AMD Roma - er det på ekte? Arkitektur og innledende HPC-ytelse
Summary: I HPC-verden i dag, en introduksjon til AMDs nyeste generasjon EPYC-prosessor kodenavnet Roma.
Symptoms
Garima Kochhar, Deepthi Cherlopalle, Joshua Weage. HPC og AI Innovation Lab, oktober 2019
Cause
Ikke aktuelt
Resolution
I HPC-verdenen i dag trenger AMDs siste generasjon EPYC-prosessor  med kodenavnet Roma knapt en introduksjon. Vi har evaluert Roma-baserte systemer i HPC og AI Innovation Lab de siste månedene, og Dell Technologies annonserte
med kodenavnet Roma knapt en introduksjon. Vi har evaluert Roma-baserte systemer i HPC og AI Innovation Lab de siste månedene, og Dell Technologies annonserte  nylig servere som støtter denne prosessorarkitekturen. Denne første bloggen i Roma-serien diskuterer prosessorarkitekturen i Roma, hvordan den kan justeres for HPC-ytelse og presentere den første mikroreferanseytelsen. Påfølgende blogger beskriver applikasjonsytelse på tvers av domenene CFD, CAE, molekylær dynamikk, værsimulering og andre applikasjoner.
nylig servere som støtter denne prosessorarkitekturen. Denne første bloggen i Roma-serien diskuterer prosessorarkitekturen i Roma, hvordan den kan justeres for HPC-ytelse og presentere den første mikroreferanseytelsen. Påfølgende blogger beskriver applikasjonsytelse på tvers av domenene CFD, CAE, molekylær dynamikk, værsimulering og andre applikasjoner.
Arkitektur
Roma er AMDs 2. generasjon EPYC CPU, som fornyer deres 1. generasjon Napoli.
En av de største arkitektoniske forskjellene mellom Napoli og Roma som gagner HPC er den nye IO-døren i Roma. I Roma er hver prosessor en multi-chip-pakke bestående av opptil 9 brikker som vist i figur.1. Det er en sentral 14nm I/O-dør som inneholder alle I/O- og minnefunksjoner – tenk minnekontrollere, Infinity-strukturkoblinger i kontakten og tilkobling mellom sokler og PCI-e. Det finnes åtte minnekontrollere per sokkel som støtter åtte minnekanaler som kjører DDR4 ved 3200 MT/s. En server med én sokkel kan støtte opptil 130 4. generasjons PCIe-baner. Et system med to sokler kan støtte opptil 160 4. generasjons PCIe-baner.
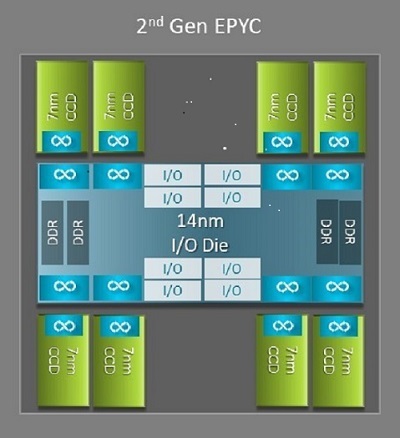
(Figur 1Roma multi-chip pakke med en sentral IO dør og opptil åtte-kjerne dør)
Rundt den sentrale IO-matrisen er opptil åtte 7nm kjernebrikker. Kjernebrikken kalles en Core Cache die eller CCD. Hver CCD har CPU-kjerner basert på Zen2-mikroarkitekturen, L2-cache og 32 MB L3-cache. CCD selv har to Core Cache Complexes (CCX), hver CCX har opptil fire kjerner og 16 MB L3 cache. Figur 2 viser en CCX.
hver CCX har opptil fire kjerner og 16 MB L3 cache. Figur 2 viser en CCX.

(Figur 2 En CCX med fire kjerner og delt 16 MB L3-cache)
De forskjellige Roma CPU-modellene  har forskjellig antall kjerner,
har forskjellig antall kjerner,  men alle har en sentral I/O-dør.
men alle har en sentral I/O-dør.
I den øverste enden er en 64-kjerners CPU-modell, for eksempel EPYC 7702. Lstopo-utgang viser oss at denne prosessoren har 16 CCX per sokkel, hver CCX har fire kjerner som vist i figur.3 &; 4, og gir dermed 64 kjerner per kontakt. 16 MB L3 per CCX som er 32 MB L3 per CCD gir denne prosessoren totalt 256 MB L3 cache. Vær imidlertid oppmerksom på at den totale L3-cachen i Roma ikke deles av alle kjerner. 16MB L3-cachen i hver CCX er uavhengig og deles bare av kjernene i CCX som vist i figur 2.
En 24-kjerners CPU som EPYC 7402 har en 128 MB L3-cache. Lstopo-utgang i figur 3 &; 4 illustrerer at denne modellen har tre kjerner per CCX og 8 CCX per sokkel.
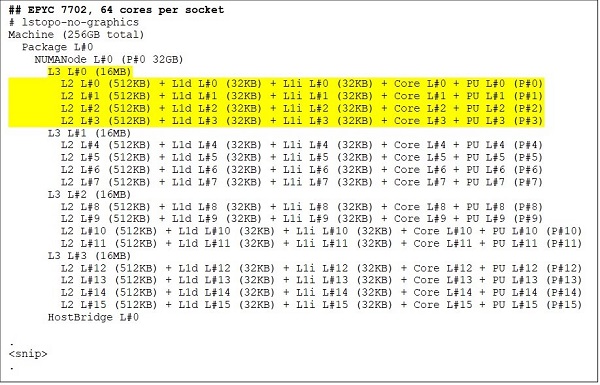
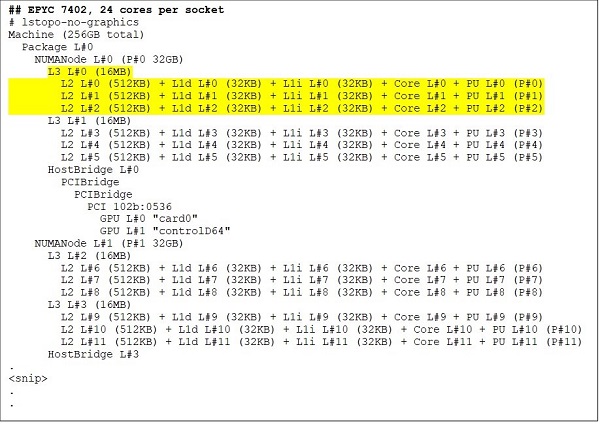
(Figur 3 &; 4 lstopo-utgang for 64-kjerners og 24-kjerners CPUer)
Uansett antall CCD-er, er hver Roma-prosessor logisk delt inn i fire kvadranter med CCD-er fordelt så jevnt over kvadrantene som mulig og to minnekanaler i hver kvadrant. Den sentrale IO-matrisen kan betraktes som logisk støtte for de fire kvadrantene i sokkelen.
BIOS-alternativer basert på Roma-arkitektur
Den sentrale IO-døren i Roma bidrar til å forbedre hukommelsesforsinkelser i forhold til de som måles  i Napoli. Det gjør det også mulig å konfigurere CPUen som et enkelt NUMA-domene som muliggjør ensartet minnetilgang for alle kjernene i kontakten. Dette forklares nedenfor.
i Napoli. Det gjør det også mulig å konfigurere CPUen som et enkelt NUMA-domene som muliggjør ensartet minnetilgang for alle kjernene i kontakten. Dette forklares nedenfor.
De fire logiske kvadrantene i en Roma-prosessor gjør at CPUen kan partisjoneres i forskjellige NUMA-domener. Denne innstillingen kalles NUMA per sokkel eller NPS.
- NPS1 innebærer at Roma CPU er et enkelt NUMA-domene, med alle kjernene i kontakten og alt minnet i dette ene NUMA-domenet. Minnet er flettet inn over de åtte minnekanalene. Alle PCIe-enheter på kontakten tilhører dette ene NUMA-domenet
- NPS2 partisjonerer CPUen i to NUMA-domener, med halvparten av kjernene og halvparten av minnekanalene på kontakten i hvert NUMA-domene. Minnet er sammenflettet over de fire minnekanalene i hvert NUMA-domene
- NPS4 partisjonerer CPUen i fire NUMA-domener. Hver kvadrant er et NUMA-domene her, og minnet er sammenflettet over de to minnekanalene i hver kvadrant. PCIe-enheter er lokale for ett av fire NUMA-domener på sokkelen, avhengig av hvilken kvadrant av I/O-matrisen som har PCIe-roten for den enheten
- Ikke alle prosessorer kan støtte alle NPS-innstillinger
Der det er tilgjengelig, anbefales NPS4 for HPC siden det forventes å gi den beste minnebåndbredden, laveste minneforsinkelser, og applikasjonene våre har en tendens til å være NUMA-klare. Der NPS4 ikke er tilgjengelig, anbefaler vi at den høyeste NPS støttes av CPU-modellen - NPS2, eller til og med NPS1.
På grunn av de mange NUMA-alternativene som er tilgjengelige på Roma-baserte plattformer, tillater PowerEdge BIOS to forskjellige metoder for opplisting av kjerner under MAD-opplisting. Lineær opplisting nummererer kjerner i rekkefølge, fyller en CCX, CCD, stikkontakt før du flytter til neste kontakt. På en 32c CPU vil kjernene 0 til 31 være på den første kontakten, kjernene 32-63 på den andre kontakten. Round robin-opplisting nummererer kjernene på tvers av NUMA-regioner. I dette tilfellet er jevne nummererte kjerner på den første kontakten, oddetallskjerner på den andre kontakten. For enkelhets skyld anbefaler vi lineær opplisting for HPC. Se figur 5 for et eksempel på lineær kjerneopplisting på en 64c-server med to sokler konfigurert i NPS4. I figuren er hver boks med fire kjerner en CCX, hvert sett med åtte sammenhengende kjerner er en CCD.
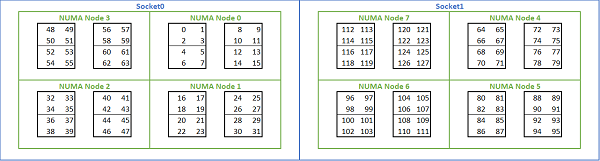
(Figur 5 Lineær kjerneopplisting på et system med to sokler, 64c per sokkel, NPS4-konfigurasjon på en 8 CCD CPU-modell)
Et annet Roma-spesifikt BIOS-alternativ kalles Foretrukket I/O-enhet. Dette er en viktig innstillingsknapp for InfiniBand-båndbredde og meldingshastighet. Den gjør det mulig for plattformen å prioritere trafikk for én I/O-enhet. Dette alternativet er tilgjengelig på Roma-plattformer med én sokkel og to sokler, og InfiniBand-enheten i plattformen må velges som foretrukket enhet i BIOS-menyen for å oppnå full meldingsfrekvens når alle CPU-kjernene er aktive.
I likhet med Napoli støtter Roma også hyper-threadingeller logisk prosessor. For HPC lar vi dette være deaktivert, men noen applikasjoner kan dra nytte av å aktivere logisk prosessor. Se etter våre påfølgende blogger om molekylær dynamikk applikasjonsstudier.
I likhet med Napoli tillater Roma også CCX som NUMA Domain. Dette alternativet eksponerer hver CCX som en NUMA-node. På et system med CPU-er med to sokler med 16 CCX-er per CPU, eksponerer denne innstillingen 32 NUMA-domener. I dette eksemplet har hver stikkontakt 8 CCD-er, det vil si 16 CCX. Hver CCX kan aktiveres som sitt eget NUMA-domene, noe som gir 16 NUMA-noder per sokkel og 32 i et to-sokkelsystem. For HPC anbefaler vi å forlate CCX som NUMA Domain ved standardalternativet deaktivert. Aktivering av dette alternativet forventes å hjelpe virtualiserte miljøer.
I likhet med Napoli tillater Roma at systemet settes i ytelsesdeterminisme eller maktdeterminisme-modus . I ytelsesdeterminisme opererer systemet med forventet frekvens for CPU-modellen, noe som reduserer variasjonen på tvers av flere servere. I strømdeterminisme opererer systemet med maksimal tilgjengelig TDP for CPU-modellen. Dette forsterker del-til-del-variasjon i produksjonsprosessen, slik at noen servere kan være raskere enn andre. Alle servere kan forbruke den maksimale nominelle effekten til CPU, noe som gjør strømforbruket deterministisk, men tillater noe ytelsesvariasjon på tvers av flere servere.
Som du forventer av PowerEdge-plattformer, har BIOS et metaalternativ kalt Systemprofil. Hvis du velger systemprofilen for ytelsesoptimert systemprofil, aktiveres turboforsterkningsmodus, deaktiverer C-tilstander og setter glidebryteren for determinisme til Effektdeterminisme, for å optimere for ytelse.
Ytelsesresultater – STREAM, HPL, InfiniBand mikrobenchmarks
Mange av leserne våre har kanskje hoppet rett til denne delen, så vi vil dykke rett inn.
I HPC og AI Innovation Lab har vi bygget ut en 64-server Roma-basert klynge vi kaller Minerva. I tillegg til den homogene Minerva-klyngen, har vi noen få andre Roma CPU-prøver vi kan evaluere. Vår testbed er beskrevet i tabell 1 og tabell.2.
(Tabell 1 CPU-modeller i Roma evaluert i denne studien)
| CPU | Kjerner per sokkel | Config | Grunnleggende klokkefrekvens | TDP |
|---|---|---|---|---|
| 7702 | 64c | 4c per CCX | 2,0 GHz | 200 W |
| 7502 | 32c | 4c per CCX | 2,5 GHz | 180 W |
| 7452 | 32c | 4c per CCX | 2,35 GHz | 155 W |
| 7402 | 24c | 3c per CCX | 2,8 GHz | 180 W |
(Tabell.2 Testbed)
| Komponent | Detaljer |
|---|---|
| Server | PowerEdge C6525 |
| Prosessor | Som vist i tabell 1 med to sokler |
| Minne | 256 GB, 16 x 16 GB 3200 MT/s DDR4 |
| Interconnect | ConnectX-6 Mellanox Infini Band HDR100 |
| Operativsystem | Red Hat Enterprise Linux 7.6 |
| Kjerne | 3.10.0.957.27.2.e17.x86_64 |
| Disken | 240 GB SATA SSD M.2-modul |
BEKK
Minnebåndbreddetester på Roma er presentert i figur.6, ble disse testene kjørt i NPS4-modus. Vi målte ~270–300 GB/s minnebåndbredde på PowerEdge C6525 med to sokler når vi brukte alle kjernene i serveren på tvers av de fire CPU-modellene som er oppført i tabell. 1. Når bare én kjerne brukes per CCX, er systemminnebåndbredden ~9–17 % høyere enn den som måles for alle kjerner.
De fleste HPC-workloader vil enten abonnere fullstendig på alle kjernene i systemet, eller HPC-sentre kjøre i modus for høy gjennomstrømming med flere jobber på hver server. Derfor er all-core minnebåndbredde den mer nøyaktige representasjonen av minnebåndbredden og minnebåndbredde per kjerne egenskapene til systemet.
Figur 6 plotter også minnebåndbredden målt på forrige generasjons EPYC Napoli-plattform , som også støttet åtte minnekanaler per sokkel, men som kjører på 2667 MT/s. Roma-plattformen gir 5% til 19% bedre total minnebåndbredde enn Napoli, og dette skyldes hovedsakelig det raskere 3200 MT/s-minnet. Selv med 64c per socket, kan Roma-systemet levere opptil 2 GB/s/kjerne.
Ved sammenligning av de ulike NPS-konfigurasjonene ble ~13 % høyere minnebåndbredde målt med NPS4 sammenlignet med NPS1, som vist i figur 7.
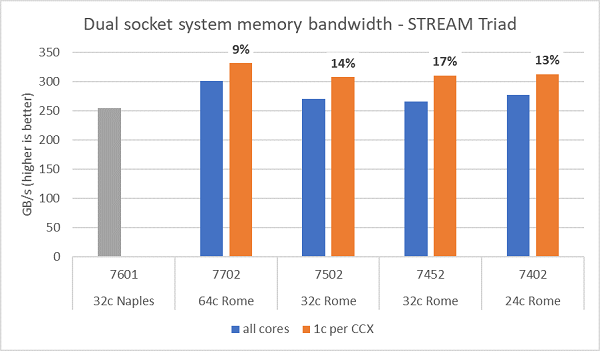
(Figur 6 NPS4 STREAM Triad-minnebåndbredde med to sokler)
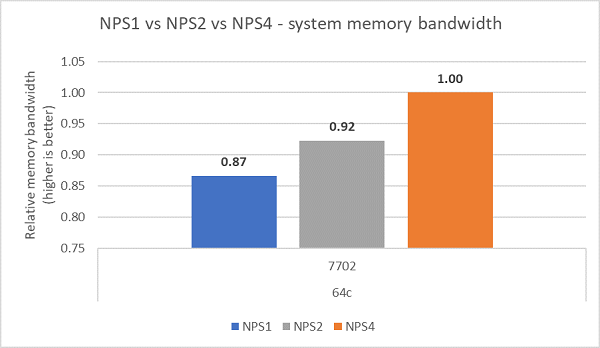
(Figur 7 NPS1 kontra NPS2 kontra NPS 4 Minnebåndbredde)
Båndbredde og meldingshastighet for InfiniBand
Figur 8 plotter InfiniBand-båndbredden med én kjerne for enveis og toveis tester. Testbed brukte HDR100 som kjører på 100 Gbps, og grafen viser forventet linjehastighetsytelse for disse testene.
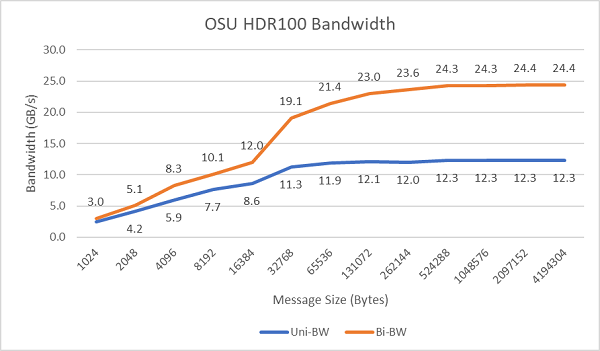
Figur 8 InfiniBand-båndbredde (én kjerne))
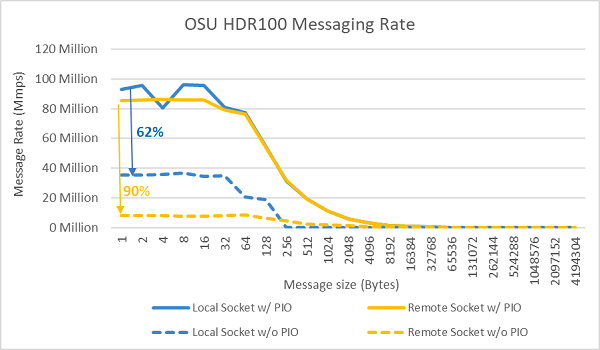
Figur 9 Meldingshastighet for InfiniBand (alle kjerner))
Meldingshastighetstestene ble deretter utført ved hjelp av alle kjernene på en sokkel i de to serverne som ble testet. Når Foretrukket I/O er aktivert i BIOS og ConnectX-6 HDR100-adapteren er konfigurert som foretrukket enhet, er meldingsfrekvensen for alle kjerner betydelig høyere enn når Foretrukket I/O ikke er aktivert, som vist i figur 9. Dette illustrerer viktigheten av dette BIOS-alternativet ved justering for HPC, og spesielt for skalerbarhet for flere noder.
HPL
Romas mikroarkitektur kan pensjonere 16 DP FLOP/syklus, dobbelt så mye som i Napoli som var 8 FLOPS/syklus. Dette gir Roma 4x den teoretiske toppen FLOPS over Napoli, 2x fra den forbedrede flyttallskapasiteten, og 2x fra dobbelt så mange kjerner (64c vs 32c). Figur 10 plotter de målte HPL-resultatene for de fire Roma CPU-modellene vi testet, sammen med våre tidligere resultater fra et Napoli-basert system. Roma HPL-effektiviteten er notert som prosentverdien over stolpene på grafen og er høyere for de lavere TDP CPU-modellene.
Testene ble kjørt i Power Determinism-modus, og et ~5 % delta i ytelse ble målt på tvers av 64 identisk konfigurerte servere. Resultatene her er dermed i dette ytelsesbåndet.
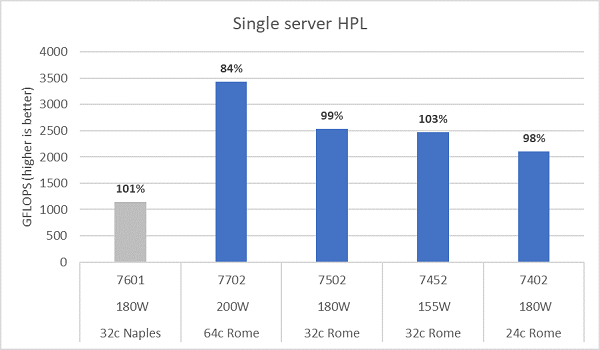
(Figur 10 Enkeltserver-HPL i NPS4)
Deretter ble HPL-tester med flere noder utført, og disse resultatene er plottet inn i figur 11. HPL-effektiviteten for EPYC 7452 forblir over 90 % i en skala på 64 noder, men effektivitetsfallene fra 102 % ned til 97 % og opptil 99 % må evalueres nærmere.
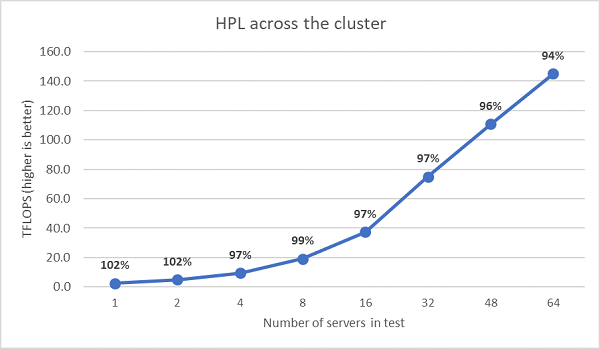
(Figur 11 HPL med flere noder, EPYC 7452 med to sokler over HDR100 InfiniBand)
Sammendrag og hva som kommer videre
Innledende ytelsesstudier på Roma-baserte servere viser forventet ytelse for vårt første sett med HPC-benchmarks. BIOS-justering er viktig når du konfigurerer for best mulig ytelse, og justeringsalternativer er tilgjengelige i vår BIOS HPC-workloadprofil som kan konfigureres på fabrikken eller angis ved hjelp av Dell EMC-verktøy for systemadministrasjon.
HPC og AI Innovation Lab har en ny 64-server Roma-basert PowerEdge-klynge, Minerva. Se denne plassen for påfølgende blogger som beskriver applikasjonsytelsesstudier på vår nye Minerva-klynge.