AMD Rome - är det på riktigt? Arkitektur och initial HPC-prestanda
Summary: I HPC-världen idag en introduktion till AMD:s senaste generation EPYC-processorer med kodnamnet Rome.
Symptoms
Garima Kochhar, Deepthi Cherlopalle, Joshua Weage. HPC och AI Innovation Lab, oktober 2019
Cause
Gäller ej
Resolution
I dagens HPC-värld behöver AMD:s senaste generation EPYC-processor  , med kodnamnet Rome , knappast någon närmare presentation. Vi har utvärderat Rom-baserade system i HPC och AI Innovation Lab de senaste månaderna, och Dell Technologies presenterade
, med kodnamnet Rome , knappast någon närmare presentation. Vi har utvärderat Rom-baserade system i HPC och AI Innovation Lab de senaste månaderna, och Dell Technologies presenterade  nyligen servrar som stöder den här processorarkitekturen. I den här första bloggen i Rome-serien diskuteras Rome-processorarkitekturen, hur den kan finjusteras för HPC-prestanda och presentera inledande prestanda för mikroprestanda. Efterföljande bloggar beskriver applikationsprestanda över domänerna CFD, CAE, molekylär dynamik, vädersimulering och andra applikationer.
nyligen servrar som stöder den här processorarkitekturen. I den här första bloggen i Rome-serien diskuteras Rome-processorarkitekturen, hur den kan finjusteras för HPC-prestanda och presentera inledande prestanda för mikroprestanda. Efterföljande bloggar beskriver applikationsprestanda över domänerna CFD, CAE, molekylär dynamik, vädersimulering och andra applikationer.
Arkitektur
Rome är AMD:s 2:a generationens EPYC-processor och uppdaterar deras 1:a generation Naples.
En av de största arkitektoniska skillnaderna mellan Neapel och Rom som gynnar HPC är den nya IO-matrisen i Rom. I Rom är varje processor ett flerchipspaket som består av upp till 9 chiplets som visas i figur 1. Det finns en central 14nm IO-matris som innehåller alla IO- och minnesfunktioner - tänk minneskontroller, Infinity-infrastrukturlänkar i sockeln och anslutningen mellan socklarna och PCI-e. Det finns åtta minnesstyrenheter per sockel som har stöd för åtta minneskanaler som kör DDR4 vid 3 200 MT/s. En server med en sockel kan stödja upp till 130 PCIe Gen4-banor. Ett system med dubbla socklar kan stödja upp till 160 PCIe Gen4-banor.
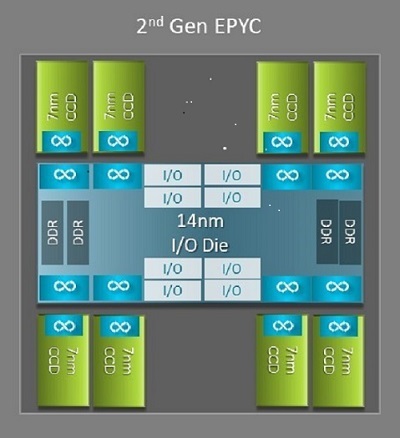
(Figur 1Rome flerchipspaket med en central IO-matris och upp till åtta kärnor)
Runt den centrala IO-matrisen finns upp till åtta 7nm kärnchiplets. Kärnchipleten kallas en Core Cache-matris eller CCD. Varje CCD har CPU-kärnor baserade på Zen2-mikroarkitekturen, L2-cache och 32 MB L3-cache. Själva CCD:n har två Core Cache Complexes (CCX), varje CCX har upp till fyra kärnor och 16 MB L3-cache. Bild 2 visar ett CCX.
varje CCX har upp till fyra kärnor och 16 MB L3-cache. Bild 2 visar ett CCX.

(Bild 2 En CCX med fyra kärnor och delat 16 MB L3-cacheminne)
De olika Rome CPU-modellerna  har olika antal kärnor,
har olika antal kärnor,  men alla har en central IO-matris.
men alla har en central IO-matris.
I den övre änden finns en CPU-modell med 64 kärnor, till exempel EPYC 7702. Lstopo-utdata visar att denna processor har 16 CCX per sockel, varje CCX har fyra kärnor som visas i figur 3 och 4, vilket ger 64 kärnor per sockel. 16 MB L3 per CCX, det vill säga 32 MB L3 per CCD, ger processorn totalt 256 MB L3-cacheminne. Observera dock att den totala L3-cachen i Rom inte delas av alla kärnor. L3-cachen på 16 MB i varje CCX är oberoende och delas endast av kärnorna i CCX enligt bild 2.
En 24-kärnig processor som EPYC 7402 har en L3-cache på 128 MB. Lstopo-utgången i figur 3 och 4 visar att denna modell har tre kärnor per CCX och 8 CCX per sockel.
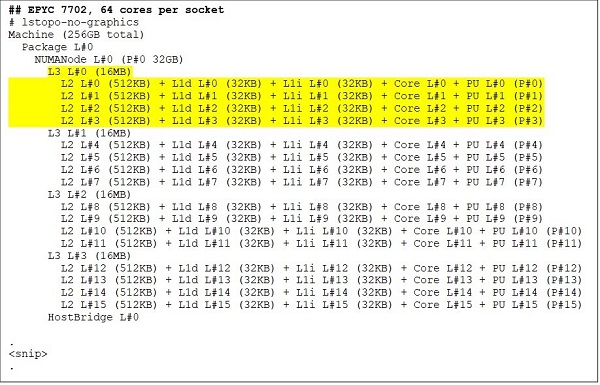
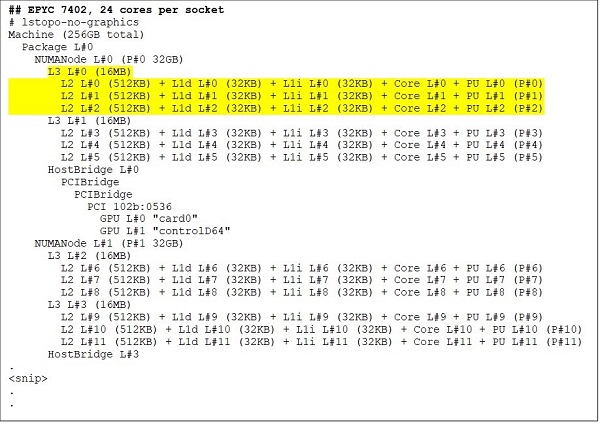
(Bild 3 och 4 lstopo-utdata för processorer med 64 och 24 kärnor)
Oavsett antalet CCD:er är varje Rome-processor logiskt uppdelad i fyra kvadranter med CCD:er fördelade så jämnt över kvadranterna som möjligt och två minneskanaler i varje kvadrant. Den centrala IO-matrisen kan ses som ett logiskt stöd för sockelns fyra kvadranter.
BIOS-alternativ baserade på Rom-arkitektur
Den centrala IO-matrisen i Rom hjälper till att förbättra minneslatenserna  jämfört med de som uppmättes i Neapel. Dessutom kan processorn konfigureras som en enda NUMA-domän, vilket ger enhetlig minnesåtkomst för alla kärnor i sockeln. Detta förklaras nedan.
jämfört med de som uppmättes i Neapel. Dessutom kan processorn konfigureras som en enda NUMA-domän, vilket ger enhetlig minnesåtkomst för alla kärnor i sockeln. Detta förklaras nedan.
De fyra logiska kvadranterna i en Rome-processor gör att processorn kan delas upp i olika NUMA-domäner. Den här inställningen kallas NUMA per socket eller NPS.
- NPS1 innebär att Rome-processorn är en enda NUMA-domän, med alla kärnor i sockeln och allt minne i denna enda NUMA-domän. Minnet är interfolierat över de åtta minneskanalerna. Alla PCIe-enheter på sockeln tillhör denna enda NUMA-domän
- NPS2 delar upp processorn i två NUMA-domäner, med hälften av kärnorna och hälften av minneskanalerna på sockeln i varje NUMA-domän. Minnet är interfolierat över de fyra minneskanalerna i varje NUMA-domän
- NPS4 delar upp processorn i fyra NUMA-domäner. Varje kvadrant är här en NUMA-domän och minnet är interfolierat över de två minneskanalerna i varje kvadrant. PCIe-enheter är lokala för en av fyra NUMA-domäner på sockeln beroende på vilken kvadrant av IO-matrisen som har PCIe-roten för den enheten
- Alla processorer har inte stöd för alla NPS-inställningar
NPS4 rekommenderas för HPC där det är tillgängligt, eftersom det förväntas ge den bästa minnesbandbredden, kortaste minneslatenser och våra program tenderar att vara NUMA-medvetna. Om NPS4 inte är tillgängligt rekommenderar vi att den högsta NPS som stöds av CPU-modellen – NPS2, eller till och med NPS1.
Med tanke på de många NUMA-alternativ som finns tillgängliga på Rom-baserade plattformar tillåter PowerEdge BIOS två olika kärnuppräkningsmetoder under MADT-uppräkning. Linjär uppräkning numrerar kärnor i ordning, fyller en CCX, CCD, socket innan den flyttas till nästa socket. På en 32c-processor finns kärnorna 0 till 31 på den första sockeln, kärnorna 32–63 på den andra sockeln. Resursallokeringsuppräkning numrerar kärnorna i NUMA-regioner. I det här fallet finns jämnt numrerade kärnor på den första sockeln, udda kärnor på den andra sockeln. För enkelhetens skull rekommenderar vi linjär uppräkning för HPC. I bild 5 finns ett exempel på linjär kärnuppräkning på en 64c-server med dubbla socklar konfigurerad i NPS4. I figuren är varje låda med fyra kärnor en CCX, varje uppsättning med åtta sammanhängande kärnor är en CCD.
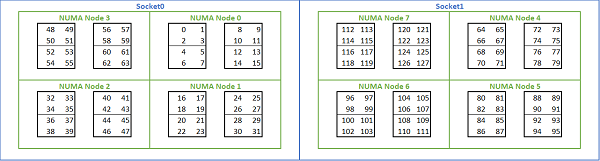
(Bild 5 Linjär kärnuppräkning på ett system med två socklar, 64c per sockel, NPS4-konfiguration på en modell med 8 CCD-processorer)
Ett annat Rom-specifikt BIOS-alternativ kallas Preferred IO Device. Detta är en viktig inställningsratt för InfiniBand-bandbredd och meddelandehastighet. Det gör att plattformen kan prioritera trafik för en IO-enhet. Det här alternativet är tillgängligt på Rome-plattformar med en och två socklar, och InfiniBand-enheten på plattformen måste väljas som prioriterad enhet i BIOS-menyn för att uppnå full meddelandefrekvens när alla processorkärnor är aktiva.
I likhet med Neapel har Rom också stöd för hypertrådningeller logisk processor. För HPC lämnar vi detta inaktiverat, men vissa applikationer kan dra nytta av att aktivera logisk processor. Håll utkik efter våra efterföljande bloggar om tillämpningar av molekyldynamik.
I likhet med Neapel tillåter Rom också CCX som NUMA-domän. Det här alternativet exponerar varje CCX som en NUMA-nod. På ett system med processorer med dubbla socklar med 16 CCX per processor exponerar den här inställningen 32 NUMA-domäner. I det här exemplet har varje sockel 8 CCD:er, det vill säga 16 CCX. Varje CCX kan aktiveras som en egen NUMA-domän, vilket ger 16 NUMA-noder per sockel och 32 i ett system med två socklar. För HPC rekommenderar vi att du lämnar CCX som NUMA-domän med standardalternativet inaktiverat. Att aktivera det här alternativet förväntas hjälpa virtualiserade miljöer.
I likhet med Neapel tillåter Rom att systemet ställs in i prestandadeterminism eller potensdeterminism . Vid prestandadeterminism arbetar systemet med den förväntade frekvensen för CPU-modellen, vilket minskar variationen mellan flera servrar. Vid Power Determinism arbetar systemet med den högsta tillgängliga TDP:n för CPU-modellen. Detta förstärker variationen från del till del i tillverkningsprocessen, vilket gör att vissa servrar kan vara snabbare än andra. Alla servrar kan förbruka processorns maximala märkeffekt, vilket gör strömförbrukningen deterministisk, men tillåter viss prestandavariation över flera servrar.
Som man kan förvänta sig av PowerEdge-plattformar har BIOS ett metaalternativ som heter System Profile. Om du väljer systemprofilen Prestandaoptimerad aktiveras turboförstärkningsläget, C-tillstånd inaktiveras och determinismreglaget ställs in på Energideterminism, vilket optimerar för prestanda.
Prestandaresultat – STREAM, HPL, InfiniBand-mikrobenchmarks
Många av våra läsare kanske har hoppat direkt till det här avsnittet, så vi kommer att dyka direkt in.
I HPC och AI Innovation Lab har vi byggt ut ett Rom-baserat kluster med 64 servrar som vi kallar Minerva. Förutom det homogena Minerva-klustret har vi några andra Rom-CPU-prover som vi kan utvärdera. Vår testbädd beskrivs i Tabell.1 och Tabell.2.
(Tabell.1 Rom CPU-modeller som utvärderats i denna studie)
| Processor | Kärnor per sockel | Konfiguration | Basklockfrekvens | TDP |
|---|---|---|---|---|
| 7702 | 64c | 4c per CCX | 2,0 GHz | 200 W |
| 7502 | 32c 32c | 4c per CCX | 2,5 GHz | 180 W |
| 7452 | 32c 32c | 4c per CCX | 2,35 GHz | 155 W |
| 7402 | 24c | 3c per CCX | 2,8 GHz | 180 W |
(Tabell.2 Testbädd)
| Komponent | Detaljer |
|---|---|
| Server | PowerEdge C6525 |
| Processor | Som visas i tabell.1 dubbla socklar |
| Minne | 256 GB, 16 × 16 GB, 3 200 MT/s, DDR4 |
| Interconnect | ConnectX-6 Mellanox Infini Band HDR100 |
| Operativsystem | Red Hat Enterprise Linux 7.6 |
| Kärna | 3.10.0.957.27.2.e17.x86_64 |
| Skiva | 240 GB SATA SSD M.2-modul |
STRÖM
Minnesbandbreddstester på Rome visas i figur 6, dessa tester kördes i NPS4-läge. Vi uppmätte ~270–300 GB/s minnesbandbredd på vår PowerEdge C6525 med dubbla socklar när vi använde alla kärnor i servern för de fyra processormodellerna som visas i tabellen.1. När endast en kärna används per CCX är systemets minnesbandbredd ~9–17 % högre än den som uppmäts med alla kärnor.
De flesta HPC-arbetsbelastningar prenumererar antingen helt på alla kärnor i systemet eller så körs HPC-center i läget för hög genomströmning med flera jobb på varje server. Därför är minnesbandbredden för alla kärnor den mer exakta representationen av systemets minnesbandbredd och minnesbandbredd-per-kärna-funktioner.
Bild 6 ritar också minnesbandbredden som uppmättes på den tidigare generationens EPYC Naples-plattform , som också hade stöd för åtta minneskanaler per socket men kördes med 2 667 MT/s. Rome-plattformen ger 5–19 % bättre total minnesbandbredd än Neapel, vilket främst beror på det snabbare minnet på 3 200 MT/s. Även med 64c per sockel kan Rome-systemet leverera upp till 2 GB/s/kärna.
Vid jämförelse av de olika NPS-konfigurationerna uppmättes ~13 % högre minnesbandbredd med NPS4 jämfört med NPS1 som visas i bild 7.
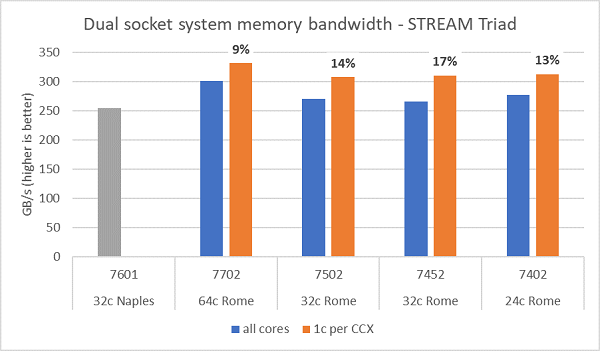
(Bild 6 NPS4 STREAM Triad-minnesbandbredd med dubbla socklar)
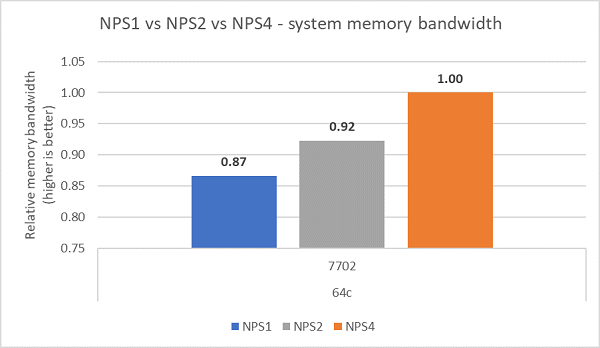
(Bild 7 : NPS1 jämfört med NPS2 jämfört med NPS 4 Minnesbandbredd)
InfiniBand-bandbredd och meddelandefrekvens
Figur 8 visar InfiniBand-bandbredden med enkel kärna för enkelriktade och dubbelriktade tester. Testbädden använde HDR100 som kördes med 100 Gbit/s, och diagrammet visar den förväntade prestandan för linjehastighet för dessa tester.
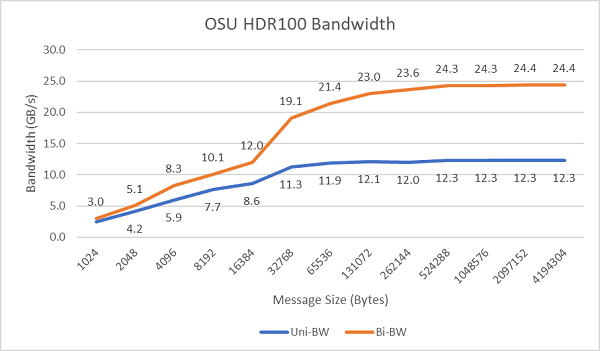
Bild 8 InfiniBand-bandbredd (enkel kärna))
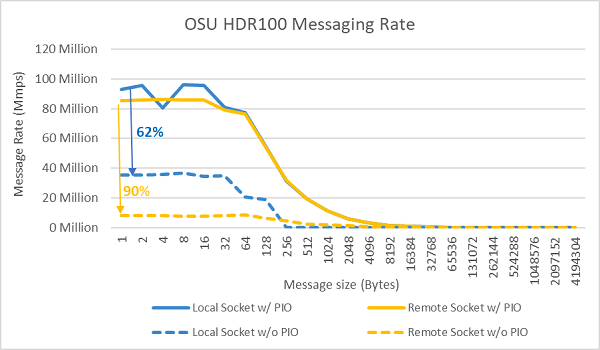
Bild 9 InfiniBand-meddelandefrekvens (alla kärnor))
Tester av meddelandefrekvensen utfördes sedan med alla kärnor på en sockel i de två servrar som testades. När föredragen IO är aktiverad i BIOS och ConnectX-6 HDR100-adaptern är konfigurerad som föredragen enhet är meddelandefrekvensen för alla kärnor betydligt högre än när föredragen IO inte är aktiverad, vilket visas i bild 9. Detta illustrerar vikten av det här BIOS-alternativet vid finjustering för HPC och särskilt för skalbarhet för program med flera noder.
HPL
Mikroarkitekturen i Rom kan pensionera 16 DP FLOP/cykel, dubbelt så mycket som i Neapel som var 8 FLOPS/cykel. Detta ger Rome 4x den teoretiska toppfloppen över Neapel, 2x från den förbättrade flyttalskapaciteten och 2x från dubbelt så många kärnor (64c mot 32c). Figur 10 visar de uppmätta HPL-resultaten för de fyra CPU-modellerna i Rom som vi testade, tillsammans med våra tidigare resultat från ett Neapel-baserat system. Rome HPL-effektiviteten anges som procentvärdet ovanför staplarna i diagrammet och är högre för de lägre TDP CPU-modellerna.
Testerna kördes i Power Determinism-läge och ett delta på ~5 % i prestanda uppmättes över 64 identiskt konfigurerade servrar. Resultatet här är alltså i det prestandaintervallet.
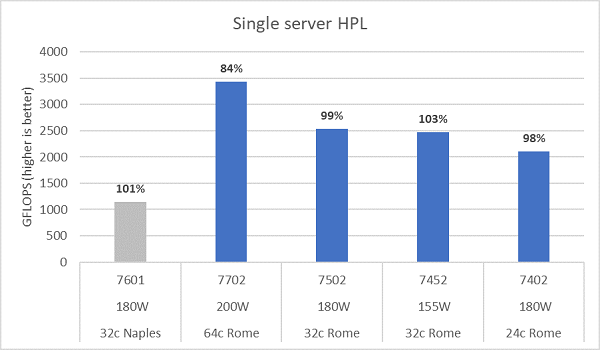
(Bild 10 HPL för en server i NPS4)
Nästa HPL-tester med flera noder utfördes och dessa resultat ritas i figur 11. HPL-effektiviteten för EPYC 7452 ligger fortfarande över 90 % vid en skala med 64 noder, men nedgången i effektivitet från 102 % ner till 97 % och tillbaka upp till 99 % behöver utvärderas ytterligare.
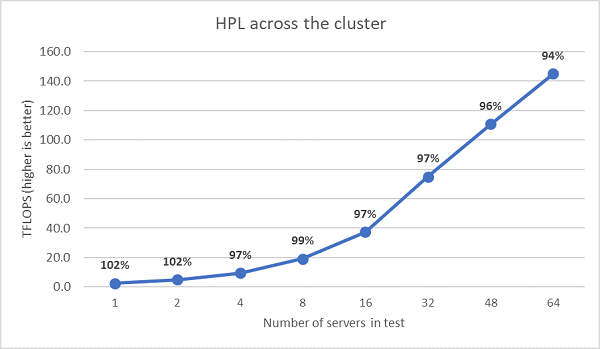
(Bild 11 HPL med flera noder, dubbla socklar EPYC 7452 över HDR100 InfiniBand)
Sammanfattning och vad som kommer härnäst
Inledande prestandastudier på Rom-baserade servrar visar förväntad prestanda för vår första uppsättning HPC-prestandatest. BIOS-finjustering är viktigt när du konfigurerar för bästa prestanda, och finjusteringsalternativ finns tillgängliga i vår BIOS HPC-arbetsbelastningsprofil som kan konfigureras på fabriken eller ställas in med hjälp av Dell EMC:s systemhanteringsverktyg.
HPC och AI Innovation Lab har ett nytt Rom-baserat PowerEdge-kluster med 64 servrar, Minerva. Håll utkik här för efterföljande bloggar som beskriver programprestandastudier på vårt nya Minerva-kluster.