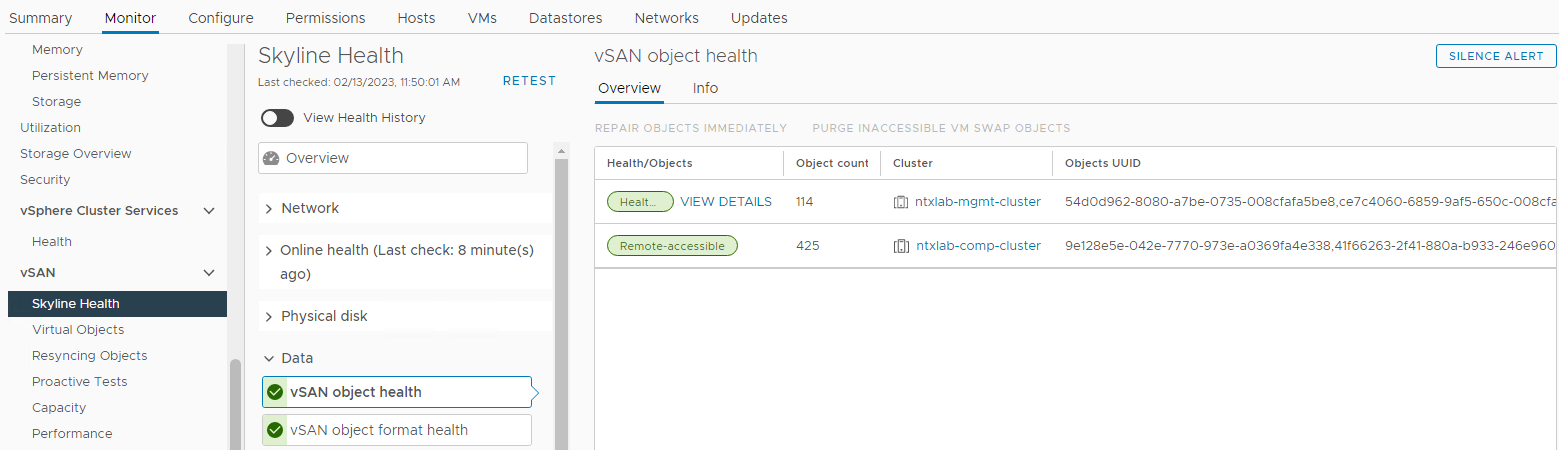
注:アクセスできないオブジェクトがないことを確認することが重要です。オブジェクトにアクセスできないとは、「オブジェクトのすべてのコピーが欠落している」ことを意味します。DLの原因となる可能性のあるディスクを取り外したり交換したりする場合。
次の手順では、CLIを使用して問題に関する詳細情報を収集し、ログを確認します。
CLIからのvSAN物理ディスク ステータスの確認:
影響を受けるホストにSSH経由で接続し、次のコマンドを実行します。
vdq -qH
「IsPDL" (永続的なデバイス損失) パラメーター。1の場合、ディスクは失われます。
Example:
DiskResults:
DiskResult[0]:
Name: naa.600508b1001c4b820b4d80f9f8acfa95
VSANUUID: 5294bbd8-67c4-c545-3952-7711e365f7fa
State: In-use for VSAN
ChecksumSupport: 0
Reason: Non-local disk
IsSSD?: 0
IsCapacityFlash?: 0
IsPDL?: 0
<<truncated>>
DiskResult[18]:
Name:
VSANUUID: 5227c17e-ec64-de76-c10e-c272102beba7
State: In-use for VSAN
ChecksumSupport: 0
Reason: None
IsSSD?: 0
IsCapacityFlash?: 0
IsPDL?: 1
vdq -iH
ディスク グループから欠落しているディスクがあるかどうかを確認します。
Example:
Mappings: DiskMapping[0]: SSD: naa.58ce38ee2016ffe5 MD: naa.5002538a4819e3e0 DiskMapping[2]: SSD: naa.58ce38ee2016fe55 MD: naa.5002538a48199ca0 MD: naa.5002538a48199e20 MD: naa.5002538a48199e00
esxcli vsan storage list
で確認します "In CMMDS" パラメーターを使用します。false の場合、ディスクへの通信が失われます。
Example:
Device: Unknown
Display Name: Unknown
Is SSD: false
VSAN UUID: 529cadbc-acd1-b588-8643-68336d5512d6
VSAN Disk Group UUID:
VSAN Disk Group Name:
Used by this host: false
In CMMDS: false
On-disk format version: <Unknown>
Deduplication: false
Compression: false
Checksum:
Checksum OK: false
Is Capacity Tier: false
for i in `esxcli storage core device list | grep ^naa` ; do echo $i; esxcli storage core device smart get -d $i; done.
smart getコマンドで読み取り/書き込みエラーを確認します。
Example:
naa.55cd2e404c1f35a1 Parameter Value Threshold Worst Raw -------------------------- ----- --------- ----- --- Health Status OK N/A N/A N/A Media Wearout Indicator 100 0 100 86 Read Error Count 130 39 130 133 Power-on Hours 100 0 100 110 Power Cycle Count 100 0 100 106 Drive Temperature 100 0 100 26 Uncorrectable Sector Count 100 0 100 0
naa.55cd2e404c1f35a5 Parameter Value Threshold Worst Raw -------------------------- ----- --------- ----- --- Health Status OK N/A N/A N/A Media Wearout Indicator 100 0 100 10 Read Error Count 130 39 130 53 Power-on Hours 100 0 100 110 Power Cycle Count 100 0 100 106 Drive Temperature 100 0 100 27 Uncorrectable Sector Count 100 0 100 0
esxcli vsan storage list | grep "VSAN Disk Group UUID:" | sort | uniq -c
使用可能なディスク グループを確認します。
Example:
2 VSAN Disk Group UUID: 5203424c-ee56-497d-75d1-fcf73ae997cb 2 VSAN Disk Group UUID: 52af8e5c-77d1-b552-3310-ec5fef09edf4
while true;do echo " ****************************************** "; echo "" > /tmp/resyncStats.txt ;cmmds-tool find -t DOM_OBJECT -f json |grep uuid |awk -F \" '{print $4}' |while read i;do pendingResync=$(cmmds-tool find -t DOM_OBJECT -f json -u $i|grep -o "\"bytesToSync\": [0-9]*,"|awk -F " |," '{sum+=$2} END{print sum / 1024 / 1024 / 1024;}');if [ ${#pendingResync} -ne 1 ]; then echo "$i: $pendingResync GiB";fi;done |tee -a /tmp/resyncStats.txt;total=$(cat /tmp/resyncStats.txt |awk '{sum+=$2} END{print sum}');echo "Total: $total GiB" |tee -aa /tmp/resyncStats.txt;total=$(cat /tmp/resyncStats.txt |grep Total);totalObj=$(cat /tmp/resyncStats.txt|grep -vE " 0 GiB|Total"|wc -l);echo "`date +%Y-%m-%dT%H:%M:%SZ` $total ($totalObj objects)" >> /tmp/totalHistory.txt; echo `date `; sleep 60; done
再同期操作が進行中か停止しているかを確認します。
Example:
Total: 0 GiB Mon Feb 13 17:32:06 UTC 2023
Ctrl+Cを押してコマンドを停止します。
cmmds-tool find -f python | grep CONFIG_STATUS -B 4 -A 6 | grep 'uuid\|content' | grep -o 'state\\\":\ [0-9]*' | sort | uniq -c
コンポーネントの状態を確認します。
Healthy -- state 7
Inaccessible -- state 13
Absent or Degraded -- state 15
Example:
425 state\": 7
CLIを使用して障害が発生したSSDまたはハード ドライブの場所を特定する方法:
使用可能なすべてのデバイスを一覧表示します。
esxcli storage core device list | grep "naa" | awk '{print $1}' | grep "naa"
Example:
naa.5000c500852df8d3 naa.55cd2e404c1f35a1 naa.55cd2e404c1f35a5 naa.5000c500852dd5e7
リストから各ディスクnaaを使用して場所を確認します。
esxcli storage core device physical get -d
Example:
esxcli storage core device physical get -d naa.5000c500852df8d3 esxcli storage core device physical get -d naa.55cd2e404c1f35a1 esxcli storage core device physical get -d naa.55cd2e404c1f35a5 esxcli storage core device physical get -d naa.5000c500852dd5e7 Physical Location: enclosure 65535 slot 0 Physical Location: enclosure 65535 slot 1 Physical Location: enclosure 65535 slot 2 Physical Location: enclosure 65535 slot 3
デバイス名がない場合に障害が発生したハード ドライブまたはSSDを識別する方法:
障害が発生したディスクが検出されず、対応するnaaを使用して識別できない可能性があります。このシナリオでは、すべてのディスクを見つける必要があり、物理的に配置されていないディスクは障害が発生したディスクです
タスクを少し速く実行するために使用できるスクリプトを次に示します。
echo "=============Physical disks placement=============="
echo ""
esxcli storage core device list | grep "naa" | awk '{print $1}' | grep "naa" | while read in; do
echo "$in"
esxcli storage core device physical get -d "$in"
sleep 1
echo "===================================================="
done
ストレージ関連の問題に関するvSAN関連ログ:
/var/log/vmkernel.log
vSANディスク、vSANホストのハートビート、PDL、SCSIセンス コードとI/O要求(読み取り/書き込み)、クラスター メンバーシップ情報の読み取りと書き込みに関する問題。
Example:
2021-06-22T12:02:08.408Z cpu30:1001397101)ScsiDeviceIO: PsaScsiDeviceTimeoutHandlerFn:12834: TaskMgmt op to cancel IO succeeded for device naa.55cd2e404b7736d0 and the IO did not complete. WorldId 0, Cmd 0x28, CmdSN = 0x428.Cancelling of IO will be 2021-06-22T12:02:08.408Z cpu30:1001397101)retried.
/var/log/vobd.log
ディスクの稼働状態、永続的なデバイス喪失ディスク(PDL)、ディスク レイテンシについてレポートし、ホストがメンテナンス モードを開始および終了したタイミングに関するレポートを作成します。
Example:
2022-05-31T11:42:46.065Z: [vSANCorrelator] 10605891965954us: [vob.vsan.lsom.devicerepair] vSAN device 521a74ce-c980-c16c-ff3d-38a036233daf is being repaired due to I/O failures, and will be out of service until the repair is complete. If the device is part of a dedup disk group, the entire disk group will be out of service until the repair is complete. 2022-05-31T11:42:46.065Z: [vSANCorrelator] 10606062774178us: [esx.problem.vob.vsan.lsom.devicerepair] Device 521a74ce-c980-c16c-ff3d-38a036233daf is in offline state and is getting repaired
/var/log/vsandevicemonitord.log
これは、過剰なログ輻輳や I/O レイテンシが原因でディスクが異常とマークされたかどうかを判断するのに役立ちます。
Example:
INFO vsandevicemonitord WARNING - WRITE Average Latency on VSAN device naa.50000xxxxxxxx has exceeded threshold value 2000000 us 2 times. INFO vsandevicemonitord Tier 2 (naa.50000xxxxxxxx) as unhealthy
Additional Information
次のビデオを参照してください。
VMware:vSAN物理ディスク トラブルシューティング ガイド
再生時間:00:10:19 (hh:mm:ss)
利用可能な場合、このビデオ プレーヤーのCCアイコンを使用してクローズド キャプション(字幕)の言語設定を選択できます。
このビデオはYouTubeでも視聴できます。
Affected Products
PowerEdge C6420, PowerEdge C6520, PowerEdge C6525, PowerEdge C6615, PowerEdge C6620, PowerEdge M640 (for PE VRTX), PowerEdge R440, PowerEdge R450, PowerEdge R540, PowerEdge R550, PowerEdge R640, PowerEdge R6415, PowerEdge R650, PowerEdge R650xs
, PowerEdge R6515, PowerEdge R6525, PowerEdge R660, PowerEdge R660xs, PowerEdge R6615, PowerEdge R6625, PowerEdge R740, PowerEdge R740XD, PowerEdge R740XD2, PowerEdge R7415, PowerEdge R7425, PowerEdge R750, PowerEdge R750XA, PowerEdge R750xs, PowerEdge R7515, PowerEdge R7525, PowerEdge R760, PowerEdge R760XA, PowerEdge R760xd2, PowerEdge R760xs, PowerEdge R7615, PowerEdge R7625, PowerEdge R840, PowerEdge R860, PowerEdge R940, PowerEdge R940xa, PowerEdge R960, PowerEdge T430, PowerEdge T440, PowerEdge T550, PowerEdge T560, PowerEdge T630, PowerEdge T640, VMware ESXi 6.7.X, VMware ESXi 7.x, VMware ESXi 8.x, VMware VSAN, Dell EMC vSAN C6420 Ready Node, Dell EMC vSAN MX740c Ready Node, Dell EMC vSAN MX750c Ready Node, Dell vSAN Ready Node MX760c, Dell EMC vSAN R440 Ready Node, Dell EMC vSAN R640 Ready Node, Dell EMC vSAN R6415 Ready Node, Dell EMC vSAN R650 Ready Node, Dell EMC vSAN R6515 Ready Node, vSAN Ready Node R660, Dell vSAN R6615 Ready Node, Dell EMC vSAN R740 Ready Node, Dell EMC vSAN R740xd Ready Node, Dell EMC vSAN R750 Ready Node, Dell EMC vSAN R7515 Ready Node, Dell EMC vSAN R760 Ready Node, Dell vSAN R7615 Ready Node, Dell vSAN Ready Node R7625, Dell EMC vSAN R840 Ready Node, Dell EMC vSAN T350 Ready Node, VxRail 460 and 470 Nodes, VxRail D560, VxRail D560F, VxRail E460, VxRail E560, VxRail E560F, VxRail E560N, VxRail E660, VxRail E660F, VxRail E660N, VxRail E665, VxRail E665F, VxRail E665N, VxRail G560, VxRail G560F, VxRail P470, VxRail P570, VxRail P570F, VxRail P580N, VxRail P670F, VxRail P670N, VxRail P675F, VxRail P675N, VxRail S470, VxRail S570, VxRail S670, VxRail V470, VxRail V570, VxRail V570F, VXRAIL V670F, VxRail VD-4510C, VxRail VD-4520C, VxRail VE-660, VxRail VE-6615, VxRail VE-670, VxRail VP-760, VxRail VP-7625, VxRail VP-770
...
Products
VxRail, PowerEdge C6420, PowerEdge C6520, PowerEdge C6525, PowerEdge C6615, PowerEdge C6620, PowerEdge M640 (for PE VRTX), PowerEdge R440, PowerEdge R450, PowerEdge R540, PowerEdge R550, PowerEdge R640, PowerEdge R6415, PowerEdge R650
, PowerEdge R650xs, PowerEdge R6515, PowerEdge R6525, PowerEdge R660, PowerEdge R660xs, PowerEdge R6615, PowerEdge R6625, PowerEdge R740, PowerEdge R740XD, PowerEdge R740XD2, PowerEdge R7415, PowerEdge R7425, PowerEdge R750, PowerEdge R750XA, PowerEdge R750xs, PowerEdge R7515, PowerEdge R7525, PowerEdge R760, PowerEdge R760XA, PowerEdge R760xd2, PowerEdge R760xs, PowerEdge R7615, PowerEdge R7625, PowerEdge R840, PowerEdge R860, PowerEdge R940, PowerEdge R940xa, PowerEdge R960, PowerEdge T430, PowerEdge T440, PowerEdge T550, PowerEdge T560, PowerEdge T630, PowerEdge T640, Dell EMC vSAN C6420 Ready Node, Dell EMC vSAN MX740c Ready Node, Dell EMC vSAN MX750c Ready Node, Dell vSAN Ready Node MX760c, Dell EMC vSAN R440 Ready Node, Dell EMC vSAN R640 Ready Node, Dell EMC vSAN R6415 Ready Node, Dell EMC vSAN R650 Ready Node, Dell EMC vSAN R6515 Ready Node, vSAN Ready Node R660, Dell vSAN R6615 Ready Node, Dell EMC vSAN R740 Ready Node, Dell EMC vSAN R740xd Ready Node, Dell EMC vSAN R750 Ready Node, Dell EMC vSAN R7515 Ready Node, Dell EMC vSAN R760 Ready Node, Dell vSAN R7615 Ready Node, Dell vSAN Ready Node R7625, Dell EMC vSAN R840 Ready Node, Dell EMC vSAN T350 Ready Node
...
Article Properties
Article Number: 000209262
Article Type: How To
Last Modified: 29 May 2026
Version: 7
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.