「PowerEdge:AMD Rome - アーキテクチャと初期HPCパフォーマンス
Summary: HPC Worldから、AMDの最新世代EPYCプロセッサー(コードネーム「Rome」)をご紹介します。
Instructions
Garima Kochhar, Deepthi Cherlopalle, Joshua Weageの詳細を確認してください。HPC & AI Innovation Lab(2019年10月)
今日のHPCの世界では、AMDの最新世代のEPYCプロセッサー(コードネーム:Rome)は、その性能と信頼性から、すでに業界のスタンダードとなっています。弊社はここ数か月、HPCおよびAIイノベーション ラボ
でRomeベースのシステム評価を行ってきましたが、デル・テクノロジーズは最近、このプロセッサーのアーキテクチャをサポートするサーバーを発表
しました。このRomeシリーズの最初のブログでは、Romeプロセッサーのアーキテクチャについて説明し、HPCのパフォーマンスを調整する方法と、初期のマイクロベンチマークの結果を紹介します。今後のブログでは、CFD、CAE、分子動力学、気象シミュレーション、その他のアプリケーションの分野にわたるアプリケーション パフォーマンスについて取り上げていきます。
アーキテクチャ
RomeはAMDの第2世代EPYC CPUであり、第1世代のNaplesを刷新した製品です。
「Naples」と「Rome」のアーキテクチャ上の大きな違いの1つは、Romeの新しいI/Oダイです。これがHPCにメリットをもたらします。Romeでは、図1に示すように、各プロセッサーが最大9個のチップレットで構成されるマルチチップ パッケージとなっています。中央に14nm I/Oダイが1つあり、メモリー コントローラー、ソケット内およびソケット間接続用のInfinity Fabricリンク、PCI-Eなど、すべてのI/O機能とメモリー機能が含まれています。ソケットあたり8個のメモリー コントローラーがあり、3200 MT/sでDDR4を実行する8個のメモリー チャネルをサポートしています。シングルソケット サーバーは、最大130個のPCIe Gen4レーンに対応しています。デュアルソケット システムは、最大160のPCIe Gen4レーンに対応しています。
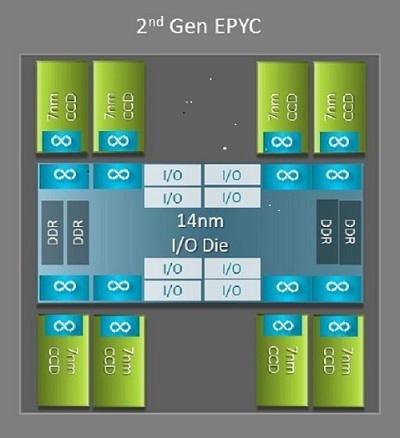
(図1:1つの中央I/Oダイと最大8個のコア ダイを備えたRomeのマルチチップ パッケージ)
中央のI/Oダイの周囲には、最大8個の7nmコア チップレットがあります。コア チップレットは、コア キャッシュ ダイまたはCCDと呼ばれます。各CCDには、Zen2マイクロアーキテクチャに基づくCPUコア、L2キャッシュ、32MB L3キャッシュが搭載されています。CCDには2つのコア キャッシュ コンプレックス(CCX)があり、各CCXは最大4コアと16MBのL3キャッシュを備えています。図2はCCXを示しています。

(図2:4コア、共有16MB L3キャッシュを搭載したCCX)
Rome CPUモデルによってコア数は異なります
が、すべてのCPUモデルに中央のI/Oダイが1つずつあります。
最上位モデルには、たとえばEPYC 7702のような64コアのCPUが搭載されています。Lstopoの出力によると、このプロセッサーにはソケットあたり16個のCCXを搭載しており、図3と4に示すように、各CCXは4個のコアを搭載しているため、1ソケットあたり合計64コアとなります。各CCXには16MBのL3、つまりCCDあたり32MBのL3となるため、このプロセッサーは256MBのL3キャッシュを備えています。ただし、注意すべき点として、RomeのL3キャッシュの合計は、すべてのコアで共有されているわけではありません。各CCXの16MB L3キャッシュは独立しており、図2に示すようにCCXのコアによってのみ共有されます。
24コアCPUであるEPYC 7402は128MBのL3キャッシュを搭載しています。図3と4に示すLstopoの出力から、このモデルにはCCXあたり3コア、ソケットあたり8個のCCXがあることが分かります。
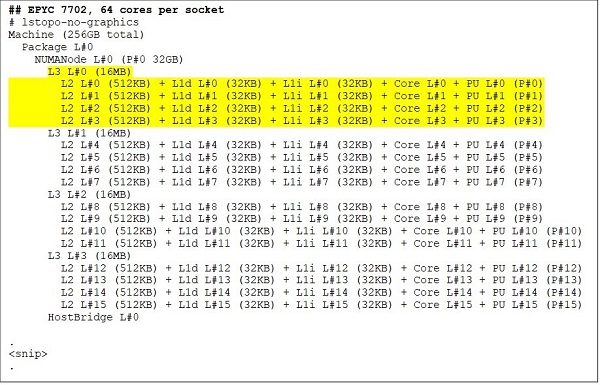
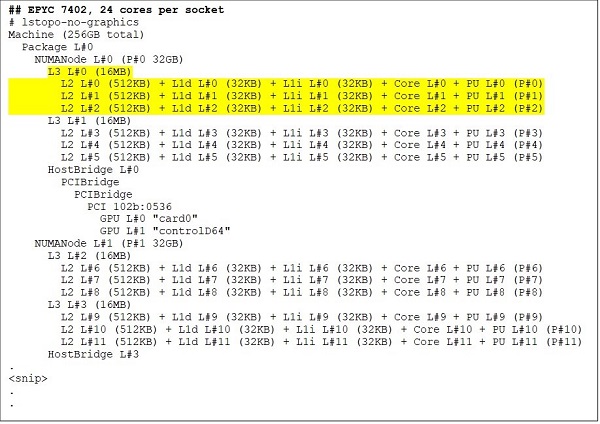
(図3および4)64コアおよび24コアCPUのLstopo出力)
各RomeプロセッサーはCCDの数に関係なく、論理的に4つの区画に分割されています。CCDは可能な限り均等に割り当てられ、各区画には2つのメモリー チャネルが備わっています。中央のI/Oダイは、ソケットの4つの区画を論理的にサポートしていると考えることができます。
Romeアーキテクチャに基づくBIOSオプション
Romeの中央I/Oダイは、Naplesで測定されたものよりもメモリー レイテンシーを改善するのに役立ちます。また、CPUを単一のNUMAドメインとして構成できるため、ソケット内のすべてのコが均一にメモリーへアクセスすることができまできます。これについては以下で説明しています。
Romeプロセッサーの4つの論理区画により、CPUを異なるNUMAドメインに分割することが可能です。この設定は、ソケットあたりのNUMAまたはNPSと呼ばれます。
- NPS1は、Rome CPUが単一のNUMAドメインであり、ソケット内のすべてのコアと、この1つのNUMAドメイン内のすべてのメモリーが含まれることを意味します。メモリーは、8つのメモリー チャネル間でインターリーブされます。ソケット上のすべてのPCIeデバイスは、この単一のNUMAドメインに属しています。
- NPS2ではCPUは2つのNUMAドメインに分割され、各NUMAドメインには、ソケット内の半分のコアと半分のメモリー チャネルが割り当てられます。メモリーは、各NUMAドメインの4つのメモリー チャネル間でインターリーブされます。
- NPS4ではCPUは4つのNUMAドメインに分割されます。ここでは、各区画がNUMAドメインであり、メモリーは各NUMAドメインの2つのメモリー チャネルにインターリーブされます。PCIeデバイスは、I/Oダイのどの区画にそのデバイスのPCIeルートがあるかに応じて、ソケット上の4つのNUMAドメインのいずれかに属します。
- CPUによっては、特定のNPS設定をサポートしていない場合があります。
使用可能な場合は、NPS4は最適なメモリー帯域幅と最小のメモリー レイテンシーを提供することが期待され、また当社のアプリケーションがNUMA対応になる傾向があるため、HPCにはNPS4が推奨されます。NPS4が使用できない場合は、CPUモデルでサポートされている最上位のNPS(NPS2、またはNPS1)を使用することをお勧めします。
Romeベースのプラットフォームで使用可能な多数のNUMAオプションを考慮して、PowerEdge BIOSでは[MADT Core Enumeration]に2つの異なるコアの列挙方法が提供されています。リニア型列挙では、コアに順番に番号を付け、次のソケットに移動する前に1つのCCX、CCD、ソケットが埋まります。32C CPUでは、コア0~31が1番目のソケットにあり、コア32~63が2番目のソケットにあります。ラウンド ロビン型列挙では、NUMAリージョン全体のコアに番号が付けられます。この場合、偶数番号のコアは1番目のソケットにあり、奇数番号のコアは2番目のソケットにあります。簡素化するために、HPCではリニア型列挙を推奨します。NPS4で構成されたデュアルソケット64cサーバーでのリニア コア列挙の例については、図5を参照してください。この図では、4つのコアの各ボックスがCCXで、8つの連続したコアの各セットがCCDです。
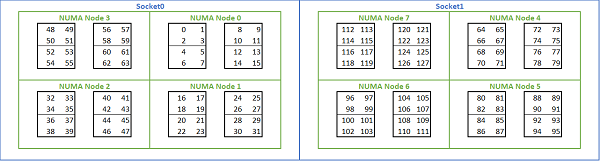
(図5:デュアルソケット システムでのコアのリニア型列挙、8台のCCD CPUモデルでソケットあたり64cのNPS4構成)
Rome固有のもう1つのBIOSオプションは、優先IOデバイスと呼ばれています。これは、InfiniBandの帯域幅とメッセージ レートを調整するための重要な調整ノブです。これにより、プラットフォームが特定のIOデバイスのトラフィックに優先順位を付けて処理できるようになります。このオプションは、1ソケットおよび2ソケットのRomeプラットフォームで使用できます。すべてのCPUコアがアクティブなときにフル メッセージ レートを実現するには、プラットフォーム内のInfiniBandデバイスをBIOSメニューで優先デバイスとして選択する必要があります。
Naplesと同様に、Romeでもハイパースレッディングまたは論理プロセッサーをサポートしています。HPCの場合は、これを無効のままにしておきますが、一部のアプリケーションでは論理プロセッサーを有効にすることでメリットが得られる場合があります。詳細については分子動力学アプリケーション検証に関する今後のブログをぜひご覧ください。
Naplesと同様に、RomeもCCXをNUMAドメインとして構成できます。このオプションは、各CCXをNUMAノードとして認識します。CPUあたり16 CCXのデュアルソケットCPUを搭載したシステムでは、この設定により32個のNUMAドメインが表示されます。この例では、各ソケットに8つのCCD、つまり16 CCXが含まれています。各CCXは、独自のNUMAドメインとして有効にすることができ、ソケットあたり16個のNUMAノード、2ソケット システムで32個のNUMAノードを提供します。HPCの場合は、[CCX as NUMA Domain]をデフォルト オプションの[Disabled]のままにしておくことをお勧めします。このオプションを有効にすると、仮想化環境の改善が期待されます。
Naplesと同様に、Romeではシステムを[Performance Determinism]モードまたは[Power Determinism]モードに設定できます。[Performance Determinism]では、システムはCPUモデルの期待周波数で動作し、複数のサーバー間のばらつきを抑制します。[Power Determinism]では、システムはCPUモデルで利用可能な最大TDPで動作します。これにより、製造プロセスにおける部品間のばらつきが増幅され、一部のサーバーは他のサーバーよりも高速に動作する場合があります。すべてのサーバーはCPUの最大定格電力を消費する可能性があるため、消費電力は安定しますが、複数のサーバー間でパフォーマンスのばらつきが生じる可能性があります。
PowerEdgeプラットフォームから予想されるように、BIOSにはシステム プロファイルと呼ばれるメタ オプションがあります。[Performance-Optimized]システム プロファイルを選択すると、ターボ ブースト モードが有効になり、C-Stateが無効になり、[Determinism]スライダーが[Power Determinism]に設定され、パフォーマンスが最適化されます。
パフォーマンス結果:STREAM、HPL、InfiniBandマイクロベンチマーク
読者の多くはこのセクションに直接移動してきたかもしれませんので、さっそく本題に入ります。
HPCとAIのイノベーションラボでは、64台のサーバーを搭載したRomeベースのクラスターとしてMinervaを構築しました。均質なMinervaクラスターに加えて、評価できるRome CPUサンプルが他にもいくつかあります。テスト環境については表1と表2に記載されています。
(表1:本調査で評価したRome CPUモデル)
| CPU | ソケットあたりのコア数 | Config | ベース クロック | TDP |
|---|---|---|---|---|
| 7702 | 64c | CCXあたり4c | 2.0 GHz | 200 W |
| 7502 | 32c | CCXあたり4c | 2.5 GHz | 180 W |
| 7452 | 32c | CCXあたり4c | 2.35 GHz | 155 W |
| 7402 | 24c | CCXあたり3c | 2.8 GHz | 180 W |
(表2:テスト環境)
| コンポーネント | 詳細 |
|---|---|
| Server | PowerEdge C6525 |
| CPU | デュアルソケット(表1に記載のとおり) |
| メモリー | 256 GB、16 x 16 GB 3200 MT/s DDR4 |
| 内部接続 | ConnectX-6 Mellanox製InfiniBand HDR100 |
| オペレーティングシステム | Red Hat Enterprise Linux 7.6 |
| カーネル | 3.10.0.957.27.2.e17.x86_64 |
| ディスク | 240 GB SATA SSD M.2モジュール |
STREAM
Romeでのメモリー帯域幅テストの詳細は図6に示すとおりです(テストはNPS4モードで実行)。表1に記載されている4つのCPUモデルでサーバー内のすべてのコアを使用した場合、デュアルソケットPowerEdge C6525で最大270~300 GB/秒のメモリー帯域幅が計測されました。CCXごとに1コアのみを使用した場合、システム メモリー帯域幅はすべてのコアで測定された値よりも約9~17%高くなります。
ほとんどのHPCワークロードは、システム内のすべてのコアを完全にサブスクライブするか、HPCセンターを高スループット モードで実行し、各サーバー上で複数のジョブを実行するかのいずれかです。したがって、すべてのコアのメモリー帯域幅が、システムのメモリー帯域幅とコアあたりのメモリー帯域幅をより正確に表す数値となります。
図6は、旧世代のEPYC Naplesプラットフォームで測定されたメモリー帯域幅も示しています。このプラットフォームはソケットあたり8個のメモリー チャネルをサポートし、2667 MT/sで動作しています。RomeプラットフォームはNaplesよりも総メモリー帯域幅が5%から19%向上しており、この要因は主に3200 MT/sの高速メモリーによるものです。ソケットあたり64cであっても、Romeシステムは1コアあたり2 GB/s以上を提供できます。
異なるNPS構成を比較すると、図7に示すように、NPS4ではNPS1と比較して約13%高いメモリー帯域幅が測定されました。
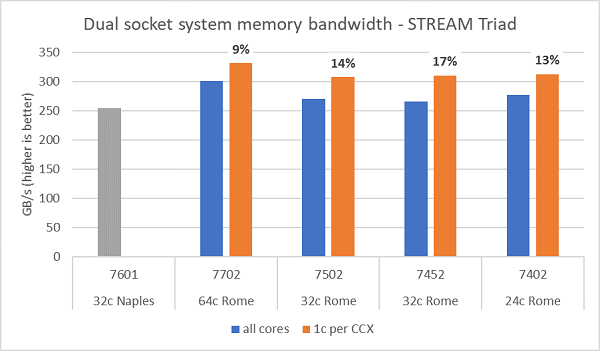
(図6:デュアルソケットNPS4メモリー帯域幅:STREAM Triad)
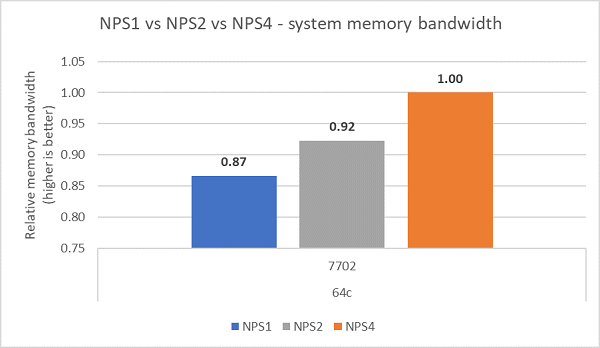
(図7:NPS1とNPS2とNPS 4のメモリー帯域幅)
InfiniBand帯域幅とメッセージ レート
図8は、単方向および双方向テスト用のシングルコアInfiniBand帯域幅を示しています。テスト環境ドでは、100 Gbpsで動作するHDR100を使用し、グラフはこれらのテストで予想されるラインレート パフォーマンスを示しています。
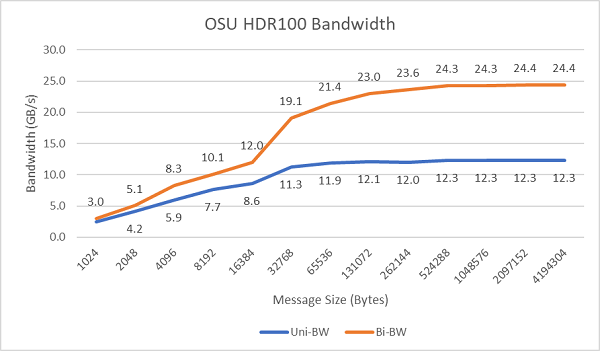
図8 InfiniBand帯域幅(シングルコア)
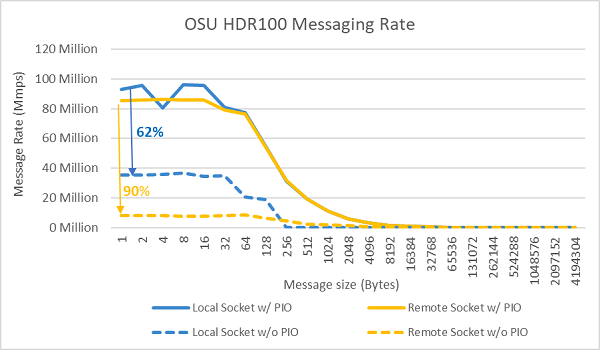
図9:InfiniBandのメッセージ レート(すべてのコア)
次に、テスト対象の2つのサーバーのソケット上で、すべてのコアを使用したメッセージ レートのテストを実施しました。BIOSでPreferred IOが有効化され、ConnectX-6 HDR100アダプターが優先デバイスとして設定されている場合、図9に示されているように、すべてのコア使用時のメッセージ レートはPreferred IOが有効化されていない場合よりも高くなっていることがわかります。これは、HPCでのチューニング、特にマルチノード アプリケーションの拡張性において、このBIOSオプションが重要であることを示しています。
HPL
Romeのマイクロアーキテクチャは16 DP FLOP/サイクルで、Naplesの8 FLOPS/サイクルの2倍です。そのため、理論上、RomeのピークFLOPSはNaplesと比較して4倍、拡張浮動小数点演算能力は2倍、コア数は2倍(64c対32c)になります。図10は、テストした4つのRome CPUモデルで測定されたHPL結果と、Naplesベースのシステムでの以前の結果を示しています。Rome HPLの効率性は、グラフのバー上のパーセンテージ値で示され、TDPが低いCPUモデルほど高くなります。
テストは[Power Determinism]モードで実行され、同じ構成の64台のサーバーで~5%のパフォーマンス差異が測定されました。したがって、ここに示す結果はそのパフォーマンス範囲内にあります。
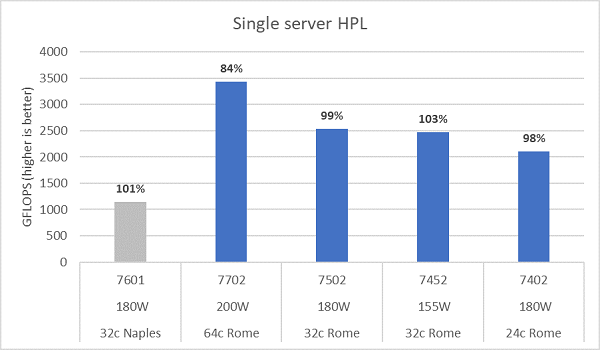
(図10:NPS4のシングル サーバーHPL)
次に、マルチノードHPLテストを実施しました。この結果は図11に示すとおりです。EPYC 7452のHPL効率は、64ノード スケールで90%を超えていますが、効率が102%から97%に低下し、さらに99%に戻っているため、さらなる評価が必要です。
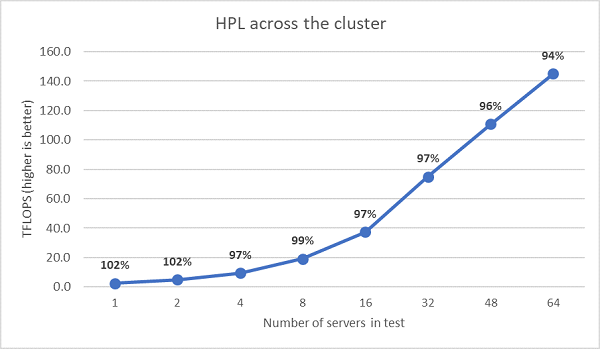
(図11:HDR100 InfiniBand経由のマルチノードHPL、デュアルソケットEPYC 7452)
まとめと今後の予定:
Romeベースのサーバーの初期パフォーマンス調査では、HPCベンチマークの最初の取り組みとして期待どおりの結果が得られました。最適なパフォーマンスを実現するためには、構成時にBIOSのチューニングが重要です。当社のBIOS HPCワークロード プロファイルではチューニング オプションを利用できます。これらは、工場出荷時に構成することも、Dell EMCシステム管理ユーティリティーを使用して設定することもできます。
HPCおよびAIイノベーション ラボでは、Romeをベースとする新しい64サーバーのPowerEdgeクラスターのMinervaを導入しました。当社の新しいMinervaクラスターのアプリケーション パフォーマンスの調査結果については、今後のブログでご紹介いたします。