PowerFlex : Dépannage des conflits d’accès aux ressources
요약: Problèmes de conflits d’accès aux ressources PowerFlex et dépannage
이 문서는 다음에 적용됩니다.
이 문서는 다음에 적용되지 않습니다.
이 문서는 특정 제품과 관련이 없습니다.
모든 제품 버전이 이 문서에 나와 있는 것은 아닙니다.
증상
Un comportement anormal des processus PowerFlex se produit lorsque les processus PowerFlex entrent en conflit d’accès aux ressources avec d’autres composants logiciels ou matériels.
Les symptômes ici peuvent être nombreux et variés. Ceci est une liste partielle des symptômes et des résultats
Problèmes liés au MDM :
- Le basculement de la propriété MDM se produit lorsque les processus MDM se bloquent et perdent la communication avec les autres MDM.
From exp.0:
Panic in file /emc/svc_flashbld/workspace/ScaleIO-RHEL7/src/mos/umt/mos_umt_sched_thrd.c, line 1798, function mosUmtSchedThrd_SuspendCK, PID 36721.Panic Expression ALWAYS_ASSERT Scheduler guard seems to be dead.
From trc.*
24/02 15:54:16.087919 0:schedThrdGuard_SampleLivnes:01463: WARNING: pThread 0x106d9360(0) in scheduler 0x7fff580c4880, running UMT 0x7f39ad00ceb8, found to be stuck.
24/02 15:54:16.088226 ad417eb8:actorLoop_IsSchedThredStuck:10932: Stuck scheduler thread identified
24/02 15:54:16.088253 ad417eb8:actor_Loop:11257: Lost quorum. ourVoters: 0 votersOwnedByOther: [0,0]
24/02 15:54:16.088299 ---Planned crash, reason: Lost quorum, going down to let another MDM become master ---
- Le processus MDM se déconnectera et se reconnectera constamment pendant un certain temps
2017-02-23 14:00:43.241 MDM_CLUSTER_LOST_CONNECTION WARNING The MDM, ID 089012db4d536880, lost connection
2017-02-23 14:00:43.422 MDM_CLUSTER_CONNECTED INFO The MDM, ID 089012db4d536880, connected
2017-02-23 23:05:25.852 MDM_CLUSTER_LOST_CONNECTION WARNING The MDM, ID 089012db4d536880, lost connection
2017-02-23 23:05:26.422 MDM_CLUSTER_CONNECTED INFO The MDM, ID 089012db4d536880, connected
2017-02-24 15:54:16.141 MDM_CLUSTER_LOST_CONNECTION WARNING The MDM, ID 089012db4d536880, lost connection
2017-02-24 15:54:16.238 MDM_CLUSTER_CONNECTED INFO The MDM, ID 089012db4d536880, connected
Problèmes liés aux SDS :
- Le SDS se déconnectera et se reconnectera constamment pendant un certain temps
2017-02-15 13:18:16.881 SDS_RECONNECTED INFO SDS: siosds2 (ID 1eb052fe00000001) reconnected
2017-02-16 03:37:37.327 SDS_DECOUPLED ERROR SDS: siosds2 (id: 1eb052fe00000001) decoupled.
2017-02-16 03:39:54.300 SDS_RECONNECTED INFO SDS: siosds2 (ID 1eb052fe00000001) reconnected
2017-02-17 04:03:41.757 SDS_DECOUPLED ERROR SDS: siosds2 (id: 1eb052fe00000001) decoupled.
2017-02-17 04:09:13.604 SDS_RECONNECTED INFO SDS: siosds2 (ID 1eb052fe00000001) reconnected
- Le SDS peut afficher des erreurs oscillantes dans les fichiers trc concernant la perte de connectivité à d’autres nœuds SDS :
14/02 19:13:24.096983 1be7eb8:contNet_OscillationNotif:01675: Con 1eb052fe00000005 - Oscillation of type 5 (RPC_LINGERED_1SEC) reported
14/02 19:13:24.196814 1be7eb8:contNet_OscillationNotif:01675: Con 1eb053000000000b - Oscillation of type 5 (RPC_LINGERED_1SEC) reported
14/02 19:13:24.296713 1be7eb8:contNet_OscillationNotif:01675: Con 1eb0530000000007 - Oscillation of type 5 (RPC_LINGERED_1SEC) reported
14/02 21:48:43.917218 afb28eb8:contNet_OscillationNotif:01675: Con 1eb052fe00000007 - Oscillation of type 1 (SOCKET_DOWN) reported
14/02 21:48:43.917296 afb28eb8:contNet_OscillationNotif:01675: Con 1eb052fe00000005 - Oscillation of type 1 (SOCKET_DOWN) reported
- Le SDS peut afficher des threads bloqués ou bloqués dans les fichiers trc :
14/02 19:13:24.147938 9aa4eeb8:netPath_IsKaNeeded:01789: DEBUG ASSERT, Reason:Socket deadlocked. Crashing.
14/02 19:13:24.148113 9aa4eeb8:netPath_IsKaNeeded:01789: DEBUG ASSERT, Reason:Socket deadlocked. Crashing.
14/02 19:13:24.148121 9aa4eeb8:netPath_IsKaNeeded:01789: DEBUG ASSERT, Reason:Socket deadlocked. Crashing.
14/02 20:52:54.097765 242f0eb8:kalive_StartIntr:00346: KA aborted due to stuck sched thread
14/02 21:48:43.510602 7fa30eb8:kalive_StartIntr:00346: KA aborted due to stuck sched thread
14/02 21:48:44.776713 1b67ceb8:kalive_StartIntr:00346: KA aborted due to stuck sched thread
14/02 02:44:41.532007 e2239eb8:contNet_OscillationNotif:01675: Con 1eb052fd00000001 - Oscillation of type 3 (RCV_KA_DISCONNECT) reported
14/02 02:44:43.799135 0:schedThrdGuard_SampleLivnes:01463: WARNING: pThread 0x1a0de10(0) in scheduler 0x7fff01bec400, running UMT 0x7f94e221eeb8, found to be stuck.
14/02 02:44:43.799155 0:schedThrdGuard_SampleLivnes:01463: WARNING: pThread 0x1a0e050(1) in scheduler 0x7fff01bec400, running UMT 0x7f94e2227eb8, found to be stuck.
14/02 02:44:43.799257 e0e38eb8:cont_IsSchedThredStuck:01678: Stuck scheduler thread identified
14/02 02:44:43.799267 e0e38eb8:kalive_StartIntr:00346: KA aborted due to stuck sched thread
- Le SDS peut afficher une « erreur de bifurcation » dans les fichiers trc :
01/09 00:37:51.329020 0x7f1001c58eb0:mosDbg_BackTraceAllOsThreads:00673: Error forking.
- Le SDS ne peut pas démarrer en raison d’un échec de l’allocation de mémoire requise.
Les éléments suivants sont consignés dans les fichiers journaux exp :
07/09 00:41:52.713502 Panic in file /data/build/workspace/ScaleIO-SLES12-2/src/mos/usr/mos_utils.c, line 235, function mos_AllocPageAlignedOrPanic, PID 25342.Panic Expression pMem != ((void *)0) .
- Le système d’exploitation peut également présenter certains symptômes dans /var/log/messages ou les journaux d’événements système :
/var/log/messages:
Feb 14 13:25:08 ScaleIO-192-168-1-2 kernel: [7461116.683555] TCP: Possible SYN flooding on port 7072. Sending cookies.
Feb 14 13:25:08 ScaleIO-192-168-1-2 kernel: [7461116.683561] TCP: Possible SYN flooding on port 7072. Sending cookies.
Feb 14 13:25:08 ScaleIO-192-168-1-2 kernel: [7461116.683566] TCP: Possible SYN flooding on port 7072. Sending cookies.
Feb 14 13:25:08 ScaleIO-192-168-1-2 kernel: [7461116.683570] TCP: Possible SYN flooding on port 7072. Sending cookies.
Feb 14 13:27:39 ScaleIO-192-168-1-2 kernel: [7461266.566145] sched: RT throttling activated
Les messages « SYN flooding on port 7072 » signifient que des paquets de données réseau sont envoyés au SDS sur cet hôte et que le SDS ne peut pas accepter les paquets sur ce port. Le SDS utilise le port 7072 par défaut.
« RT throttling activated » est un message indiquant que le planificateur du système d’exploitation a identifié certains threads en temps réel qui monopolisent le processeur et privent les autres threads. Le système d’exploitation le fait pour tenter de limiter ces tâches en temps réel et d’empêcher le système d’exploitation de se bloquer ou de planter.
Problèmes liés à la DDC :
Le SDC peut également subir des erreurs d’E/S lorsque les SDS se déconnectent fréquemment ou ne peuvent pas répondre au SDC assez rapidement et essaient toujours de gérer les blocs d’E/S qu’il possède.
Impact
Les symptômes ci-dessus peuvent entraîner des DATA_DEGRADED, des événements DATA_FAILED ainsi que des CLUSTER_DEGRADED.
원인
Si tous les symptômes ci-dessus correspondent, il s’agit probablement d’un problème de manque de ressources de processeur ou de mémoire. Recherchez les applications ou processus tiers en cours d’exécution susceptibles d’affecter le processeur et la mémoire des processus MDM ou SDS.
Dans un environnement virtuel, il est arrivé que le processeur présente des performances médiocres. Cela est dû au fait que les SVM sont définies dans le même pool de ressources.
Dans ce cas, il est conseillé de ne pas placer les SVM dans un pool de ressources, mais de disposer de leurs ressources dédiées, telles que définies dans la SVM.
해결
Assurez-vous que les composants PowerFlex (MDM, SDS, SDC) ont été réglés pour les paramètres de performances. Consultez les guides de « réglage fin » et de « dépannage » des performances disponibles ici.
Vérification de la configuration :
- Tout d’abord, confirmez que les paramètres CPU et RAM de la SVM sont conformes aux pratiques d’excellence :
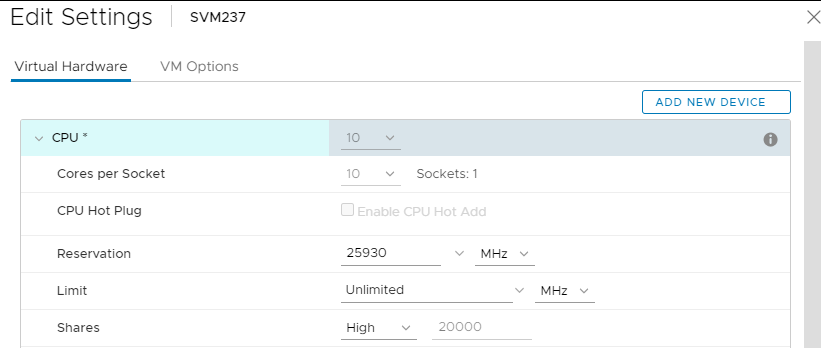
- Paramètres du processeur SVM : (Peut être réglé à la volée)
- Cores per Socket : le tout dans un seul socket, donc « Sockets » a une valeur de « 1 ». (Le nombre global de cœurs est déterminé par les besoins du SDS qu’il héberge : Les technologies All-Flash, FG, DASCache, Cloudlink, 3.5, etc., ont toutes un impact (augmentent) sur les besoins en CPU.)
- Réservation: Sélectionnez la valeur « Maximum » dans la liste déroulante.
- Actions: Élevé
- Cela devrait ressembler à ceci :
- Paramètres du processeur SVM : (Peut être réglé à la volée)
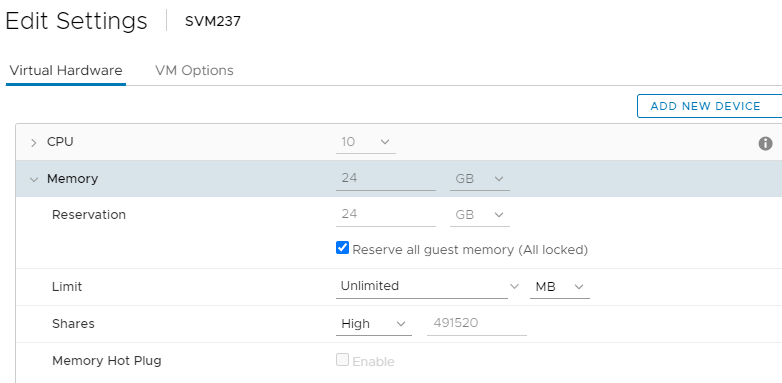
b. Paramètres de la RAM SVM : (Peut être réglé à la volée)
- Cochez la case « Réserver toute la mémoire invité (toutes verrouillées) »
- Actions: Élevé
- Cela devrait ressembler à ceci :
c. Paramètres de surallocation de la mémoire du système d’exploitation SVM invité : (Redémarrage requis)
-
- Exécutez sysctl -a|grep overcommit pour confirmer que les paramètres de surallocation sont corrects :
# sysctl -a|grep overcommit vm.overcommit_memory = 2 vm.overcommit_ratio = 100 -
Si les valeurs ci-dessus ne sont pas définies, une partie de la mémoire SVM sera inutilisable pour le processus SDS. Corrigez ce problème en éditant le fichier /etc/sysctl.conf et en modifiant/ajoutant les valeurs ci-dessus
- Placez le SDS en mode maintenance, puis redémarrez la SVM pour appliquer les paramètres
- Confirmez en exécutant « cat /etc/sysctl.conf|grep overcommit » après le redémarrage
- Quitter le mode maintenance
- Exécutez sysctl -a|grep overcommit pour confirmer que les paramètres de surallocation sont corrects :
- Pour les trouver dans les journaux :
- Configuration SVM (vmsupport) :
-
Un fichier .vmx de SVM correctement configuré contient les éléments suivants :
-
- Configuration SVM (vmsupport) :
sched.cpu.units = "mhz"
sched.cpu.affinity = "all"
sched.cpu.min = "25930" (nonzero value that's equal to core speed * the # of cores allocated)
sched.cpu.shares = "high"
sched.mem.min = "24576" (nonzero value that's a full allocation of configured memory)
sched.mem.minSize = "24576" (nonzero value that's a full allocation of configured memory)
sched.mem.shares = "high"
cpuid.coresPerSocket = "10" (value equal to total # of cores allocated, so they're all in one socket)
sched.mem.pin = "TRUE"
- Les SVMconfigs incorrectes (obsolètes) comportent les éléments suivants :
sched.cpu.min = "0"
sched.cpu.shares = "normal"
sched.mem.pin = "FALSE"
sched.mem.shares = "normal"
cpuid.coresPerSocket = "4" (value less than total # of cores allocated, usually 1/2 or 1/4)
Configuration du système d’exploitation invité (getinfo) :
-
Surallocation de mémoire correctement configurée :
Le serveur/sysctl.txt de fichiers contient :
vm.overcommit_memory = 2
vm.overcommit_ratio = 100
-
PowerFlex utilise une quantité considérable de RAM pour que chacun des services s’exécute en mémoire et à grande vitesse. C’est pourquoi il ne prend pas en charge l’utilisation de swap pour décharger l’un des services PowerFlex.
Le paramètre par défaut, qui est attendu pour le stockage uniquement et les SVM dans une solution HCI, est une mémoire de surallocation de 2. De cette façon, le noyau ne surchargera pas la mémoire et, sans paramètres de non-permutation, il garantit qu’aucune valeur de commit_as n’est supérieure à la mémoire totale/disponible.
Le rapport de 100 garantit également qu’aucun échange n’est utilisé, pour plus de contrôle par rapport à l’échange de blocs utilisé.
-
Surallocation de mémoire mal configurée :
le serveur/sysctl.txt de fichiers contient :
vm.overcommit_memory = 0 (value not 2)
vm.overcommit_ratio = 50 (value less than 95)
Autres solutions de contournement possibles :
- Arrêtez les applications à l’origine de la panne de ressources de processeur/mémoire ou vérifiez auprès du fournisseur d’applications les mises à jour permettant de réduire l’accaparement des ressources.
- Utilisez les outils de tendances du processeur/mémoire (tâches top/sar/cron/etc.) pour identifier l’application qui utilise les ressources. Des intervalles de 1 seconde sont recommandés pour obtenir la granularité nécessaire pour savoir quand le problème se produit et qui est responsable
- Mettre à niveau le processeur et/ou la mémoire de l’hôte pour lui donner plus de ressources
- Recréez l’architecture vers une configuration à deux couches plutôt qu’un système convergé (si les SDS/SDC se trouvent sur le même hôte)
추가 정보
문서 속성
문서 번호: 000167765
문서 유형: Solution
마지막 수정 시간: 24 11월 2025
버전: 5
다른 Dell 사용자에게 질문에 대한 답변 찾기
지원 서비스
디바이스에 지원 서비스가 적용되는지 확인하십시오.