PowerEdge: AMD Rome – Architektura a počáteční výkon HPC
Summary: Představení nejnovější generace procesorů EPYC s kódovým označením Rome v dnešním světě HPC.
Instructions
Garima Kochhar, Deepthi Cherlopalle, Joshua Weage. HPC and AI Innovation Lab, říjen 2019
V dnešním světě HPC není třeba nejnovější generaci procesorů EPYC s kódovým označením Rome představovat. V laboratoři HPC and AI Innovation Lab
jsme v posledních měsících vyhodnocovali systémy založené na architektuře Rome a společnost Dell Technologies nedávno představila
servery, které tuto procesorovou architekturu podporují. První blog ze série Rome se zabývá architekturou procesoru Rome, možností jeho vyladění pro výkon HPC a představuje počáteční výkon mikro srovnávacího testu. Následující blogy popisují výkon aplikací v oblastech CFD, CAE, molekulární dynamiky, simulace počasí a dalších aplikací.
Architektura
Rome je procesor AMD EPYC 2. generace, který obnovuje 1. generaci Naples.
Jedním z největších architektonických rozdílů mezi verzí Naples a Rome, který přináší výhody pro HPC, je nová matice IO ve verzi Rome. Ve verzi Rome je každý procesor vícečipový balíček složený až z devíti čipů, jak je znázorněno na obrázku 1. K dispozici je jeden centrální 14nm IO čip, který obsahuje všechny IO a paměťové funkce – například paměťové řadiče, linky Infinity Fabric v rámci socketu a mezisocketové propojení a PCI-e. Na každý socket připadá osm paměťových řadičů, které podporují osm paměťových kanálů s DDR4 při 3 200 MT/s. Jednosocketový server může podporovat až 130 linek PCIe 4. generace. Dvousocketový systém podporuje až 160 linek PCIe 4. generace.
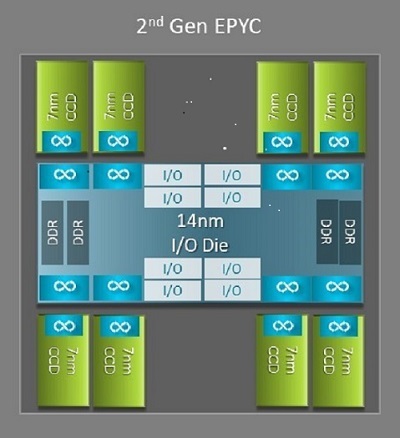
(Obrázek 1 Vícečipový balíček Rome s jedním centrálním čipem IO a až osmijádrovými čipy)
Kolem centrálního čipu IO je až osm 7nm jádrových čipů. Čip jádra se nazývá Core Cache Die neboli CCD. Každý čip CCD má jádra procesoru založená na mikroarchitektuře Zen2, L2 cache a 32MB L3 cache. Samotný čip CCD má dva bloky Core Cache Complexes (CCX) , každý blok CCX má až čtyři jádra a 16MB L3 cache. Obrázek 2 znázorňuje blok CCX.

(Obrázek 2 Blok CCX se čtyřmi jádry a sdílenou 16MB L3 cache)
Různé modely procesorů Rome mají různý počet jader
, ale všechny mají jeden centrální čip IO.
Na horním konci je model procesoru s 64 jádry, například EPYC 7702. Výstup lstopo nám ukazuje, že tento procesor má 16 bloků CCX na socket, každý blok CCX má 4 jádra, jak je znázorněno na obrázku 3 a 4, což dává 64 jader na socket. 16 MB L3 na blok CCX, tedy 32 MB L3 na čip CCD, dává tomuto procesoru 256 MB L3 cache. Všimněte si však, že celková cache L3 v architektuře Rome není sdílena všemi jádry. 16MB cache L3 v každém bloku CCX je nezávislá a je sdílena pouze jádry v bloku CCX, jak je znázorněno na obrázku 2.
24jádrový procesor, jako je EPYC 7402, má 128 MB cache L3. Výstup lstopo na obrázku 3 a 4 ukazuje, že tento model má 3 jádra na blok CCX a 8 bloků CCX na socket.


(Obrázek 3 a 4: Výstup lstopo pro 64jádrové a 24jádrové procesory)
Bez ohledu na počet čipů CCD je každý procesor Rome logicky rozdělen do 4 kvadrantů u čipů CCD distribuovanými co nejrovnoměrněji napříč kvadranty a dvěma paměťovými kanály v každém kvadrantu. Centrální čip IO si lze považovat za logickou podporu 4 kvadrantů socketu.
Možnosti systému BIOS vycházející z architektury Rome
Centrální čip IO v architektuře Rome pomáhá zlepšit latenci paměti oproti té, která byla naměřena v architektuře Naples. Umožňuje také nakonfigurovat procesor jako jednu doménu NUMA, což vytváří podmínky pro jednotný přístup k paměti pro všechna jádra v socketu. To je vysvětleno níže.
Čtyři logické kvadranty v procesoru Rome umožňují rozdělit procesor do různých domén NUMA. Toto nastavení se nazývá NUMA per Socket neboli NPS.
- NPS1 znamená, že procesor Rome je jedna doména NUMA se všemi jádry v socketu a veškerou pamětí v této jedné doméně NUMA. Paměť je prokládána napříč osmi paměťovými kanály. Všechna zařízení PCIe na socketu patří do této jediné domény NUMA.
- Server NPS2 rozdělí procesor do dvou domén NUMA s polovinou jader a polovinou paměťových kanálů na socketu v každé doméně NUMA. Paměť je prokládaná napříč čtyřmi paměťovými kanály v každé doméně NUMA
- Server NPS4 rozdělí procesor do čtyř domén NUMA. Každý kvadrant je zde doménou NUMA a paměť je prokládána přes dva paměťové kanály v každém kvadrantu. Zařízení PCIe jsou místní pro jednu ze čtyř domén NUMA na socketu v závislosti na tom, který kvadrant čipu IO má kořen PCIe pro dané zařízení.
- Ne všechny procesory podporují všechna nastavení serveru NPS.
Tam, kde je k dispozici, se pro HPC doporučuje NPS4, protože se očekává, že poskytne nejlepší šířku pásma paměti, nejnižší latenci paměti a naše aplikace obvykle podporují technologii NUMA. Pokud NPS4 není k dispozici, doporučujeme nejvyšší NPS podporovaný modelem procesoru – NPS2, nebo dokonce NPS1.
Vzhledem k velkému množství možností NUMA, které jsou k dispozici na platformách Rome, umožňuje systém BIOS serveru PowerEdge v rámci výčtu MADT dvě různé metody výčtu jader. Lineární výčet čísel jader v pořadí, vyplnění jednoho bloku CCX, čipu CCD, socketu před přechodem na další socket. Na procesoru 32c jsou jádra 0 až 31 na prvním socketu a jádra 32–63 na druhém socketu. Kruhové dotazování čísluje jádra napříč oblastmi NUMA. V tomto případě jsou sudá jádra na prvním socketu a lichá jádra na druhém socketu. Pro zjednodušení doporučujeme lineární výčet pro HPC. Na obrázku 5 je uveden příklad lineárního výčtu jader na dvousocketovém serveru 64c nakonfigurovaném v NPS4. Na obrázku představuje každá skupina čtyř jader CCX, každá skupina osmi sousedících jader představuje čip CCD.
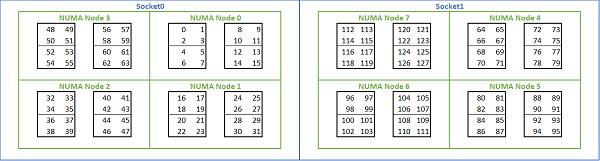
(Obrázek 5 Lineární výčet jader v systému se dvěma sockety, 64c na socket, konfigurace NPS4 v modelu procesoru s osmi čipy CCD)
Další volba systému BIOS specifická pro architekturu Rome se nazývá Preferred IO Device. Jedná se o důležitý ovládací prvek pro nastavení šířky pásma InfiniBand a rychlosti přenosu zpráv. Umožňuje platformě upřednostnit provoz pro jedno zařízení IO. Tato možnost je k dispozici na platformách Rome s jedním a dvěma sockety a zařízení InfiniBand v platformě musí být vybráno jako preferované zařízení v nabídce BIOS, aby bylo možné dosáhnout plné rychlosti přenosu zpráv, když jsou aktivní všechna jádra procesoru.
Podobně jako Naples podporuje i architektura Rome hyper-threading nebo logický procesor. Pro HPC tuto funkci necháváme deaktivovanou, ale některé aplikace mohou z aktivace logického procesoru těžit. Sledujte naše další blogy o studiích aplikací molekulární dynamiky.
Podobně jako Naples umožňuje i architektura Rome blok CCX jako doménu NUMA. Tato možnost zpřístupňuje každý blok CCX jako uzel NUMA. V systému s dvousocketovými procesory s 16 bloky CCX na procesor toto nastavení zpřístupňuje 32 domén NUMA. V tomto příkladu má každý socket osm čipů CCD, tedy 16 bloků CCX. Každý blok CCX může být povolen jako vlastní doména NUMA, což dává 16 uzlů NUMA na socket a 32 v systému se dvěma sockety. V případě HPC doporučujeme ponechat možnost CCX as NUMA Domain ve výchozím nastavení Disabled. Očekává se, že povolení této možnosti pomůže virtualizovaným prostředím.
Podobně jako Naples i architektura Rome umožňuje nastavit systém v režimu Performance Determinism nebo Power Determinism. V režimu Performance Determinism systém pracuje s očekávanou frekvencí pro model procesoru, což snižuje variabilitu mezi více servery. V režimu Power Determinism systém pracuje s maximálním dostupným TDP modelu procesoru. To zesiluje rozdíly ve výrobním procesu mezi díly, což umožňuje, aby některé servery byly rychlejší než jiné. Všechny servery mohou spotřebovávat maximální jmenovitý výkon procesoru, takže spotřeba energie je deterministická, ale umožňuje určité rozdíly ve výkonu napříč více servery.
Jak se dá očekávat u platforem PowerEdge, systém BIOS obsahuje meta možnost nazvanou System Profile. Výběrem profilu systému Performance-Optimized povolíte režim Turbo Boost, zakážete stavy C a nastavíte posuvník determinismu na hodnotu Power Determinism, čímž optimalizujete výkon.
Výsledky výkonu – mikro srovnávací testy STREAM, HPL, InfiniBand
Mnoho našich čtenářů možná skočilo rovnou na tuto část, takže se do ní rovnou ponoříme.
V laboratoři HPC and AI Innovation Lab jsme vytvořili cluster s 64 servery v architektuře Rome, kterému říkáme Minerva. Kromě homogenního clusteru Minerva máme několik dalších vzorků procesorů Rome, které bychom mohli vyhodnotit. Náš testbed je popsán v tabulce 1 a tabulce 2.
(Tabulka 1 Modely procesoru v architektuře Rome hodnocené v této studii)
| Procesor | Počet jader na socket | Config | Základní taktovací frekvence | TDP |
|---|---|---|---|---|
| 7702 | 64c | 4c na blok CCX | 2,0 GHz | 200 W |
| 7502 | 32c | 4c na blok CCX | 2,5 GHz | 180W |
| 7452 | 32c | 4c na blok CCX | 2,35 GHz | 155W |
| 7402 | 24c | 3c na blok CCX | 2,8 GHz | 180W |
(Tabulka 2 Testbed)
| Komponentní | Podrobnosti |
|---|---|
| Server | PowerEdge C6525 |
| Procesor | Jak je uvedeno v tabulce 1: Dva sockety |
| Paměť | 256 GB, 16x 16 GB, 3 200 MT/s, DDR4 |
| Interconnect | ConnectX-6 Mellanox Infini Band HDR100 |
| Operační systém | Red Hat Enterprise Linux 7.6 |
| Jádro | 3.10.0.957.27.2.e17.x86_64 |
| Disk | 240GB modul SATA SSD M.2 |
STREAM
Testy šířky pásma paměti v architektuře Rome jsou znázorněny na obrázku 6. Tyto testy probíhaly v režimu NPS4. Naměřili jsme šířku pásma paměti zhruba 270–300 GB/s na našem dvousocketovém serveru PowerEdge C6525 při využití všech jader serveru ve všech čtyřech modelech procesorů uvedených v tabulce 1. Pokud je na jeden blok CCX použito pouze jedno jádro, šířka pásma systémové paměti je zhruba 9–17 % vyšší než šířka pásma se všemi jádry.
Většina úloh HPC buď plně využívá všechna jádra v systému, nebo centra HPC běží v režimu vysoké propustnosti s více úlohami na každém serveru. Proto je šířka pásma paměti všech jader přesnější reprezentací šířky pásma paměti a schopností šířky pásma paměti na jádro systému.
Obrázek 6 také znázorňuje propustnost paměti naměřenou na předchozí generaci platformy EPYC Naples, která také podporovala osm paměťových kanálů na socket, ale běžela rychlostí 2667 MT/s. Platforma Rome poskytuje o 5 až 19 % lepší celkovou propustnost paměti než Naples, a to především díky rychlejší paměti 3 200 MT/s. Dokonce i s 64c na socket může systém Rome dodávat až 2 GB/s na jádro.
Při porovnání různých konfigurací serveru NPS byla u NPS4 naměřena zhruba o 13 % vyšší šířka pásma paměti ve srovnání s NPS1, jak je znázorněno na obrázku 7.

(Obrázek 6: Šířka pásma paměti NPS4 STREAM Triad se dvěma sockety)

(Obrázek 7 Šířka pásma paměti NPS1 vs. NPS2 vs. NPS4)
Šířka pásma a rychlost zpráv InfiniBand
Obrázek 8 znázorňuje šířku pásma InfiniBand s jedním jádrem pro jednosměrné a obousměrné testy. Testovací prostředí používalo HDR100 při 100 Gb/s a graf ukazuje očekávaný výkon rychlosti linek pro tyto testy.
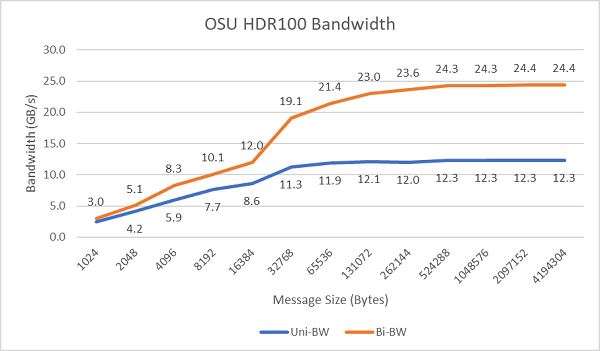
Obrázek 8 Šířka pásma InfiniBand (jedno jádro)

Obrázek 9 Rychlost zpráv InfiniBand (všechna jádra))
Dále byly provedeny testy rychlosti přenosu zpráv se všemi jádry socketu na dvou testovaných serverech. Když je v systému BIOS povolena funkce Preferred IO a adaptér ConnectX-6 HDR100 je nakonfigurován jako preferované zařízení, rychlost zpráv všech jader je vyšší, než když preferovaný IO není povolen, jak je znázorněno na obrázku 9. To ilustruje důležitost této možnosti systému BIOS při ladění pro HPC a zejména při škálování aplikací s více uzly.
HPL
Mikroarchitektura Rome dokáže vyřadit 16 DP FLOP/cyklus, což je dvojnásobek oproti architektuře Naples, která měla 8 FLOP/cyklus. To dává architektuře Rome 4x teoretický špičkový výkon FLOPS oproti Naples, 2x díky vylepšené schopnosti plovoucí desetinné čárky a 2x díky dvojnásobnému počtu jader (64c vs. 32c). Obrázek 10 znázorňuje naměřené výsledky HPL pro čtyři modely procesoru Rome, které jsme testovali, spolu s našimi předchozími výsledky ze systému založeného na architektuře Naples. Účinnost Rome HPL je uvedena jako procentuální hodnota nad sloupci v grafu a je vyšší u modelů procesorů s nižším TDP.
Testy byly provedeny v režimu Power Determinism a byl naměřen zhruba 5% rozdíl ve výkonu u 64 identicky nakonfigurovaných serverů, výsledky zde jsou tedy v tomto výkonnostním pásmu.

(Obrázek 10 HPL pro jeden server v NPS4)
Dále byly provedeny testy HPL s více uzly a tyto výsledky jsou uvedeny na obrázku 11. Účinnost HPL pro EPYC 7452 zůstává nad 90 % v měřítku 64 uzlů, ale poklesy účinnosti ze 102 % dolů na 97 % a zpět na 99 % vyžadují další vyhodnocení.

(Obrázek 11 HPL s více uzly, dvousocketový procesor EPYC 7452 přes HDR100 InfiniBand)
Shrnutí a další kroky:
Úvodní studie výkonu serverů z architektury Rome ukazují očekávaný výkon pro naši první sadu srovnávacích testů HPC. Ladění systému BIOS je důležité při konfiguraci maximálního výkonu. Možnosti ladění jsou k dispozici v profilu zátěže BIOS HPC, který lze nakonfigurovat ve výrobě nebo nastavit pomocí nástrojů pro správu systémů Dell EMC.
Laboratoře HPC and AI Innovation Lab má nový cluster PowerEdge Minerva se 64 servery na bázi architektury Rome. Sledujte tento prostor, kde budou zveřejňovány další blogy popisující studie výkonu aplikací na našem novém clusteru Minerva.