PowerEdge: AMD Rome – Architektur und HPC-Anfangsperformance
Summary: Einführung in AMDs EPYC-Prozessor der neuesten Generation mit dem Codenamen Rome
Instructions
Garima Kochhar, Deepthi Cherlopalle, Joshua Weage. HPC and AI Innovation Lab, Oktober 2019
In der aktuellen HPC-Welt muss AMDs EPYC-Prozessor der neuesten Generation mit dem Codenamen Rome kaum noch vorgestellt werden. Wir haben in den letzten Monaten im HPC and AI Innovation Lab
Rome-basierte Systeme evaluiert und Dell Technologies hat kürzlich Server angekündigt
, die diese Prozessorarchitektur unterstützen. In diesem ersten Blog der Rome-Reihe wird die Rome-Prozessorarchitektur beschrieben und erläutert, wie diese für HPC-Performance optimiert werden kann. Außerdem werden erste Microbenchmark-Performanceergebnisse vorgestellt. In nachfolgenden Blogs wird es um die Anwendungsperformance in den Bereichen CFD, CAE, Molekulardynamik, Wettersimulation und bei anderen Anwendungen gehen.
Architektur
Rome ist AMDs EPYC-CPU der 2. Generation und eine Aktualisierung der 1. Generation, Naples.
Einer der größten Architekturunterschiede zwischen Naples und Rome, von dem HPC profitiert, ist der neue I/O-Chip in Rome. Jeder Rome-Prozessor ist ein Multi-Chip-Gehäuse, das aus bis zu neun Chiplets besteht, wie in Abbildung 1 dargestellt. Es gibt einen zentralen 14-nm-I/O-Chip, der alle I/O- und Speicherfunktionen enthält, sprich Speicher-Controller, Infinity-Fabric-Links innerhalb des Sockels und Sockel-zu-Sockel-Verbindungen sowie PCIe. Pro Sockel sind acht Speicher-Controller vorhanden, die acht Speicherkanäle unterstützen, auf denen DDR4 mit 3.200 MT/s ausgeführt wird. Ein Server mit einem Sockel kann bis zu 130 PCIe-Gen4-Lanes unterstützen. Ein System mit zwei Sockeln kann bis zu 160 PCIe-Gen4-Lanes unterstützen.
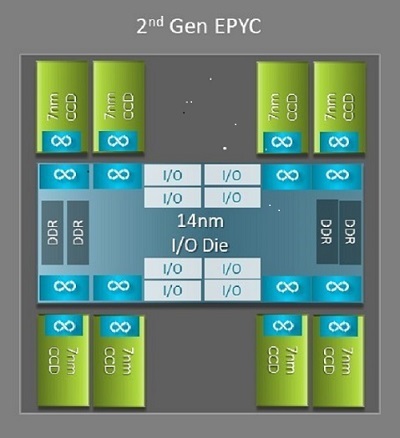
(Abbildung 1: Rome-Multi-Chip-Gehäuse mit einem zentralen I/O-Chip und bis zu 8-Core-Chips)
Um den zentralen I/O-Chip herum sind bis zu acht 7-nm-Core-Chiplets angeordnet. Das Core-Chiplet wird als Core-Cache-Die bzw. CCD bezeichnet. Jeder CCD verfügt über CPU-Cores basierend auf der Zen2-Mikroarchitektur mit L2-Cache und 32 MB L3-Cache. Der CCD selbst verfügt über zwei Core Cache Complexes (CCX) mit jeweils bis zu vier Cores und 16 MB L3-Cache. Abbildung 2 zeigt einen CCX.

(Abbildung 2: CCX mit vier Cores und gemeinsam genutztem 16-MB-L3-Cache)
Die verschiedenen Rome-CPU-Modelle haben zwar eine unterschiedliche Anzahl an Cores
, sie verfügen jedoch alle über einen zentralen I/O-Chip.
An der Spitze steht ein 64-Core-CPU-Modell, zum Beispiel der EPYC 7702. Die Lstopo-Ausgabe zeigt, dass dieser Prozessor mit 16 CCXs pro Sockel ausgestattet ist, wobei jeder CCX über vier Cores verfügt, wie in Abbildung 3 und 4 gezeigt, was 64 Cores pro Sockel ergibt. Mit 16 MB L3-Cache pro CCX, also 32 MB L3-Cache pro CCD, bietet dieser Prozessor 256 MB L3-Cache. Es ist jedoch zu beachten, dass der gesamte L3-Cache in Rome nicht von allen Cores gemeinsam genutzt wird. Die 16-MB-L3-Caches in jedem CCX sind unabhängig voneinander und werden nur von den Cores im jeweiligen CCX gemeinsam genutzt, wie in Abbildung 2 dargestellt.
Eine 24-Core-CPU wie der EPYC 7402 verfügt über einen L3-Cache mit 128 MB. Die Lstopo-Ausgabe in Abbildung 3 und 4 zeigt, dass dieses Modell drei Cores pro CCX und acht CCX pro Sockel hat.
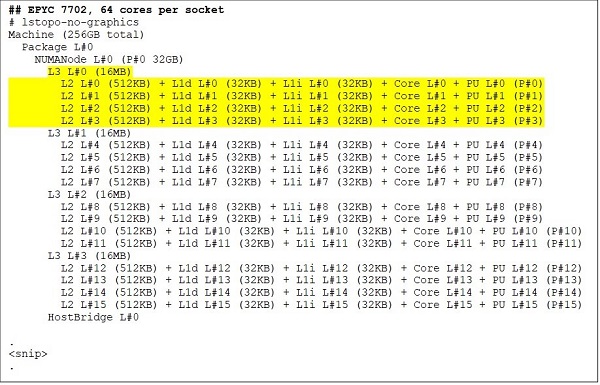
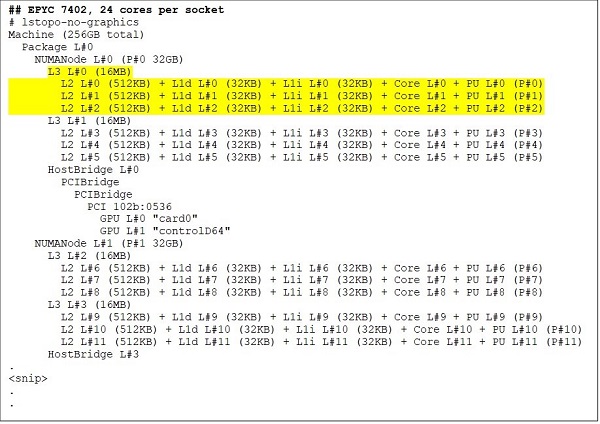
(Abbildung 3 und 4: Lstopo-Ausgabe für 64- und 24-Core-CPUs)
Unabhängig von der Anzahl der CCDs ist jeder Rome-Prozessor logisch in vier Quadranten unterteilt, wobei die CCDs möglichst gleichmäßig über die Quadranten verteilt und in jedem Quadranten zwei Speicherkanäle vorhanden sind. Der zentrale I/O-Chip kann als logische Unterstützung der vier Quadranten des Sockels betrachtet werden.
BIOS-Optionen basierend auf der Rome-Architektur
Der zentrale I/O-Chip in Rome trägt zur Verbesserung der Speicherlatenzen gegenüber den in Naples gemessenen Werten bei. Darüber hinaus kann die CPU als eine einzige NUMA-Domäne konfiguriert werden, sodass ein einheitlicher Speicherzugriff für alle Cores im Sockel möglich ist. Dies wird im Folgenden näher erläutert.
Die vier logischen Quadranten in einem Rome-Prozessor ermöglichen die Partitionierung der CPU in verschiedene NUMA-Domänen. Diese Einstellung wird als NUMA pro Sockel oder NPS bezeichnet.
- NPS1 gibt an, dass die Rome-CPU eine einzelne NUMA-Domäne ist, in der sich alle Cores im Sockel und der gesamte Arbeitsspeicher befinden. Der Arbeitsspeicher ist über die acht Speicherkanäle hinweg verschachtelt. Alle PCIe-Geräte auf dem Sockel gehören zu dieser einen NUMA-Domäne.
- NPS2 teilt die CPU in zwei NUMA-Domänen auf, in denen sich jeweils die Hälfte der Cores und die Hälfte der Arbeitsspeicherkanäle auf dem Sockel befinden. Der Arbeitsspeicher ist über die vier Speicherkanäle in jeder NUMA-Domäne verschachtelt.
- NPS4 teilt die CPU in vier NUMA-Domänen auf. Jeder Quadrant ist hier eine NUMA-Domäne und der Arbeitsspeicher ist über die beiden Arbeitsspeicherkanäle in jedem Quadranten verschachtelt. PCIe-Geräte befinden sich lokal in einer der vier NUMA-Domänen auf dem Sockel, je nachdem, in welchem Quadranten des I/O-Chips sich der PCIe-Stamm für dieses Gerät befindet.
- Nicht alle CPUs unterstützen alle NPS-Einstellungen.
Sofern verfügbar, wird für HPC NPS4 empfohlen, da dies die beste Speicherbandbreite und die niedrigsten Speicherlatenzen verspricht und unsere Anwendungen in der Regel NUMA-fähig sind. Wenn NPS4 nicht verfügbar ist, empfehlen wir die höchste NPS-Einstellung, die vom CPU-Modell unterstützt wird: NPS2 oder sogar NPS1.
Angesichts der Vielzahl an NUMA-Optionen auf Rome-basierten Plattformen ermöglicht das PowerEdge-BIOS zwei verschiedene Core-Aufzählungsmethoden im Rahmen der MADT-Aufzählung. Bei der linearen Aufzählung werden die Cores der Reihe nach nummeriert, wobei zuerst ein CCX, dann ein CCD und dann ein Sockel ausgefüllt und anschließend zum nächsten Sockel gewechselt wird. Bei einer 32-Core-CPU befinden sich die Cores 0 bis 31 auf dem ersten Sockel und die Cores 32 bis 63 auf dem zweiten Sockel. Bei der Rundlaufaufzählung werden die Cores über NUMA-Regionen hinweg nummeriert. In diesem Fall befinden sich die Cores mit geraden Nummern auf dem ersten Sockel und die Cores mit ungeraden Nummern auf dem zweiten Sockel. Der Einfachheit halber empfiehlt sich für HPC eine lineare Aufzählung. Abbildung 5 zeigt ein Beispiel für eine lineare Core-Aufzählung bei einem 64-Core-Server mit zwei Sockeln, der mit NPS4 konfiguriert ist. In der Abbildung ist jedes Feld mit vier Cores ein CCX und jeder Satz mit acht zusammenhängenden Cores ein CCD.
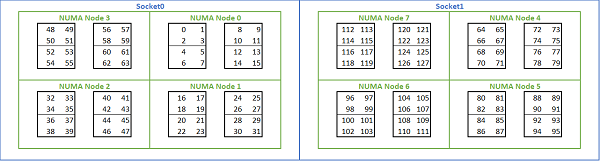
(Abbildung 5: Lineare Core-Aufzählung auf einem System mit zwei Sockeln, 64 Cores pro Sockel und NPS4-Konfiguration bei einem Modell mit 8 CCD-CPUs)
Eine weitere Rome-spezifische BIOS-Option nennt sich Bevorzugtes I/O-Gerät. Dies ist eine wichtige Tuning-Einstellung für die InfiniBand-Bandbreite und -Nachrichtenraten. Sie ermöglicht der Plattform, den Datenverkehr für ein I/O-Gerät zu priorisieren. Diese Option ist auf Rome-Plattformen mit einem und zwei Sockeln verfügbar. Das InfiniBand-Gerät auf der Plattform muss im BIOS-Menü als bevorzugtes Gerät festgelegt werden, um die volle Nachrichtenrate zu erreichen, wenn alle CPU-Cores aktiv sind.
Ähnlich wie Naples unterstützt auch Rome Hyper-Threading bzw. logische Prozessoren. Für HPC lassen wir diese Option deaktiviert. Es gibt jedoch Anwendungen, die von der Aktivierung des logischen Prozessors profitieren. Dies wird in einem nachfolgenden Blog zu molekulardynamischen Anwendungen thematisiert.
Ähnlich wie bei Naples sind auch in Rome CCX als NUMA-Domänen zulässig. Mit dieser Option wird jeder CCX als NUMA-Node verfügbar gemacht. Auf einem System mit 2-Sockel-CPUs und 16 CCXs pro CPU macht diese Einstellung 32 NUMA-Domänen verfügbar. In diesem Beispiel verfügt jeder Sockel über acht CCDs, also 16 CCX. Jeder CCX kann als eigene NUMA-Domäne aktiviert werden, sodass sich 16 NUMA-Nodes pro Sockel bzw. 32 in einem System mit zwei Sockeln ergeben. Für HPC empfiehlt es sich, CCX als NUMA-Domäne auf der Standardoption deaktiviert zu belassen. Das Aktivieren dieser Option soll in virtualisierten Umgebungen hilfreich sein.
Ähnlich wie bei Naples kann das System mit Rome in die Modi Performancedeterminismus oder Stromdeterminismus versetzt werden. Beim Performancedeterminismus arbeitet das System mit der für das CPU-Modell erwarteten Frequenz, wodurch Schwankungen über mehrere Server hinweg reduziert werden. Beim Stromdeterminismus arbeitet das System mit der maximal verfügbaren TDP für das CPU-Modell. Dies verstärkt Abweichungen zwischen den einzelnen Teilen im Fertigungsprozess, sodass einige Server schneller sind als andere. Alle Server können die maximale Nennleistung der CPU verbrauchen, sodass der Stromverbrauch deterministisch ist, zwischen mehreren Servern jedoch Performanceschwankungen möglich sind.
Wie von PowerEdge-Plattformen gewohnt, verfügt das BIOS über eine Meta-Option namens Systemprofil. Durch Auswahl des performanceoptimierten Systemprofils werden der Turbo-Boost-Modus aktiviert, C-States deaktiviert und der Determinismus-Schieberegler auf „Stromdeterminismus“ gesetzt, um die Performance zu optimieren.
Performanceergebnisse – STREAM-, HPL-, InfiniBand-Mikrobenchmarks
Viele unserer LeserInnen sind wahrscheinlich direkt zu diesem Abschnitt gesprungen, also tauchen wir gleich ein.
Im HPC and AI Innovation Lab haben wir einen Rome-basierten Cluster mit 64 Servern erstellt, den wir Minerva getauft haben. Neben dem homogenen Minerva-Cluster haben wir noch ein paar weitere Systeme mit Rome-CPU zur Evaluierung erstellt. Unsere Testumgebung ist in Tabelle 1 und 2 beschrieben.
(Tabelle 1: In dieser Untersuchung evaluierte Rome-CPU-Modelle)
| CPU | Cores pro Sockel | Konfiguration | Basistakt | TDP |
|---|---|---|---|---|
| 7702 | 64c | 4 Cores pro CCX | 2,0GHz | 200 W |
| 7502 | 32c | 4 Cores pro CCX | 2,5 GHz | 180 W |
| 7452 | 32c | 4 Cores pro CCX | 2,35GHz | 155 W |
| 7402 | 24c | 3 Cores pro CCX | 2,8 GHz | 180 W |
(Tabelle 2: Testumgebung)
| Komponente | Details |
|---|---|
| Server | PowerEdge C6525 |
| Prozessor | Zwei Sockel, wie in Tabelle 1 dargestellt |
| Arbeitsspeicher | 256 GB, 16 x 16 GB, 3.200 MT/s DDR4 |
| Interconnect | ConnectX-6 Mellanox Infini Band HDR100 |
| Betriebssystem | Red Hat Enterprise Linux 7.6 |
| Kernel | 3.10.0.957.27.2.e17.x86_64 |
| Festplatte | 240-GB-SATA-SSD-M.2-Modul |
STREAM
Die Arbeitsspeicher-Bandbreitentests mit Rome sind in Abbildung 6 dargestellt. Diese Tests wurden im NPS4-Modus durchgeführt. Wir haben auf unserem PowerEdge C6525 mit zwei Sockeln mit den in Tabelle 1 aufgeführten vier CPU-Modellen ca. 270–300 GB/s an Speicherbandbreite gemessen, wenn alle Cores im Server verwendet werden. Wenn nur ein Core pro CCX verwendet wird, ist die Systemspeicherbandbreite ca. 9–17 % höher als die Bandbreite, die mit allen Cores gemessen wird.
Die meisten HPC-Workloads werden entweder alle Cores im System vollständig belegen oder HPC Center werden im Hochdurchsatzmodus mit mehreren Jobs pro Server ausgeführt. Daher ist die Speicherbandbreite aller Cores die genauere Darstellung der Speicherbandbreite sowie der Speicherbandbreite pro Core des Systems.
Abbildung 6 zeigt auch die gemessene Speicherbandbreite der EPYC-Naples-Plattform der vorherigen Generation, die ebenfalls acht Speicherkanäle pro Sockel unterstützt, aber mit 2.667 MT/s ausgeführt wird. Die Rome-Plattform bietet eine 5–19 % höhere Gesamtspeicherbandbreite als Naples, was hauptsächlich auf den schnelleren Arbeitsspeicher mit 3.200 MT/s zurückzuführen ist. Selbst mit 64 Cores pro Sockel kann das Rome-System mehr als 2 GB/s pro Core liefern.
Beim Vergleich der verschiedenen NPS-Konfigurationen wurde eine ca. 13 % höhere Speicherbandbreite mit NPS4 im Vergleich zu NPS1 gemessen, wie in Abbildung 7 dargestellt.
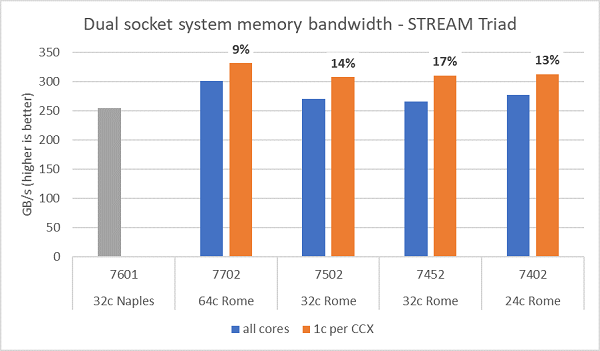
(Abbildung 6: STREAM-Triad-Speicherbandbreite bei zwei Sockeln und NPS4)
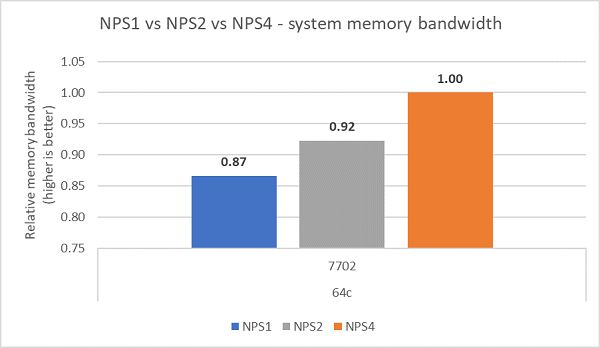
(Abbildung 7: Speicherbandbreite mit NPS1 vs. NPS2 vs. NPS4)
InfiniBand-Bandbreite und -Nachrichtenrate
In Abbildung 8 ist die InfiniBand-Bandbreite mit einem Core bei unidirektionalen und bidirektionalen Tests dargestellt. In der Testumgebung wurde HDR100 mit 100 Gbit/s verwendet. Das Diagramm zeigt die erwartete Performance bei voller Bandbreite bei diesen Tests.
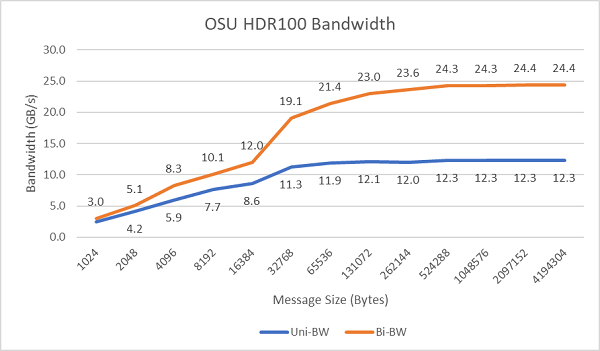
Abbildung 8: InfiniBand-Bandbreite (ein Core)
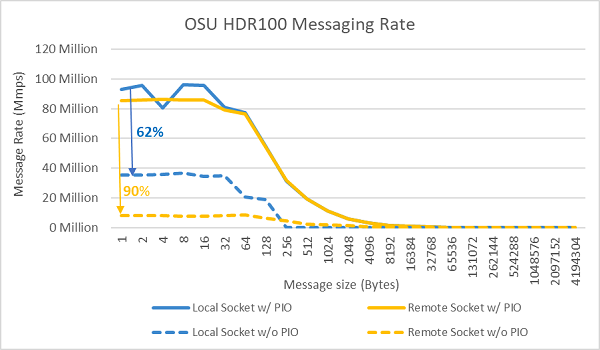
Abbildung 9: InfiniBand-Nachrichtenrate (alle Cores)
Als Nächstes wurden auf beiden Testservern Tests zur Nachrichtenrate mit allen Cores auf einem Sockel durchgeführt. Wenn im BIOS „Bevorzugtes I/O-Gerät“ aktiviert und der ConnectX-6 HDR100-Adapter als bevorzugtes Gerät konfiguriert wurde, ist die Nachrichtenrate mit allen Cores höher als wenn „Bevorzugtes I/O-Gerät“ nicht aktiviert ist, wie in Abbildung 9 dargestellt. Dies verdeutlicht die Bedeutung dieser BIOS-Option beim Tuning für HPC und insbesondere für die Skalierbarkeit von Multi-Node-Anwendungen.
HPL
Die Rome-Mikroarchitektur kann 16 DP-FLOPS/Zyklus erreichen, doppelt so viele wie Naples mit 8 FLOPS/Zyklus. Damit erzielt Rome das 4-fache an theoretischen Spitzen-FLOPS gegenüber Naples, die Hälfte davon durch die erweiterte Gleitkommafähigkeit und die andere Hälfte durch die doppelte Anzahl an Cores (64 vs. 32 Cores). Abbildung 10 zeigt die für die vier getesteten Rome-CPU-Modelle gemessenen HPL-Ergebnisse zusammen mit unseren vorherigen Ergebnissen eines Naples-basierten Systems. Die HPL-Effizienz von Rome wird als Prozentwert über den Balken im Diagramm angegeben und ist bei CPU-Modellen mit niedrigerer TDP höher.
Die Tests wurden im Stromdeterminismus-Modus ausgeführt und bei 64 identisch konfigurierten Servern wurde ein Performancedelta von ca. 5 % gemessen. Die Ergebnisse liegen also in diesem Performanceband.
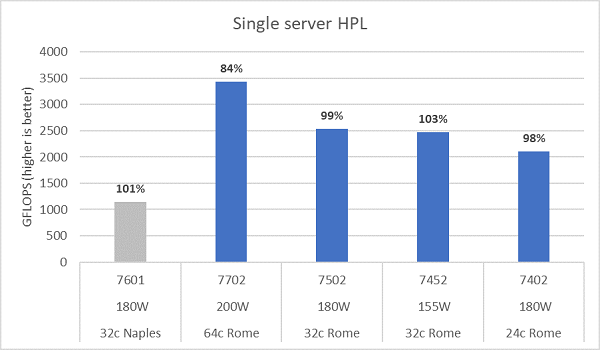
(Abbildung 10: Einzelserver-HPL mit NPS4)
Als Nächstes wurden Multi-Node-HPL-Tests durchgeführt, deren Ergebnisse in Abbildung 11 dargestellt sind. Die HPL-Effizienzen für EPYC 7452 bleiben bei einem Umfang von 64 Nodes über 90 %, allerdings müssen die Effizienzeinbrüche von 102 % auf 97 % und wieder auf 99 % weiter untersucht werden.
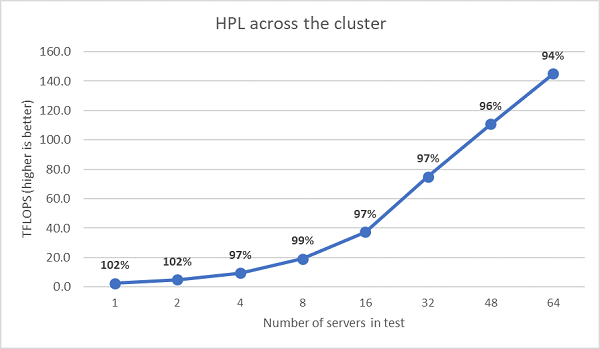
(Abbildung 11: Multi-Node-HPL, EPYC 7452 mit zwei Sockeln über HDR100-InfiniBand)
Zusammenfassung und nächste Schritte:
Erste Performanceuntersuchungen mit Rome-basierten Servern zeigen bei unserer ersten HPC-Benchmark-Reihe die erwartete Performance. BIOS-Tuning spielt bei der Konfiguration für optimale Performance eine wichtige Rolle. In unserem BIOS-HPC-Workload-Profil sind Tuning-Optionen verfügbar, die werkseitig konfiguriert oder mithilfe von Dell EMC Systemmanagementdienstprogrammen eingestellt werden können.
Das HPC and AI Innovation Lab hat einen neuen Rome-basierten PowerEdge-Cluster mit 64 Servern namens Minerva erstellt. Behalten Sie diesen Bereich für weitere Blogs im Auge, die sich mit der Anwendungsperformance unseres neuen Minerva-Clusters beschäftigen werden.