PowerEdge: AMD Rome - Mimari ve ilk HPC performansı
Summary: Bugün HPC dünyasında, AMD'nin Rome kod adlı en yeni nesil EPYC işlemcisinin tanıtımı.
Instructions
Garima Kochhar, Deepthi Cherlopalle, Joshua Weage. HPC and AI Innovation Lab, Ekim 2019
Günümüz HPC dünyasında, AMD'nin Rome kod adlı en yeni nesil EPYC işlemcisini tanıtmaya gerek yok. Son birkaç aydır HPC and AI Innovation Lab'de
Rome tabanlı sistemleri değerlendiriyorduk ve Dell Technologies kısa süre önce bu işlemci mimarisini destekleyen sunucuları duyurdu
. Rome serisinin bu ilk blogunda Rome işlemci mimarisi, bu mimarinin HPC performansı için nasıl ayarlanabileceği ele alınıyor ve ilk mikro karşılaştırma performansı sunuluyor. Sonraki bloglar; CFD, CAE, moleküler dinamik, hava durumu simülasyonu ve diğer uygulama alanlarındaki uygulama performansını açıklıyor.
Mimari
Rome, AMD'nin 1. nesil Naples'ı yenileyen 2. nesil EPYC CPU'sudur.
Naples ve Rome arasında HPC'ye fayda sağlayan en büyük mimari farklardan biri, Rome'daki yeni G/Ç kalıbıdır. Rome'da her işlemci, Şekil 1'de gösterildiği gibi en fazla dokuz chiplet'ten oluşan çok çipli bir pakettir. Tüm G/Ç ve bellek işlevlerini içeren bir adet merkezi 14 nm G/Ç kalıbı vardır (bellek denetleyicileri, soket içindeki Infinity yapı bağlantıları ve yuvalar arası bağlantı ve PCI-e). 3200 MT/sn.de DDR4 çalıştıran sekiz bellek kanalını destekleyen soket başına sekiz bellek denetleyicisi bulunur. Tek soketli bir sunucu en fazla 130 PCIe Gen4 hattını destekleyebilir. Çift soketli bir sistem en fazla 160 PCIe Gen4 hattını destekleyebilir.
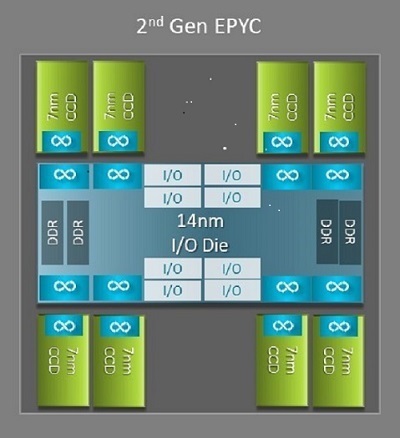
(Şekil 1 Bir adet merkezi G/Ç kalıbı ve sekiz adede kadar çekirdek kalıbı içeren Rome çoklu çip paketi)
Merkezi G/Ç kalıbını çevreleyen sekiz adede kadar 7 nm çekirdek chiplet'i bulunur. Çekirdek chiplet'i, Çekirdek Önbellek kalıbı veya CCD olarak adlandırılır. Her CCD, Zen2 mikro mimarisi, L2 önbellek ve 32 MB L3 önbellek temelli CPU çekirdeklerine sahiptir. CCD'nin kendisinde iki Çekirdek Önbellek Bloku (CCX) vardır, her CCX'in dört adede kadar çekirdeği ve 16 MB L3 önbelleği bulunur. Şekil 2'de bir CCX gösterilmektedir.

(Şekil 2: Dört çekirdekli ve paylaşımlı 16 MB L3 önbelleğe sahip bir CCX)
Farklı Rome CPU modellerifarklı sayıda çekirdeğe sahiptir
ancak hepsinde bir merkezi G/Ç kalıbı vardır.
En üst uçta 64 çekirdekli bir CPU modeli, örneğin EPYC 7702 vardır. Lstopo çıkışı bize bu işlemcinin soket başına 16 CCX'e sahip olduğunu, her CCX'in Şekil 3 ve 4'te gösterildiği gibi dört çekirdeğe sahip olduğunu ve böylece soket başına 64 çekirdek sağladığını gösteriyor. CCX başına 16 MB L3, yani CCD başına 32 MB L3 bu işlemciye 256 MB L3 önbellek sağlar. Rome'daki toplam L3 önbelleğinin tüm çekirdekler tarafından paylaşılmadığını unutmayın. Her CCX'teki 16 MB L3 önbellek bağımsızdır ve Şekil 2'de gösterildiği gibi yalnızca CCX'teki çekirdekler tarafından paylaşılır.
EPYC 7402 gibi 24 çekirdekli bir CPU, 128 MB L3 önbelleğe sahiptir. Şekil 3 ve 4'teki Lstopo çıkışı, bu modelin CCX başına üç çekirdeğe ve soket başına sekiz CCX'e sahip olduğunu göstermektedir.
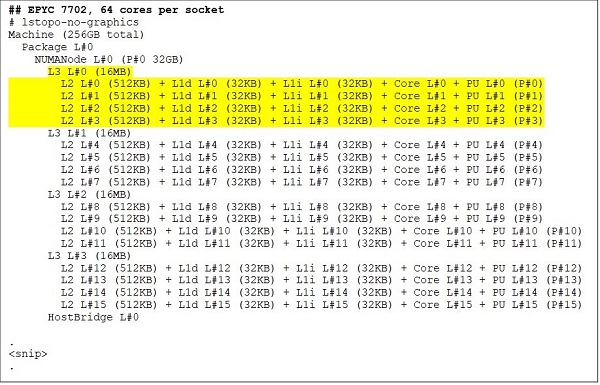
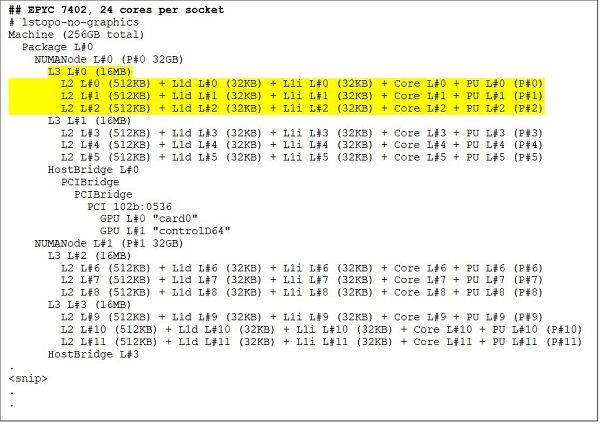
(Şekil 3 ve 4: 64 çekirdekli ve 24 çekirdekli CPU'lar için Lstopo çıkışı)
CCD'lerin sayısı ne olursa olsun, her Rome işlemcisi mantıksal olarak dört çeyreğe bölünmüştür ve CCD'ler çeyreklere mümkün olduğunca eşit bir şekilde dağıtılır ve her çeyrekte iki bellek kanalı bulunur. Merkezi G/Ç kalıbının soketin dört çeyreğini mantıksal olarak desteklediği düşünülebilir.
Rome mimarisi tabanlı BIOS seçenekleri
Rome'daki merkezi G/Ç kalıbı, Naples'da ölçülen bellek gecikme sürelerini iyileştirmeye yardımcı olur. Ayrıca CPU'nun soketteki tüm çekirdekler için tek tip bellek erişimi sağlayan tek bir NUMA etki alanı olarak yapılandırılmasına olanak tanır. Bu aşağıda açıklanmıştır.
Bir Rome işlemcisindeki dört mantıksal çeyrek CPU'nun farklı NUMA etki alanlarına bölümlenmesini sağlar. Bu ayara soket başına NUMA veya NPS adı verilir.
- NPS1, Rome CPU'nun tek bir NUMA etki alanı olduğunu, tüm çekirdeklerin sokette ve tüm belleğin bu NUMA etki alanında olduğunu belirtir. Bellek, sekiz bellek kanalı arasında dönüşümlü olarak çalıştırılır. Soketteki tüm PCIe aygıtları bu tek NUMA etki alanına aittir
- NPS2, CPU'yu iki NUMA etki alanına böler ve her NUMA etki alanındaki çekirdeklerin yarısı ve bellek kanallarının yarısı sokette bulunur. Bellek, her NUMA etki alanındaki dört bellek kanalında dönüşümlü olarak çalıştırılır
- NPS4, CPU'yu dört NUMA etki alanına böler. Burada her çeyrek bir NUMA etki alanıdır ve bellek her çeyrekteki iki bellek kanalında dönüşümlü olarak çalıştırılır. PCIe aygıtları, G/Ç kalıbının hangi çeyreğinin o aygıt için PCIe köküne sahip olduğuna bağlı olarak soketteki dört NUMA etki alanından birinde yereldir
- Tüm CPU'lar tüm NPS ayarlarını destekleyemez
En iyi bellek bant genişliğini, en düşük bellek gecikme sürelerini sağlaması beklendiğinden ve uygulamalarımız NUMA'yı tanıma eğiliminde olduğundan, kullanılabilir olduğunda HPC için NPS4 önerilir. NPS4'ün kullanılamadığı durumlarda CPU modeli tarafından desteklenen en yüksek NPS'nin (NPS2 ve hatta NPS1) olmasını öneririz.
Rome tabanlı platformlarda bulunan çok sayıda NUMA seçeneği göz önüne alındığında PowerEdge BIOS, MADT numaralandırması altında iki farklı çekirdek numaralandırma yöntemine izin verir. Doğrusal numaralandırma, bir CCX, CCD, soketi doldurduktan sonra bir sonraki sokete geçmeden çekirdekleri sırayla numaralandırır. 32c CPU'da 0 ile 31 arasındaki çekirdekler ilk sokette, 32-63 arasındaki çekirdekler ikinci sokette bulunur. Çevrimsel sıralı numaralandırma, NUMA bölgelerindeki çekirdekleri numaralandırır. Bu durumda, çift sayılı çekirdekler birinci sokette, tek sayılı çekirdekler ikinci sokette bulunur. Kolaylık olması açısından, HPC için doğrusal numaralandırmayı öneririz. NPS4'te yapılandırılmış çift soketli 64c sunucuda doğrusal çekirdek numaralandırması örneği için Şekil 5'e bakın. Şekilde, dört çekirdekten oluşan her kutu bir CCX'tir, sekiz bitişik çekirdekten oluşan her set bir CCD'dir.
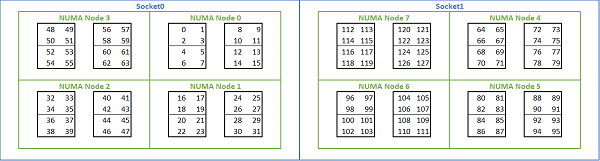
(Şekil 5 Çift soketli sistemde doğrusal çekirdek numaralandırması, soket başına 64c, sekiz CCD CPU modelinde NPS4 yapılandırması)
Rome'a özgü başka bir BIOS seçeneği ise Tercih Edilen G/Ç Aygıtı olarak adlandırılır. Bu, InfiniBand bant genişliği ve mesaj hızı için önemli bir ayarlama düğmesidir. Platformun bir G/Ç aygıtı için trafiğe öncelik vermesini sağlar. Bu seçenek tek soketli ve iki soketli Rome platformlarında mevcuttur ve tüm CPU çekirdekleri etkin olduğunda tam mesaj hızına ulaşmak için platformdaki InfiniBand aygıtı BIOS menüsünde tercih edilen aygıt olarak seçilmelidir.
Naples'a benzer şekilde Rome da hiper iş parçacığı veya mantıksal işlemciyi destekler. HPC için bunu devre dışı bırakırız ancak bazı uygulamalar mantıksal işlemcinin etkinleştirilmesinden fayda sağlayabilir. Moleküler dinamik uygulama çalışmaları ile ilgili sonraki bloglarımıza bakın.
Naples'a benzer şekilde Rome da NUMA Etki Alanı olarak CCX'e izin verir. Bu seçenek her CCX'i bir NUMA düğümü olarak gösterir. CPU başına 16 CCX bulunan çift soketli CPU'lara sahip bir sistemde bu ayar 32 NUMA etki alanı gösterir. Bu örnekte, her sokette sekiz CCD, yani 16 CCX bulunur. Her CCX, soket başına 16 NUMA düğümü ve iki soketli bir sistemde 32 NUMA düğümü sağlayarak kendi NUMA etki alanı olarak etkinleştirilebilir. HPC için NUMA Etki Alanı olarak CCX'i varsayılan devre dışı seçeneğinde bırakmanızı öneririz. Bu seçeneğin etkinleştirilmesinin sanallaştırılmış ortamlara yardımcı olması beklenir.
Naples'a benzer şekilde Rome da sistemin Performans Belirleyiciliği veya Güç Belirleyiciliği modunda ayarlanmasına izin verir. Performans Belirleyiciliği modunda sistem, CPU modeli için beklenen frekansta çalışarak birden çok sunucu arasındaki değişkenliği azaltır. Güç Belirleyiciliği modunda sistem, CPU modelinin mevcut maksimum TDP'sinde çalışır. Bu, üretim sürecindeki parçadan parçaya değişkenliği artırarak bazı sunucuların diğerlerinden daha hızlı olmasını sağlar. Tüm sunucular CPU'nun maksimum nominal gücünü tüketerek güç tüketimini belirleyici hale getirebilir ancak birden çok sunucu arasında bazı performans değişikliklerine izin verebilir.
PowerEdge platformlarından beklediğiniz gibi BIOS'ta Sistem Profili adı verilen bir meta seçenek bulunur. Performans için Optimize Edilmiş sistem profilinin seçilmesi turbo boost modunu etkinleştirir, C durumlarını devre dışı bırakır ve belirleyicilik kaydırıcısını Performans için optimize etmek üzere Güç Belirleyiciliği olarak ayarlar.
Performans Sonuçları - STREAM, HPL, InfiniBand mikro karşılaştırmaları
Okurlarımızın çoğu doğrudan bu bölüme atlamış olabilir, bu yüzden hemen başlıyoruz.
HPC and AI Innovation Lab'de, Minerva adını verdiğimiz 64 sunuculu Rome tabanlı bir küme oluşturduk. Homojen Minerva kümesine ek olarak, değerlendirebileceğimiz birkaç Rome CPU örneğimiz daha var. Test ortamımız Tablo 1 ve Tablo 2'de açıklanmıştır.
(Tablo 1: Bu çalışmada değerlendirilen Rome CPU modelleri)
| CPU | Soket Başına Çekirdek | Yapılandırma | Taban Saat | TDP |
|---|---|---|---|---|
| 7702 | 64c | CCX başına 4c | 2,0 GHz | 200W |
| 7502 | 32c | CCX başına 4c | 2,5 GHz | 180W |
| 7452 | 32c | CCX başına 4c | 2,35 GHz | 155W |
| 7402 | 24c | CCX başına 3c | 2,8 GHz | 180W |
(Tablo 2: Test Ortamı)
| Bileşen | Ayrıntılar |
|---|---|
| Sunucu | PowerEdge C6525 |
| İşlemci | Tablo 1'de gösterildiği gibi çift soketli |
| Bellek | 256 GB, 16x16 GB, 3200 MT/sn. DDR4 |
| Interconnect | ConnectX-6 Mellanox Infini Band HDR100 |
| İşletim Sistemi | Red Hat Enterprise Linux 7.6 |
| Kernel | 3.10.0.957.27.2.e17.x86_64 |
| Disk | 240 GB SATA SSD M.2 modülü |
STREAM
Rome'daki bellek bant genişliği testleri Şekil 6'da sunulmuştur ve bu testler NPS4 modunda çalıştırılmıştır. Çift soketli PowerEdge C6525 sistemimizde, Tablo 1'de listelenen dört CPU modelinde sunucudaki tüm çekirdekleri kullanırken ~270-300 GB/sn. bellek bant genişliği ölçtük. CCX başına yalnızca bir çekirdek kullanıldığında sistem bellek bant genişliği tüm çekirdeklerle ölçülenden ~%9-17 daha yüksektir.
Çoğu HPC iş yükü, sistemdeki tüm çekirdekleri tam olarak kullanır veya HPC merkezleri, her sunucuda birden fazla işle yüksek aktarım hızı modunda çalışır. Bu nedenle tüm çekirdek bellek bant genişliği, sistemin bellek bant genişliği ve çekirdek başına bellek bant genişliği özelliklerinin daha doğru temsilidir.
Şekil 6'da, soket başına sekiz bellek kanalını destekleyen ancak 2667 MT/sn.de çalışan önceki nesil EPYC Naples platformunda ölçülen bellek bant genişliği de gösterilmektedir. Rome platformu, Naples'dan %5 ila %19 daha iyi toplam bellek bant genişliği sağlar ve bunun nedeni ağırlıklı olarak daha hızlı 3200 MT/sn. bellektir. Soket başına 64c ile bile, Rome sistemi 2 GB/sn./çekirdek'ten fazla performans sağlayabilir.
Farklı NPS yapılandırmaları karşılaştırıldığında, Şekil 7'de gösterildiği gibi NPS1'e kıyasla NPS4 ile ~%13 daha yüksek bellek bant genişliği ölçülmüştür.
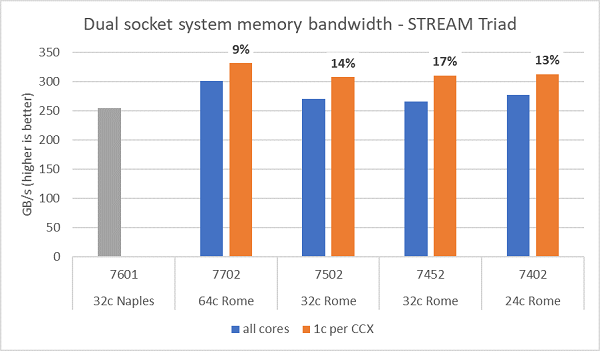
(Şekil 6: Çift soketli NPS4 STREAM Triad bellek bant genişliği)
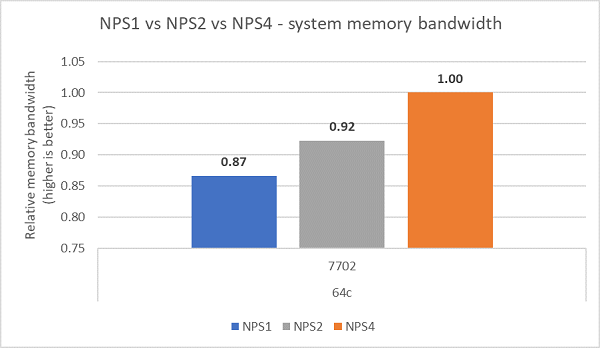
(Şekil 7: NPS1 - NPS2 - NPS 4 Bellek bant genişliği)
InfiniBand bant genişliği ve mesaj hızı
Şekil 8'de, tek yönlü ve çift yönlü testler için tek çekirdekli InfiniBand bant genişliği gösterilmektedir. Test ortamında 100 Gb/sn.de çalışan HDR100 kullanıldı ve grafikte bu testler için beklenen hat hızı performansı gösterilmektedir.
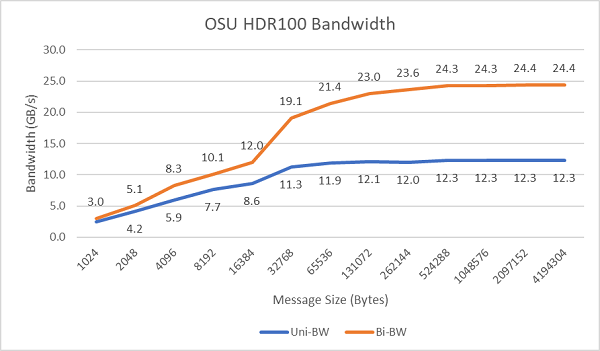
Şekil 8: InfiniBand bant genişliği (tek çekirdekli))
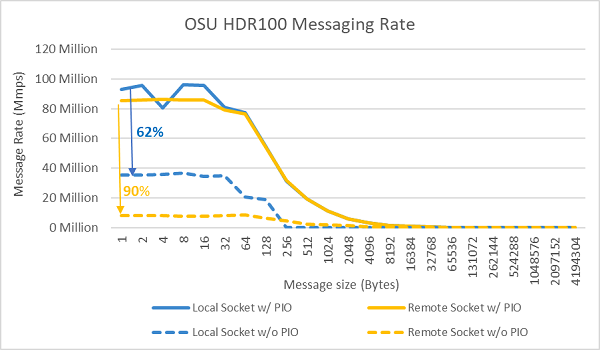
Şekil 9: InfiniBand mesaj hızı (tüm çekirdekler))
Mesaj hızı testleri, test edilen iki sunucudaki bir sokette bulunan tüm çekirdekler kullanılarak gerçekleştirildi. BIOS'ta Tercih Edilen G/Ç etkinleştirildiğinde ve ConnectX-6 HDR100 bağdaştırıcısı tercih edilen aygıt olarak yapılandırıldığında tüm çekirdek mesaj hızı, Şekil 9'da gösterildiği gibi Tercih Edilen G/Ç'nin etkinleştirilmediği duruma göre daha yüksektir. Bu durum, HPC ve özellikle çok düğümlü uygulama ölçeklenebilirliği için ayarlama yaparken bu BIOS seçeneğinin önemini gösterir.
HPL
Rome mikro mimarisi, 16 DP FLOP/döngüyü sonlandırabilir; bu da 8 FLOPS/döngüyü sonlandırabilen Naples'ın iki katıdır. Bu, Rome'a teorik olarak Naples'a göre 4 kat en yüksek FLOPS sağlar; 2 katı gelişmiş kayan nokta yeteneğinden ve 2 katı da çekirdek sayısının iki katına çıkmasından kaynaklanır (64c'ye karşı 32c). Şekil 10, Naples tabanlı bir sistemden elde ettiğimiz önceki sonuçlarımızla birlikte test ettiğimiz dört Rome CPU modeli için ölçülen HPL sonuçlarını göstermektedir. Rome HPL verimliliği, grafikteki çubukların üzerindeki yüzde değeri olarak belirtilir ve daha düşük TDP CPU modelleri için daha yüksektir.
Testler Güç Belirleyiciliği modunda gerçekleştirilmiştir ve aynı şekilde yapılandırılmış 64 sunucuda performansta ~%5'lik bir delta ölçülmüştür. Bu nedenle buradaki sonuçlar bu performans bandındadır.
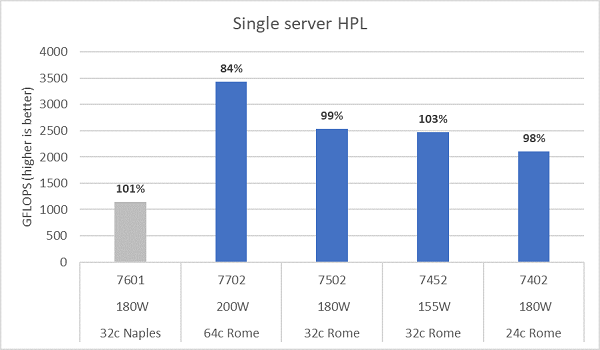
(Şekil 10: NPS4'te tek sunucu HPL)
Daha sonra çok düğümlü HPL testleri yapılmış ve bu sonuçlar Şekil 11'de gösterilmiştir. EPYC 7452 için HPL verimlilikleri, 64 düğümlü bir ölçekte %90'ın üzerinde kalır ancak verimlilikteki %102'den %97'ye düşüş ve tekrar %99'a çıkış gibi dalgalanmaların daha fazla değerlendirilmesi gerekir.

(Şekil 11: Çok düğümlü HPL, HDR100 InfiniBand üzerinden çift soketli EPYC 7452)
Özet ve sıradakiler:
Rome tabanlı sunucularla ilgili ilk performans çalışmaları, ilk HPC karşılaştırma testlerimiz için beklenen performansı göstermektedir. En iyi performans için yapılandırma yaparken BIOS ayarı önemlidir ve fabrikada yapılandırılabilen veya Dell EMC sistem yönetimi yardımcı programları kullanılarak ayarlanabilen BIOS HPC iş yükü profilimizde ayarlama seçenekleri mevcuttur.
HPC and AI Innovation Lab, 64 sunuculu yeni bir Rome tabanlı PowerEdge kümesi olan Minerva'ya sahiptir. Yeni Minerva kümemizdeki uygulama performansı çalışmalarını açıklayan sonraki bloglar için bu alanı izleyin.