PowerFlex:リソース競合のトラブルシューティング
요약: PowerFlexリソース競合の問題とトラブルシューティング
이 문서는 다음에 적용됩니다.
이 문서는 다음에 적용되지 않습니다.
이 문서는 특정 제품과 관련이 없습니다.
모든 제품 버전이 이 문서에 나와 있는 것은 아닙니다.
증상
PowerFlexプロセスで他のソフトウェアまたはハードウェア コンポーネントとのリソース競合が発生した場合、PowerFlexプロセスの異常な動作が発生します。
ここでの症状は多岐にわたります。これは、症状と結果の部分的なリストです
MDMの問題:
- MDMプロセスがスタックし、他のMDMとの通信が失われると、MDM所有権のフェールオーバーが発生します
From exp.0:
Panic in file /emc/svc_flashbld/workspace/ScaleIO-RHEL7/src/mos/umt/mos_umt_sched_thrd.c, line 1798, function mosUmtSchedThrd_SuspendCK, PID 36721.Panic Expression ALWAYS_ASSERT Scheduler guard seems to be dead.
From trc.*
24/02 15:54:16.087919 0:schedThrdGuard_SampleLivnes:01463: WARNING: pThread 0x106d9360(0) in scheduler 0x7fff580c4880, running UMT 0x7f39ad00ceb8, found to be stuck.
24/02 15:54:16.088226 ad417eb8:actorLoop_IsSchedThredStuck:10932: Stuck scheduler thread identified
24/02 15:54:16.088253 ad417eb8:actor_Loop:11257: Lost quorum. ourVoters: 0 votersOwnedByOther: [0,0]
24/02 15:54:16.088299 ---Planned crash, reason: Lost quorum, going down to let another MDM become master ---
- MDMプロセスは、一定時間にわたって切断と再接続を繰り返します
2017-02-23 14:00:43.241 MDM_CLUSTER_LOST_CONNECTION WARNING The MDM, ID 089012db4d536880, lost connection
2017-02-23 14:00:43.422 MDM_CLUSTER_CONNECTED INFO The MDM, ID 089012db4d536880, connected
2017-02-23 23:05:25.852 MDM_CLUSTER_LOST_CONNECTION WARNING The MDM, ID 089012db4d536880, lost connection
2017-02-23 23:05:26.422 MDM_CLUSTER_CONNECTED INFO The MDM, ID 089012db4d536880, connected
2017-02-24 15:54:16.141 MDM_CLUSTER_LOST_CONNECTION WARNING The MDM, ID 089012db4d536880, lost connection
2017-02-24 15:54:16.238 MDM_CLUSTER_CONNECTED INFO The MDM, ID 089012db4d536880, connected
SDSの問題:
- SDSは一定時間にわたって切断と再接続を繰り返します
2017-02-15 13:18:16.881 SDS_RECONNECTED INFO SDS: siosds2 (ID 1eb052fe00000001) reconnected
2017-02-16 03:37:37.327 SDS_DECOUPLED ERROR SDS: siosds2 (id: 1eb052fe00000001) decoupled.
2017-02-16 03:39:54.300 SDS_RECONNECTED INFO SDS: siosds2 (ID 1eb052fe00000001) reconnected
2017-02-17 04:03:41.757 SDS_DECOUPLED ERROR SDS: siosds2 (id: 1eb052fe00000001) decoupled.
2017-02-17 04:09:13.604 SDS_RECONNECTED INFO SDS: siosds2 (ID 1eb052fe00000001) reconnected
- SDSは、他のSDSノードへの接続喪失に関するtrcファイルに振動エラーを表示する場合があります。
14/02 19:13:24.096983 1be7eb8:contNet_OscillationNotif:01675: Con 1eb052fe00000005 - Oscillation of type 5 (RPC_LINGERED_1SEC) reported
14/02 19:13:24.196814 1be7eb8:contNet_OscillationNotif:01675: Con 1eb053000000000b - Oscillation of type 5 (RPC_LINGERED_1SEC) reported
14/02 19:13:24.296713 1be7eb8:contNet_OscillationNotif:01675: Con 1eb0530000000007 - Oscillation of type 5 (RPC_LINGERED_1SEC) reported
14/02 21:48:43.917218 afb28eb8:contNet_OscillationNotif:01675: Con 1eb052fe00000007 - Oscillation of type 1 (SOCKET_DOWN) reported
14/02 21:48:43.917296 afb28eb8:contNet_OscillationNotif:01675: Con 1eb052fe00000005 - Oscillation of type 1 (SOCKET_DOWN) reported
- SDSは、trcファイルでデッドロックまたはスタックしたスレッドを表示する場合があります。
14/02 19:13:24.147938 9aa4eeb8:netPath_IsKaNeeded:01789: DEBUG ASSERT, Reason:Socket deadlocked. Crashing.
14/02 19:13:24.148113 9aa4eeb8:netPath_IsKaNeeded:01789: DEBUG ASSERT, Reason:Socket deadlocked. Crashing.
14/02 19:13:24.148121 9aa4eeb8:netPath_IsKaNeeded:01789: DEBUG ASSERT, Reason:Socket deadlocked. Crashing.
14/02 20:52:54.097765 242f0eb8:kalive_StartIntr:00346: KA aborted due to stuck sched thread
14/02 21:48:43.510602 7fa30eb8:kalive_StartIntr:00346: KA aborted due to stuck sched thread
14/02 21:48:44.776713 1b67ceb8:kalive_StartIntr:00346: KA aborted due to stuck sched thread
14/02 02:44:41.532007 e2239eb8:contNet_OscillationNotif:01675: Con 1eb052fd00000001 - Oscillation of type 3 (RCV_KA_DISCONNECT) reported
14/02 02:44:43.799135 0:schedThrdGuard_SampleLivnes:01463: WARNING: pThread 0x1a0de10(0) in scheduler 0x7fff01bec400, running UMT 0x7f94e221eeb8, found to be stuck.
14/02 02:44:43.799155 0:schedThrdGuard_SampleLivnes:01463: WARNING: pThread 0x1a0e050(1) in scheduler 0x7fff01bec400, running UMT 0x7f94e2227eb8, found to be stuck.
14/02 02:44:43.799257 e0e38eb8:cont_IsSchedThredStuck:01678: Stuck scheduler thread identified
14/02 02:44:43.799267 e0e38eb8:kalive_StartIntr:00346: KA aborted due to stuck sched thread
- SDSはtrcファイルに「error forking」を表示する場合があります。
01/09 00:37:51.329020 0x7f1001c58eb0:mosDbg_BackTraceAllOsThreads:00673: Error forking.
- 必要なメモリの割り当てに失敗したため、SDS を開始できません
expログ ファイルでは、次の内容が報告されます。
07/09 00:41:52.713502 Panic in file /data/build/workspace/ScaleIO-SLES12-2/src/mos/usr/mos_utils.c, line 235, function mos_AllocPageAlignedOrPanic, PID 25342.Panic Expression pMem != ((void *)0) .
- OSの/var/log/messagesまたはシステムイベントログにもいくつかの症状がある場合があります。
/var/log/messages:
Feb 14 13:25:08 ScaleIO-192-168-1-2 kernel: [7461116.683555] TCP: Possible SYN flooding on port 7072. Sending cookies.
Feb 14 13:25:08 ScaleIO-192-168-1-2 kernel: [7461116.683561] TCP: Possible SYN flooding on port 7072. Sending cookies.
Feb 14 13:25:08 ScaleIO-192-168-1-2 kernel: [7461116.683566] TCP: Possible SYN flooding on port 7072. Sending cookies.
Feb 14 13:25:08 ScaleIO-192-168-1-2 kernel: [7461116.683570] TCP: Possible SYN flooding on port 7072. Sending cookies.
Feb 14 13:27:39 ScaleIO-192-168-1-2 kernel: [7461266.566145] sched: RT throttling activated
「ポート7072でのSYNフラッディング」メッセージは、ネットワーク データ パケットがこのホスト上のSDSに送信されており、SDSがそのポート上のパケットを受け入れることができないことを意味します。SDSは、デフォルトでポート7072を使用します。
「RT throttling activated」は、OS スケジューラが CPU を占有し、他のスレッドを枯渇させているリアルタイムスレッドを特定したことを示すメッセージです。OSは、これらのリアルタイムタスクを調整し、OSがハングしたりクラッシュしたりしないようにするためにこれを行います。
SDCの問題:
また、SDSが頻繁に切断された場合や、SDCに十分な速さで応答できず、所有するIOブロックの処理を試行している場合にも、SDCでIOエラーが発生する可能性があります。
問題
上記の症状は、DATA_DEGRADED、DATA_FAILEDイベント、およびCLUSTER_DEGRADEDを引き起こす可能性があります。
원인
上記のすべての現象が一致する場合は、CPUまたはメモリー リソースの枯渇の問題である可能性が高くなります。MDMまたはSDSプロセスからCPUとメモリーを枯渇させている可能性のあるサード パーティー製アプリケーションまたは実行中のプロセスを探します
仮想環境で、CPUのパフォーマンスが低下したことが何度かありました。これは、SVMが同じリソース プールで定義されているために発生します
このような場合は、SVMをリソース プールの下に配置するのではなく、SVMで定義されている専用リソースを使用することをお勧めします。
해결
PowerFlexコンポーネント(MDM、SDS、SDC)のパフォーマンス設定がチューニングされていることを確認します。こちらにあるパフォーマンスの「微調整」および「トラブルシューティング」ガイドを参照してください。
構成の確認:
- まず、SVMのCPUとRAMの設定がベスト プラクティスに従っていることを確認します。
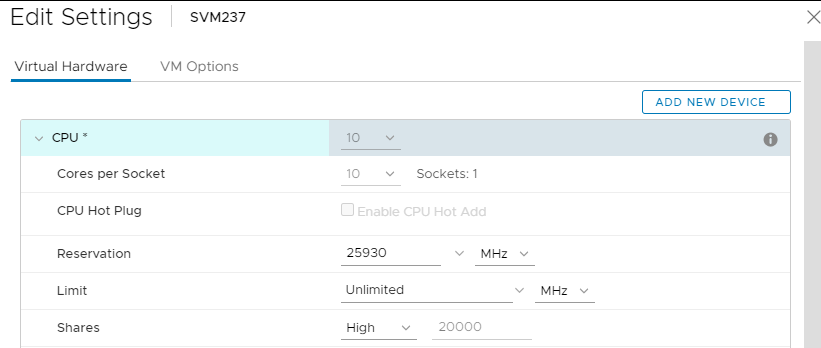
- SVM CPU設定: (臨機応変に設定可能)
- ソケットあたりのコア数:オールインワンソケットであるため、「Sockets」の値は「1」になります。(コアの総数は、ホストするSDSのニーズによって決まります。オールフラッシュ、FG、DASCache、Cloudlink、3.5などはすべて、CPU要件に影響を与えます(増加します)。
- 予約:ドロップダウンで[Maximum]の値を選択します
- 株式:High
- これは、次のようになります。
- SVM CPU設定: (臨機応変に設定可能)
b. SVM RAM 設定: (臨機応変に設定可能)
- 「Reserve all guest memory (All locked)」にチェックを入れる
- 株式:High
- これは、次のようになります。

c. ゲスト内 SVM OS メモリ オーバーコミット設定: (再起動が必要)
-
- sysctl -a|grep overcommit を実行して、オーバーコミット設定が正しいことを確認します。
# sysctl -a|grep overcommit vm.overcommit_memory = 2 vm.overcommit_ratio = 100 -
上記の値が設定されていない場合、一部のSVMメモリーがSDSプロセスで使用できなくなります。/etc/sysctl.confを編集し、上記の値を編集/追加して、これを修正します
- SDSをメンテナンス モードにし、SVMを再起動して設定を適用します
- 再起動後に「cat /etc/sysctl.conf|grep overcommit」を実行して確認します。
- メンテナンス モードの終了
- sysctl -a|grep overcommit を実行して、オーバーコミット設定が正しいことを確認します。
- これらをログで見つけるには、次のようにします。
- SVM構成(vmsupport):
-
正しく構成されたSVMの.vmxファイルには、次のものが含まれます。
-
- SVM構成(vmsupport):
sched.cpu.units = "mhz"
sched.cpu.affinity = "all"
sched.cpu.min = "25930" (nonzero value that's equal to core speed * the # of cores allocated)
sched.cpu.shares = "high"
sched.mem.min = "24576" (nonzero value that's a full allocation of configured memory)
sched.mem.minSize = "24576" (nonzero value that's a full allocation of configured memory)
sched.mem.shares = "high"
cpuid.coresPerSocket = "10" (value equal to total # of cores allocated, so they're all in one socket)
sched.mem.pin = "TRUE"
- 不正な(古い)SVMconfigには、次の情報が表示されます。
sched.cpu.min = "0"
sched.cpu.shares = "normal"
sched.mem.pin = "FALSE"
sched.mem.shares = "normal"
cpuid.coresPerSocket = "4" (value less than total # of cores allocated, usually 1/2 or 1/4)
ゲスト内OS構成(getinfo):
-
正しく構成されたメモリー オーバーコミット:
ファイル サーバー/sysctl.txtには、次のものが含まれます。
vm.overcommit_memory = 2
vm.overcommit_ratio = 100
-
PowerFlexは、各サービスがメモリー内で高速に実行されるように、かなりの量のRAMを使用します。これが、PowerFlexサービスのオフロードに使用するスワップの使用をサポートしていない理由です。
HCIソリューションのストレージのみとSVMで想定されるデフォルト設定は、オーバーコミット メモリー2です。この方法では、カーネルはメモリをオーバーサブスクライブせず、スワップを使用しない場合は、commit_as値が空き/利用可能なメモリの合計よりも大きくなることはありません。
比率を100にすると、スワップが使用されないようにし、使用されるスワップをより詳細に制御できます。
-
不適切に設定されたメモリー オーバーコミット:
ファイル サーバー/sysctl.txtには次のものが含まれます。
vm.overcommit_memory = 0 (value not 2)
vm.overcommit_ratio = 50 (value less than 95)
その他の考えられる回避策:
- CPU/メモリー リソース不足の原因となっているアプリケーションを停止するか、アプリケーション ベンダーにアップデートを確認してリソースの消費を軽減します。
- CPU/メモリーのトレンド分析ツール(top/sar/cronジョブなど)を使用して、リソースを使用しているアプリケーションを特定します。問題がいつ発生するか、誰が責任があるかを示すのに必要な粒度を得るには、1秒の間隔をお勧めします
- ホストのCPUやメモリーをアップグレードしてリソースを増やす
- コンバージド システムではなく2レイヤー セットアップに再設計する(SDS/SDCが同じホスト上にある場合)
추가 정보
문서 속성
문서 번호: 000167765
문서 유형: Solution
마지막 수정 시간: 24 11월 2025
버전: 5
다른 Dell 사용자에게 질문에 대한 답변 찾기
지원 서비스
디바이스에 지원 서비스가 적용되는지 확인하십시오.