PowerFlex: Rozwiązywanie problemów z rywalizacją o zasoby
요약: Problemy z rywalizacją o zasoby PowerFlex i rozwiązywanie problemów
이 문서는 다음에 적용됩니다.
이 문서는 다음에 적용되지 않습니다.
이 문서는 특정 제품과 관련이 없습니다.
모든 제품 버전이 이 문서에 나와 있는 것은 아닙니다.
증상
Nietypowe zachowanie procesów PowerFlex powoduje, że procesy PowerFlex natrafiają na rywalizację o zasoby z innym oprogramowaniem lub komponentami sprzętowymi.
Objawy mogą być tutaj liczne i różnorodne. To jest częściowa lista objawów i wyników
Problemy z MDM:
- Przełączanie awaryjne własności MDM następuje, gdy procesy MDM utkną i utracą komunikację z innymi MDM
From exp.0:
Panic in file /emc/svc_flashbld/workspace/ScaleIO-RHEL7/src/mos/umt/mos_umt_sched_thrd.c, line 1798, function mosUmtSchedThrd_SuspendCK, PID 36721.Panic Expression ALWAYS_ASSERT Scheduler guard seems to be dead.
From trc.*
24/02 15:54:16.087919 0:schedThrdGuard_SampleLivnes:01463: WARNING: pThread 0x106d9360(0) in scheduler 0x7fff580c4880, running UMT 0x7f39ad00ceb8, found to be stuck.
24/02 15:54:16.088226 ad417eb8:actorLoop_IsSchedThredStuck:10932: Stuck scheduler thread identified
24/02 15:54:16.088253 ad417eb8:actor_Loop:11257: Lost quorum. ourVoters: 0 votersOwnedByOther: [0,0]
24/02 15:54:16.088299 ---Planned crash, reason: Lost quorum, going down to let another MDM become master ---
- Proces MDM będzie się rozłączał i łączył ponownie przez pewien czas
2017-02-23 14:00:43.241 MDM_CLUSTER_LOST_CONNECTION WARNING The MDM, ID 089012db4d536880, lost connection
2017-02-23 14:00:43.422 MDM_CLUSTER_CONNECTED INFO The MDM, ID 089012db4d536880, connected
2017-02-23 23:05:25.852 MDM_CLUSTER_LOST_CONNECTION WARNING The MDM, ID 089012db4d536880, lost connection
2017-02-23 23:05:26.422 MDM_CLUSTER_CONNECTED INFO The MDM, ID 089012db4d536880, connected
2017-02-24 15:54:16.141 MDM_CLUSTER_LOST_CONNECTION WARNING The MDM, ID 089012db4d536880, lost connection
2017-02-24 15:54:16.238 MDM_CLUSTER_CONNECTED INFO The MDM, ID 089012db4d536880, connected
Problemy z kartą SDS:
- SDS będzie się rozłączać i ponownie łączyć przez pewien czas
2017-02-15 13:18:16.881 SDS_RECONNECTED INFO SDS: siosds2 (ID 1eb052fe00000001) reconnected
2017-02-16 03:37:37.327 SDS_DECOUPLED ERROR SDS: siosds2 (id: 1eb052fe00000001) decoupled.
2017-02-16 03:39:54.300 SDS_RECONNECTED INFO SDS: siosds2 (ID 1eb052fe00000001) reconnected
2017-02-17 04:03:41.757 SDS_DECOUPLED ERROR SDS: siosds2 (id: 1eb052fe00000001) decoupled.
2017-02-17 04:09:13.604 SDS_RECONNECTED INFO SDS: siosds2 (ID 1eb052fe00000001) reconnected
— SDS może wyświetlać błędy oscylacyjne w plikach trc dotyczące utraty łączności z innymi węzłami SDS:
14/02 19:13:24.096983 1be7eb8:contNet_OscillationNotif:01675: Con 1eb052fe00000005 - Oscillation of type 5 (RPC_LINGERED_1SEC) reported
14/02 19:13:24.196814 1be7eb8:contNet_OscillationNotif:01675: Con 1eb053000000000b - Oscillation of type 5 (RPC_LINGERED_1SEC) reported
14/02 19:13:24.296713 1be7eb8:contNet_OscillationNotif:01675: Con 1eb0530000000007 - Oscillation of type 5 (RPC_LINGERED_1SEC) reported
14/02 21:48:43.917218 afb28eb8:contNet_OscillationNotif:01675: Con 1eb052fe00000007 - Oscillation of type 1 (SOCKET_DOWN) reported
14/02 21:48:43.917296 afb28eb8:contNet_OscillationNotif:01675: Con 1eb052fe00000005 - Oscillation of type 1 (SOCKET_DOWN) reported
- SDS może pokazywać zablokowane lub zablokowane wątki w plikach trc:
14/02 19:13:24.147938 9aa4eeb8:netPath_IsKaNeeded:01789: DEBUG ASSERT, Reason:Socket deadlocked. Crashing.
14/02 19:13:24.148113 9aa4eeb8:netPath_IsKaNeeded:01789: DEBUG ASSERT, Reason:Socket deadlocked. Crashing.
14/02 19:13:24.148121 9aa4eeb8:netPath_IsKaNeeded:01789: DEBUG ASSERT, Reason:Socket deadlocked. Crashing.
14/02 20:52:54.097765 242f0eb8:kalive_StartIntr:00346: KA aborted due to stuck sched thread
14/02 21:48:43.510602 7fa30eb8:kalive_StartIntr:00346: KA aborted due to stuck sched thread
14/02 21:48:44.776713 1b67ceb8:kalive_StartIntr:00346: KA aborted due to stuck sched thread
14/02 02:44:41.532007 e2239eb8:contNet_OscillationNotif:01675: Con 1eb052fd00000001 - Oscillation of type 3 (RCV_KA_DISCONNECT) reported
14/02 02:44:43.799135 0:schedThrdGuard_SampleLivnes:01463: WARNING: pThread 0x1a0de10(0) in scheduler 0x7fff01bec400, running UMT 0x7f94e221eeb8, found to be stuck.
14/02 02:44:43.799155 0:schedThrdGuard_SampleLivnes:01463: WARNING: pThread 0x1a0e050(1) in scheduler 0x7fff01bec400, running UMT 0x7f94e2227eb8, found to be stuck.
14/02 02:44:43.799257 e0e38eb8:cont_IsSchedThredStuck:01678: Stuck scheduler thread identified
14/02 02:44:43.799267 e0e38eb8:kalive_StartIntr:00346: KA aborted due to stuck sched thread
- SDS może pokazywać "rozwidlenie błędów" w plikach trc:
01/09 00:37:51.329020 0x7f1001c58eb0:mosDbg_BackTraceAllOsThreads:00673: Error forking.
- Nie można uruchomić serwera SDS z powodu niepowodzenia przydzielenia wymaganej pamięci.
W plikach dziennika exp zgłaszane są następujące informacje:
07/09 00:41:52.713502 Panic in file /data/build/workspace/ScaleIO-SLES12-2/src/mos/usr/mos_utils.c, line 235, function mos_AllocPageAlignedOrPanic, PID 25342.Panic Expression pMem != ((void *)0) .
- System operacyjny może również mieć pewne objawy w /var/log/messages lub dziennikach zdarzeń systemowych:
/var/log/messages:
Feb 14 13:25:08 ScaleIO-192-168-1-2 kernel: [7461116.683555] TCP: Possible SYN flooding on port 7072. Sending cookies.
Feb 14 13:25:08 ScaleIO-192-168-1-2 kernel: [7461116.683561] TCP: Possible SYN flooding on port 7072. Sending cookies.
Feb 14 13:25:08 ScaleIO-192-168-1-2 kernel: [7461116.683566] TCP: Possible SYN flooding on port 7072. Sending cookies.
Feb 14 13:25:08 ScaleIO-192-168-1-2 kernel: [7461116.683570] TCP: Possible SYN flooding on port 7072. Sending cookies.
Feb 14 13:27:39 ScaleIO-192-168-1-2 kernel: [7461266.566145] sched: RT throttling activated
Komunikaty "SYN flooding on port 7072" oznaczają, że pakiety danych sieciowych są wysyłane do SDS na tym hoście, a SDS nie może przyjąć pakietów na tym porcie. Serwer SDS domyślnie korzysta z portu 7072.
"Ograniczenie przepustowości RT aktywowane" to komunikat informujący, że harmonogram systemu operacyjnego zidentyfikował niektóre wątki w czasie rzeczywistym, które obciążają procesor i blokują inne wątki. System operacyjny robi to, próbując ograniczyć te zadania w czasie rzeczywistym i zapobiec zawieszaniu się lub awariom systemu operacyjnego.
Problemy z SDC:
Kontroler SDC może również napotkać błędy we/wy, gdy serwery SDS często się rozłączają lub nie mogą wystarczająco szybko zareagować na SDC i nadal próbują obsługiwać bloki we/wy, których jest właścicielem.
Wpływ
Powyższe objawy mogą powodować zdarzenia DATA_DEGRADED, DATA_FAILED, a także CLUSTER_DEGRADED.
원인
Jeśli wszystkie powyższe objawy są zgodne, najprawdopodobniej problem z niedoborem zasobów procesora lub pamięci. Sprawdź, czy nie są uruchomione aplikacje lub procesy innych firm, które mogą pozbawiać procesor i pamięć z procesów MDM lub SDS.
W środowisku wirtualnym kilka razy procesor miał słabą wydajność. Jest to spowodowane tym, że maszyny SVM są zdefiniowane w tej samej puli zasobów.
W takich przypadkach powinniśmy radzić, aby nie umieszczać SVM w puli zasobów, ale mieć ich dedykowane zasoby zdefiniowane w SVM.
해결
Upewnij się, że elementy PowerFlex (MDM, SDS, SDC) zostały dostrojone pod kątem ustawień wydajności. Zapoznaj się z przewodnikami "Dostrajanie" i "Rozwiązywanie problemów" dotyczącymi wydajności, które znajdują się tutaj.
Przegląd konfiguracji:
- Najpierw sprawdź, czy ustawienia procesora i pamięci RAM SVM są zgodne z najlepszymi praktykami:
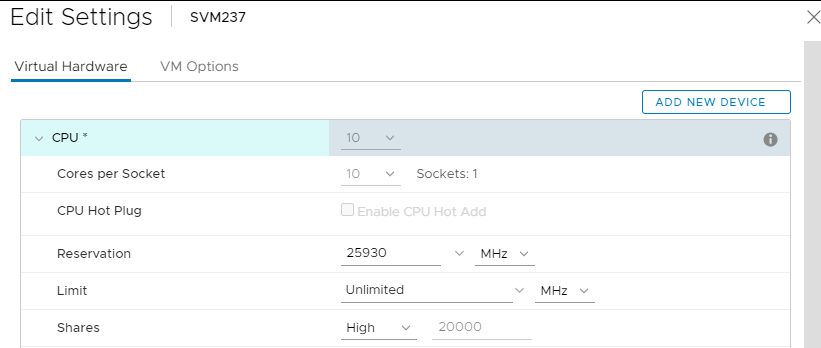
- Ustawienia procesora SVM: (Można ustawić w locie)
- Rdzenie na gniazdo: wszystko w jednym gnieździe, więc "Sockets" ma wartość "1". (Ogólna liczba rdzeni zależy od potrzeb hosta SDS: All-flash, FG, DASCache, CloudLink, 3.5 itd., wszystkie te czynniki wpływają na (zwiększą) wymagania procesora).
- Rezerwacja: Wybierz wartość "Maksymalna" z listy rozwijanej
- Udziały: Wysokie
- Powinno to wyglądać tak, jak na poniższym przykładzie:
- Ustawienia procesora SVM: (Można ustawić w locie)
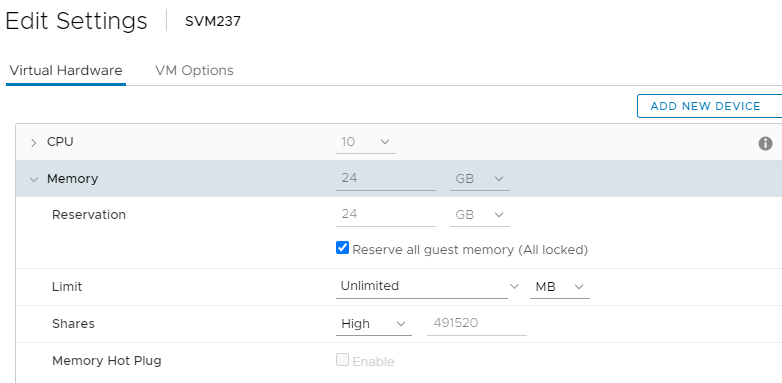
b. Ustawienia pamięci RAM SVM: (Można ustawić w locie)
- Zaznacz opcję "Zarezerwuj całą pamięć gościa (wszystkie zablokowane)"
- Udziały: Wysokie
- Powinno to wyglądać tak, jak na poniższym przykładzie:
c. Ustawienia nadmiernego commit pamięci SVM OS gościa: (Wymaga ponownego uruchomienia)
-
- Uruchom polecenie sysctl -a|grep overcommit, aby potwierdzić poprawność ustawień overcommit:
# sysctl -a|grep overcommit vm.overcommit_memory = 2 vm.overcommit_ratio = 100 -
Jeśli powyższe wartości nie zostaną ustawione, część pamięci SVM nie będzie mogła być używana przez proces SDS. Popraw to, edytując plik /etc/sysctl.conf i edytując/dodając powyższe wartości
- Przełącz serwer SDS w tryb konserwacji i uruchom ponownie SVM, aby zastosować ustawienia
- Potwierdź, uruchamiając polecenie "cat /etc/sysctl.conf|grep overcommit" po ponownym uruchomieniu
- Wyjdź z trybu konserwacji
- Uruchom polecenie sysctl -a|grep overcommit, aby potwierdzić poprawność ustawień overcommit:
- Aby znaleźć je w dziennikach:
- Konfiguracja SVM (vmsupport):
-
Poprawnie skonfigurowany plik .vmx SVM będzie zawierał następujące elementy:
-
- Konfiguracja SVM (vmsupport):
sched.cpu.units = "mhz"
sched.cpu.affinity = "all"
sched.cpu.min = "25930" (nonzero value that's equal to core speed * the # of cores allocated)
sched.cpu.shares = "high"
sched.mem.min = "24576" (nonzero value that's a full allocation of configured memory)
sched.mem.minSize = "24576" (nonzero value that's a full allocation of configured memory)
sched.mem.shares = "high"
cpuid.coresPerSocket = "10" (value equal to total # of cores allocated, so they're all in one socket)
sched.mem.pin = "TRUE"
- Niepoprawne (nieaktualne) konfiguracje SVMconfigs będą miały następujące elementy:
sched.cpu.min = "0"
sched.cpu.shares = "normal"
sched.mem.pin = "FALSE"
sched.mem.shares = "normal"
cpuid.coresPerSocket = "4" (value less than total # of cores allocated, usually 1/2 or 1/4)
Konfiguracja systemu operacyjnego gościa (getinfo):
-
Prawidłowo skonfigurowane przekroczenie pojemności pamięci:
Serwer/sysctl.txt plików zawiera:
vm.overcommit_memory = 2
vm.overcommit_ratio = 100
-
PowerFlex używa znaczną ilość pamięci RAM, aby każda z usług działała w pamięci i z dużą szybkością. Z tego powodu nie obsługuje on użycia swap w celu odciążenia którejkolwiek z usług PowerFlex.
Domyślnym ustawieniem, które jest oczekiwane dla Tylko pamięć masowa i SVM w rozwiązaniu HCI, jest pamięć z nadmiernym zobowiązaniem wynosząca 2. W ten sposób jądro nie będzie nadmiernie subskrybować pamięci, a bez użycia ustawień bez wymiany, żadna wartość commit_as nie będzie większa niż całkowita wolna/dostępna pamięć.
Współczynnik 100 zapewnia, że nie jest również używany swap, co zapewnia większą kontrolę nad stosowaniem swapu blokowego.
-
Nieprawidłowo skonfigurowane nadmierne zaangażowanie pamięci:
serwer plików/sysctl.txt zawiera:
vm.overcommit_memory = 0 (value not 2)
vm.overcommit_ratio = 50 (value less than 95)
Inne możliwe sposoby obejścia problemu:
- Zatrzymaj aplikacje powodujące niedobór zasobów procesora/pamięci lub skontaktuj się z dostawcą aplikacji, aby uzyskać aktualizacje w celu złagodzenia problemu przeciążania zasobów.
- Użyj narzędzi do trendowania procesora/pamięci (zadania top/sar/cron/itp.), aby dowiedzieć się, która aplikacja pobiera zasoby. Zalecane odstępy 1 sekundy w celu uzyskania szczegółowości niezbędnej do pokazania, kiedy występuje problem i kto jest za niego odpowiedzialny
- Uaktualnij procesor i/lub pamięć hosta, aby zapewnić więcej zasobów
- Zmiana architektury na konfigurację dwuwarstwową zamiast systemu konwergentnego (jeśli SDS/SDC znajdują się na tym samym hoście)
추가 정보
문서 속성
문서 번호: 000167765
문서 유형: Solution
마지막 수정 시간: 24 11월 2025
버전: 5
다른 Dell 사용자에게 질문에 대한 답변 찾기
지원 서비스
디바이스에 지원 서비스가 적용되는지 확인하십시오.