PowerEdge. AMD Rome — архитектура и первоначальная производительность HPC
Summary: В современном мире HPC мы представляем процессор AMD EPYC последнего поколения с кодовым названием Rome.
Instructions
Garima Kochhar, Deepthi Cherlopalle, Joshua Weage. HPC and AI Innovation Lab, октябрь 2019 г.
В современном мире HPC процессор AMD EPYC последнего поколения с кодовым названием Rome вряд ли нуждается в представлении. В последние несколько месяцев мы оценивали системы на базе Rome в лаборатории HPC and AI Innovation Lab
, а компания Dell Technologies недавно объявила
о выпуске серверов, поддерживающих эту архитектуру процессоров. В этой первой публикации блога о серии Rome обсуждается архитектура процессора Rome, способы ее настройки для обеспечения производительности HPC и представлена начальная производительность микро-эталонного теста. Последующие публикации в блоге описывают производительность приложений в областях CFD, CAE, молекулярной динамики, метеорологического моделирования и других приложений.
Архитектура
Rome — это процессор AMD EPYC 2-го поколения, обновляющий Naples первого поколения.
Одним из самых больших архитектурных различий между Naples и Rome, которое обеспечивает преимущество для HPC, является новый кристалл ввода-вывода в Rome. В Rome каждый процессор представляет собой многочипный пакет, состоящий из до девяти микрочипов, как показано на рис. 1. Среди них один центральный кристалл ввода-вывода 14 нм, содержащий все функции ввода-вывода и памяти: контроллеры памяти, каналы фабрики Infinity в сокете и межсокетные соединения, а также PCI-e. В каждом сокете имеется восемь контроллеров памяти, поддерживающих восемь каналов памяти DDR4 с частотой 3200 млн транзакций в секунду. Сервер с одним сокетом может поддерживать до 130 каналов PCIe Gen4. Система с двумя сокетами поддерживает до 160 каналов PCIe Gen4.
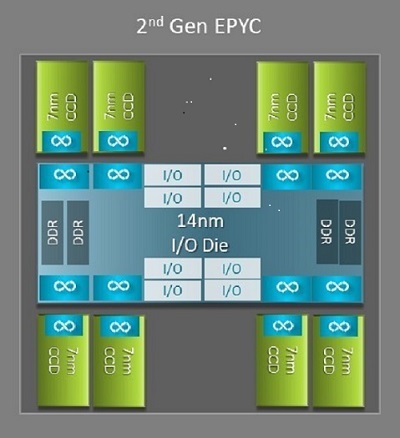
(Рис. 1. Многочипный пакет Rome с одним центральным кристаллом ввода-вывода и до 8-ядерных кристаллов)
Вокруг центрального кристалла ввода-вывода находятся до восьми микрочипов ядра 7 нм. Микрочип ядра называется кристаллом кэша ядра или CCD. Каждый CCD имеет ядра ЦП на основе микроархитектуры Zen2, кэш L2 и кэш L3 32 Мбайт. Сам CCD имеет два комплекса кэша ядра (CCX), каждый CCX имеет до четырех ядер и 16 Мбайт кэша L3. На рис. 2 показан CCX.

(Рис. 2. CCX с четырьмя ядрами и общим кэшем L3 16 Мбайт)
Разные модели ЦП Rome имеют разное количество ядер,
но все они оснащены одним центральным кристаллом ввода-вывода.
В верхней части находится модель ЦП с 64 ядрами, например EPYC 7702. Выходные данные Lstopo показывают, что этот процессор содержит 16 CCX на сокет, каждый CCX имеет четыре ядра, как показано на рис. 3 и 4, что дает 64 ядра на сокет. 16 Мбайт L3 на CCX, то есть 32 Мбайт L3 на CCD, обеспечивает этому процессору кэш L3 256 Мбайт. Однако обратите внимание, что общий объем кэша L3 в Rome используется не всеми ядрами. Кэш L3 16 Мбайт в каждом CCX независим и используется только ядрами CCX, как показано на рис. 2.
24-ядерный ЦП, такой как EPYC 7402, имеет кэш L3 128 Мбайт. Выходные данные Lstopo на рис. 3 и 4 показывают, что эта модель имеет три ядра на CCX и восемь CCX на сокет.


(Рис. 3 и 4. Вывод Lstopo для 64-ядерных и 24-ядерных ЦП)
Независимо от количества CCD, каждый процессор Rome логически разделен на четыре квадранта с как можно более равномерным распределением CCD, с двумя каналами памяти в каждом квадранте. Центральный кристалл ввода-вывода можно рассматривать как логическую поддержку четырех квадрантов сокета.
Параметры BIOS на основе архитектуры Rome
Центральный модуль ввода-вывода Rome помогает улучшить задержку памяти по сравнению с задержками, измеренными на Naples. Кроме того, он позволяет настроить ЦП в качестве одного домена NUMA, обеспечивая единый доступ к памяти для всех ядер в сокете. Это объясняется ниже.
Четыре логических квадранта в процессоре Rome позволяют разделить ЦП на разные домены NUMA. Этот параметр называется NUMA на сокет или NPS.
- NPS1 подразумевает, что ЦП Rome — это один домен NUMA со всеми ядрами в сокете и всей памятью в этом домене NUMA. Память чередуется по восьми каналам памяти. Все устройства PCIe в сокете принадлежат этому домену NUMA
- NPS2 разделяет ЦП на два домена NUMA с половиной ядер и половиной каналов памяти в сокете в каждом домене NUMA. Память чередуется по четырем каналам памяти в каждом домене NUMA
- NPS4 разделяет ЦП на четыре домена NUMA. Каждый квадрант является доменом NUMA, и память чередуется по двум каналам памяти в каждом квадранте. Устройства PCIe являются локальными для одного из четырех доменов NUMA в сокете в зависимости от того, какой квадрант кристалла ввода-вывода содержит корень PCIe для этого устройства
- Не все ЦП поддерживают все настройки NPS
Если доступно, NPS4 рекомендуется для HPC, так как ожидается, что он обеспечит наилучшую пропускную способность памяти, наименьшую задержку памяти, а наши приложения, как правило, поддерживают NUMA. Если NPS4 недоступен, рекомендуется использовать самый высокий NPS, поддерживаемый моделью ЦП, — NPS2 или даже NPS1.
Учитывая множество вариантов NUMA, доступных на платформах на базе Rome, BIOS PowerEdge позволяет использовать два различных метода нумерации ядер в разделе Нумерация MADT. Линейная нумерация назначает номера ядер по порядку, заполняя один CCX, CCD, сокет перед переходом к следующему сокету. В 32-ядерном ЦП ядра 0–31 находятся в первом сокете, а ядра 32–63 — во втором. Нумерация циклическим перебором присваивает номера ядрам по регионам NUMA. В этом случае ядра с четными номерами находятся в первом сокете, а ядра с нечетными номерами — во втором. Из соображений простоты для HPC рекомендуется линейная нумерация. Пример линейной нумерации ядер на двухсокетном 64-ядерном сервере, настроенном в NPS4, см. на рис. 5. На рисунке каждый прямоугольник из четырех ядер представляет собой CCX, каждый набор из восьми непрерывных ядер представляет собой CCD.
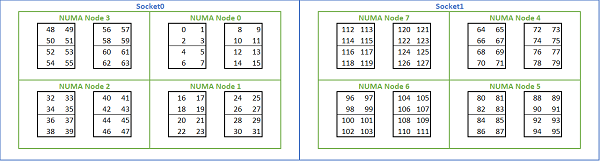
(Рис. 5. Линейная нумерация ядер в двухсокетной системе, 64 ядра на сокет, конфигурация NPS4 на модели с ЦП на 8 CCD)
Другой параметр BIOS, специфичный для Rome, это Предпочитаемое устройство ввода-вывода. Это важный регулятор настройки пропускной способности InfiniBand и частоту отправки сообщений. Это позволяет платформе определять приоритет трафика для одного устройства ввода-вывода. Этот параметр доступен на односокетных и двухсокетных платформах Rome, и устройство InfiniBand на платформе должно быть выбрано в качестве предпочтительного устройства в меню BIOS, чтобы обеспечить полную частоту отправки сообщений, когда все ядра ЦП активны.
Как и Naples, Rome поддерживает Hyper-Threading или логический процессор. Для HPC эта функция отключена, но некоторые приложения могут воспользоваться преимуществами включения логического процессора. Ознакомьтесь с нашими последующими публикациями в блоге об исследованиях в области молекулярной динамики.
Как и Naples, Rome позволяет использовать CCX в качестве домена NUMA. Этот параметр представляет каждый CCX как узел NUMA. В системе с двухсокетными ЦП с 16 CCX на ЦП этот параметр представляет 32 домена NUMA. В данном примере каждый сокет имеет восемь CCD, то есть 16 CCX. Каждый CCX можно включить в качестве собственного домена NUMA, предоставляя 16 узлов NUMA на сокет и 32 в двухсокетной системе. Для HPC рекомендуется оставить CCX в качестве домена NUMA с параметром по умолчанию Отключено. Включение этого параметра поможет виртуализированным средам.
Как и Naples, Rome позволяет перевести систему в режим Детерминированная производительность или Детерминированная мощность. В режиме Детерминированная производительностьсистема работает с ожидаемой частотой для модели ЦП, что снижает изменчивость на нескольких серверах. В режиме Детерминированная мощность система работает с максимальной доступной НТМ модели ЦП. Это расширяет различия в производственном процессе, что позволяет некоторым серверам работать быстрее, чем другим. Все серверы могут потреблять максимальную номинальную мощность ЦП, что делает потребляемую мощность детерминированной, но допускает некоторое изменение производительности на нескольких серверах.
Как и следовало ожидать от платформ PowerEdge, в BIOS есть метапараметр под названием Профиль системы. Выбор профиля системы Оптимизированная производительность включает режим Turbo Boost, отключает состояния C-states и устанавливает ползунок в положение «Детерминированная мощность», оптимизируя производительность.
Результаты производительности — микро-эталонные тесты для STREAM, HPL, InfiniBand
Многие из наших читателей, возможно, перешли прямо в этот раздел, поэтому мы подробно рассмотрим его.
В лаборатории HPC and AI Innovation Lab мы создали кластер на базе 64 серверов с процессорами Rome, который мы называем Minerva. В дополнение к однородному кластеру Minerva у нас есть несколько других образцов с ЦП Rome, которые можно оценить. Наш тестовый стенд описан в таблице 1 и таблице 2.
(Таблица 1. Модели ЦП Rome, оцененные в этом исследовании)
| ЦП | Количество ядер на сокет | Конфигурация | Базовая частота | Расчетная тепловая мощность |
|---|---|---|---|---|
| 7702 | 64 ядра | 4 ядра на CCX | 2,0 ГГц | 200 Вт |
| 7502 | 32 ядра | 4 ядра на CCX | 2,5 ГГц | 180 Вт |
| 7452 | 32 ядра | 4 ядра на CCX | 2,35 ГГц | 155 Вт |
| 7402 | 24 ядра | 3 ядра на CCX | 2,8 ГГц | 180 Вт |
(Таблица 2. Тестовый стенд)
| Компонент | Описание |
|---|---|
| Сервер | PowerEdge C6525 |
| Процессор | Как показано в таблице 1, двухсокетная система |
| Память | 256 Гбайт памяти DDR4, 16 x 16 Гбайт, 3200 млн транзакций в секунду |
| Соединение | ConnectX-6, Mellanox InfiniBand HDR100 |
| Операционная система | Red Hat Enterprise Linux 7.6 |
| Ядро | 3.10.0.957.27.2.e17.x86_64 |
| Диск | Модуль SSD M.2 SATA 240 Гбайт |
STREAM
Тесты пропускной способности памяти Rome представлены на рис. 6. Эти тесты выполнялись в режиме NPS4. Мы измерили пропускную способность памяти ~270-300 Гбайт/с на нашем двухсокетном сервере PowerEdge C6525 при использовании всех ядер сервера на моделях четырех ЦП, перечисленных в таблице.1. При использовании только одного ядра для каждого CCX пропускная способность системной памяти на 9–17% выше, чем при измерении для всех ядер.
Большинство рабочих нагрузок HPC либо полностью подписывают все ядра в системе, либо центры HPC работают в режиме высокой пропускной способности с несколькими заданиями на каждом сервере. Таким образом, пропускная способность памяти для всех ядер является более точным представлением пропускной способности памяти и возможностей памяти для каждого ядра системы.
На рис. 6 также показана пропускная способность памяти, измеренная на платформе EPYC Naples предыдущего поколения, которая также поддерживает восемь каналов памяти на сокет, но работает со скоростью 2667 млн транзакций в секунду. Платформа Rome обеспечивает на 5–19% большую общую пропускную способность памяти, чем Naples, и это в основном связано с более высокой скоростью памяти 3200 млн транзакций в секунду. Даже при 64 ядрах на сокет система Rome может обеспечивать скорость до 2 Гбайт/с на ядро.
При сравнении различных конфигураций NPS пропускная способность памяти была увеличена на ~13% с помощью NPS4 по сравнению с NPS1, как показано на рис. 7.
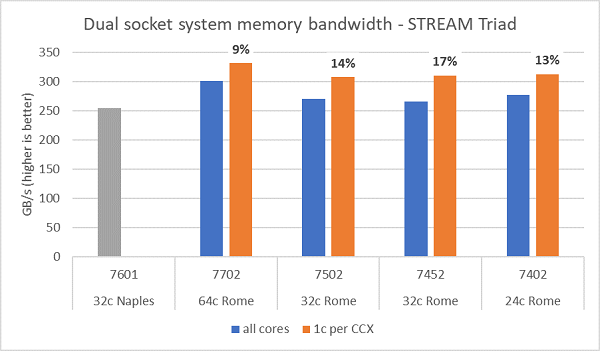
(Рис. 6. Пропускная способность STREAM Triad для двухсокетной системы NPS4)
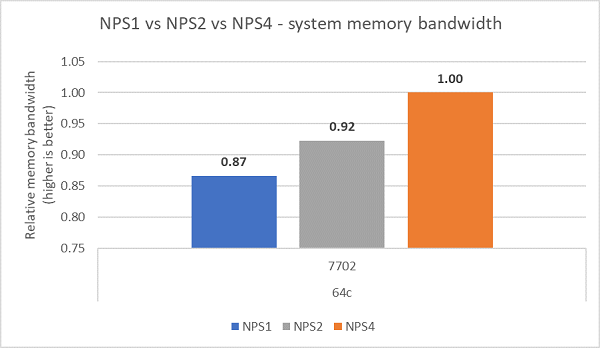
(Рис. 7. Пропускная способность памяти NPS1, NPS2 и NPS 4)
Пропускная способность InfiniBand и скорость передачи сообщений
На рис. 8 показана пропускная способность одноядерных процессоров InfiniBand для однонаправленных и двунаправленных тестов. В тестовом стенде используется HDR100 со скоростью 100 Гбит/с, а на графике показана ожидаемая пропускная способность линии для этих тестов.
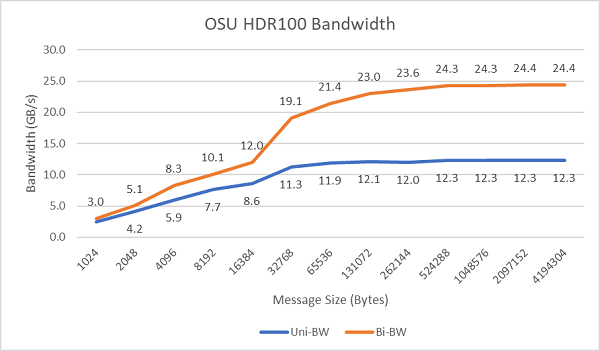
Рис. 8. Пропускная способность InfiniBand (одно ядро)
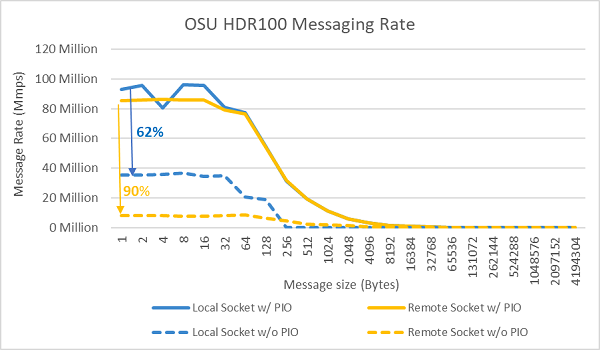
Рис. 9. Частота отправки сообщений InfiniBand (все ядра)
Затем были проведены тесты скорости сообщений с использованием всех ядер в сокете на двух тестируемых серверах. Если в BIOS включен предпочтительный ввод-вывод, а адаптер ConnectX-6 HDR100 настроен в качестве предпочтительного устройства, частота сообщений для всех ядер выше, чем при отключении предпочтительного ввода-вывода, как показано на рис. 9. Это демонстрирует важность этого параметра BIOS при настройке для HPC и особенно для масштабируемости приложений с несколькими узлами.
HPL
Микроархитектура Rome может вывести из эксплуатации 16 флопс/цикл, что вдвое больше, чем Naples с показателем 8 флопс/цикл. Это обеспечивает Rome в четыре раза больший теоретический пиковый коэффициент в флопсах по сравнению с Naples, в два раза больший за счет улучшенных возможностей для плавающей запятой и в два раза больший из-за удвоенного количества ядер (64 ядра по сравнению с 32 ядрами). На рис. 10 показаны измеренные результаты HPL для четырех моделей ЦП Rome, которые мы протестировали, а также наши предыдущие результаты по системе на базе Naples. Эффективность Rome HPL помечена как процентное значение над столбцами на графике и выше для моделей ЦП с более низкой НТМ.
Тесты выполнялись в режиме «Детерминированная мощность», и разница производительности ~5% измерялась на 64 серверах с одинаковой конфигурацией. Таким образом, результаты приведены в этом диапазоне производительности.
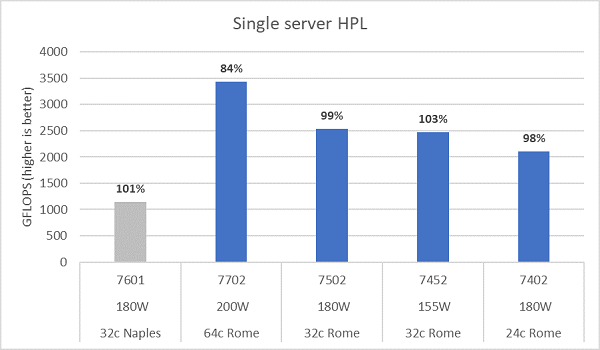
(Рис. 10. HPL одного сервера в NPS4)
Были выполнены следующие тесты HPL с несколькими узлами, и эти результаты представлены на рис. 11. Эффективность HPL для EPYC 7452 остается выше 90% в масштабе с 64 узлами, но снижение эффективности с 102% до 97% и подъем до 99% требует дальнейшей оценки.
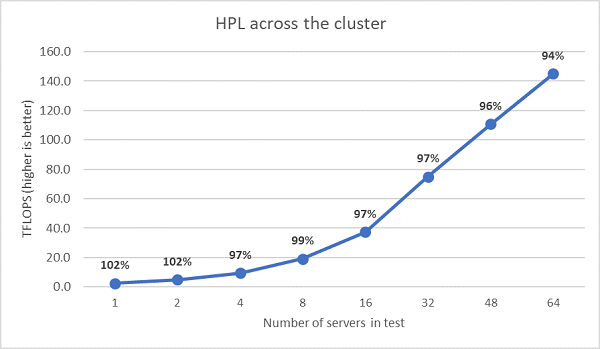
(Рис. 11. Многоузловой HPL, двухсокетный EPYC 7452 через HDR100 InfiniBand)
Сводка и дальнейшие действия.
Первоначальные исследования производительности на серверах на базе Rome показывают ожидаемую производительность для нашего первого набора эталонных тестов HPC. Настройка BIOS важна при настройке максимальной производительности, а параметры настройки доступны в нашем профиле рабочих нагрузок BIOS HPC, который можно настроить на заводе или с помощью утилит управления системами Dell EMC.
У лаборатории HPC and AI Innovation Lab есть новый 64-серверный кластер PowerEdge Minerva на базе Rome. Следите за последующими публикациями в блоге, где будут описаны исследования производительности приложений на нашем новом кластере Minerva.