PowerEdge: AMD Rome - Architettura e prestazioni HPC iniziali
Summary: Nel mondo dell'HPC di oggi, ecco il processore EPYC AMD di nuova generazione, con nome in codice Rome.
Instructions
Garima Kochhar, Deepthi Cherlopalle, Joshua Weage. HPC and AI Innovation Lab, ottobre 2019
Nel mondo dell'HPC di oggi, il processore EPYC AMD di nuova generazione, con nome in codice Rome, non ha bisogno di presentazioni. Negli ultimi mesi abbiamo valutato i sistemi basati su Rome nell'HPC and AI Innovation Lab
e Dell Technologies ha recentemente annunciato
l'introduzione di server che supportano questa architettura di processori. Questo primo blog della serie su Rome illustra l'architettura dei processori Rome e come può essere ottimizzata per le prestazioni HPC; presenta inoltre le prestazioni iniziali di un microbenchmark. I blog successivi descrivono le prestazioni delle applicazioni nei domini di CFD, CAE, dinamica molecolare, simulazione meteorologica e di altro tipo.
Architettura
Rome è la CPU EPYC di seconda generazione di AMD, evoluzione diretta della prima generazione, Naples.
Una delle principali differenze a livello di architettura tra Naples e Rome che beneficia l'HPC è la nuova matrice IO di Rome. In Rome, ogni processore è un pacchetto multichip composto da un massimo di nove chiplet, come illustrato nella Figura 1. È presente una matrice di IO centrale da 14 nm che contiene tutte le funzioni di IO e memoria, come i controller di memoria, i collegamenti Infinity Fabric all'interno del socket, la connettività tra socket e le interfacce PCI-e. Ogni socket dispone di otto controller di memoria che supportano otto canali di memoria DDR4 a 3.200 MT/s. Un server a socket singolo può supportare fino a 130 corsie PCIe Gen4. Un sistema a due socket può supportare fino a 160 corsie PCIe Gen4.
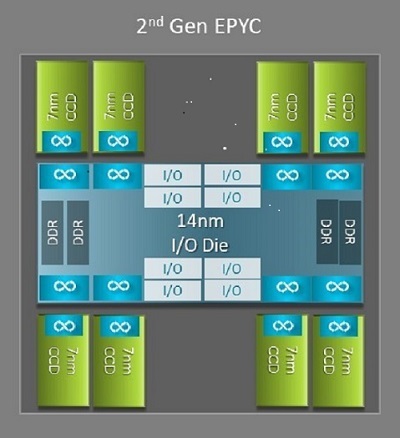
Figura 1 Package multichip di Rome con una matrice di IO centrale e fino a otto matrici core
Attorno alla matrice IO centrale sono presenti fino a otto chiplet core a 7 nm. Il chiplet core è chiamato Core Cache Die o CCD. Ogni CCD ha core CPU basati sulla microarchitettura Zen2, con memorie cache L2 e L3 da 32 MB. Il CCD stesso ha due Core Cache Complex (CCX), ciascuno dei quali presenta fino a quattro core e 16 MB di memoria cache L3. La Figura 2 mostra un CCX.

Figura 2 Un CCX con quattro core e 16 MB di memoria cache L3 condivisa
I vari modelli di CPU di Rome hanno numeri di core diversi
, ma tutti condividono un'unica matrice di IO centrale.
Nell'estremità superiore è presente un modello di CPU a 64 core, ad esempio EPYC 7702. L'output di Lstopo ci mostra che questo processore ha 16 CCX per socket, ciascuno con quattro core, come illustrato nelle Figure 3 e 4, per un totale di 64 core per socket. 16 MB di memoria cache L3 per CCX, pari a 32 MB di memoria cache L3 per CCD, portano questo processore ad avere 256 MB di memoria cache L3 complessiva. Tuttavia, la memoria cache L3 totale di Rome non è condivisa da tutti i core. La memoria cache L3 da 16 MB in ciascun CCX è indipendente e condivisa solo dai core del CCX, come illustrato nella Figura 2.
Una CPU con 24 core come EPYC 7402 ha una memoria cache L3 da 128 MB. L'output di Lstopo nelle Figure 3 e 4 mostra che questo modello ha tre core per CCX e otto CCX per socket.
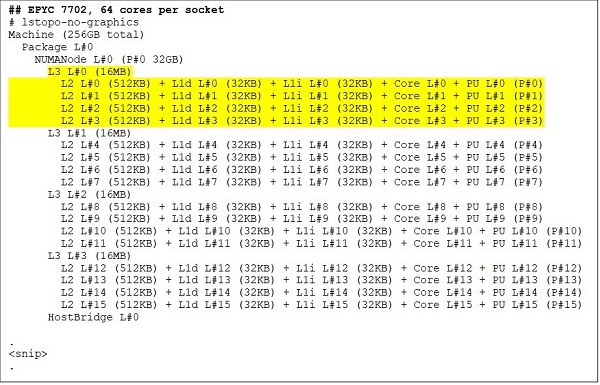
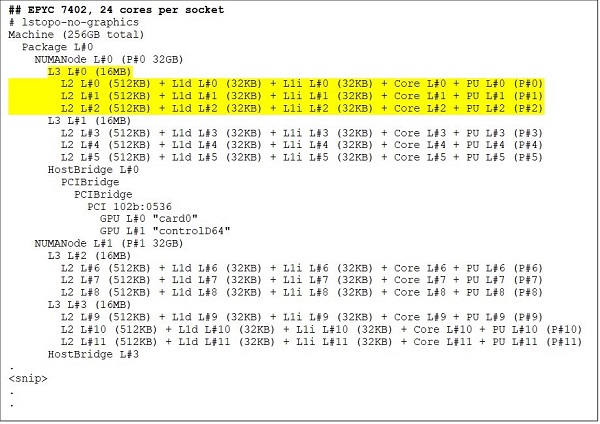
Figure 3 e 4 Output di Lstopo per CPU con 64 e 24 core
Indipendentemente dal numero di CCD, ogni processore di Rome è logicamente diviso in quattro quadranti, con CCD distribuiti il più uniformemente possibile tra i quadranti e due canali di memoria in ciascun quadrante. La matrice di IO centrale può essere considerata come un supporto logico dei quattro quadranti del socket.
Opzioni del BIOS basate sull'architettura di Rome
La matrice di IO centrale in Rome contribuisce a migliorare le latenze della memoria rispetto a quelle misurate in Naples. Inoltre, consente alla CPU di essere configurata come un singolo dominio NUMA, garantendo un accesso uniforme alla memoria per tutti i core del socket, come spiegato di seguito.
I quattro quadranti logici di un processore di Rome consentono di partizionare la CPU in diversi domini NUMA. Questa impostazione è chiamata NUMA per socket o NPS.
- NPS1 implica che la CPU di Rome sia un singolo dominio NUMA, con tutti i core nel socket e tutta la memoria in questo unico dominio NUMA. La memoria è distribuita in modalità interleaving tra gli otto canali di memoria. Tutti i dispositivi PCIe sul socket appartengono a questo singolo dominio NUMA
- NPS2 partiziona la CPU in due domini NUMA, con metà dei core e metà dei canali di memoria sul socket in ciascun dominio NUMA. La memoria è distribuita in modalità interleaving tra i quattro canali di memoria in ciascun dominio NUMA
- NPS4 partiziona la CPU in quattro domini NUMA. Ogni quadrante è un dominio NUMA e la memoria è distribuita in modalità interleaving tra i due canali di memoria in ciascun quadrante. I dispositivi PCIe sono locali a uno dei quattro domini NUMA sul socket, a seconda del quadrante della matrice di IO che ospita la root PCIe per tale dispositivo
- Non tutte le CPU possono supportare tutte le impostazioni NPS
Laddove disponibile, è consigliabile la configurazione NPS4 per HPC poiché dovrebbe fornire la migliore larghezza di banda della memoria, le latenze di memoria più basse e le nostre applicazioni tendono a essere ottimizzare per NUMA. Se NPS4 non è disponibile, consigliamo di utilizzare il valore NPS più alto supportato dal modello di CPU: NPS2 o anche NPS1.
Data la moltitudine di opzioni NUMA disponibili sulle piattaforme basate su Rome, il BIOS PowerEdge consente due diversi metodi di enumerazione dei core in base all'enumerazione MADT. L'enumerazione lineare assegna i numeri ai core in ordine, riempiendo un CCX, un CCD e un socket prima di passare al socket successivo. Su una CPU a 32 core, i core da 0 a 31 si trovano nel primo socket, i core da 32 a 63 nel secondo socket. L'enumerazione Round Robin distribuisce i numeri dei core tra le regioni NUMA. In questo caso, i core con numero pari si trovano sul primo socket, quelli con numero dispari sul secondo socket. Per semplicità, consigliamo l'enumerazione lineare per HPC. Vedere la Figura 5 per un esempio di enumerazione lineare dei core su un server con 64 core a due socket configurato in NPS4. Nella figura, ogni riquadro di quattro core rappresenta un CCX, ogni set di otto core contigui è un CCD.
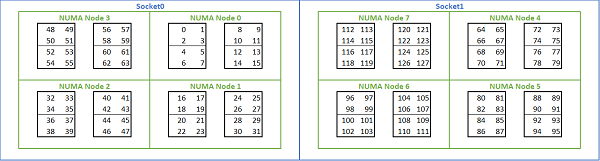
Figura 5 Enumerazione lineare dei core su un sistema con due socket, 64 core per socket, configurazione NPS4 su un modello di CPU con otto CCD
Un'altra opzione del BIOS specifica per Rome è denominata Preferred IO Device. Si tratta di un importante parametro di ottimizzazione per la larghezza di banda e la frequenza dei messaggi InfiniBand. Consente alla piattaforma di dare priorità al traffico per un dispositivo IO specifico. Questa opzione è disponibile sulle piattaforme Rome a uno e due socket e il dispositivo InfiniBand nella piattaforma deve essere selezionato come preferito nel menu del BIOS per ottenere la massima frequenza di messaggi quando tutti i core della CPU sono attivi.
Come per Naples, anche Rome supporta l'hyper-threading o processore logico. Per HPC, lasciamo questa funzione disabilitata, ma alcune applicazioni possono trarne beneficio se abilitata. Seguire i nostri prossimi blog dedicati agli studi sulle applicazioni di dinamica molecolare.
Analogamente a Naples, anche Rome offre l'opzione CCX as NUMA Domain. Questa opzione espone ogni CCX come un nodo NUMA. In un sistema con CPU a due socket e 16 CCX per CPU, questa impostazione espone 32 domini NUMA. In questo esempio, ogni socket ha otto CCD, ovvero 16 CCX. Ogni CCX può essere abilitato come proprio dominio NUMA, fornendo 16 nodi NUMA per socket e 32 in un sistema a due socket. Per HPC, si consiglia di mantenere l'opzione CCX as NUMA Domain con il valore predefinito disabled. L'abilitazione di questa opzione dovrebbe migliorare gli ambienti virtualizzati.
Come per Naples, Rome consente di configurare il sistema in modalità Performance Determinism o Power Determinism. In Performance Determinism, il sistema opera alla frequenza prevista per il modello di CPU riducendo la variabilità tra più server. In Power Determinism, il sistema funziona al massimo TDP disponibile per il modello di CPU. Questa amplifica le variazioni da parte a parte nel processo di produzione, consentendo ad alcuni server di essere più veloci di altri. Tutti i server possono consumare la potenza massima nominale della CPU, rendendo il consumo energetico deterministico, ma con variazioni delle prestazioni tra più server.
Come ci si aspetta dalle piattaforme PowerEdge, il BIOS include un'opzione meta denominata System Profile. Selezionando il profilo di sistema Performance-Optimized, si abilita la modalità turbo boost, si disabilitano gli stati C e si imposta il cursore di determinismo su Power Determinism, ottimizzando il sistema per le massime prestazioni.
Risultati delle prestazioni: microbenchmark STREAM, HPL, InfiniBand
Molti dei nostri lettori potrebbero essere passati direttamente a questa sezione, quindi entriamo subito nel vivo.
In HPC and AI Innovation Lab abbiamo creato un cluster basato su Rome con 64 server, che chiamiamo Minerva. Oltre al cluster omogeneo Minerva, abbiamo altri campioni di CPU di Rome da poter valutare. Il nostro banco di prova è descritto nelle Tabelle 1 e 2.
Tabella 1 Modelli CPU di Rome valutati in questo studio
| CPU | Core per socket | Config | Clock base | TDP |
|---|---|---|---|---|
| 7702 | 64c | 4c per CCX | 2,0 GHz | 200 W |
| 7502 | 32c | 4c per CCX | 2,5 GHz | 180 W |
| 7452 | 32c | 4c per CCX | 2,35 GHz | 155 W |
| 7402 | 24c | 3c per CCX | 2,8 GHz | 180 W |
Tabella 2 Banco di prova
| Componente | Dettagli |
|---|---|
| Server | PowerEdge C6525 |
| Processore | Come illustrato nella Tabella 1, due socket |
| Memoria | 256 GB, 16 da 16 GB, DDR4 a 3.200 MT/s |
| Interconnessione | ConnectX-6 Mellanox Infiniband HDR100 |
| Sistema operativo | Red Hat Enterprise Linux 7.6 |
| Kernel | 3.10.0.957.27.2.e17.x86_64 |
| Disco | Modulo M.2 SATA SSD da 240 GB |
STREAM
I test sulla larghezza di banda della memoria in Rome sono mostrati nella Figura 6; questi test sono stati eseguiti in modalità NPS4. Abbiamo misurato una larghezza di banda della memoria di circa 270-300 GB/s sul nostro PowerEdge C6525 a due socket utilizzando tutti i core del server nei quattro modelli di CPU elencati nella Tabella 1. Quando viene utilizzato un solo core per CCX, la larghezza di banda della memoria di sistema è circa il 9-17% superiore rispetto a quella misurata con tutti i core.
La maggior parte dei carichi di lavoro HPC sfrutta completamente tutti i core del sistema oppure i centri HPC operano in modalità a throughput elevato con più processi su ciascun server. Pertanto, la larghezza di banda della memoria con tutti i core rappresenta una stima più accurata delle capacità di larghezza di banda della memoria totale e per core del sistema.
La Figura 6 mostra anche la larghezza di banda della memoria misurata sulla piattaforma EPYC Naples della generazione precedente, che supporta anch'essa otto canali di memoria per socket, ma a 2.667 MT/s. La piattaforma Rome offre una larghezza di banda totale della memoria dal 5% al 19% superiore rispetto a Naples, principalmente grazie alla memoria più veloce a 3.200 MT/s. Anche con 64 core per socket, il sistema Rome è in grado di offrire oltre 2 Gb/s per core.
Confrontando le diverse configurazioni NPS, con NPS4 è stata misurata una larghezza di banda della memoria circa del 13% superiore rispetto a NPS1, come illustrato nella Figura 7.
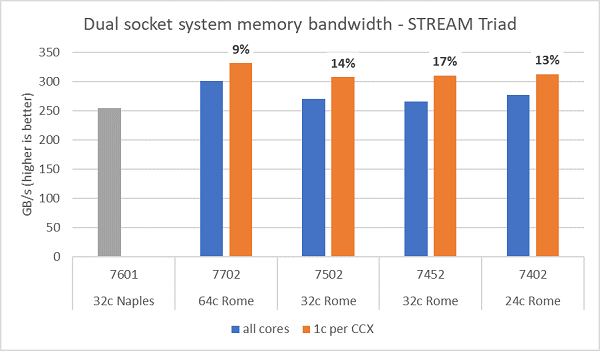
Figura 6 Larghezza di banda della memoria STREAM Triad su un sistema a due socket con configurazione NPS4
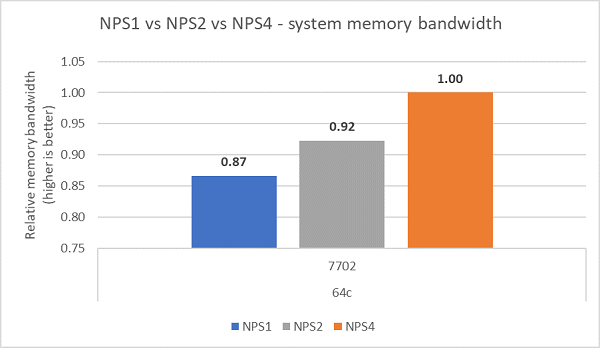
Figura 7 Larghezza di banda della memoria con NPS1, NPS2 e NPS 4
Larghezza di banda InfiniBand e frequenza dei messaggi
La Figura 8 mostra la larghezza di banda InfiniBand a singolo core per i test unidirezionali e bidirezionali. Il banco di prova utilizzava HDR100 a 100 Gb/s e il grafico mostra le prestazioni previste a piena velocità di linea per questi test.
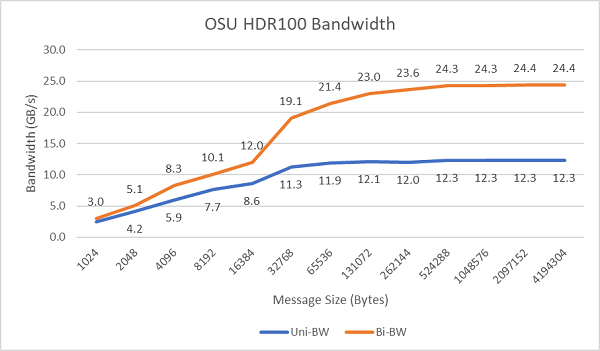
Figura 8 Larghezza di banda InfiniBand (un core)
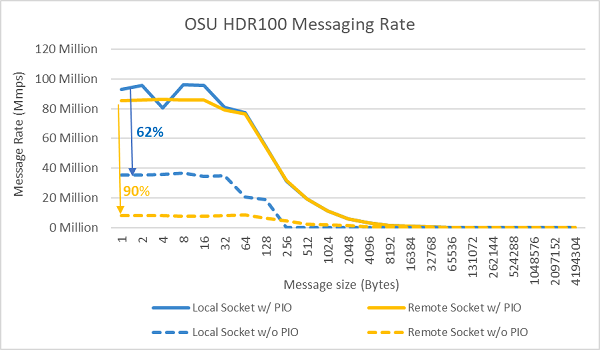
Figura 9 Frequenza dei messaggi InfiniBand (tutti i core)
I test sulla frequenza di invio dei messaggi sono stati condotti successivamente utilizzando tutti i core di un socket nei due server in esame. Quando l'opzione Preferred IO è abilitata nel BIOS e l'adattatore ConnectX-6 HDR100 è configurato come dispositivo preferito, la frequenza dei messaggi con tutti i core è superiore rispetto a quando l'opzione non è abilitata, come mostrato nella Figura 9. Questo evidenzia l'importanza dell'opzione del BIOS nell'ottimizzazione per ambienti HPC, in particolare per la scalabilità delle applicazioni multinodo.
HPL
La microarchitettura di Rome è in grado di ritirare 16 operazioni in virgola mobile in doppia precisione (DP FLOP) per ciclo, ovvero il doppio rispetto a Naples, che ne supportava 8 per ciclo. Questo conferisce a Rome una potenza teorica di picco 4 volte superiore rispetto a Naples: 2 volte grazie alle capacità di calcolo in virgola mobile potenziate e 2 volte grazie al raddoppio del numero di core (64 core rispetto a 32 core). La Figura 10 mostra i risultati misurati con HPL per i quattro modelli di CPU Rome testati, insieme ai risultati ottenuti in precedenza da un sistema basato su Naples. L'efficienza HPL di Rome è indicata come valore percentuale al di sopra delle barre del grafico ed è più elevata per i modelli di CPU con TDP più basso.
I test sono stati eseguiti in modalità Power Determinism e su 64 server configurati in modo identico è stato riscontrato un delta nelle prestazioni di circa il 5%. I risultati riportati rientrano dunque in questo intervallo.
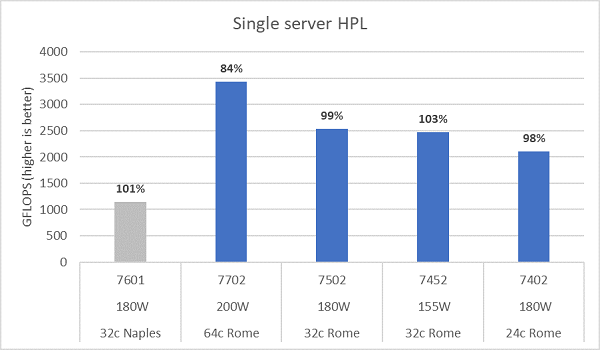
Figura 10 HPL per server singolo in NPS4
Successivamente sono stati eseguiti test HPL multinodo, i cui risultati sono riportati nella Figura 11. Le efficienze HPL per EPYC 7452 rimangono superiori al 90% su una scala di 64 nodi, ma i cali di efficienza dal 102% al 97%, con un successivo aumento al 99%, richiedono ulteriori analisi.
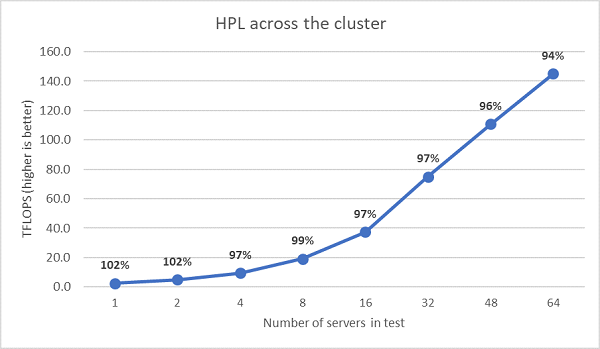
Figura 11 HPL multinodo su un sistema a due socket EPYC 7452 con connessione InfiniBand HDR100
Riepilogo e prossimi sviluppi:
Gli studi iniziali sulle prestazioni dei server basati su Rome mostrano risultati in linea con le aspettative per il nostro primo set di benchmark HPC. L'ottimizzazione del BIOS è fondamentale per configurare il sistema alle massime prestazioni e le opzioni di ottimizzazione sono disponibili nel profilo di carico di lavoro HPC del BIOS, che può essere configurato in fabbrica o impostato tramite le utilità di gestione dei sistemi Dell EMC.
HPC and AI Innovation Lab dispone di un nuovo cluster PowerEdge basato su Rome, chiamato Minerva, composto da 64 server. Nei prossimi blog descriveremo gli studi sulle prestazioni delle applicazioni sul nostro nuovo cluster Minerva.