PowerEdge: AMD Rome — Arquitetura e desempenho inicial de HPC
Summary: No mundo atual de HPC, uma apresentação do processador EPYC de última geração da AMD, de codinome Rome.
Instructions
Garima Kochhar, Deepthi Cherlopalle, Joshua Weage. Laboratório de inovação em IA e HPC, outubro de 2019
No mundo atual de HPC, o processador EPYC de última geração da AMD, de codinome Rome, nem precisa de apresentação. Nos últimos meses, avaliamos sistemas baseados em Rome no Laboratório de inovação em IA e HPC
, e a Dell Technologies anunciou recentemente
servidores compatíveis com essa arquitetura de processador. Este primeiro blog da série Rome discute a arquitetura do processador Rome, como ela pode ser ajustada para o desempenho de HPC e apresenta os resultados iniciais da microrreferência de desempenho. Os blogs subsequentes descrevem o desempenho dos aplicativos nos domínios de CFD, CAE, dinâmica molecular, simulação climática e outros aplicativos.
Arquitetura
O Rome é a CPU EPYC de 2ª geração da AMD e atualiza o Naples, que era a 1ª geração.
Uma das maiores diferenças arquitetônicas benéficas para HPC entre o Naples e o Rome é o novo die de E/S no Rome. No Rome, cada processador é um pacote multichip composto por até nove chiplets, conforme mostrado na Figura 1. Há um die central de E/S de 14 nm que contém todas as funções de E/S e de memória, como controladores de memória, links de fabric Infinity dentro do soquete e conectividade entre soquetes e PCI-e. Há oito controladores de memória por soquete compatíveis com oito canais de memória que executam DDR4 a 3.200 MT/s. Um servidor de soquete único pode ser compatível com até 130 faixas PCIe de 4ª geração. Um sistema de soquete duplo pode ser compatível com até 160 faixas PCIe de 4ª geração.
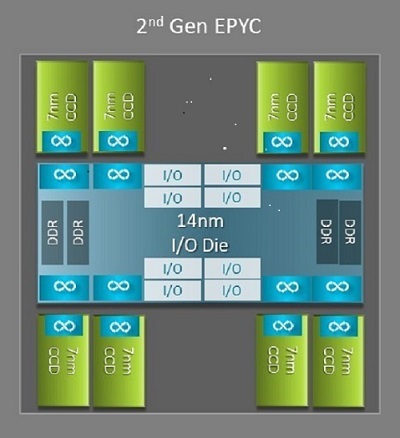
(Figura 1 Rome Pacote multichip com um die de E/S central e dies de até oito núcleos)
Em torno do die de E/S central, há até oito chiplets de núcleo de 7 nm. O chiplet principal é chamado de Core Cache Die, ou CCD. Cada CCD tem núcleos de CPU baseados na microarquitetura Zen2, cache L2 e cache L3 de 32 MB. O próprio CCD tem dois complexos de cache de núcleo (CCX), cada CCX tem até quatro núcleos e 16 MB de cache L3. A Figura 2 mostra um CCX.

(Figura 2 Um CCX com quatro núcleos e cache L3 compartilhado de 16 MB)
Os diferentes modelos de CPU Rome têm números diferentes de núcleos,
mas todos têm um die de E/S central.
Na extremidade superior, há um modelo de CPU de 64 núcleos, por exemplo, o EPYC 7702. O resultado do Lstopo mostra que esse processador tem 16 CCXs por soquete, cada CCX tem quatro núcleos, conforme mostrado nas Figuras 3 e 4, gerando 64 núcleos por soquete. L3 de 16 MB por CCX, ou L3 de 32 MB por CCD, fornece a esse processador cache L3 de 256 MB. No entanto, o cache L3 total no Rome não é compartilhado por todos os núcleos. O cache L3 de 16 MB em cada CCX é independente e é compartilhado apenas pelos núcleos no CCX, conforme ilustrado na Figura 2.
Uma CPU de 24 núcleos, como a EPYC 7402, tem um cache L3 de 128 MB. O resultado do Lstopo nas Figuras 3 e 4 ilustra que esse modelo tem três núcleos por CCX e oito CCX por soquete.
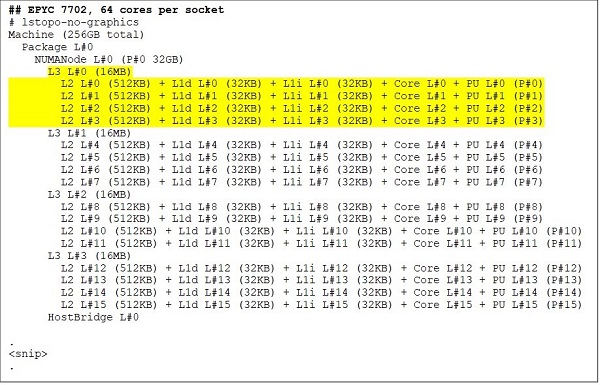
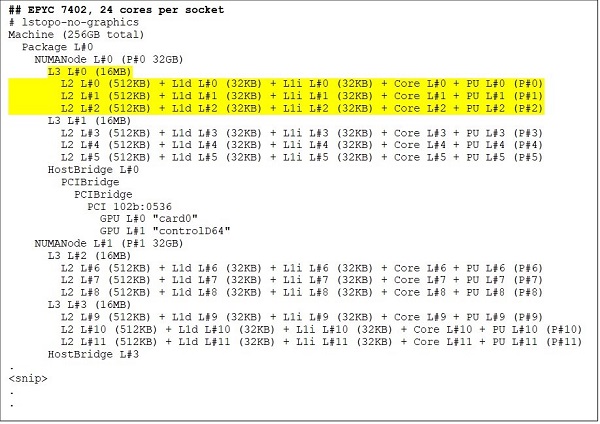
(Figuras 3 e 4: Resultado do Lstopo para CPUs de 64 núcleos e 24 núcleos)
Independentemente do número de CCDs, cada processador Rome é logicamente dividido em quatro quadrantes com CCDs distribuídos da maneira mais uniforme possível entre os quadrantes e dois canais de memória em cada quadrante. O die de E/S central pode ser considerado como compatível logicamente com os quatro quadrantes do soquete.
Opções de BIOS baseadas na arquitetura Rome
O die de E/S no Rome ajuda a melhorar as latências de memória em relação às medidas no Naples. Além disso, ele permite que a CPU seja configurada como um único domínio NUMA, permitindo acesso uniforme à memória para todos os núcleos no soquete. Isso é explicado abaixo.
Os quatro quadrantes lógicos em um processador Rome permitem que a CPU seja particionada em diferentes domínios NUMA. Essa configuração é chamada NUMA por soquete ou NPS.
- NPS1 implica que a CPU do Rome é um domínio NUMA único, com todos os núcleos no soquete e toda a memória nesse domínio NUMA. A memória é intercalada entre os oito canais de memória. Todos os dispositivos PCIe no soquete pertencem a este único domínio NUMA
- O NPS2 particiona a CPU em dois domínios NUMA, com metade dos núcleos e metade dos canais de memória no soquete em cada domínio NUMA. A memória é intercalada entre os quatro canais de memória em cada domínio NUMA
- O NPS4 particiona a CPU em quatro domínios NUMA. Nesse caso, cada quadrante é um domínio NUMA, e a memória é intercalada entre os dois canais de memória em cada quadrante. Os dispositivos PCIe são locais para um dos quatro domínios NUMA no soquete, dependendo de qual quadrante do die de E/S tem a raiz PCIe para esse dispositivo
- Nem todas as CPUs são compatíveis com todas as configurações de NPS
Quando disponível, o NPS4 é recomendado para HPC, pois espera-se que ele forneça a melhor largura de banda de memória, as menores latências de memória, e nossos aplicativos tendem a reconhecer NUMA. Quando o NPS4 não estiver disponível, recomendamos que o NPS mais alto seja compatível com o modelo de CPU: NPS2 ou até mesmo NPS1.
Dada a infinidade de opções de NUMA disponíveis em plataformas baseadas em Rome, o BIOS do PowerEdge permite dois métodos de enumeração de núcleo diferentes na enumeração MADT. A enumeração linear numera os núcleos em ordem, preenchendo um soquete CCX, CCD, antes de passar para o próximo soquete. Em uma CPU 32c, os núcleos 0 a 31 estão no primeiro soquete, os núcleos 32 a 63 no segundo soquete. A enumeração de rodízio numera os núcleos nas regiões NUMA. Nesse caso, os núcleos pares estão no primeiro soquete, os núcleos ímpares estão no segundo soquete. Para simplificar, recomendamos a enumeração linear para HPC. Consulte a Figura 5 para obter um exemplo de enumeração linear de núcleos em um servidor 64c de soquete duplo configurado no NPS4. Na figura, cada caixa de quatro núcleos é um CCX, cada conjunto de oito núcleos contíguos é um CCD.
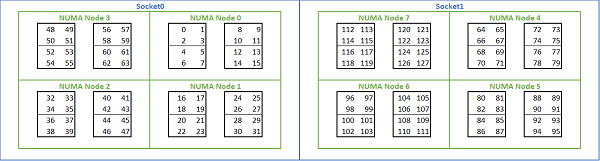
(Figura 5 Enumeração linear do núcleo em um sistema de soquete duplo, 64 c por soquete, configuração NPS4 em um modelo de oito CPUs CCD)
Outra opção de BIOS específica do Rome é a de Dispositivo de E/S preferencial. Este é um botão de ajuste importante para largura de banda InfiniBand e taxa de mensagens. Isso permite que a plataforma priorize o tráfego para um dispositivo de E/S. Essa opção está disponível em plataformas Rome de um e de dois soquetes, e o dispositivo InfiniBand na plataforma precisa ser selecionado como o dispositivo preferencial no menu do BIOS para atingir a taxa de mensagem completa quando todos os núcleos da CPU estiverem ativos.
Assim como no Naples, o Rome também é compatível com hyper-threading ou processador lógico. Em HPC, deixamos essa opção desativada, mas alguns aplicativos podem se beneficiar com a ativação do processador lógico. Procure nossos blogs subsequentes sobre estudos de aplicação de dinâmica molecular.
Semelhante a Naples, Rome também permite o uso de CCX como domínio NUMA. Essa opção expõe cada CCX como um nó NUMA. Em um sistema com CPUs de soquete duplo com 16 CCXs por CPU, essa configuração expõe 32 domínios NUMA. Neste exemplo, cada soquete tem oito CCDs, ou seja, 16 CCX. Cada CCX pode ser ativado como seu próprio domínio NUMA, fornecendo 16 nós NUMA por soquete e 32 em um sistema de dois soquetes. Em HPC, recomendamos deixar o CCX como domínio NUMA na opção padrão desativada. A ativação dessa opção é útil em ambientes virtualizados.
De modo semelhante ao Naples, o Rome permite que o sistema seja definido no modo Performance Determinism ou Power Determinism. No Performance Determinism, o sistema opera na frequência esperada para o modelo de CPU, reduzindo a variabilidade em vários servidores. No Power Determinism, o sistema opera com a TDP máxima disponível do modelo de CPU. Isso amplifica a variação de peça a peça no processo de fabricação, permitindo que alguns servidores sejam mais rápidos do que outros. Todos os servidores podem consumir a potência nominal máxima da CPU, tornando o consumo de energia determinista, mas permitindo alguma variação de desempenho em vários servidores.
Como esperado nas plataformas PowerEdge, o BIOS tem uma meta opção chamada System Profile. Selecionar o perfil do sistema otimizado para desempenho ativa o modo turbo boost, desativa os estados C e define o controle deslizante de determinismo como Power Determinism, otimizando o desempenho.
Resultados de desempenho — STREAM, HPL, microrreferências de desempenho InfiniBand
Muitos de nossos leitores podem ter pulado direto para esta seção, então vamos nos aprofundar.
No Laboratório de inovação em IA e HPC, criamos um cluster baseado no Rome de 64 servidores, que chamamos de Minerva. Além do cluster homogêneo Minerva, podemos avaliar outros exemplos de CPU Rome. Nosso ambiente de testes está descrito nas Tabelas 1 e 2.
(Tabela 1 Modelos da CPU do Rome avaliados neste estudo)
| CPU | Núcleos por soquete | Config | Relógio de base | TDP |
|---|---|---|---|---|
| 7702 | 64c | 4 núcleos por CCX | 2,0 GHz | 200 W |
| 7502 | 32c | 4 núcleos por CCX | 2,5 GHz | 180 W |
| 7452 | 32c | 4 núcleos por CCX | 2,35 GHz | 155 W |
| 7402 | 24c | 3 núcleos por CCX | 2,8 GHz | 180 W |
(Tabela 2 Ambiente de teste)
| Componente | Detalhes |
|---|---|
| Servidor | PowerEdge C6525 |
| Processador | Conforme mostrado na Tabela 1 Soquete duplo |
| Memória | 256 GB, 16 DDR4 de 16 GB e 3.200 MT/s |
| Interconexão | ConnectX-6 Mellanox Infini Band HDR100 |
| Sistema operacional | Red Hat Enterprise Linux 7.6 |
| Kernel | 3.10.0.957.27.2.e17.x86_64 |
| Disco | Módulo SSD SATA M.2 de 240 GB |
STREAM
Os testes de largura de banda da memória em Rome são apresentados na Figura 6. Esses testes foram executados no modo NPS4. Medimos uma largura de banda de memória aproximada de 270 a 300 GB/s em nosso PowerEdge C6525 de soquete duplo ao usar todos os núcleos no servidor nos quatro modelos de CPU listados na Tabela 1. Quando apenas um núcleo é usado por CCX, a largura de banda da memória do sistema é aproximadamente 9 a 17% maior do que a medida com todos os núcleos.
A maioria das cargas de trabalho de HPC usará totalmente todos os núcleos do sistema ou os centros de HPC serão executados no modo de alto throughput com vários trabalhos em cada servidor. Por isso, a largura de banda da memória de todos os núcleos é a representação mais precisa da largura de banda da memória e dos recursos de largura de banda da memória por núcleo do sistema.
A Figura 6 também mostra a largura de banda de memória medida na plataforma Naples EPYC da geração anterior, que também era compatível com oito canais de memória por soquete, mas com execução a 2667 MT/s. A plataforma Rome oferece uma largura de banda de memória total de 5% a 19% melhor do que a Naples, e isso se deve principalmente à memória de 3200 MT/s, que é significativamente mais rápida. Mesmo com 64c por soquete, o sistema Rome pode oferecer mais de 2 Gb/s/núcleo.
Ao comparar as diferentes configurações de NPS, aproximadamente 13% mais largura de banda de memória foi medida com o NPS4 em comparação com o NPS1, conforme mostrado na Figura 7.
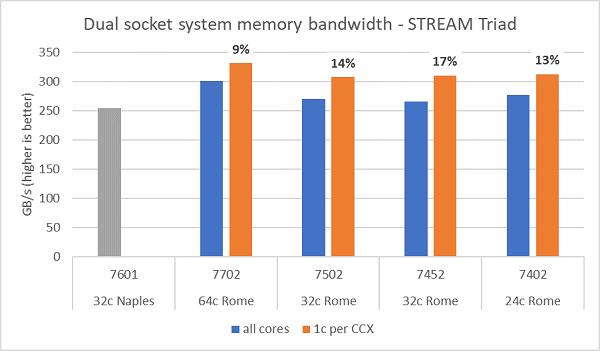
(Figura 6 Largura de banda da memória de NPS4 STREAM Triad de soquete duplo)
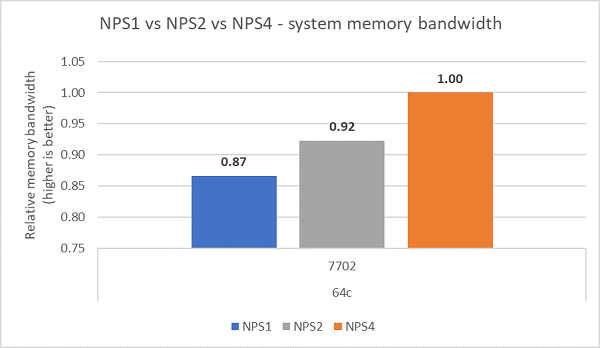
(Figura 7 Largura de banda de memória NPS1 versus NPS2 versus NPS 4)
Largura de banda InfiniBand e taxa de mensagens
A Figura 8 mostra a largura de banda InfiniBand de núcleo único para testes unidirecionais e bidirecionais. O ambiente de testes usou o HDR100 em execução a 100 Gbps, e o gráfico mostra o desempenho esperado da taxa de linha para esses testes.
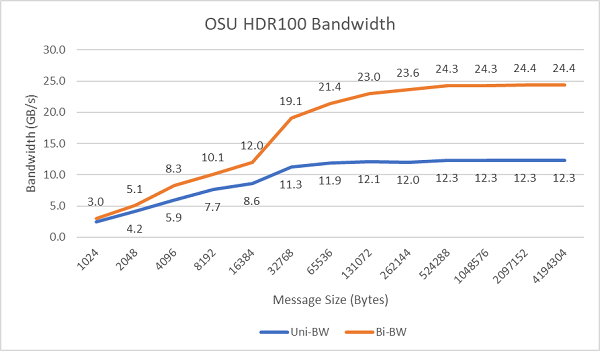
Figura 8 Largura de banda de InfiniBand (núcleo único))
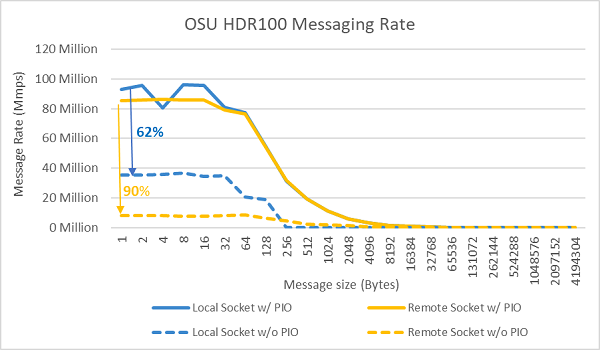
Figura 9 Taxa de mensagens de InfiniBand (todos os núcleos))
Em seguida, foram realizados os testes de taxa de mensagens usando todos os núcleos em um soquete nos dois servidores em teste. Quando a E/S preferencial está ativada no BIOS e o adaptador ConnectX-6 HDR100 está configurado como o dispositivo preferencial, a taxa de mensagens de todos os núcleos é maior do que quando a E/S preferencial não está ativada, conforme mostrado na Figura 9. Isso ilustra a importância dessa opção do BIOS ao ajustar para HPC e, especialmente, para escalabilidade de aplicativos de vários nós.
HPL
A microarquitetura do Rome pode desativar 16 DP FLOP/ciclo, o dobro do Naples, que era de 8 FLOPS/ciclo. Com isso, em teoria, o Rome tem 4 vezes mais FLOPS de pico em relação ao Naples: 2 vezes do recurso de ponto flutuante aprimorado e 2 vezes do dobro do número de núcleos (64 versus 32). A Figura 10 mostra os resultados de HPL medidos para os quatro modelos de CPU do Rome que testamos, juntamente com os resultados anteriores de um sistema baseado em Naples. O valor de eficiência Rome HPL é indicado como o percentual acima das barras no gráfico e é maior nos modelos de CPU com TDP mais baixa.
Os testes foram executados no modo Power Determinism, e foi medida uma variação aproximada de 5% no desempenho de 64 servidores com configuração idêntica. Portanto, os resultados estão nessa faixa de desempenho.

(Figura 10 HPL de servidor único no NPS4)
Em seguida, foram realizados testes de HPL de vários nós, e esses resultados estão representados na Figura 11. As eficiências de HPL do EPYC 7452 permanecem acima de 90% em uma escala de 64 nós, mas as variações de eficiência de 102% para 97% e de volta para 99% precisam de uma avaliação mais aprofundada.

(Figura 11 HPL de vários nós, EPYC 7452 de soquete duplo sobre InfiniBand HDR100)
Resumo e o que está por vir:
Os estudos iniciais de desempenho em servidores baseados em Rome mostram o desempenho esperado para nosso primeiro conjunto de referências de desempenho de HPC. O ajuste do BIOS é importante na configuração para obter o melhor desempenho, e as opções de ajuste estão disponíveis em nosso perfil de carga de trabalho de HPC do BIOS, que pode ser configurado na fábrica ou definido usando os utilitários de gerenciamento de sistemas da Dell EMC.
O Laboratório de inovação em IA e HPC tem um novo cluster PowerEdge baseado em Rome com 64 servidores, Minerva. Assista a este espaço para ver blogs subsequentes que descrevem estudos de desempenho de aplicativos em nosso novo cluster Minerva.