PowerFlex:資源爭奪疑難排解
요약: PowerFlex 資源爭奪問題和故障診斷
이 문서는 다음에 적용됩니다.
이 문서는 다음에 적용되지 않습니다.
이 문서는 특정 제품과 관련이 없습니다.
모든 제품 버전이 이 문서에 나와 있는 것은 아닙니다.
증상
當 PowerFlex 程序與其他軟體或硬體元件發生資源爭用時,會導致 PowerFlex 程序出現異常行為。
這裡的癥狀可能多種多樣。這是症狀和結果的部分清單
MDM 問題:
- 當 MDM 進程停滯並失去與其他 MDM 的通信時,會發生 MDM 擁有權故障轉移
From exp.0:
Panic in file /emc/svc_flashbld/workspace/ScaleIO-RHEL7/src/mos/umt/mos_umt_sched_thrd.c, line 1798, function mosUmtSchedThrd_SuspendCK, PID 36721.Panic Expression ALWAYS_ASSERT Scheduler guard seems to be dead.
From trc.*
24/02 15:54:16.087919 0:schedThrdGuard_SampleLivnes:01463: WARNING: pThread 0x106d9360(0) in scheduler 0x7fff580c4880, running UMT 0x7f39ad00ceb8, found to be stuck.
24/02 15:54:16.088226 ad417eb8:actorLoop_IsSchedThredStuck:10932: Stuck scheduler thread identified
24/02 15:54:16.088253 ad417eb8:actor_Loop:11257: Lost quorum. ourVoters: 0 votersOwnedByOther: [0,0]
24/02 15:54:16.088299 ---Planned crash, reason: Lost quorum, going down to let another MDM become master ---
- MDM 流程將斷開連接,並在一段時間內不斷重新連接
2017-02-23 14:00:43.241 MDM_CLUSTER_LOST_CONNECTION WARNING The MDM, ID 089012db4d536880, lost connection
2017-02-23 14:00:43.422 MDM_CLUSTER_CONNECTED INFO The MDM, ID 089012db4d536880, connected
2017-02-23 23:05:25.852 MDM_CLUSTER_LOST_CONNECTION WARNING The MDM, ID 089012db4d536880, lost connection
2017-02-23 23:05:26.422 MDM_CLUSTER_CONNECTED INFO The MDM, ID 089012db4d536880, connected
2017-02-24 15:54:16.141 MDM_CLUSTER_LOST_CONNECTION WARNING The MDM, ID 089012db4d536880, lost connection
2017-02-24 15:54:16.238 MDM_CLUSTER_CONNECTED INFO The MDM, ID 089012db4d536880, connected
SDS 問題:
- SDS 將在一段時間內斷開連接並不斷重新連接
2017-02-15 13:18:16.881 SDS_RECONNECTED INFO SDS: siosds2 (ID 1eb052fe00000001) reconnected
2017-02-16 03:37:37.327 SDS_DECOUPLED ERROR SDS: siosds2 (id: 1eb052fe00000001) decoupled.
2017-02-16 03:39:54.300 SDS_RECONNECTED INFO SDS: siosds2 (ID 1eb052fe00000001) reconnected
2017-02-17 04:03:41.757 SDS_DECOUPLED ERROR SDS: siosds2 (id: 1eb052fe00000001) decoupled.
2017-02-17 04:09:13.604 SDS_RECONNECTED INFO SDS: siosds2 (ID 1eb052fe00000001) reconnected
- SDS 可能會在 trc 檔案中顯示有關與其他 SDS 節點失去連線的振蕩錯誤:
14/02 19:13:24.096983 1be7eb8:contNet_OscillationNotif:01675: Con 1eb052fe00000005 - Oscillation of type 5 (RPC_LINGERED_1SEC) reported
14/02 19:13:24.196814 1be7eb8:contNet_OscillationNotif:01675: Con 1eb053000000000b - Oscillation of type 5 (RPC_LINGERED_1SEC) reported
14/02 19:13:24.296713 1be7eb8:contNet_OscillationNotif:01675: Con 1eb0530000000007 - Oscillation of type 5 (RPC_LINGERED_1SEC) reported
14/02 21:48:43.917218 afb28eb8:contNet_OscillationNotif:01675: Con 1eb052fe00000007 - Oscillation of type 1 (SOCKET_DOWN) reported
14/02 21:48:43.917296 afb28eb8:contNet_OscillationNotif:01675: Con 1eb052fe00000005 - Oscillation of type 1 (SOCKET_DOWN) reported
- SDS 可能會在 trc 檔中顯示死鎖或卡住的線程:
14/02 19:13:24.147938 9aa4eeb8:netPath_IsKaNeeded:01789: DEBUG ASSERT, Reason:Socket deadlocked. Crashing.
14/02 19:13:24.148113 9aa4eeb8:netPath_IsKaNeeded:01789: DEBUG ASSERT, Reason:Socket deadlocked. Crashing.
14/02 19:13:24.148121 9aa4eeb8:netPath_IsKaNeeded:01789: DEBUG ASSERT, Reason:Socket deadlocked. Crashing.
14/02 20:52:54.097765 242f0eb8:kalive_StartIntr:00346: KA aborted due to stuck sched thread
14/02 21:48:43.510602 7fa30eb8:kalive_StartIntr:00346: KA aborted due to stuck sched thread
14/02 21:48:44.776713 1b67ceb8:kalive_StartIntr:00346: KA aborted due to stuck sched thread
14/02 02:44:41.532007 e2239eb8:contNet_OscillationNotif:01675: Con 1eb052fd00000001 - Oscillation of type 3 (RCV_KA_DISCONNECT) reported
14/02 02:44:43.799135 0:schedThrdGuard_SampleLivnes:01463: WARNING: pThread 0x1a0de10(0) in scheduler 0x7fff01bec400, running UMT 0x7f94e221eeb8, found to be stuck.
14/02 02:44:43.799155 0:schedThrdGuard_SampleLivnes:01463: WARNING: pThread 0x1a0e050(1) in scheduler 0x7fff01bec400, running UMT 0x7f94e2227eb8, found to be stuck.
14/02 02:44:43.799257 e0e38eb8:cont_IsSchedThredStuck:01678: Stuck scheduler thread identified
14/02 02:44:43.799267 e0e38eb8:kalive_StartIntr:00346: KA aborted due to stuck sched thread
- SDS 可能會在 trc 檔中顯示「錯誤分叉」:
01/09 00:37:51.329020 0x7f1001c58eb0:mosDbg_BackTraceAllOsThreads:00673: Error forking.
- 由於無法分配所需的記憶體,SDS 無法啟動。
在 exp 記錄檔中會報告以下內容:
07/09 00:41:52.713502 Panic in file /data/build/workspace/ScaleIO-SLES12-2/src/mos/usr/mos_utils.c, line 235, function mos_AllocPageAlignedOrPanic, PID 25342.Panic Expression pMem != ((void *)0) .
在 /var/log/messages 或系統事件記錄中,作業系統也可能有一些症狀:
/var/log/messages:
Feb 14 13:25:08 ScaleIO-192-168-1-2 kernel: [7461116.683555] TCP: Possible SYN flooding on port 7072. Sending cookies.
Feb 14 13:25:08 ScaleIO-192-168-1-2 kernel: [7461116.683561] TCP: Possible SYN flooding on port 7072. Sending cookies.
Feb 14 13:25:08 ScaleIO-192-168-1-2 kernel: [7461116.683566] TCP: Possible SYN flooding on port 7072. Sending cookies.
Feb 14 13:25:08 ScaleIO-192-168-1-2 kernel: [7461116.683570] TCP: Possible SYN flooding on port 7072. Sending cookies.
Feb 14 13:27:39 ScaleIO-192-168-1-2 kernel: [7461266.566145] sched: RT throttling activated
“埠 7072 上的 SYN 泛洪”消息意味著網络數據包正在發送到此主機上的 SDS,並且 SDS 無法接受該埠上的數據包。SDS 預設使用連接埠 7072。
“RT 限制已啟動”是一條消息,表明操作系統計劃程式已識別一些即時線程佔用 CPU 並使其他線程耗盡。操作系統這樣做是為了嘗試限制這些實時任務,並防止操作系統掛起或崩潰。
SDC 問題:
當 SDS 經常中斷連線,或無法足夠快速地回應 SDC,且仍在嘗試為其擁有的 I/O 區塊提供服務時,SDC 也可能遭遇 IO 錯誤。
影響
上述症狀可能導致DATA_DEGRADED、DATA_FAILED事件以及CLUSTER_DEGRADED。
원인
如果上述所有症狀都相符,則很可能是 CPU 或記憶體資源匱乏問題。尋找正在執行的第三方應用程式或程序,這些應用程式或程序可能會使 MDM 或 SDS 程序耗盡 CPU 和記憶體。
在虛擬環境中,有幾次 CPU 效能不佳。這是由在同一資源池下定義的 SVM 引起的。
在這種情況下,我們應該建議不要將 SVM 放在資源池下,而是將其專用資源放在 SVM 中定義。
해결
確定 PowerFlex 元件 (MDM、SDS、SDC) 已針對效能設定進行調整。請參閱此處的效能「微調」和「疑難排解」指南。
組態檢閱:
- 首先,確認 SVM CPU 和 RAM 設定符合最佳實踐:
- SVM CPU 設定:(可以即時設定)
- 每個插槽的核心數:全部在一個插槽中,因此「插槽」的值為「1」。(核心總數取決於其託管的 SDS 需求:全快閃、FG、DASCache、Cloudlink、3.5 等,皆會影響 (增加) CPU 需求。)
- 保留:在下拉式清單中選取「最大值」
- 股票:High
- 這看起來應該如下:
- SVM CPU 設定:(可以即時設定)

b. SVM RAM 設定:(可以即時設定)
- 檢查「保留所有客戶機記憶體 (全部鎖定)」
- 股票:High
- 這看起來應該如下:
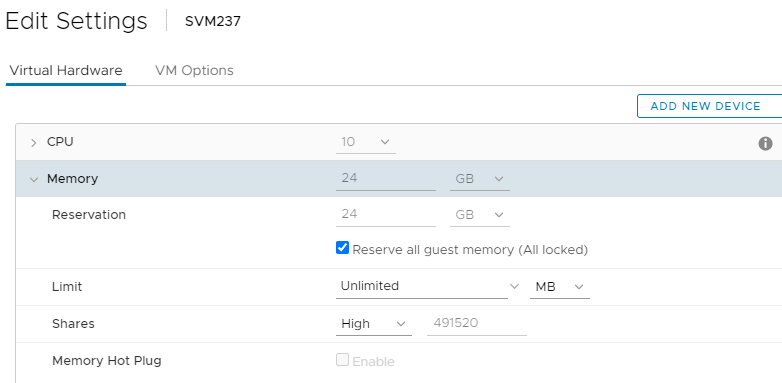
c. 客體內 SVM 作業系統記憶體超額使用設定:(需要重新開機)
-
- 執行 sysctl -a|grep overcommit 以確認 overcommit 設定正確無誤:
# sysctl -a|grep overcommit vm.overcommit_memory = 2 vm.overcommit_ratio = 100 -
如果未設置上述值,某些 SVM 記憶體將無法用於 SDS 進程。編輯 /etc/sysctl.conf 並編輯/新增上述值以更正此問題
- 將 SDS 置於維護模式,然後重新啟動 SVM 以套用設定
- 在重新開機後執行「cat /etc/sysctl.conf|grep overcommit」以確認
- 結束維護模式
- 執行 sysctl -a|grep overcommit 以確認 overcommit 設定正確無誤:
- 若要在記錄中尋找這些資訊:
- SVM 組態 (vmsupport):
-
正確設定的 SVM 的 .vmx 檔案將包含以下內容:
-
- SVM 組態 (vmsupport):
sched.cpu.units = "mhz"
sched.cpu.affinity = "all"
sched.cpu.min = "25930" (nonzero value that's equal to core speed * the # of cores allocated)
sched.cpu.shares = "high"
sched.mem.min = "24576" (nonzero value that's a full allocation of configured memory)
sched.mem.minSize = "24576" (nonzero value that's a full allocation of configured memory)
sched.mem.shares = "high"
cpuid.coresPerSocket = "10" (value equal to total # of cores allocated, so they're all in one socket)
sched.mem.pin = "TRUE"
- 不正確(過時)的 SVM 設定將具有以下內容:
sched.cpu.min = "0"
sched.cpu.shares = "normal"
sched.mem.pin = "FALSE"
sched.mem.shares = "normal"
cpuid.coresPerSocket = "4" (value less than total # of cores allocated, usually 1/2 or 1/4)
客體內作業系統組態 (getinfo):
-
正確設定的記憶體過量使用:
檔案伺服器/sysctl.txt包含:
vm.overcommit_memory = 2
vm.overcommit_ratio = 100
-
PowerFlex 會為每個服務使用大量的 RAM,才能在記憶體中高速執行。這就是為什麼它不支援使用交換來卸載任何 PowerFlex 服務。
HCI 解決方案中「僅儲存」和「SVM」預期的預設設定為 2 的超額記憶體。這樣,內核就不會超額訂閱記憶體,並且在不使用交換設置的情況下,確保commit_as值不會大於總可用/可用記憶體。
100 的比率確保也沒有使用掉期,以便更好地控制使用塊掉期。
-
未正確設定的記憶體過度使用:
檔案伺服器/sysctl.txt包含:
vm.overcommit_memory = 0 (value not 2)
vm.overcommit_ratio = 50 (value less than 95)
其他可能的因應措施:
- 停止導致 CPU/記憶體資源匱乏的應用程式,或與應用程式供應商聯繫以獲取更新以緩解資源佔用。
- 使用 CPU/記憶體趨勢工具 (top/sar/cron 工作等) 找出哪個應用程式佔用了資源。建議間隔 1 秒,以取得必要的粒度,以顯示問題發生的時間以及責任人
- 升級主機 CPU 和/或記憶體,為其提供更多資源
- 重新架構至雙層設定而非融合式系統 (如果 SDS/SDC 位於相同主機上)
추가 정보
문서 속성
문서 번호: 000167765
문서 유형: Solution
마지막 수정 시간: 24 11월 2025
버전: 5
다른 Dell 사용자에게 질문에 대한 답변 찾기
지원 서비스
디바이스에 지원 서비스가 적용되는지 확인하십시오.