PowerFlex: Risoluzione dei problemi di conflitto delle risorse
요약: Problemi di conflitto delle risorse PowerFlex e risoluzione dei problemi
이 문서는 다음에 적용됩니다.
이 문서는 다음에 적용되지 않습니다.
이 문서는 특정 제품과 관련이 없습니다.
모든 제품 버전이 이 문서에 나와 있는 것은 아닙니다.
증상
Il comportamento anomalo dei processi PowerFlex si verifica quando i processi PowerFlex si imbattono in un conflitto di risorse con altri componenti software o hardware.
I sintomi qui possono essere molti e vari. Questo è un elenco parziale dei sintomi e dei risultati
Problemi dell MDM:
- Il failover della proprietà MDM si verifica quando i processi MDM si bloccano e perdono la comunicazione con gli altri MDM
From exp.0:
Panic in file /emc/svc_flashbld/workspace/ScaleIO-RHEL7/src/mos/umt/mos_umt_sched_thrd.c, line 1798, function mosUmtSchedThrd_SuspendCK, PID 36721.Panic Expression ALWAYS_ASSERT Scheduler guard seems to be dead.
From trc.*
24/02 15:54:16.087919 0:schedThrdGuard_SampleLivnes:01463: WARNING: pThread 0x106d9360(0) in scheduler 0x7fff580c4880, running UMT 0x7f39ad00ceb8, found to be stuck.
24/02 15:54:16.088226 ad417eb8:actorLoop_IsSchedThredStuck:10932: Stuck scheduler thread identified
24/02 15:54:16.088253 ad417eb8:actor_Loop:11257: Lost quorum. ourVoters: 0 votersOwnedByOther: [0,0]
24/02 15:54:16.088299 ---Planned crash, reason: Lost quorum, going down to let another MDM become master ---
- Il processo MDM si disconnetterà e si riconnetterà costantemente per un certo periodo di tempo
2017-02-23 14:00:43.241 MDM_CLUSTER_LOST_CONNECTION WARNING The MDM, ID 089012db4d536880, lost connection
2017-02-23 14:00:43.422 MDM_CLUSTER_CONNECTED INFO The MDM, ID 089012db4d536880, connected
2017-02-23 23:05:25.852 MDM_CLUSTER_LOST_CONNECTION WARNING The MDM, ID 089012db4d536880, lost connection
2017-02-23 23:05:26.422 MDM_CLUSTER_CONNECTED INFO The MDM, ID 089012db4d536880, connected
2017-02-24 15:54:16.141 MDM_CLUSTER_LOST_CONNECTION WARNING The MDM, ID 089012db4d536880, lost connection
2017-02-24 15:54:16.238 MDM_CLUSTER_CONNECTED INFO The MDM, ID 089012db4d536880, connected
Problemi dell SDS:
- L SDS si disconnetterà e si riconnetterà costantemente per un certo periodo di tempo
2017-02-15 13:18:16.881 SDS_RECONNECTED INFO SDS: siosds2 (ID 1eb052fe00000001) reconnected
2017-02-16 03:37:37.327 SDS_DECOUPLED ERROR SDS: siosds2 (id: 1eb052fe00000001) decoupled.
2017-02-16 03:39:54.300 SDS_RECONNECTED INFO SDS: siosds2 (ID 1eb052fe00000001) reconnected
2017-02-17 04:03:41.757 SDS_DECOUPLED ERROR SDS: siosds2 (id: 1eb052fe00000001) decoupled.
2017-02-17 04:09:13.604 SDS_RECONNECTED INFO SDS: siosds2 (ID 1eb052fe00000001) reconnected
- L SDS potrebbe mostrare errori di oscillazione nei file trc relativi alla perdita di connettività ad altri nodi SDS:
14/02 19:13:24.096983 1be7eb8:contNet_OscillationNotif:01675: Con 1eb052fe00000005 - Oscillation of type 5 (RPC_LINGERED_1SEC) reported
14/02 19:13:24.196814 1be7eb8:contNet_OscillationNotif:01675: Con 1eb053000000000b - Oscillation of type 5 (RPC_LINGERED_1SEC) reported
14/02 19:13:24.296713 1be7eb8:contNet_OscillationNotif:01675: Con 1eb0530000000007 - Oscillation of type 5 (RPC_LINGERED_1SEC) reported
14/02 21:48:43.917218 afb28eb8:contNet_OscillationNotif:01675: Con 1eb052fe00000007 - Oscillation of type 1 (SOCKET_DOWN) reported
14/02 21:48:43.917296 afb28eb8:contNet_OscillationNotif:01675: Con 1eb052fe00000005 - Oscillation of type 1 (SOCKET_DOWN) reported
- SDS può mostrare thread bloccati o bloccati nei file trc:
14/02 19:13:24.147938 9aa4eeb8:netPath_IsKaNeeded:01789: DEBUG ASSERT, Reason:Socket deadlocked. Crashing.
14/02 19:13:24.148113 9aa4eeb8:netPath_IsKaNeeded:01789: DEBUG ASSERT, Reason:Socket deadlocked. Crashing.
14/02 19:13:24.148121 9aa4eeb8:netPath_IsKaNeeded:01789: DEBUG ASSERT, Reason:Socket deadlocked. Crashing.
14/02 20:52:54.097765 242f0eb8:kalive_StartIntr:00346: KA aborted due to stuck sched thread
14/02 21:48:43.510602 7fa30eb8:kalive_StartIntr:00346: KA aborted due to stuck sched thread
14/02 21:48:44.776713 1b67ceb8:kalive_StartIntr:00346: KA aborted due to stuck sched thread
14/02 02:44:41.532007 e2239eb8:contNet_OscillationNotif:01675: Con 1eb052fd00000001 - Oscillation of type 3 (RCV_KA_DISCONNECT) reported
14/02 02:44:43.799135 0:schedThrdGuard_SampleLivnes:01463: WARNING: pThread 0x1a0de10(0) in scheduler 0x7fff01bec400, running UMT 0x7f94e221eeb8, found to be stuck.
14/02 02:44:43.799155 0:schedThrdGuard_SampleLivnes:01463: WARNING: pThread 0x1a0e050(1) in scheduler 0x7fff01bec400, running UMT 0x7f94e2227eb8, found to be stuck.
14/02 02:44:43.799257 e0e38eb8:cont_IsSchedThredStuck:01678: Stuck scheduler thread identified
14/02 02:44:43.799267 e0e38eb8:kalive_StartIntr:00346: KA aborted due to stuck sched thread
- L SDS potrebbe mostrare un "errore di biforcazione" nei file trc:
01/09 00:37:51.329020 0x7f1001c58eb0:mosDbg_BackTraceAllOsThreads:00673: Error forking.
- L SDS non può avviarsi a causa di una mancata allocazione della memoria richiesta.
Nei file exp log vengono riportati i seguenti elementi:
07/09 00:41:52.713502 Panic in file /data/build/workspace/ScaleIO-SLES12-2/src/mos/usr/mos_utils.c, line 235, function mos_AllocPageAlignedOrPanic, PID 25342.Panic Expression pMem != ((void *)0) .
- Anche il sistema operativo potrebbe avere alcuni sintomi in /var/log/messages o nei registri degli eventi di sistema:
/var/log/messages:
Feb 14 13:25:08 ScaleIO-192-168-1-2 kernel: [7461116.683555] TCP: Possible SYN flooding on port 7072. Sending cookies.
Feb 14 13:25:08 ScaleIO-192-168-1-2 kernel: [7461116.683561] TCP: Possible SYN flooding on port 7072. Sending cookies.
Feb 14 13:25:08 ScaleIO-192-168-1-2 kernel: [7461116.683566] TCP: Possible SYN flooding on port 7072. Sending cookies.
Feb 14 13:25:08 ScaleIO-192-168-1-2 kernel: [7461116.683570] TCP: Possible SYN flooding on port 7072. Sending cookies.
Feb 14 13:27:39 ScaleIO-192-168-1-2 kernel: [7461266.566145] sched: RT throttling activated
I messaggi "SYN flooding on port 7072" indicano che i pacchetti di dati di rete vengono inviati all SDS su questo host e l SDS non è in grado di accettare i pacchetti su tale porta. L SDS utilizza la porta 7072 per impostazione predefinita.
"RT throttling activated" è un messaggio indicante che l'utilità di pianificazione del sistema operativo ha identificato alcuni thread in tempo reale che monopolizzano la CPU e affamano altri thread. Il sistema operativo esegue questa operazione nel tentativo di limitare tali attività in tempo reale ed evitare il blocco o l'arresto anomalo del sistema operativo.
Problemi dell SDC:
L SDC può inoltre subire errori di I/O quando gli SDS si disconnettono frequentemente o non sono in grado di rispondere all SDC abbastanza rapidamente e stanno ancora tentando di riparare i blocchi di I/O di cui è proprietario.
Impatto
I sintomi di cui sopra possono provocare DATA_DEGRADED, eventi DATA_FAILED e CLUSTER_DEGRADED.
원인
Se tutti i sintomi di cui sopra corrispondono, è molto probabile che si tratti di un problema di esaurimento delle risorse di CPU o memoria. Cercare applicazioni o processi di terze parti in esecuzione che potrebbero ridurre la CPU e la memoria dei processi MDM o SDS.
In un'ambiente virtuale, un paio di volte la CPU ha avuto scarse prestazioni. Ciò è causato dal fatto che le SVM vengono definite nello stesso pool di risorse.
In questi casi, si consiglia di non inserire le SVM nel pool di risorse, ma di disporre delle relative risorse dedicate, come definito nella SVM.
해결
Assicurarsi che i componenti PowerFlex (MDM, SDS, SDC) siano stati ottimizzati per le impostazioni delle prestazioni. Consultare le guide "Fine-Tuning" e "Troubleshooting" delle prestazioni disponibili qui.
Revisione della configurazione:
- Innanzitutto, verificare che le impostazioni della CPU e della RAM della SVM siano conformi alla best practice:
- Impostazioni CPU SVM: (Può essere impostato al volo)
- Core per socket: all-in-one socket, quindi "Sockets" ha un valore pari a "1". (Il numero complessivo di core è determinato dalle esigenze dell SDS che ospita: All-Flash, FG, DASCache, Cloudlink, 3.5 e così via, tutti hanno un impatto (aumento) dei requisiti della CPU.)
- Prenotazione: Seleziona il valore "Massimo" nel menu a discesa
- Azioni: Alto
- L'aspetto dovrebbe essere simile al seguente:
- Impostazioni CPU SVM: (Può essere impostato al volo)
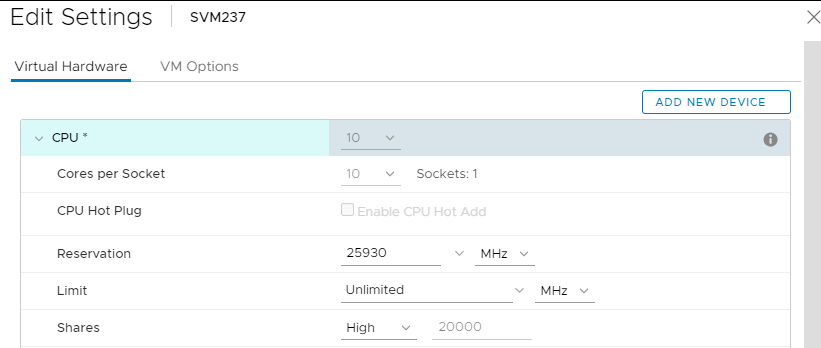
b. Impostazioni della RAM SVM: (Può essere impostato al volo)
- Seleziona "Prenota tutta la memoria ospite (Tutto bloccato)"
- Azioni: Alto
- L'aspetto dovrebbe essere simile al seguente:

c. Impostazioni di overcommit della memoria del sistema operativo SVM in-guest: (Richiede il riavvio)
-
- Eseguire sysctl -a|grep overcommit per confermare che le impostazioni di overcommit siano corrette:
# sysctl -a|grep overcommit vm.overcommit_memory = 2 vm.overcommit_ratio = 100 -
Se i valori di cui sopra non sono impostati, parte della memoria SVM sarà inutilizzabile per il processo SDS. Per correggere questo errore, modificare /etc/sysctl.conf e modificare/aggiungere i valori precedenti
- Impostare l SDS in modalità di manutenzione e riavviare la SVM per applicare le impostazioni
- Confermare eseguendo "cat /etc/sysctl.conf|grep overcommit" dopo il riavvio
- Uscita dalla modalità di manutenzione
- Eseguire sysctl -a|grep overcommit per confermare che le impostazioni di overcommit siano corrette:
- Per trovarli nei registri:
- Configurazione SVM (vmsupport):
-
Il file .vmx di una SVM contenuta correttamente conterrà quanto segue:
-
- Configurazione SVM (vmsupport):
sched.cpu.units = "mhz"
sched.cpu.affinity = "all"
sched.cpu.min = "25930" (nonzero value that's equal to core speed * the # of cores allocated)
sched.cpu.shares = "high"
sched.mem.min = "24576" (nonzero value that's a full allocation of configured memory)
sched.mem.minSize = "24576" (nonzero value that's a full allocation of configured memory)
sched.mem.shares = "high"
cpuid.coresPerSocket = "10" (value equal to total # of cores allocated, so they're all in one socket)
sched.mem.pin = "TRUE"
- Le SVMconfig errate (obsolete) presenteranno quanto segue:
sched.cpu.min = "0"
sched.cpu.shares = "normal"
sched.mem.pin = "FALSE"
sched.mem.shares = "normal"
cpuid.coresPerSocket = "4" (value less than total # of cores allocated, usually 1/2 or 1/4)
Configurazione del sistema operativo in-guest (getinfo):
-
Overcommit di memoria configurato correttamente:
Il file server/sysctl.txt contiene:
vm.overcommit_memory = 2
vm.overcommit_ratio = 100
-
Per l'esecuzione di ciascuno dei servizi in memoria e a velocità elevata, PowerFlex utilizza una notevole quantità di RAM. Questo è il motivo per cui non supporta l'utilizzo dello swap per eseguire l'offload dei servizi PowerFlex.
L'impostazione predefinita prevista per Storage Only e SVM in una soluzione HCI è un overcommit di memoria pari a 2. In questo modo il kernel non sovrascriverà la memoria e, senza impostazioni su nessun swap, assicurerà che nessun valore di commit_as sia maggiore della memoria totale libera/disponibile.
Il rapporto di 100 assicura che non venga utilizzato alcuno scambio, per un maggiore controllo sull'utilizzo dello scambio di blocchi.
-
Overcommit della memoria configurato in modo errato:
il file server/sysctl.txt contiene:
vm.overcommit_memory = 0 (value not 2)
vm.overcommit_ratio = 50 (value less than 95)
Altre possibili soluzioni alternative:
- Arrestare le applicazioni che causano l'esaurimento delle risorse di CPU/memoria o verificare con il fornitore dell'applicazione la disponibilità di aggiornamenti per alleviare il monopolio delle risorse.
- Utilizzare gli strumenti di tendenza di CPU/memoria (lavori top/sar/cron/ecc.) per scoprire quale applicazione sta prendendo le risorse. Si consigliano intervalli di 1 secondo per ottenere la granularità necessaria a mostrare quando si verifica il problema e chi ne è responsabile
- Aggiornare la CPU e/o la memoria dell host per ottenere più risorse
- Riprogettazione per una configurazione a due livelli anziché un sistema convergente (se SDS/SDC si trovano sullo stesso host)
추가 정보
문서 속성
문서 번호: 000167765
문서 유형: Solution
마지막 수정 시간: 24 11월 2025
버전: 5
다른 Dell 사용자에게 질문에 대한 답변 찾기
지원 서비스
디바이스에 지원 서비스가 적용되는지 확인하십시오.